Sistemas de processamento de fluxo
- 11 minutos
As estruturas que examinamos até agora (MapReduce, Spark, GraphLab) foram projetadas principalmente para executar computação em lotes. Em geral, suas entradas são grandes conjuntos de dados distribuídos, que são processados por várias horas para produzir uma saída grande e útil. O uso dessas estruturas foi originalmente restrito a cientistas de dados e programadores, que os usaram para consultas grandes e específicas em que essa alta latência era tolerável. No entanto, como o uso de Big Data ganhou prevalência nas empresas, houve uma movimentação na direção da consulta ad hoc de dados, com latências esperadas de minutos, não de horas. Ferramentas como Pig, Hive, Shark e Spark SQL permitiam que muitas empresas fizessem perguntas complexas sobre seus dados, sem depender de um grande pool de programadores altamente treinados. A nuvem favoreceu ainda mais essa adoção, proporcionando um fornecimento elástico de recursos de computação pela duração de uma consulta ad hoc.
Rapidamente a expectativa de latências ficou ainda menor. O Big Data começou a ser recebido em tempo real e, muitas vezes, era valioso apenas por uma curta duração. Por exemplo, os mecanismos de pesquisa exigiam que a melhor combinação de anúncios fosse servida em milissegundos para cada consulta; os sites de mídia social detectavam tendências, assuntos de tendências e hashtags