Como lidar com a latência de cauda
- 13 minutos
Já discutimos várias técnicas de otimização usadas na nuvem para reduzir a latência. Algumas das medidas estudadas incluem dimensionar recursos horizontal ou verticalmente e usar um balanceador de carga para rotear solicitações para os recursos disponíveis mais próximos. Esta página se aprofunda mais no motivo pelo qual, em um grande datacenter ou aplicativo de nuvem, é importante minimizar a latência de todas as solicitações e não apenas otimizar para o caso geral. Estudaremos como mesmo algumas exceções de alta latência podem prejudicar significativamente o desempenho observado de um sistema grande. Esta página também aborda várias técnicas para criar serviços que fornecem respostas previsíveis de baixa latência, mesmo que os componentes individuais não garantam isso. Esse é um problema especialmente significativo para aplicativos interativos em que a latência desejada para uma interação está abaixo de 100 ms.
O que é a latência de cauda?
A maioria dos aplicativos de nuvem são sistemas grandes e distribuídos que geralmente dependem da paralelização para reduzir a latência. Uma técnica comum é espalhar uma solicitação recebida em um nó raiz (por exemplo, um servidor Web front-end) para vários nós folha (servidores de computação de back-end). A melhoria de desempenho é impulsionada pelo paralelismo da computação distribuída e também pelo fato de que os custos de movimentação de dados extremamente caros são evitados. Simplesmente movemos a computação para o local onde os dados são armazenados. É claro que cada nó folha opera simultaneamente em centenas ou até milhares de solicitações paralelas.
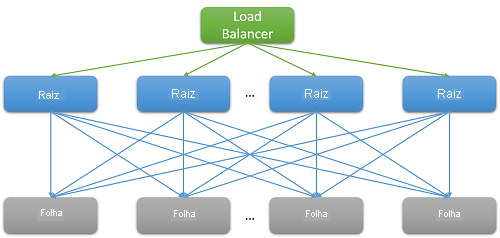
Figura 7: Latência devido à expansão
Considere o exemplo de pesquisa de um filme na Netflix. À medida que um usuário começa a digitar na caixa de pesquisa, isso gerará vários eventos paralelos do servidor Web raiz. No mínimo, esses eventos incluem as seguintes solicitações:
- Para o mecanismo de preenchimento automático, para de fato prever a pesquisa que está sendo feita com base nas últimas tendências e no perfil do usuário.
- Para o mecanismo de correção, que encontra erros na consulta digitada com base em um modelo de linguagem constantemente adaptado.
- Resultados de pesquisa individuais para cada uma das palavras componentes de uma consulta de várias palavras, que devem ser combinadas com base na classificação e relevância dos filmes.
- Pós-processamento e filtragem adicionais de resultados para atender às preferências de "pesquisa segura" do usuário.
Esses exemplos são extremamente comuns. Uma única solicitação do Facebook é conhecida por contatar milhares de servidores memcached, enquanto uma única pesquisa do Bing geralmente contata mais de dez mil servidores de índice.
Claramente, a necessidade de escala levou a uma grande distribuição no back-end para cada solicitação individual atendida pelo front-end. Para serviços que devem ser "responsivos" para manter sua base de usuários, a heurística mostra que as respostas são esperadas dentro de 100 ms. Conforme o número de servidores necessários para resolver uma consulta aumenta, o tempo total frequentemente depende da resposta com pior desempenho de um nó folha para um nó raiz. Supondo que todos os nós folha devem concluir a execução antes que um resultado possa ser retornado, a latência geral sempre deve ser maior do que a latência do componente mais lento.
Assim como a maioria dos processos estocásticos, o tempo de resposta de único nó folha pode ser expresso como uma distribuição. Décadas de experiência mostraram que, no caso geral, a maioria (>99%) solicitações de um sistema de nuvem bem configurado será executada extremamente rapidamente. Mas, muitas vezes, há muito poucas exceções em um sistema que são executados extremamente lentamente.
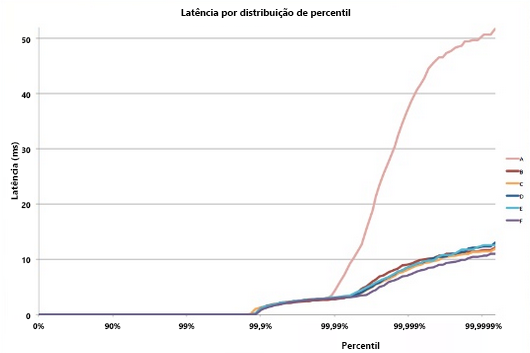
Figura 8: Exemplo de latência de cauda5
Considere um sistema em que todos os nós folha têm um tempo médio de resposta de 1 ms, mas há uma probabilidade de 1% de que o tempo de resposta seja maior que 1.000 ms (um segundo). Se cada consulta for tratada por apenas um nó folha, a probabilidade da consulta levar mais de um segundo também será de 1%. No entanto, quando aumentamos o número de nós para 100, a probabilidade de que a consulta seja concluída dentro de um segundo cai para 36,6%, o que significa que há uma chance de 63,4% de que a duração da consulta seja determinada pela cauda (1% mais baixo) da distribuição de latência.
