Persistir informações extraídas em um repositório de conhecimento
Dica
Consulte a guia Texto e imagens para obter mais detalhes!
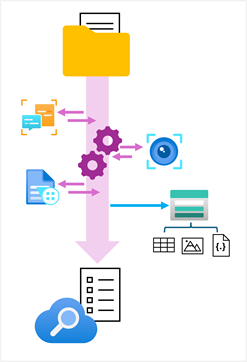
Embora o índice possa ser considerado a saída primária de um processo de indexação, os dados enriquecidos que ele contém também podem ser úteis de outras maneiras. Por exemplo:
- Como o índice é essencialmente uma coleção de objetos JSON, cada um representando um registro indexado, pode ser útil exportar os objetos como arquivos JSON para integração em um processo de orquestração de dados para operações de ETL (extração, transformação e carregamento).
- O ideal é normalizar os registros de índice em um esquema relacional de tabelas para análise e relatórios.
- Após extrair imagens incorporadas de documentos durante o processo de indexação, convém salvá-las como arquivos.
A Pesquisa de IA do Azure dá suporte a esses cenários, permitindo que você defina um repositório de conhecimento no conjunto de habilidades que encapsula o pipeline de enriquecimento. O repositório de conhecimento é composto por projeções dos dados enriquecidos, que podem ser arquivos de imagem, tabelas ou objetos JSON. Quando um indexador executa o pipeline para criar ou atualizar um índice, as projeções são geradas e persistidas no repositório de conhecimento.
Dica
Para saber mais sobre como usar um repositório de conhecimento, veja Repositório de conhecimento na Pesquisa de IA do Azure na documentação da Pesquisa de IA do Azure.