e as ferramentas de monitoramento do sistema detectavam padrões complexos em vários componentes grandes de infraestrutura. Para poder fornecer essas baixas latências, uma nova classe de estruturas de processamento de fluxo começou a tomar forma. Elas tinham requisitos e restrições fundamentalmente diferentes dos sistemas de processamento interativos e de lote do passado.
Isso levou ao advento dos sistemas de processamento de fluxo.
Processamento de fluxo
O paradigma de processamento de fluxo aplica uma série de operações em cada elemento de dados emitido por uma fonte de dados de entrada infinitamente longa. A série de operações é geralmente organizada em pipeline, o que cria dependências entre operações. No aplicativo de processamento, as informações de estado são frequentemente lidas e gravadas em uma fonte de dados pequena e rápida. A saída de um pipeline de operações de fluxo também é um fluxo de dados. Isso pode ser usado para acionar outros aplicativos ou ser armazenado em buffer e salvo em armazenamento estável. A arquitetura conceitual básica desse sistema é mostrada abaixo.
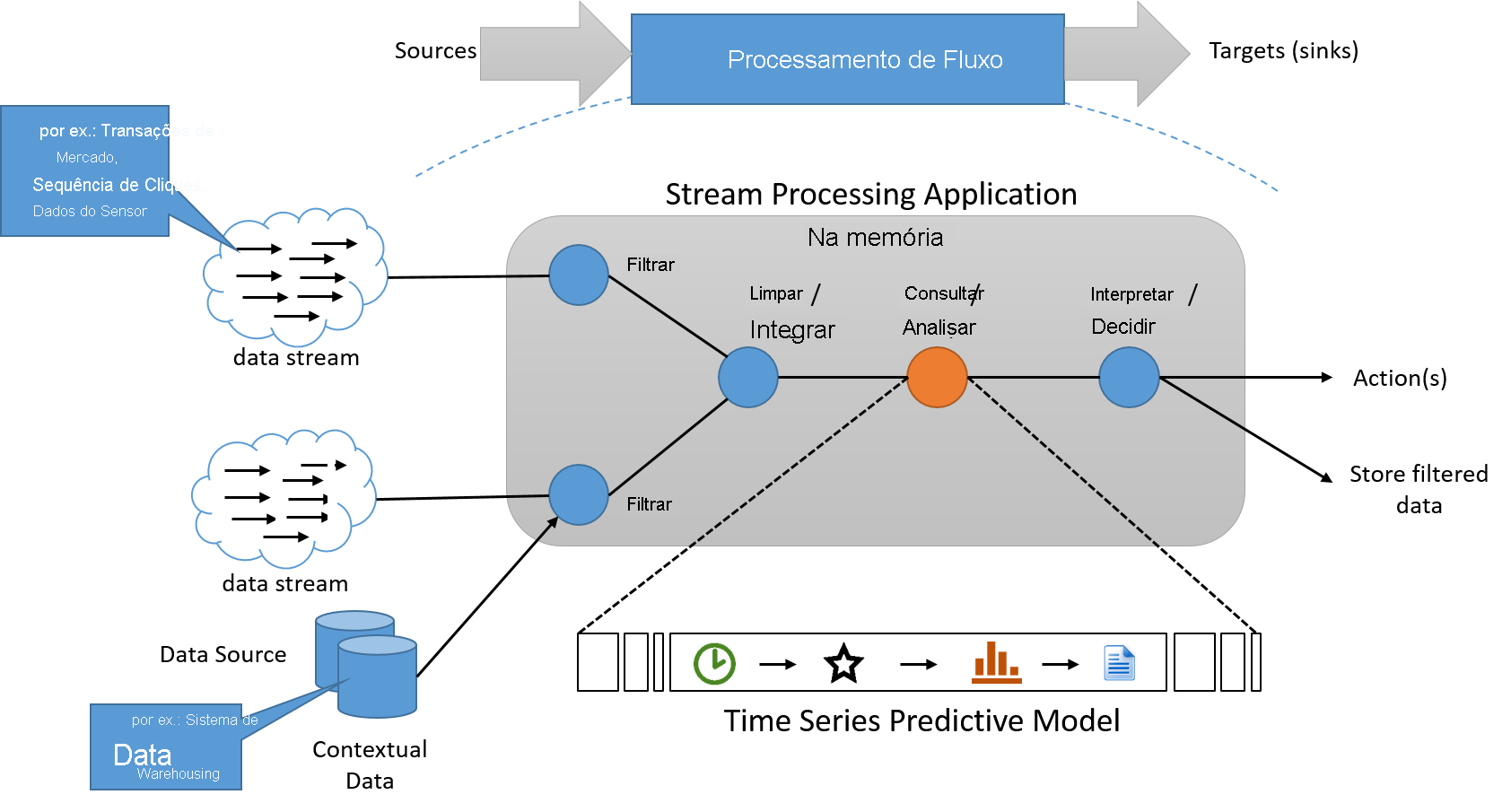
Figura 6: Um sistema de processamento de fluxo deve processar dados em fluxo, com um pipeline separado para armazenamento, se necessário, que não se encontra no "caminho crítico"
Oito regras para processamento de fluxo
