Descrever normalização
A normalização do banco de dados é um processo de design usado para organizar dados em tabelas e colunas dentro de um banco de dados. Cada tabela deve conter dados relacionados a uma entidade específica e incluir apenas informações que dão suporte a essa entidade. O objetivo principal da normalização é minimizar a duplicação de dados no banco de dados, o que ajuda a evitar a degradação do desempenho durante inserções e atualizações. Por exemplo, se o endereço de um cliente precisar ser atualizado, será mais simples implementar a alteração se esse endereço for armazenado em um único local, como a tabela Customers.
As formas mais comuns de normalização são a primeira, a segunda e a terceira formas normais.
Primeira forma normal
A primeira forma normal tem as seguintes especificações:
- Criar uma tabela separada para cada conjunto de dados relacionados
- Eliminar grupos de repetição em tabelas individuais
- Identificar cada conjunto de dados relacionados a uma chave primária
Nesse modelo, você deve evitar o uso de várias colunas em uma única tabela para armazenar dados semelhantes. Por exemplo, se um produto puder vir em várias cores, você não deverá ter várias colunas em uma única linha contendo os diferentes valores de cores. A primeira tabela a seguir, ProductColors, não está na primeira forma normal porque tem valores repetidos de cor. Para os produtos com apenas uma cor, há desperdício de espaço. Além disso, se um produto vem em mais de três cores, torna-se impraticável definir um número máximo de colunas. Em vez disso, podemos recriar a tabela, conforme mostrado na segunda tabela, ProductColor.
A primeira forma normal também requer uma chave exclusiva para a tabela, que é uma coluna (ou colunas) cujo valor identifica exclusivamente cada linha. Na segunda tabela, nenhuma das colunas é exclusiva por si só, mas, juntas, a combinação de ProductID e Color forma uma chave exclusiva. Quando várias colunas são necessárias para criar uma chave exclusiva, ela é conhecida como uma chave composta.
Tabela
ProductColors:Productid Color1 Cor2 Cor3 1 Vermelho Verde Amarelo 2 Amarelo 3 Azul Vermelho 4 Azul 5 Vermelho Tabela
ProductColor:Productid Cor 1 Vermelho 1 Verde 1 Amarelo 2 Amarelo 3 Azul 3 Vermelho 4 Azul 5 Vermelho
A terceira tabela, ProductInfo, está na primeira forma normal porque cada linha se refere a um produto específico, não há grupos repetidos e temos a coluna ProductID a ser usada como chave primária.
| Productid | ProductName | Preço | ProductionCountry | ShortLocation |
|---|---|---|---|---|
| 1 | Widget | 15.95 | Estados Unidos | EUA |
| 2 | Foop | 41.95 | Reino Unido | Reino Unido |
| 3 | Glombit | 49.95 | Reino Unido | Reino Unido |
| 4 | Sorfin | 99.99 | República das Filipinas | RepPhil |
| 5 | Stem Bolt | 29.95 | Estados Unidos | EUA |
Segunda forma normal
A segunda forma normal tem a seguinte especificação, além daquelas requeridas pela primeira forma normal:
- Se a tabela tiver uma chave composta, todos os atributos deverão depender da chave completa, não apenas parte dela.
A segunda forma normal é relevante apenas para tabelas com chaves compostas, como na tabela ProductColor, que é a segunda tabela. Considere o caso em que a tabela ProductColor também inclui o preço do produto. Essa tabela tem uma chave composta em ProductID e Color, porque usando apenas os valores das duas colunas podemos identificar exclusivamente uma linha. Se o preço de um produto não for alterado com a cor, poderemos ver os dados conforme mostrados nesta tabela.
| Productid | Cor | Preço |
|---|---|---|
| 1 | Vermelho | 15.95 |
| 1 | Verde | 15.95 |
| 1 | Amarelo | 15.95 |
| 2 | Amarelo | 41.95 |
| 3 | Azul | 49.95 |
| 3 | Vermelho | 49.95 |
| 4 | Azul | 99,95 |
| 5 | Vermelho | 29.95 |
Essa tabela não está na segunda forma normal. O valor do preço depende de ProductID, mas não de Color. Há três linhas para ProductID 1, portanto, o preço desse produto é repetido três vezes. O problema de violar a segunda forma normal é que, se precisarmos atualizar o preço, teremos que garantir que ele seja atualizado em todos os lugares. Se atualizarmos o preço na primeira linha, mas não na segunda ou terceira, encontraremos uma anomalia de atualização. Após a atualização, não conseguiríamos determinar o preço real para ProductID 1. A solução é mover a coluna Price para uma tabela que tem ProductID como uma única chave de coluna, porque essa é a única coluna da qual Price depende. Por exemplo, poderíamos usar a Tabela 3 para armazenar Price.