$(.99^{100})$
Se simularmos isso para uma variedade de casos, veremos que, à medida que o número de servidores aumenta, o impacto de uma única consulta lenta é mais pronunciado (observe que o grafo abaixo está aumentando monotonicamente). Além disso, como a probabilidade dessas exceções diminui de 1% para 0,01%, o sistema é substancialmente menor.
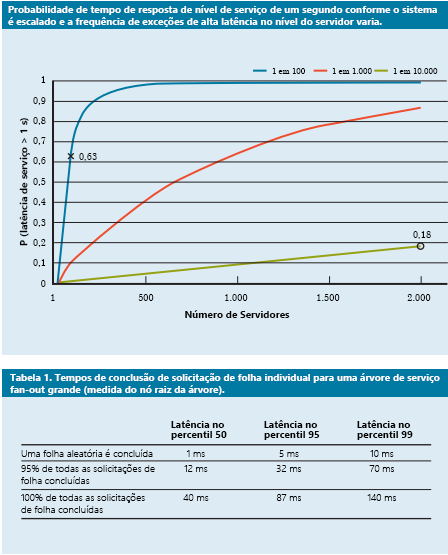
Figura 9: Estudo recente da probabilidade de tempo de resposta que mostra os percentis 50, 95 e 99 para latência das solicitações4
Assim como projetamos nossos aplicativos para serem tolerantes a falhas, lidando com problemas de confiabilidade de recursos, agora deve estar claro por que é importante que os aplicativos sejam "tolerantes a atraso". Para conseguir isso, devemos entender as fontes dessas variabilidades prolongadas no desempenho e identificar mitigações sempre que possível e soluções alternativas onde não for possível.
Variabilidade na nuvem: fontes e mitigações
Para resolver a variabilidade do tempo de resposta que leva a esse problema de latência de cauda, precisamos compreender as fontes da variabilidade de desempenho.1
- Uso de recursos compartilhados: muitas VMs diferentes (e aplicativos dentro dessas VMs) exigem um pool compartilhado de recursos de computação. Em casos raros, é possível que essa contenção leve a uma baixa latência para algumas solicitações. Para tarefas críticas, pode fazer sentido usar instâncias dedicadas e executar benchmarks periodicamente quando ociosas, para garantir que elas se comportem corretamente.
- Daemons em segundo plano e manutenção: já falamos sobre a necessidade de processos em segundo plano criarem pontos de verificação, criarem backups, atualizarem logs, coletarem lixo e manipularem a limpeza de recursos. No entanto, isso pode prejudicar o desempenho do sistema durante a execução. Para atenuar isso, é importante sincronizar interrupções devido a processos de manutenção para minimizar o impacto no fluxo de tráfego. Isso fará com que toda a variação ocorra em uma janela curta e conhecida, em vez de aleatoriamente durante o tempo de vida do aplicativo.
- Enfileiramento: Outra fonte comum de variabilidade é a intermitência dos padrões de chegada de tráfego.1 Essa variabilidade será exacerbada se o sistema operacional usar um algoritmo de agendamento diferente do PEPS. Os sistemas Linux geralmente agendam threads fora de ordem para otimizar a taxa de transferência geral e maximizar a utilização do servidor. Estudos descobriram que o uso do agendamento FIFO no sistema operacional reduz a latência final ao custo de reduzir a taxa de transferência geral do sistema.
- Incast de todos para todos: O padrão mostrado na Figura 8 acima é conhecido como comunicação de todos para todos. Como a maior parte da comunicação de rede é por TCP, isso leva a milhares de solicitações e respostas simultâneas entre o servidor Web front-end e todos os nós de processamento de back-end. Esse é um padrão extremamente intermitente de comunicação que, muitas vezes, leva a um tipo especial de falha de congestionamento conhecido como colapso de incast TCP.1, 2 A resposta intensa e repentina de milhares de servidores leva muitos pacotes a serem descartados e retransmitidos, eventualmente causando uma avalanche de tráfego de rede para pacotes de dados muito pequenos. Grandes datacenters e aplicativos de nuvem geralmente precisam usar drivers de rede personalizados para ajustar dinamicamente a janela de recebimento TCP e o temporizador de retransmissão. Os roteadores também podem ser configurados para remover o tráfego que excede uma taxa específica e reduzir o tamanho do envio.
- Gerenciamento de energia e temperatura: por fim, a variabilidade é um subproduto de outras técnicas de redução de custos, como o uso de estados ociosos ou redução de frequência de CPU. Um processador pode, muitas vezes, dedicar uma quantidade de tempo não trivial a escalar verticalmente de um estado ocioso. Desativar essas otimizações de custo leva a maiores custos e uso de energia, mas menor variabilidade. Isso é menos um problema na nuvem pública, pois os modelos de preços raramente consideram as métricas de utilização interna dos recursos do cliente.