Stonebraker et. Al. descreveu oito regras básicas para sistemas de processamento de fluxo.
Regra 1: Manter os dados em movimento
Uma estrutura de processamento de fluxo em tempo real deve ser capaz de processar mensagens "em fluxo" sem precisar armazená-las no disco, o que adiciona latência inaceitável no caminho crítico. Além disso, esses sistemas devem ser ativos (controlados por eventos) e não passivos (situação em que os aplicativos precisam sondar os resultados para detectar condições de interesse).
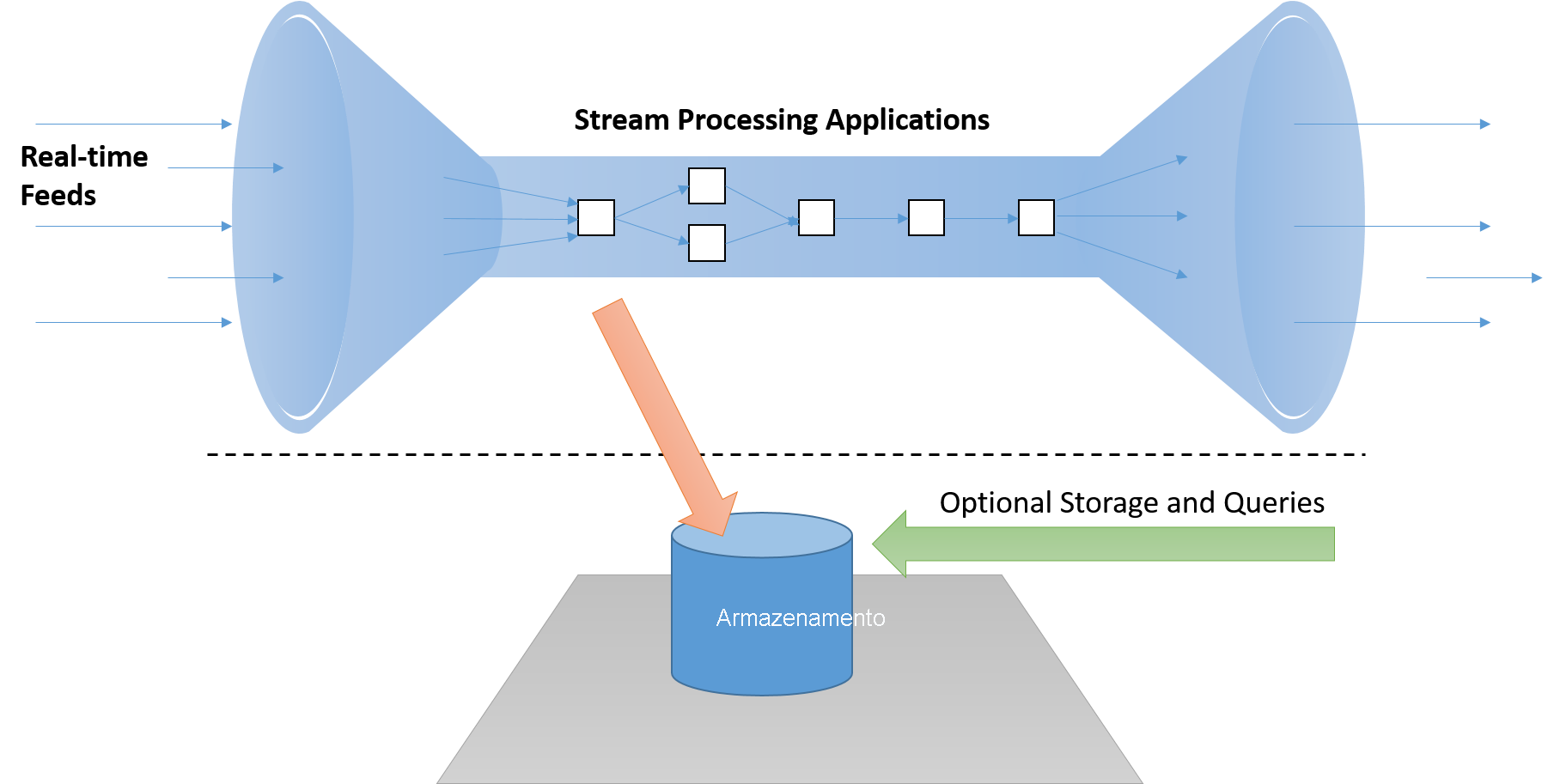
Figura 7: Um sistema de processamento de fluxo deve processar dados em fluxo, com um pipeline separado para armazenamento, se necessário, que não se encontra no "caminho crítico"
Regra 2: Os fluxos devem ser compatíveis com consulta com uso de SQL
A SQL surgiu como um padrão amplamente usado e familiar para consultar dados. No entanto, o SQL tradicional opera em uma quantidade fixa de dados, na qual alcançar o final da tabela de dados indica à consulta que foi concluída. Em cenários de streaming, os dados aumentam continuamente. Stonebraker et. Al. percebeu a necessidade de uma linguagem StreamSQL, com janelas deslizantes com base no tempo e de comprimento variável, que definem o escopo de uma consulta. As janelas podem ser definidas usando o tempo, o número de mensagens ou parâmetros arbitrários. Operadores adicionais podem ser necessários para mesclar mensagens de vários fluxos.
