Explicar as opções de PaaS para a implantação do SQL Server no Azure
A PaaS (plataforma como serviço) fornece um ambiente completo de desenvolvimento e implantação na nuvem, que pode ser usado para aplicativos simples baseados em nuvem, bem como para aplicativos empresariais avançados.
O Banco de Dados SQL do Azure e a Instância Gerenciada de SQL do Azure fazem parte da oferta de PaaS do SQL do Azure.
Banco de Dados SQL do Azure – parte de uma família de produtos baseados no mecanismo do SQL Server na nuvem. Ele proporciona aos desenvolvedores uma grande flexibilidade na criação de serviços de aplicativos e opções de implantação granulares em escala. O Banco de Dados SQL oferece uma solução de baixa manutenção que pode ser uma ótima opção para determinadas cargas de trabalho.
Instância Gerenciada de SQL do Azure – é melhor para a maioria dos cenários de migração para a nuvem, pois fornece serviços e recursos totalmente gerenciados.

Como visto na imagem acima, cada oferta fornece um determinado nível de administração que você tem sobre a infraestrutura, segundo o grau de custo benefício.
Modelos de implantação
O Banco de Dados SQL do Azure está disponível em dois modelos de implantação:
Banco de dados individual – um banco de dados único que é cobrado e gerenciado no nível do banco de dados. Você gerencia cada um de seus bancos de dados individualmente por meio de perspectivas de escala e tamanho de dados. Cada banco de dados implantado nesse modelo tem os próprios recursos dedicados, mesmo se implantado no mesmo servidor lógico.
Pools Elásticos – um grupo de bancos de dados gerenciados em conjunto e que compartilham recursos em comum. Os pools elásticos fornecem uma solução econômica para o modelo de aplicativo de software como serviço, pois os recursos são compartilhados entre todos os bancos de dados. Você pode configurar recursos com base no modelo de compra baseado em DTU ou no modelo de compra baseado em vCore.
Modelo de compra
No Azure, todos os serviços são apoiados por hardware físico, e você pode escolher entre dois modelos de compra:
DTU (Unidade de Transmissão de Dados)
As DTUs são calculadas com base em uma fórmula que combina recursos de computação, armazenamento e E/S. É uma boa opção para clientes que desejam opções de recursos simples e pré-configuradas.
O modelo de compra de DTU vem em várias camadas de serviço diferentes, como Básico, Standard e Premium. Cada camada tem funcionalidades variadas que oferecem uma ampla gama de opções quando essa plataforma é escolhida.
Em termos de desempenho, a camada Básico é usada para cargas de trabalho menos exigentes, enquanto a Premium é usada para requisitos intensivos de carga de trabalho.
Os recursos de computação e armazenamento dependem do nível de DTU e oferecem uma variedade de recursos de desempenho com limite de armazenamento, retenção de backup e custo fixos.
Observação
O modelo de compra de DTU só tem suporte do Banco de Dados SQL do Azure.
Para saber mais sobre o modelo de compra de DTU, confira Visão geral do modelo de compra baseado em DTU.
vCore
O modelo de vCore permite que você compre um número especificado de vCores com base em suas cargas de trabalho determinadas. vCore é o modelo de compra padrão ao adquirir recursos do Banco de Dados SQL do Azure. Os bancos de dados vCore têm uma relação específica entre o número de núcleos e a quantidade de memória e armazenamento fornecidos ao banco de dados. O modelo de compra de vCore é compatível com o Banco de Dados SQL do Azure e a Instância Gerenciada de SQL do Azure.
Você também pode comprar bancos de dados vCore em três camadas de serviço diferentes:
Uso Geral – essa camada destina-se a cargas de trabalho de uso geral. Ele tem o suporte do armazenamento premium do Azure. Ela terá maior latência do que a camada Comercialmente Crítico. Ela também fornece as seguintes camadas de computação:
- Provisionado – os recursos de computação são pré-alocados Cobrado por hora com base nos vCores configurados.
