Tipos de paralelismo
- 11 minutos
Um segundo aspecto a ser considerado no desenvolvimento de programas distribuídos envolve a especificação do tipo de paralelismo: de dados ou de grafos. O design com paralelismo de dados enfatiza a natureza distribuída dos dados e os espalha entre vários computadores. A computação, enquanto isso, pode permanecer a mesma entre todos os nós e pode ser aplicada a dados diferentes. Como alternativa, tarefas em computadores diferentes podem executar diferentes tarefas computacionais. Quando as tarefas são idênticas, classificamos o programa distribuído como programa único, dados múltiplos (SPMD); caso contrário, categorizamos como programas múltiplos, dados múltiplos (MPMD).
A ideia básica do paralelismo de dados é simples: distribuindo um arquivo grande em vários computadores, torna-se possível acessar e processar diferentes partes do arquivo em paralelo. Conforme discutido em um módulo anterior, uma técnica popular de distribuição de dados é a divisão de arquivo, em que um arquivo é particionado e distribuído entre vários servidores. Outra forma de paralelismo de dados é distribuir arquivos inteiros (sem particionamento) entre computadores, especialmente quando os arquivos são pequenos e os dados contidos neles exibem estruturas muito irregulares. Observe que os dados podem ser distribuídos entre tarefas distribuídas de maneira explícita, usando a passagem de mensagem, ou implícita, usando a memória compartilhada, supondo que o sistema distribuído subjacente tenha suporte para memória compartilhada.
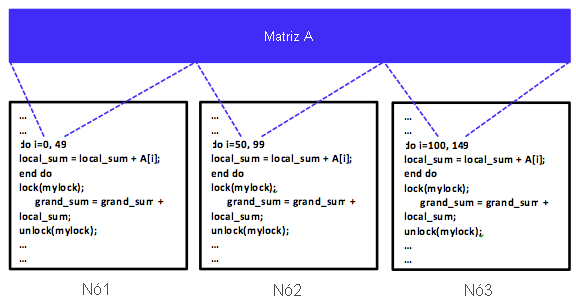
Figura 9: um programa distribuído do SPMD usando o modelo de programação de memória compartilhada
O paralelismo de dados é obtido quando cada nó executa uma ou várias tarefas em diferentes partes dos dados distribuídos. Em um exemplo específico, suponha que a matriz A seja compartilhada entre três computadores em um sistema distribuído de memória compartilhada. Considere também um programa distribuído que apenas adiciona todos os elementos da matriz A. É possível instruir os computadores 1, 2 e 3 a executarem a tarefa de adição, cada um deles em um terço dos elementos da matriz A ou em 50 elementos, como mostra a Figura 9. Os dados podem ser alocados entre tarefas usando o modelo de programação de memória compartilhada, que exige um mecanismo de sincronização. Claramente, trata-se de um programa SPMD. Por outro lado, a matriz A também pode ser distribuída de maneira uniforme (usando a passagem de mensagem) por uma tarefa (mestre) entre três computadores, incluindo o computador do mestre, como mostra a Figura 10. Cada computador executará a tarefa de adição de maneira independente; no entanto, eventualmente os resultados do somatório precisarão ser agregados na tarefa mestre para gerar um total geral. Nesse cenário, todas as tarefas são semelhantes no sentido de que estão executando a mesma operação de adição, ainda que em uma parte diferente da matriz A. A tarefa mestre, no entanto, também está distribuindo dados para todas as tarefas e agregando os resultados do somatório, o que a diferencia ligeiramente das outras duas tarefas. Claramente, isso faz com que o programa seja do tipo MPMD. Como abordaremos em uma unidade posterior sobre o MapReduce, ele usa o paralelismo de dados com programas MPMD.
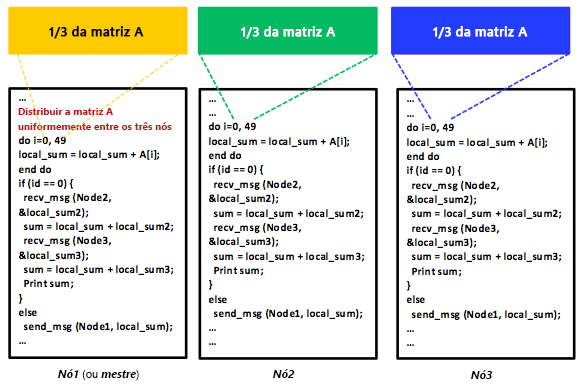
Figura 10: um programa distribuído do MPMD usando o modelo de programação de passagem de mensagens
O paralelismo do grafo, por outro lado, concentra-se na distribuição da computação em oposição aos dados. Na verdade, a maioria dos programas distribuídos se encaixa em algum ponto do continuum entre os dois tipos. O paralelismo de grafos é amplamente utilizado em muitos domínios, como aprendizado de máquina, mineração de dados, física e design de circuitos eletrônicos. Muitos problemas nesses domínios podem ser modelados como grafos em que os vértices representam computações e as bordas codificam dependências ou comunicações de dados. Lembre-se de que um grafo $G$ é um par, $(V, E)$, em que $V$ é um conjunto finito de vértices e $E$ é um conjunto finito de relações emparelhadas, $E \subconjunto (V \vezes V)$, chamadas bordas. É possível associar pesos aos vértices e às bordas para indicar a quantidade de trabalho em cada vértice e os dados de comunicação em cada borda.
