Estudo de caso: HDFS (Sistema de Arquivos Distribuído do Hadoop)
O modelo de programação MapReduce permite que trabalhos computacionais sejam estruturados de acordo com duas funções: mapear e reduzir. A entrada de dados será inserida como pares de chave-valor no MapReduce, onde, a seguir, será processada por meio de uma função de mapa e inserida em uma função de redução. A operação de redução produzirá um resultado que também estará na forma de pares chave-valor. A MapReduce foi projetada para executar várias instâncias do mapa e operações de redução de maneira paralela em um grande cluster computacional. O modelo de programação MapReduce será detalhado em um módulo posterior.
O modelo de programação MapReduce assume a disponibilidade de um sistema de armazenamento distribuído que está disponível em todos os nós do cluster com um namespace, o local de entrada de um DFS (sistema de arquivos distribuído). Um DFS será colocado com os nós do cluster MapReduce. O DFS foi projetado para funcionar em conjunto com a MapReduce e mantém um namespace para todo o cluster MapReduce.
Uma versão de software livre do MapReduce, chamada Apache Hadoop2, é muito popular nos círculos de Big Data. O HDFS é um DFS de software livre. O HDFS foi projetado para ser um sistema de arquivos distribuído, escalonável e tolerante a falhas que atende principalmente às necessidades do modelo de programação MapReduce. O vídeo 4.12 apresentará o HDFS.
É importante observar que o HDFS não está em conformidade com o POSIX e não é um sistema de arquivos montável por conta própria. O acesso ao HDFS geralmente é por meio de clientes HDFS ou usando chamadas à API (interface de programação de aplicativo) de bibliotecas do Hadoop. No entanto, o desenvolvimento de um driver FUSE (Sistema de Arquivos no Espaço do Usuário) para o HDFS permite que ele seja montado como um dispositivo virtual em sistemas operacionais UNIX.
Arquitetura HDFS
Conforme descrito anteriormente, o HDFS é um DFS projetado para ser executado em um cluster de nós e é arquitetado com as seguintes metas:
- Um namespace único e comum em todo o cluster
- Capacidade para armazenar arquivos grandes (terabytes ou petabytes)
- Suporte para o modelo de programação MapReduce
- Acesso a dados de streaming para padrões de acesso a dados de gravação única e muitas leituras
- Alta disponibilidade usando um hardware de commodities
Um cluster HDFS será ilustrado na seguinte figura:

Figura 1: arquitetura HDFS
O HDFS segue um design subordinado ao mestre. O nó mestre é chamado de NameNode. O NameNode lida com o gerenciamento de metadados para todo o cluster e mantém um namespace para todos os arquivos armazenados no HDFS. Os nós subordinados são conhecidos como DataNodes. Os DataNodes armazenam blocos de dados reais no sistema de arquivos local em cada nó.
Os arquivos são divididos em blocos no HDFS, também chamados de partes, com um tamanho padrão de 128MB cada. Por outro lado, os sistemas de arquivos locais normalmente têm tamanhos de blocos de cerca de 4KB. O HDFS usa tamanhos de bloco grandes porque foi projetado para armazenar arquivos extremamente grandes de uma forma que seja eficiente para processar com trabalhos do MapReduce.
Uma tarefa de mapa na MapReduce será configurada por padrão para funcionar em um bloco do HDFS de maneira independente. Portanto, várias tarefas de mapa poderão processar vários blocos do HDFS em paralelo. Se o tamanho do bloco for muito pequeno, um grande número de tarefas de mapa precisará ser distribuído entre os nós do cluster e a sobrecarga resultante poderá afetar o desempenho negativamente. Por outro lado, caso o bloco seja muito grande, o número de tarefas de mapa que poderão processar o arquivo em paralelo será reduzido, afetando assim o paralelismo. O HDFS permite que os tamanhos dos blocos sejam específicos por arquivo para que os usuários possam ajustar o tamanho do bloco para atingir o nível de paralelismo desejado. A interação entre MapReduce e HDFS será detalhada em um módulo posterior.
Além disso, como o HDFS foi projetado para tolerar falhas de nós individuais, os blocos de dados serão replicados entre os nós para fornecer uma redundância de dados. Esse processo será detalhado nas seções a seguir.