- Sem servidor– os recursos de computação são dimensionados automaticamente. Cobrado por segundo com base nos vCores usados.
Comercialmente Crítico – essa camada destina-se a cargas de trabalho de alto desempenho que oferecem a menor latência de qualquer camada de serviço. Essa camada tem o suporte de SSDs locais em vez do armazenamento de blobs do Azure. Ela também oferece a maior resiliência a falhas, bem como uma réplica de banco de dados somente leitura interno que pode ser usado para descarregar cargas de trabalho de relatório.
Hiperescala – os bancos de dados de Hiperescala podem ser dimensionados muito além do limite de 4 TB das outras ofertas de Banco de Dados SQL do Azure e têm uma arquitetura exclusiva que dá suporte a bancos de dados de até 100 TB.
Sem servidor
O nome "Sem servidor" pode ser um pouco confuso, pois você ainda implanta seu Banco de Dados SQL do Azure em um servidor lógico, ao qual você se conecta. O Banco de Dados SQL do Azure sem servidor é uma camada de computação que escala ou reduz verticalmente de forma automática os recursos de determinado banco de dados com base na demanda da carga de trabalho. Se a carga de trabalho não exigir mais recursos de computação, o banco de dados será "pausado" e somente o armazenamento será cobrado durante o período em que ele estiver inativo. Quando uma tentativa de conexão for feita, o banco de dados será "retomado" e ficará disponível.
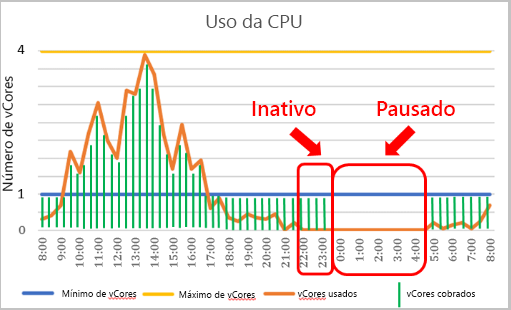
A configuração para controlar a pausa é chamada de atraso de autopausa e tem um valor mínimo de 60 minutos e um valor máximo de sete dias. Se o banco de dados ficar ocioso por esse período, ele será pausado.
Quando o banco de dados ficar inativo pelo período especificado, ele será pausado até que haja uma tentativa de conexão subsequente. Configurar um intervalo de dimensionamento automático de computação e um atraso de pausa automática afeta o desempenho do banco de dados e os custos de computação.
Todos os aplicativos que usam o modelo sem servidor devem ser configurados para lidar com erros de conexão e incluir lógica de repetição, uma vez que a conexão a um banco de dados pausado gerará um erro de conexão.
Outra diferença entre o modelo de vCore normal e sem servidor do Banco de Dados SQL do Azure é que, no sem servidor, você pode especificar um número mínimo e máximo de vCores. Os limites de memória e E/S são proporcionais ao intervalo especificado.

A imagem acima mostra a tela de configuração para um banco de dados sem servidor no portal do Azure. Você tem a opção de selecionar um mínimo igual à metade de um vCore e um máximo de 16 vCores.
A opção sem servidor não é totalmente compatível com todos os recursos do Banco de Dados SQL do Azure, pois alguns deles exigem que os processos em segundo plano sejam executados a todo momento, como:
- Replicação geográfica
- Retenção de backup de longo prazo
- Banco de dados de trabalho em trabalhos elásticos
- Banco de dados de sincronização na Sincronização de Dados SQL (a Sincronização de Dados é um serviço que replica dados entre um grupo de bancos de dados)
Observação
Atualmente, o Banco de Dados SQL sem servidor é compatível apenas com a camada de Uso Geral no modelo de compra de vCore.
Backups
Um dos recursos mais importantes da oferta de plataforma como serviço é o backup. Nesse caso, os backups são executados automaticamente sem nenhuma intervenção sua. Os backups são armazenados no armazenamento com redundância geográfica de blobs do Azure e, por padrão, são mantidos entre 7 e 35 dias, com base na camada de serviço do banco de dados. Os bancos de dados Basic e vCore têm como padrão sete dias de retenção e, nos bancos de dados vCore, esse valor pode ser ajustado pelo administrador. O tempo de retenção pode ser estendido por meio da configuração da LTR (retenção de longo prazo), o que permitiria a você reter os backups por até dez anos.
