Por que usar a programação distribuída?
Várias técnicas analíticas nos níveis do algoritmo e do código são capazes de identificar o paralelismo potencial em programas sequenciais1 e, em princípio, todo programa sequencial pode ser paralelizado. Um programa pode ser dividido em partes seriais e paralelas, como mostra a Figura 3. As partes paralelas podem ser executadas simultaneamente em apenas um computador ou podem ser distribuídas entre computadores. Normalmente, os programadores transformam programas sequenciais em versões paralelas principalmente para obter uma maior velocidade computacional ou taxa de transferência. Idealmente, paralelizar um programa sequencial em um programa distribuído em n partes produziria uma diminuição de n vezes do tempo de execução. O uso de programas distribuídos em vez de programas sequenciais é crucial para vários domínios, especialmente o da ciência. Por exemplo, a simulação do enovelamento de apenas uma proteína pode levar anos quando executada em sequência, mas apenas dias quando executada em paralelo. O ritmo da descoberta científica em alguns domínios depende da rapidez com que determinados problemas científicos podem ser resolvidos. Além disso, alguns programas têm restrições de tempo real em que, se a computação não é executada com rapidez suficiente, o programa inteiro é inutilizado. Por exemplo, a previsão da direção de furacões e tornados usando modelagem climática deve ser feita em tempo hábil, caso contrário, a previsão será desperdiçada. Na realidade, cientistas e engenheiros se baseiam há décadas em programas distribuídos para resolver problemas científicos importantes e complexos, como mecânica quântica, simulações físicas, previsão do tempo, exploração de gás e petróleo e modelagem molecular, para mencionar alguns. Essa tendência provavelmente continuará, pelo menos no futuro próximo.
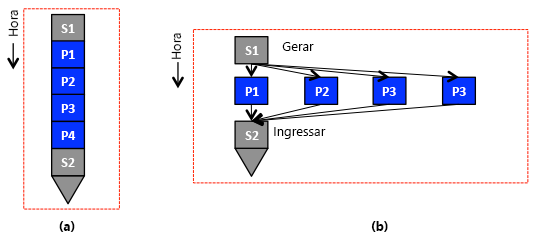
Figura 3: (a) Um programa sequencial com peças serial (S1) e paralela (P1). (b) Um programa paralelo/distribuído que corresponde ao programa sequencial em (a), em que as partes paralelas podem ser distribuídas entre computadores ou executadas simultaneamente em um único computador.
Os programas distribuídos também encontraram aplicações amplas além da ciência, como em mecanismos de pesquisa, servidores Web e bancos de dados. Um exemplo é o projeto Folding@Home que usa a computação distribuída em todos os tipos de sistemas, de supercomputadores a PCs pessoais, para executar simulações de dinâmica molecular da dinâmica de proteínas. Sem a paralelização, o Folding@Home não poderia acessar quase nenhum recurso computacional. Por exemplo, a execução de um programa MapReduce2 do Hadoop em apenas uma instância de VM não é tão eficaz quanto a execução em um cluster de grande escala de instâncias de VM. É claro que confirmar os trabalhos inicialmente na nuvem leva à redução de custos, que é um objetivo fundamental dos usuários de nuvem.
Os programas distribuídos também ajudam a reduzir gargalos de subsistemas. Por exemplo, dispositivos de E/S, como discos e placas de adaptador de rede, normalmente representam grandes gargalos em termos de largura de banda, desempenho e/ou taxa de transferência. Com a distribuição do trabalho entre diversos computadores, os dados podem ser fornecidos por vários discos simultaneamente, oferecendo uma maior largura de banda de E/S agregada, aprimorando o desempenho e maximizando a taxa de transferência. Em resumo, os programas distribuídos desempenham um papel crítico na solução rápida de vários problemas de computação e na mitigação efetiva de gargalos de recursos. Isso aprimora o desempenho, aumenta a taxa de transferência e reduz custos, especialmente na nuvem.
Referências
- Y. Solihin (2009). Conceitos básicos da arquitetura do computador paralelo Livros de Solihin
- Apache Hadoop