Se o preço de um produto fosse diferente com base em sua cor, a quarta tabela estaria na segunda forma normal, pois o preço dependeria de ambas as partes da chave: ProductID e Color.
Terceira forma normal
Em geral, a terceira forma normal é o objetivo da maioria dos bancos de dados OLTP. A terceira forma normal tem a seguinte especificação, além daquelas exigidas pela segunda forma normal:
- Todas as colunas que não sejam de chave são dependentes de maneira não transitiva da chave primária.
Uma relação transitiva implica que uma coluna em uma tabela está relacionada a outras colunas por meio de uma segunda coluna. Dependência significa que uma coluna pode derivar seu valor de outra como resultado dessa relação. Por exemplo, sua idade pode ser determinada com base em sua data de nascimento, tornando sua idade dependente de sua data de nascimento. Volte para a terceira tabela, ProductInfo. Essa tabela está na segunda forma normal, mas não na terceira. A coluna ShortLocation depende da coluna ProductionCountry, que não é a chave. Como a segunda forma normal, violar a terceira forma normal pode levar a anomalias de atualização. Acabaríamos com dados inconsistentes se atualizássemos ShortLocation em uma linha, mas não em todas as linhas em que esse local ocorreu. Para evitar isso, é possível criar uma tabela separada a fim de armazenar nomes de países/regiões e suas formas abreviadas.
Desnormalização
Embora a terceira forma normal seja teoricamente desejável, nem sempre ela é possível para todos os dados. Além disso, um banco de dados normalizado nem sempre proporciona o melhor desempenho. Os dados normalizados frequentemente exigem várias operações de junção para obter todos os dados necessários retornados em uma só consulta. Há prós e contras entre a normalização de dados, em que o número de junções necessárias para retornar os resultados da consulta apresenta alta utilização da CPU, e a desnormalização de dados, que tem menos junções e menos necessidade de CPU, mas gera a possibilidade de anomalias de atualização.