Para fornecer redundância, você também pode usar o armazenamento de blobs com redundância geográfica com acesso de leitura. Esse armazenamento replica os backups de banco de dados para uma região secundária de sua preferência. Ele também permite que você leia essa região secundária, se necessário. Backups manuais de bancos de dados não têm suporte e a plataforma negará qualquer solicitação para isso.
Os backups de banco de dados são feitos conforme um cronograma:
- Completo – uma vez por semana
- Diferencial – a cada 12 horas
- Log – a cada cinco a dez minutos, dependendo da atividade do log de transações
Esse cronograma de backup precisa atender às necessidades da maioria dos RPO/RTO (objetivos de tempo/ponto de recuperação), mas cada cliente deve avaliar se eles atendem aos requisitos de negócios.
Há várias opções disponíveis para restaurar um banco de dados. Devido à natureza da plataforma como serviço, não é possível restaurar manualmente um banco de dados usando métodos convencionais, como emitir o comando T-SQL RESTORE DATABASE.
Independentemente do método de restauração implementado, não será possível restaurá-lo em um banco de dados existente. Se um banco de dados precisar ser restaurado, o banco de dados existente deverá ser descartado ou renomeado antes do início do processo de restauração. Além disso, tenha em mente que, dependendo da camada de serviço da plataforma, os tempos de restauração não são garantidos e poderão variar. Recomendamos que você teste o processo de restauração para obter métricas de linha de base sobre quanto tempo uma restauração pode demorar.
As opções de restauração disponíveis são:
Restaurar usando o portal do Azure – no portal do Azure, você tem a opção de restaurar um banco de dados para o mesmo servidor do Banco de Dados SQL do Azure ou pode usar a restauração para criar um banco de dados em um novo servidor em qualquer região do Azure.
Restaurar usando linguagens de script – o PowerShell e a CLI do Azure podem ser usados para restaurar um banco de dados.
Observação
O backup somente cópia para o armazenamento de blobs do Azure está disponível para a Instância Gerenciada de SQL. O Banco de Dados SQL não dá suporte a esse recurso.
Para obter mais informações sobre backups automatizados, confira Backups automatizados – Banco de Dados SQL do Azure e Instância Gerenciada de SQL do Azure.
Replicação geográfica ativa
A replicação geográfica é um recurso de continuidade de negócios que replica de forma assíncrona um banco de dados para até quatro réplicas secundárias. À medida que as transações são confirmadas no primário (e suas réplicas na mesma região), as transações são enviadas para os secundários a serem reproduzidos. Como essa comunicação é feita de forma assíncrona, o aplicativo de chamada não precisa esperar que a réplica secundária confirme a transação antes que o SQL Server retorne o controle ao chamador.
Os bancos de dados secundários são legíveis e podem ser usados para descarregar cargas de trabalho somente leitura, liberando, assim, os recursos para cargas de trabalho transacionais no primário ou deixando os dados mais próximos dos usuários finais. Além disso, os bancos de dados secundários podem estar na mesma região que o primário ou em outra região do Azure.
Com a replicação geográfica, um failover pode ser iniciado manualmente pelo usuário ou no aplicativo. Se ocorrer um failover, você provavelmente precisará atualizar as cadeias de conexão do aplicativo para refletir o novo ponto de extremidade do que agora é o banco de dados primário.
Grupos de failover
Os grupos de failover são baseados na tecnologia usada na replicação geográfica, mas fornecem um único ponto de extremidade para conexão. O principal motivo de usar grupos de failover é que a tecnologia fornece pontos de extremidade, que podem ser utilizados a fim de rotear o tráfego para a réplica adequada. Após um failover, seu aplicativo pode se conectar sem alterações na cadeia de conexão.