Topologia de cluster no HDFS
Os clusters Hadoop normalmente são implantados em um data center que é composto por vários racks de servidores conectados usando uma topologia de árvore FAT, conforme discutido em um módulo anterior. Para que isso ocorra, o HDFS foi projetado para levar em conta uma topologia de cluster que ajuda a tomar decisões quanto ao posicionamento de blocos de modo a influenciar o desempenho e a tolerância a falhas. Os clusters Hadoop comuns têm cerca de 30 a 40 servidores por rack, com um comutador de gigabit dedicado ao rack e um uplink para o comutador ou roteador principal com largura de banda compartilhada entre vários racks no data center, conforme mostrado na seguinte figura:

Figura 2: topologia do cluster HDFS
A questão fundamental a ser observada é que o Hadoop pressupõe que a largura de banda agregada dentro dos nós em um rack é maior do que a largura de banda agregada entre os nós em diferentes racks. Essa suposição foi projetada no design do Hadoop quando se trata de acesso a dados e posicionamento de réplica, que serão discutido nas seções a seguir.
Quando o HDFS for implantado em um cluster, os administradores do sistema poderão configurá-lo com uma descrição de topologia que mapeia cada nó para um rack específico no cluster. A distância da rede será medida em saltos, em que um salto corresponde a um link na topologia. O Hadoop assume uma topologia no estilo de árvore e a distância entre dois nós será a soma das distâncias dos predecessores comuns mais próximos.
No exemplo da Figura 2, a distância entre o Nó 1 e ele próprio é de zero saltos, situação em que dois processos estão se comunicando no mesmo nó. A distância entre o Nó 1 e o Nó 2 é de dois saltos, enquanto a distância entre o Nó 3 e o Nó 4 é de quatro saltos.
O vídeo a seguir mostrará as operações de leitura e gravação de arquivo no HDFS.

Figura 3: leituras de arquivo no HDFS
A Figura 3 ilustra o processo de leitura de um arquivo no HDFS. Um cliente HDFS, a entidade que precisa acessar um arquivo, primeiro entra em contato com o NameNode quando um arquivo for aberto para leitura. O NameNode fornece ao cliente uma lista de locais de blocos do arquivo. O Hadoop também pressupõe que os blocos serão replicados entre os nós, de modo que o NameNode localizará o bloco mais próximo do cliente ao fornecer a localização de um bloco específico. A localidade será determinada na seguinte ordem de redução da localidade: blocos no mesmo nó que o cliente, blocos no mesmo rack que o cliente e blocos que estão fora do rack do cliente.
Depois que os locais do bloco forem determinados, o cliente abrirá uma conexão direta para cada DataNode e transmitirá os dados do DataNode para o processo do cliente, o que será feito quando o cliente HDFS invocar a operação de leitura no bloco de dados. Portanto, o bloco não precisará ser integralmente transferido antes que o cliente possa iniciar a computação, intercalando, assim, a computação e a comunicação. Após terminar de ler o primeiro bloco, o cliente repetirá esse processo com os blocos restantes até que o cliente tenha terminado de ler todos os blocos. Em seguida, prosseguirá para o fechamento do arquivo.
É importante observar que os clientes entram em contato com o DataNode diretamente para recuperar dados. Esse contato permite que o HDFS seja dimensionado para um grande número de clientes ao mesmo tempo para obter leituras paralelas e simultâneas de dados.
As gravações de arquivo são diferentes das leituras de arquivo no HDFS (Figura 4). Um cliente que precisa gravar dados no HDFS primeiro entrará em contato com o NameNode e fará uma notificação sobre a criação de um arquivo. O NameNode verificará se o arquivo já existe e se o cliente tem permissão para criar um arquivo. Caso as verificações sejam aprovadas, o NameNode fará o registro de um novo arquivo.

Figura 4: gravações de arquivo no HDFS
O cliente prosseguirá com a gravação do arquivo em uma fila de dados interna e solicitará o NameNode para locais de blocos em DataNodes no cluster. Os blocos na fila interna serão transferidos para DataNodes individuais na forma de pipeline. O bloco será gravado no primeiro DataNode que usará um pipeline no bloco para outros DataNodes a fim de gravar réplicas do bloco. Portanto, os blocos serão replicados durante a própria gravação do arquivo. É importante observar que o HDFS não reconhecerá uma gravação no cliente (etapa 5 da Figura 4.28) até que todas as réplicas desse arquivo tenham sido gravadas pelos DataNodes.
O Hadoop também usará a noção de localidade do rack durante o posicionamento da réplica. Os blocos de dados serão replicados três vezes no HDFS por padrão. O HDFS tentará posicionar a primeira réplica no mesmo nó do cliente que está gravando o bloco. Se o processo do cliente não estiver em execução no cluster do HDFS, um nó será escolhido aleatoriamente. A segunda réplica será gravada em um nó que estará em um rack diferente do primeiro (fora do rack). A terceira réplica do bloco será gravada em outro nó aleatório no mesmo rack que o segundo. Réplicas adicionais serão gravadas em nós aleatórios no cluster, porém o sistema tentará evitar colocar muitas réplicas no mesmo rack. A Figura 5 ilustra o posicionamento da réplica para um bloco com replicação tripla no HDFS. A lógica por trás do posicionamento da réplica do HDFS é poder tolerar falhas de nós e racks. Por exemplo, quando um rack inteiro ficar offline devido a problemas de energia ou de rede, o bloco solicitado ainda poderá ser localizado em um rack diferente.