Os dados desnormalizados podem ser mais eficientes para consulta, especialmente para cargas de trabalho com muita leitura, como uma data warehouse. Nesses casos, ter colunas extras pode oferecer melhores padrões de consulta e/ou consultas mais simples.
Esquema em estrela
Embora a maior parte da normalização seja destinada a cargas de trabalho OLTP, os data warehouses têm sua própria estrutura de modelagem, que normalmente é um modelo desnormalizado . Esse design usa tabelas de fatos para registrar medidas ou métricas para eventos específicos, como vendas, e as une a tabelas de dimensão. As tabelas de dimensão são menores em termos de número de linhas, mas podem ter um número grande de colunas para descrever os dados de fatos. Alguns exemplos de dimensões são estoque, tempo e geografia. Esse padrão de design facilita a consulta do banco de dados e oferece ganhos de desempenho para cargas de trabalho de leitura.
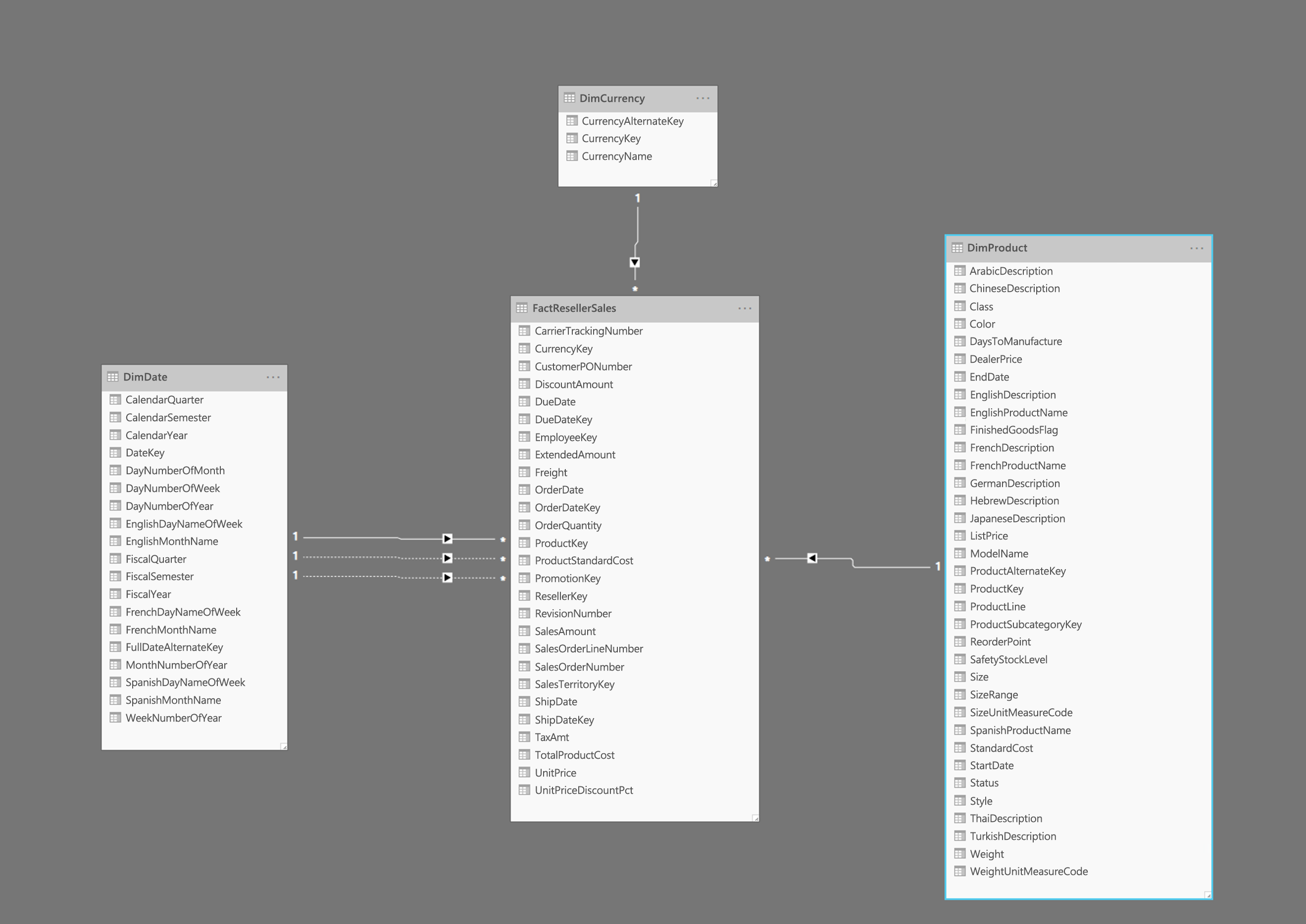
A imagem ilustra um exemplo de um esquema de estrela, com uma tabela de fatos FactResellerSales e dimensões para data, moeda e produtos. A tabela de fatos contém dados relacionados a transações de vendas, enquanto as dimensões contêm apenas dados relacionados a elementos específicos dos dados de vendas. Por exemplo, a tabela FactResellerSales inclui apenas um ProductKey para indicar qual produto foi vendido. Todos os detalhes sobre cada produto são armazenados na tabela DimProduct e estão relacionados à tabela de fatos usando a coluna ProductKey.
Relacionado ao design de esquema de estrela está o esquema floco de neve, que usa um conjunto de tabelas mais normalizadas para uma única entidade de negócios. A imagem a seguir ilustra um exemplo de uma única dimensão em um esquema de floco de neve. A dimensão Produtos é normalizada e armazenada em três tabelas: DimProductCategory, DimProductSubcategory e DimProduct.
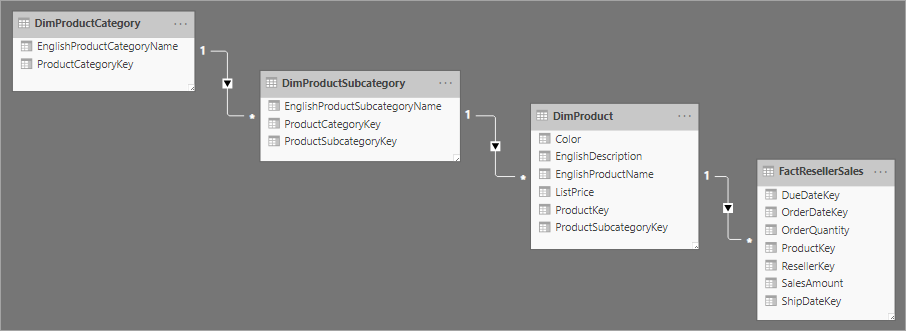
A principal diferença entre os esquemas estrela e floco de neve é que as dimensões em um esquema floco de neve são normalizadas para reduzir a redundância, o que economiza espaço de armazenamento. A desvantagem é que suas consultas exigem mais junções, o que pode aumentar a complexidade e diminuir o desempenho.