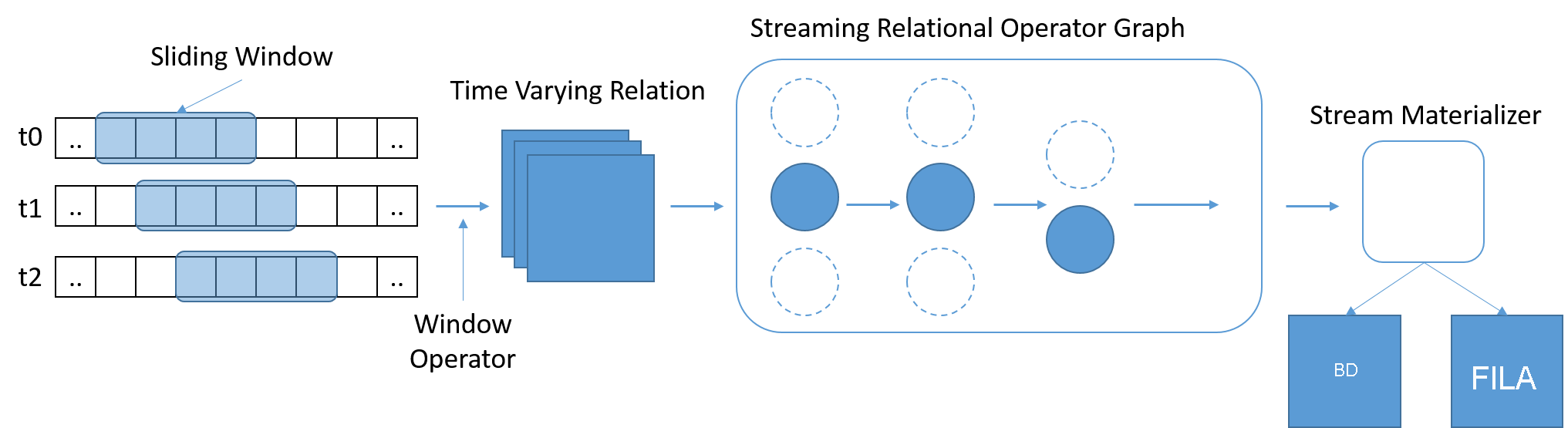
Figura 8: A StreamSQL deve processar subconjuntos de dados e permitir que as relações sejam expressas em janelas
Regra 3: Lidar com imperfeições de fluxo
Em sistemas em tempo real, os dados podem ser perdidos, chegar atrasados ou chegar fora de ordem. Um sistema de processamento de fluxo não pode aguardar indefinidamente os dados, mas também pode não ter a flexibilidade de ignorar ou perder dados. Esses sistemas devem ser resilientes contra imperfeições no fluxo, com mecanismos como tempos limite configuráveis e "tempos de folga", nos quais uma chegada tardia pode ser aceita.
Regra 4: Gerar resultados previsíveis
O resultado de qualquer sistema de processamento de fluxo deve ser determinístico e repetível, reproduzindo o fluxo. Isso é particularmente difícil quando o sistema está operando em vários fluxos simultâneos ou quando as mensagens chegam fora de ordem. As mensagens devem ser produzidas em ordem crescente de tempo, independentemente da hora de chegada. Essa propriedade também possibilita a tolerância a falhas, tornando razoável a reprodução de fluxos nos quais houve falha no processamento.
Regra 5: Integrar estado armazenado
Aplicativos de processamento de fluxo geralmente devem combinar o presente com o passado. Por exemplo, ao recomendar um anúncio a um usuário, um mecanismo de pesquisa deve combinar as informações atuais sobre o termo de pesquisa e o estado atual do mercado do anúncio, com informações passadas sobre os hábitos de clique do usuário. A integração de dados de estado armazenado e de streaming também permite uma transição suave, na qual um algoritmo pode ser testado em dados históricos e, em seguida, transferido para a transmissão ao vivo quando estiver funcionando satisfatoriamente. Os dados devem ser armazenados no mesmo espaço de endereço do sistema que o aplicativo, talvez usando um banco de dados embutido, para permitir o uso de uma linguagem uniforme que lide com os dados armazenados e de streaming.
Regra 6: Garantir alta disponibilidade
Os sistemas de processamento de fluxo funcionam em tempo real e, muitas vezes, não podem tolerar recuperações de reinicialização. Esses sistemas devem permitir uma comutação ativa para um backup ou uma sombra, que deve ser sincronizada regularmente com o primário. A integridade dos dados deve ser garantida, de acordo com a regra 4.
Regra 7: Suporte a particionamento e dimensionamento automático
O processamento distribuído é o modelo padrão de operação para todos esses grandes sistemas. Uma boa arquitetura de processamento de fluxo deve ser sem bloqueio e explorar arquiteturas de multithread modernas. Além disso, ela deve ser capaz de lidar com a expansão ou a redução do sistema por conta própria, adicionando ou removendo máquinas, seja com base em volumes de dados aumentados ou reduzidos, ou com base em atrasos ou complexidades no processamento. Ademais, ela deve executar o balanceamento de carga de maneira automática e transparente nos computadores disponíveis. O usuário final não deve ter que lidar com nenhuma dessas complexidades.