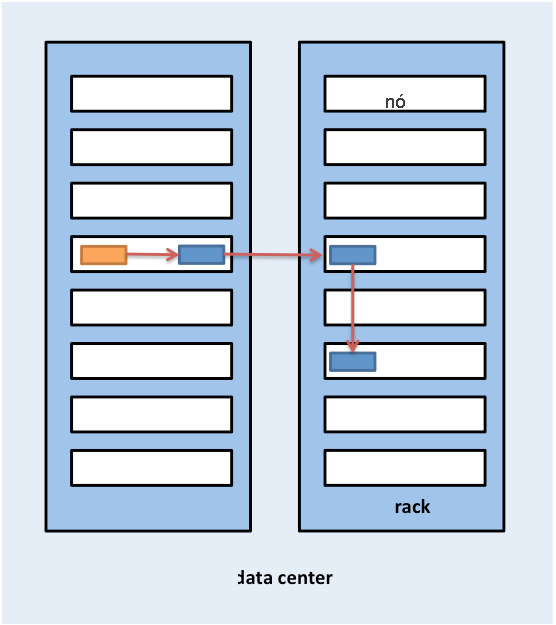
Figura 5: posicionamento de réplica para um bloco com replicação tripla no HDFS
Sincronização: semântica
A semântica do HDFS mudou um pouco. As versões anteriores do HDFS seguiram uma semântica imutável estrita. Depois de ser gravado nas versões anteriores do HDFS, um arquivo nunca mais poderá ser reaberto para gravações. Os arquivos ainda poderão ser excluídos. No entanto, as versões atuais do HDFS são compatíveis com acréscimos de maneira limitada. Tudo isso ainda é bastante limitado, no sentido de que os dados binários existentes já gravados no HDFS não podem ser modificados no local.
Essa opção de design foi feita no HDFS porque algumas das cargas de trabalho de MapReduce mais comuns seguem o padrão de acesso a dados de gravação única e muitas leituras. MapReduce é um modelo computacional restrito com estágios predefinidos e saídas de redutores em arquivos independentes de gravação de MapReduce para HDFS como saída. O HDFS se concentra nos acessos de leitura rápidos e simultâneos para vários clientes de cada vez.
Modelo de consistência
O HDFS é um sistema de arquivos fortemente coerente. Cada bloco de dados é replicado para vários nós, porém uma gravação é declarada como bem-sucedida somente depois que todas as réplicas tiverem sido gravadas com êxito. Assim, todos os clientes devem ver o arquivo assim que for gravado e sua exibição será a mesma para todos os clientes. A semântica imutável do HDFS torna esse processo comparativamente fácil de implementar, pois um arquivo pode ser aberto para gravação apenas uma vez durante todo o tempo de vida.
Tolerância a falhas no HDFS
O principal mecanismo de tolerância a falhas no HDFS é a replicação. Conforme mostrado anteriormente, todos os blocos gravados no HDFS são replicados três vezes por padrão, porém isso poderá ser alterado pelos usuários por arquivo, se necessário.
O NameNode mantém o controle dos DataNodes por meio de um mecanismo de pulsação. Cada DataNode envia mensagens de pulsação periódicas, em questão de segundos, para o NameNode. Caso um DataNode se torne inativo, as pulsações para o NameNode são interrompidas. O NameNode detectará que um DataNode está inativo se o número de mensagens de pulsação perdidas atingir um determinado limite. O NameNode então marcará o DataNode como inativo e não encaminhará mais nenhuma solicitação de E/S para esse DataNode. Os blocos armazenados nesse DataNode deverão ter réplicas adicionais em outros DataNodes. Além disso, o NameNode fará uma verificação de status no sistema de arquivos para encontrar blocos com replicação insuficiente e executará um processo de reequilíbrio de cluster para iniciar a replicação para os blocos que tiverem menos do que o número desejado de réplicas.
O NameNode é um ponto único de falha (SPOF) no HDFS porque uma falha do NameNode fará com que todo o sistema de arquivos seja desativado. Internamente, o NameNode mantém duas estruturas de dados em disco que armazenam o estado do sistema de arquivos: um arquivo de imagem e um log de edição. O arquivo de imagem é um ponto de verificação dos metadados do sistema de arquivos no tempo, enquanto o log de edição é um log de todas as transações dos metadados do sistema de arquivos desde a última criação do arquivo de imagem. Todas as alterações de entrada nos metadados do sistema de arquivos serão gravadas no log de edição. Os logs de edição e os arquivos de imagem são mesclados em intervalos periódicos para criar um novo instantâneo do arquivo de imagem e o log de edição é removido. No entanto, em caso de falha do NameNode, os metadados não ficariam disponíveis e uma falha de disco no NameNode seria catastrófica, pois os metadados do arquivo seriam perdidos.