Alguns experimentos encontraram que a variabilidade desses sistemas é muito pior na nuvem pública,3 frequentemente devido ao isolamento de desempenho imperfeito dos recursos virtuais e do processador compartilhado. Isso será exacerbado se muitos trabalhos sensíveis à latência forem executados no mesmo nó físico que trabalhos com uso intensivo de CPU.
Vivendo com variabilidade: soluções de engenharia
Muitas das fontes de variabilidade acima não têm uma solução infalível. Portanto, em vez de tentar tratar de todas as fontes que ampliam a latência de cauda, os aplicativos de nuvem devem ser projetados de maneira a serem tolerantes a essa latência. Isso, é claro, é semelhante à maneira como projetamos aplicativos para serem tolerantes a falhas, pois não podemos esperar corrigir todas as falhas possíveis. Algumas das técnicas comuns para lidar com essa variabilidade são:
- Resultados "bons o suficiente": muitas vezes, quando o sistema está esperando para receber resultados de milhares de nós, a importância de qualquer resultado único pode ser considerada bastante baixa. Portanto, muitos aplicativos podem optar por simplesmente responder aos usuários com resultados que chegam em uma janela de latência específica e curta e descartar o restante.
- Canários: outra alternativa que costuma ser usada para caminhos de código raros é testar uma solicitação em um pequeno subconjunto de nós folha para testar se isso causa falhas que podem afetar todo o sistema. A consulta do tipo fan-out completa será gerada somente se o canário não causar uma falha. Isso é semelhante a enviar um canário (pássaro) para uma mina de carvão para testar se é seguro para os humanos.
- Verificações de integridade e sondagens induzidas pela latência: é claro que grande parte das solicitações para um sistema são comuns demais para testar usando um canário. É mais provável que essas solicitações tenham uma latência de cauda maior se um dos nós folha estiver apresentando mau desempenho. Para combater isso, o sistema deve monitorar periodicamente a integridade e a latência de cada nó folha e não rotear solicitações para nós que demonstram baixo desempenho (devido a falhas ou manutenção).
- QoS diferencial: classes de serviço separadas podem ser criadas para solicitações interativas, permitindo que elas sejam priorizadas em qualquer fila. Aplicativos que não diferenciam latência podem tolerar tempos de espera mais longos para suas operações.
- Cobertura de solicitação: Essa é uma solução simples para reduzir o impacto da variabilidade encaminhando a mesma solicitação para várias réplicas e usando a resposta que chegar primeiro. Claro, isso pode dobrar ou triplicar a quantidade de recursos necessários. Para reduzir o número de solicitações em espera, a segunda requisição poderá ser enviada somente se a primeira resposta estiver pendente por mais do que o 95º percentil da latência esperada para essa requisição. Isso faz com que a carga extra seja apenas cerca de 5%, mas reduz a cauda da latência de maneira significativa (no caso típico mostrado na Figura 9, em que a latência do 95º percentil é muito menor do que a latência do 99º percentil).
- Execução especulativa e replicação seletiva: tarefas em nós que estão particularmente ocupados podem ser enviadas especulativamente para outros nós folha subutilizados. Isso será eficaz especialmente se uma falha em um nó específico fizer com que ele fique sobrecarregado.
- Soluções baseadas em UX: por fim, o atraso pode ser inteligentemente oculto do usuário por meio de uma interface de usuário bem projetada que reduz a sensação de atraso experimentado por um usuário humano. As técnicas para fazer isso podem incluir o uso de animações, mostrar resultados iniciais ou envolver o usuário enviando mensagens relevantes.
Usando essas técnicas, é possível melhorar significativamente a experiência dos usuários finais de um aplicativo de nuvem para resolver o problema peculiar de uma cauda longa.
Referências
- Li, J., Sharma, N. K., Ports, D. R., &Gribble, S. D. (2014). Tales of the Tail: Fontes de hardware, sistema operacional e nível de aplicativo de latência final do Proceedings of the ACM Symposium on Cloud Computing, ACM
- Wu, Haitao e Feng, Zhenqian e Guo, Chuanxiong e Zhang, Yongguang (2013). ICTCP: Incast Congestion Control for TCP in Data-Center Networks, IEEE/ACM Transactions on Networking (TON), IEEE Press
- Xu, Yunjing e Musgrave, Zachary e Noble, Brian e Bailey, Michael (2013). Bontail: Avoiding Long Tails in the Cloud, 10ª Conferência da USENIX sobre Design e Implementação de Sistemas em Rede, USENIX Association
- Dean, Jeffrey e Barroso, Luiz André (2013). The tail at scale, Comunicações da ACM, ACM
- Tene, Gil (2014). [Noções básicas sobre latência - algumas lições e ferramentas importantes](https://www.infoq.com/presentations/latency-lessons-tools/, QCon London