Considere um problema clássico do design de circuitos: a meta comum de manter determinados pinos de vários componentes eletricamente iguais conectando-os. Se presumirmos que há $n$ pinos, então um esquema com $(n-1)$ fios, cada um conectando dois pinos, poderá ser empregado. De todos os esquemas desse tipo, aquele que exige o número mínimo de fios normalmente é o mais desejável. Obviamente, esse problema de conexão pode ser modelado como um problema de grafo. Em particular, cada pino pode ser representado como um vértice e cada interconexão entre um par de pinos, $(u, v)$, pode ser representada como uma borda. Um peso, $w(u, v)$, pode ser definido entre $u$ e $v$ para codificar o custo (a quantidade de fios necessários) de conectar $u$ e $v$. O problema passa a ser como encontrar um subconjunto acíclico, $S$, de bordas, $E$, que conecta todos os vértices, $V$ e cujo peso total,
$$ w(S) = \Sigma_{(u, v)\in S} w(u, v) $$
é o mínimo.
Como $S$ é acíclico e totalmente conectado, ele deve resultar em uma árvore conhecida como árvore de expansão mínima. Consequentemente, a solução do problema de fiação se transforma na solução do problema da árvore de expansão mínima, um problema clássico que pode ser resolvido com algoritmos como o de Kruskal e o de Primname.
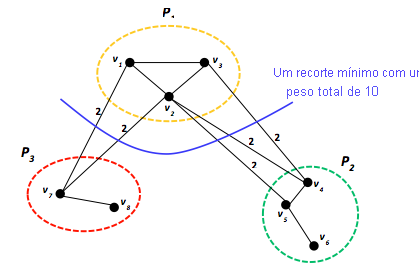
Figura 11: um grafo particionado usando a métrica de corte de borda
Uma vez modelado como um grafo, um programa pode ser distribuído entre os computadores em um sistema distribuído usando uma técnica de particionamento de grafo, que envolve dividir o trabalho (vértices) entre os nós distribuídos para ter uma computação distribuída eficiente. Assim como ocorre com o paralelismo de dados, a ideia básica é simples: ao distribuir um grafo grande entre vários computadores, passa a ser possível processar partes diferentes do grafo em paralelo, resultando em um design com grafos paralelos. O objetivo padrão do particionamento de grafos é distribuir o trabalho de maneira uniforme entre p processadores, particionando os vértices em p partições ponderadas igualmente, enquanto a comunicação entre nós refletida pelas bordas é minimizada. Esse objetivo normalmente é chamado de métrica de corte de borda padrão. Embora o problema de particionamento de grafos seja NP-difícil, a heurística pode alcançar soluções quase ideais. Em um exemplo específico, a Figura 11 demonstra três partições, $P_{1}$, $P_{2}$ e $P_{3}$, em que os vértices $ \lbrace v_{1}, \cdots, v_{8} \rbrace $ são divididos usando a métrica de corte de borda. Cada borda tem um peso de dois, que corresponde a uma unidade de dados comunicada em cada direção. Consequentemente, o peso total do corte de borda mostrado é 10. Outros cortes resultarão em mais tráfego de comunicação. Claramente, para aplicativos com uso intensivo de comunicação, o particionamento de grafos é crítico e pode desempenhar um papel considerável ao ditar o desempenho geral do aplicativo. Tanto o Pregel quanto o GraphLab empregam o particionamento de grafos. Discutiremos cada um deles com mais detalhes em unidades posteriores.
Referências
- T. H. Cormen, C. E. Leiserson, R. L. Rivest e C. Stein (31 de julho de 2009). Introdução aos algoritmos MIT Press, Terceira Edição
- B. Hendrickson e T. G. Kolda (2000). Modelos de particionamento de grafo para computação paralela Computação paralela
- M. R. Garey, D. S. Johnson e L. Stockmeyer (1976). Alguns problemas de grafo de NP-Complete simplificados Ciência teórica da computação
- B. Hendrickson e R. Leland (1995). Relatório Técnico do Guia do Usuário do Chaco versão 2.0 SAND95-2344, Laboratórios Nacionais da Sandia
- G. Karypis e V. Kumar (1998). Um esquema multinível rápido e de alta qualidade para particionamento de grafos irregulares SIAM Journal on Scientific Computing