Extrair informações de documentos
Observação
Consulte a guia Texto e imagens para obter mais detalhes!
Os processos empresariais de hoje dependem muito dos dados contidos em documentos como formulários, recibos e faturas. O processamento manual pode introduzir atrasos e erros, tornando a automação de extração de dados mais importante do que nunca.
Como funciona o Azure Content Understanding
O Entendimento de Conteúdo do Azure segue um fluxo de trabalho de extração controlado por modelo no qual o conteúdo não estruturado é ingerido, analisado e retornado como dados estruturados.
Ingerir conteúdo: você envia conteúdo para o Azure Content Understanding.
Análise de IA: o serviço usa uma combinação de: OCR (Reconhecimento Óptico de Caracteres), reconhecimento de fala, reconhecimento de linguagem natural e modelos de IA multimodal para analisar o conteúdo.
Saída estruturada: o serviço retorna resultados estruturados (por exemplo, em JSON) que correspondem ao seu modelo, tornando os dados fáceis de armazenar, pesquisar ou integrar em sistemas downstream.
Observação
JSON (JavaScript Object Notation) é um formato de dados baseado em texto usado para armazenar e trocar dados estruturados entre sistemas. É fácil para os humanos ler e escrever, e fácil para as máquinas analisarem e gerarem.
Entender esquemas
O OCR (reconhecimento óptico de caracteres) permite que um computador 'leia' o texto de imagens, como documentos verificados, fotos de recibos ou imagens de páginas impressas, e transforme esse texto em texto digital editável e pesquisável. O OCR básico ajuda a reconhecer o texto impresso, concentra-se na extração de texto e não entende o significado, o contexto ou as relações entre palavras.
Os recursos de análise de documentos do Azure Content Understanding vão além da simples extração de texto baseada em OCR para incluir a extração baseada em esquema de campos e seus valores. A abordagem orientada por esquema é o que diferencia o Reconhecimento de Conteúdo do Azure dos serviços básicos de OCR ou transcrição.
Um esquema descreve quais informações você deseja extrair e como essas informações devem ser estruturadas. Quando você define um esquema, especifica campos a serem extraídos. Um esquema lista os campos ou entidades específicas com as quais você se importa.
Por exemplo, suponha que você defina um esquema que inclua os campos comuns normalmente encontrados em uma fatura, como:
- Nome do fornecedor
- Número da fatura
- Data da fatura
- Nome do cliente
- Endereço personalizado
- Itens - os itens ordenados, cada um deles inclui:
- Descrição do item
- Preço unitário
- Quantidade ordenada
- Total do item de linha
- Subtotal da fatura
- Imposto
- Encargo de envio
- Total da fatura
Agora, suponha que você precise extrair essas informações da seguinte fatura:
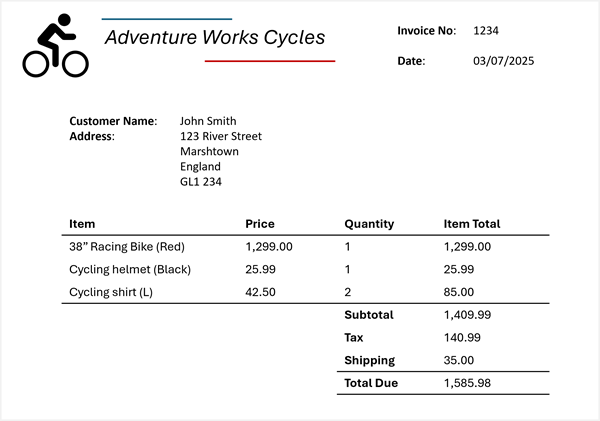
Azure Content Understanding pode aplicar o esquema de fatura às suas faturas e identificar os campos correspondentes, mesmo quando rotulados com nomes diferentes ou não rotulados de modo algum. A análise resultante produz um resultado como este:

O esquema também define a estrutura de campo. Os esquemas dão suporte a campos estruturados e aninhados, não apenas texto simples. Por exemplo:
-
Itemsé uma coleção - Cada item tem
description,unit priceequantityline total
Identificar campos estruturados permite que o Reconhecimento de Conteúdo do Azure entenda as relações entre valores, algo que o OCR sozinho não pode fazer.
No exemplo da fatura, para cada campo detectado, você pode extrair valores aninhados:
- Nome do fornecedor: Adventure Works Cycles
- Número da fatura: 1234
- Data da fatura: 07/03/2025
- Nome do cliente: John Smith
- Endereço personalizado: 123 River Street, Marshtown, Inglaterra, GL1 234
-
Itens:
- Item 1:
- Descrição do item: Bicicleta de Corrida de 38" (Vermelho)
- Preço unitário: 1299,00
- Quantidade ordenada: 1
- Total do item de linha: 1299.00
- Item 2:
- Descrição do item: Capacete de ciclismo (preto)
- Preço unitário: 25,99
- Quantidade ordenada: 1
- Total do item de linha: 25.99
- Item 3:
- Descrição do item: Camisa de ciclismo (L)
- Preço unitário: 42,50
- Quantidade ordenada: 2
- Total do item de linha: 85.00
- Item 1:
- Subtotal da fatura: 1409.99
- Imposto: 140.99
- Encargo de envio: 35.00
- Total da fatura: 1585,98
O Azure Content Understanding extrai o significado esperado, não apenas os rótulos. Esquemas são aplicados semanticamente, ou seja:
- Os campos podem ser extraídos mesmo se os rótulos forem diferentes
- Os campos podem ser extraídos mesmo se os rótulos estiverem ausentes
Por exemplo, Invoice No., Invoice #, ou um número sem rótulo podem todos ser mapeados para InvoiceNumber se o analisador determinar que eles representam o mesmo conceito.
Entenda os analisadores
Um analisador é uma unidade no Azure Content Understanding que usa entrada, aplica a análise de IA e produz resultados estruturados. Os analisadores aplicam consistentemente a mesma lógica de extração a todo o conteúdo de entrada. Depois de configurado, um analisador garante que um esquema seja reutilizado consistentemente para cada solicitação de análise. Os analisadores também produzem resultados JSON previsíveis. Os resultados estruturados facilitam o processamento downstream (armazenamento, pesquisa, automação).
O Azure Content Understanding oferece analisadores predefinidos para cenários comuns e dá suporte a analisadores personalizados adaptados às suas necessidades. Em um alto nível:
- Você seleciona ou cria um analisador.
- O analisador inclui um esquema definindo campos e estrutura.
- Você envia conteúdo para análise
- O serviço aplica o esquema
- Você recebe resultados JSON estruturados que correspondem ao esquema
Usando o Azure Content Understanding no portal do Foundry
Observação
O portal do Foundry tem uma interface do usuário (interface do usuário) clássica e uma nova interface do usuário.
Depois de criar um recurso do Microsoft Foundry, você pode usar a interface clássica do portal do Foundry para testar o Azure Content Understanding. O portal do Foundry fornece exemplos de conteúdo e permite que você carregue seu próprio material para análise.
Você pode usar a interface visual para selecionar um documento de origem e extrair campos de informações padrão. Por exemplo, quando você experimenta o Entendimento de Conteúdo do Azure em um documento a partir de uma imagem, o serviço retorna o texto do documento e informações de layout de texto.