Para fazer backup dos metadados no NameNode, o HDFS permite a criação de um NameNode secundário que copia periodicamente os arquivos de imagem do NameNode. Essas cópias ajudam a recuperar o sistema de arquivos em caso de perda de dados no NameNode, mas, nesse caso, as últimas alterações que estivessem no log de edição do NameNode seriam perdidas. O trabalho contínuo nas versões mais recentes do Hadoop visa criar um verdadeiro NameNode secundário superabundante que assumiria automaticamente em caso de falha do NameNode.
O HDFS na prática
Embora o HDFS tenha sido projetado principalmente para ser compatível com os trabalhos de MapReduce do Hadoop, fornecendo um DFS para operações de mapeamento e redução, o HDFS encontrou uma infinidade de usos com ferramentas de Big Data.
O HDFS é usado em vários projetos do Apache criados sobre a estrutura do Hadoop, incluindo Pig, Hive, HBase e Giraph. O suporte ao HDFS também está incluído em outros projetos, como o GraphLab.
As principais vantagens do HDFS incluem o seguinte:
- Alta largura de banda para cargas de trabalho MapReduce: grandes clusters Hadoop (milhares de computadores) são conhecidos por gravar de maneira contínua em 1 terabyte por segundo usando o HDFS.
- Alta confiabilidade: A tolerância a falhas é uma das principais metas de design no HDFS. A replicação do HDFS fornece alta confiabilidade e disponibilidade, especialmente em grandes clusters, nos quais a probabilidade de falhas de disco e servidor aumenta de maneira significativa.
- Baixo custo por byte: Quando comparado a uma solução dedicada de disco compartilhado, como a SAN, o HDFS custa menos por gigabyte porque o armazenamento é colocado em servidores de computação. Com a SAN é necessário pagar custos adicionais para obter uma infraestrutura gerenciada, como o compartimento de matriz de discos e os discos corporativos de maior nível a fim de gerenciar falhas no hardware. O HDFS foi projetado para ser executado com hardwares de commodities e a redundância é gerenciada no software para tolerar falhas.
- Escalabilidade: O HDFS permite que DataNodes sejam adicionados a um cluster em execução e oferece ferramentas para reequilibrar blocos de dados manualmente quando nós de cluster forem adicionados, o que pode ser feito sem desligar o sistema de arquivos.
As principais desvantagens do HDFS incluem o seguinte:
- Ineficiências de arquivos pequenos: O HDFS foi projetado para ser usado com tamanhos grandes de bloco (de 64MB e maiores). Sua função é pegar arquivos grandes (com centenas de megabytes, gigabytes ou terabytes) e agrupá-los em blocos que, a seguir, podem ser inseridos nos trabalhos do MapReduce para um processamento paralelo. O HDFS será ineficiente quando os tamanhos reais do arquivo forem pequenos (no intervalo de quilobytes). Ter um grande número de arquivos pequenos aumenta o estresse do NameNode que tem de manter metadados para todos os arquivos no sistema de arquivos. Os usuários do HDFS normalmente combinam muitos arquivos pequenos com outros maiores usando técnicas como arquivos de sequência.
- Não conformidade com o POSIX: O HDFS não foi projetado para ser um sistema de arquivos montável em conformidade com o POSIX. Os aplicativos precisam ser gravados a partir do zero ou modificados para usar um cliente de HDFS. Existem soluções alternativas que permitem que o HDFS seja montado usando um driver FUSE, porém a semântica do sistema de arquivos não permite gravações nos arquivos após terem sido fechados.
- Modelo de gravação única: O modelo de gravação única é uma possível desvantagem para aplicativos que exigem acessos simultâneos de gravação no mesmo arquivo. No entanto, a versão mais recente do HDFS já é compatível com acréscimos de arquivo.
Em resumo, o HDFS é uma boa opção como um back-end de armazenamento para aplicativos distribuídos que seguem o modelo do MapReduce ou foram escritos especificamente para usar o HDFS. O HDFS pode ser usado de maneira eficiente com um pequeno número de arquivos grandes, em vez de um grande número de arquivos pequenos.
Referências
- Sanjay Ghemawat, Howard Gobioff e Shun-Tak Leung (2003). The Google File Systems 19th ACM Symposium on Operating Systems Principles
- White, Tom (2012). Hadoop: The Definitive Guide O'Reilly Media, Yahoo Press