Regra 8: Certifique-se de que possa acompanhar
Todos os componentes do sistema devem ser projetados para o alto desempenho, com um número mínimo de operações acontecendo fora do núcleo. O sistema deve ser testado e avaliado com base na carga de trabalho alvo e as metas de taxa de transferência e latência devem ser validadas.
Evolução dos mecanismos de processamento de fluxo
O Aurora (2002) foi um dos sistemas de processamento de fluxo mais antigos, também desenvolvido por Stonebraker et al. no MIT e na Brown University. Aurora tratou o problema de processamento de fluxo como um DAG (grafo direcionado acíclico).
A entrada de fluxo é uma sequência de tuplas ilimitadas (a1, a2, ..., an) ao longo do tempo que flui de fluxo ascendente (início) para fluxo descendente (saída). Um aplicativo inteiro pode ser construído adicionando diferentes combinações de caixas de processamento e criando conexões entre elas. O Aurora era um sistema de nó único, que não tinha muitos dos requisitos de escalabilidade de um mecanismo de processamento de fluxo. Uma versão do Aurora chamada Aurora* (2003) foi criada para combinar muitos nós do Aurora em uma rede. Portanto, a escalabilidade foi obtida ao particionar os diferentes estágios do trabalho de processamento de fluxo em nós físicos diferentes. Por fim, o projeto Medusa (2003) adicionou suporte à federação ao Aurora, permitindo a colaboração e o compartilhamento por vários usuários.
O Borealis (2005) foi a extensão seguinte do projeto Aurora, que adicionou suporte para alta disponibilidade com uso de replicação ativa. As réplicas foram cuidadosamente sincronizadas para fornecer consistência de dados.
Apache Storm (2011) era um mecanismo de processamento de fluxo desenvolvido por X. Aqui, os nós de processamento (Bolts) podem assinar fluxos de diferentes fontes (Spouts), habilitando, assim, um modelo de computação de assinante simples. O Storm oferece processamento de mensagens garantido, independentemente de falhas de nó, além de permitir uma semântica "exatamente uma vez" para garantir que os dados não sejam subcontados nem contados em excesso. O Apache S4 (2011) foi um sistema de assinatura semelhante desenvolvido na Yahoo!. Ele é simétrico, no sentido de que todos os nós são iguais e não há controle centralizado, na esperança de torná-lo escalonável. O S4 não era compatível com adição nem remoção dinâmica de nós de e para um cluster em execução. O Apache Samza (2013) é outro sistema de vários assinantes neste molde que exploraremos mais detalhadamente.
O Storm, o Samza e o S4 seguem o modelo de streaming tradicional, conhecido como processamento de um registro por vez. Nesse modelo, os operadores com estado processam os registros que chegam usando os novos dados para modificar o estado interno e, em seguida, emitir novos registros. A tolerância a falhas e a recuperação são feitas pela replicação, fazendo várias cópias de elementos de processamento ou armazenando em buffer e armazenando backups de mensagens upstream e reenviando-as downstream, em caso de falhas. Além disso, como o layout do DAG se torna mais complexo, é difícil garantir a consistência entre caminhos diferentes. Por fim, a combinação dessas estruturas com sistemas de lote não é trivial e, muitas vezes, isso é feito usando a arquitetura Lambda (discutida posteriormente).
Outra abordagem para a criação de sistemas de processamento de fluxo é fornecida pelo Spark Streaming (2012), que fornece "micro envio em lote". O micro envio em lote converte cálculos de fluxo em um conjunto de cálculo extremamente rápido, com latências de centenas de milissegundos a alguns segundos. Ao custo de maior latência, isso torna mais fácil fornecer tolerância a falhas e semânticas "exatamente uma vez" no resultado de cada micro lote.
A seleção da estrutura correta a ser usada para uma tarefa é a consideração da latência esperada, da tolerância a falhas e das garantias de entrega de mensagens, bem como do conjunto de habilidades dos usuários e dos custos de desenvolvimento desejados. Na próxima unidade, exploraremos os elementos internos dessas estruturas mais detalhadamente, estudando o Apache Samza.