Os analisadores do Azure Content Understanding identificam valores de texto em documentos e os mapeiam para campos específicos. Por exemplo, considerando uma fatura, o serviço retorna os campos (como o endereço do fornecedor) e os dados nos campos (como 123 456th Street).

No portal do Foundry, você também pode exibir os resultados JSON do processamento.

Criando um aplicativo cliente com o Reconhecimento de Conteúdo do Azure
Você pode usar a API de Reconhecimento de Conteúdo para criar um aplicativo cliente leve que extraia dados programaticamente.
Observação
Um aplicativo cliente é um programa de software executado no dispositivo de um usuário e solicita serviços ou dados de outro sistema, normalmente um servidor, em uma rede. O cliente faz parte de um aplicativo com o qual os usuários interagem, enquanto o servidor faz o trabalho pesado nos bastidores. Os aplicativos podem solicitar dados ou ações de um serviço e receber uma resposta estruturada usando uma API.
Ao usar a API de Reconhecimento de Conteúdo, você pode escolher um analisador predefinido ou criar um analisador personalizado. Analisadores predefinidos incluem: prebuilt-invoice, prebuilt-imageSearch, prebuilt-audioSearch, e prebuilt-videoSearch. Quando você envia conteúdo para análise para o analisador, a análise é assíncrona, o que significa que você obtém o resultado mais tarde quando ele está pronto. Como a análise é assíncrona, você precisa sondar a URL do Operation-Location (ou analyzerResults) até que o trabalho seja bem-sucedido.
Usando o SDK do Python de Compreensão de Conteúdo do Azure
Vamos dar uma olhada no processo de usar o SDK do Python para analisar uma fatura de uma URL.
- Instale o SDK do Python de Compreensão de Conteúdo do Azure.
python -m pip install azure-ai-contentunderstanding
Identifique o ponto de extremidade do seu recurso do Foundry e a chave de API ou o Microsoft Entra ID. Seu ponto de extremidade normalmente se parece com:
https://<your-resource-name>.services.ai.azure.com/Crie e execute o código do aplicativo cliente. O
analzyer_idé o ID do analisador predefinido. Você pode encontrar uma lista de valores de ID do analisador predefinidos aqui.
import os
from azure.ai.contentunderstanding import ContentUnderstandingClient
from azure.core.credentials import AzureKeyCredential
endpoint = os.environ["FOUNDRY_ENDPOINT"]
key = os.environ["FOUNDRY_KEY"]
client = ContentUnderstandingClient(endpoint=endpoint, credential=AzureKeyCredential(key))
# 1) start analysis with analyzer id + inputs
analyzer_id = "prebuilt-invoice"
inputs = [
{"url": "https://github.com/Azure-Samples/azure-ai-content-understanding-python/raw/refs/heads/main/data/invoice.pdf"}
]
# 2) wait for the Long Running Operation (LRO) to complete
poller = client.begin_analyze(analyzer_id=analyzer_id, inputs=inputs) # starts LRO
result = poller.result() # waits for completion (polling handled by SDK)
# 3) read structured fields + markdown
# The result typically includes extracted "fields" and "markdown" per input content item.
for content in result.contents:
print(content.markdown)
print(content.fields)
A saída resultante é JSON que mostra a marcação extraída, os campos, os dados nos campos e a pontuação de confiança. Por exemplo:
{
"status": "Succeeded",
"result": {
"analyzerId": "prebuilt-invoice",
"apiVersion": "2025-05-01-preview",
"contents": [
{
"markdown": "# INVOICE\n\nCONTOSO LTD.\n\nContoso Headquarters\n123 456th St\nNew York, NY, 10001\n\nINVOICE: INV-100\n\nINVOICE DATE: 11/15/2019\n\nDUE DATE: 12/15/2019\n\nCUSTOMER NAME: MICROSOFT CORPORATION\n",
"fields": {
"CustomerName": {
"type": "string",
"valueString": "MICROSOFT CORPORATION",
"confidence": 0.95,
},
"InvoiceDate": {
"type": "date",
"valueDate": "2019-11-15",
"confidence": 0.994,
}
}
}
]
}
}
Em seguida, saiba como usar analisadores do Azure Content Understanding para extrair dados estruturados de áudio e vídeo.