Como funciona o HDInsight
O HDInsight é um sistema de processamento de dados distribuído na nuvem altamente disponível e seguro por padrão. No cerne deste sistema está o Apache Hadoop. O Apache Hadoop inclui dois componentes principais: o HDFS (Sistema de Arquivos Distribuído do Hadoop), que é usado para armazenamento, e o YARN (Yet Another Resource Negotiator), que fornece processamento. Além disso, é um modelo de programação MapReduce simples que permite processar e analisar dados. Os benefícios de usar o MapReduce são a configuração fácil e a possibilidade de controlar os custos por meio do recurso de dimensionamento automático.
Armazenamento
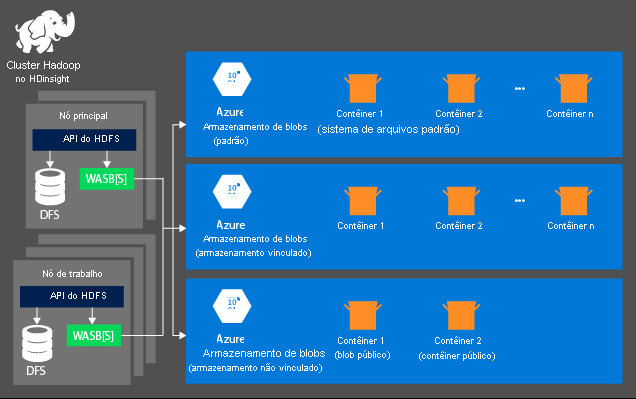
O aspecto de armazenamento não é criado automaticamente quando você provisiona um cluster do HDInsight. Em vez disso, ele é fornecido por um sistema em conformidade com HDFS, como o Armazenamento do Azure ou o Azure Data Lake. O desacoplamento do armazenamento da camada de processamento permite que você exclua com segurança um cluster do HDInsight que é usado para computação sem perder dados do usuário. Ao adicionar um cluster do HDInsight, você deve definir um sistema de arquivos padrão. Você pode vincular e desvincular sistemas de arquivos conforme necessário para aumentar o tamanho do armazenamento.
As informações a seguir são específicas para o HDInsight 3.6 e superiores. Durante o processo de criação do cluster HDInsight, você pode selecionar o Armazenamento do Azure ou o Azure Data Lake Storage Gen2 como o sistema de arquivos padrão. Fornecer um sistema de arquivos padrão garante que as referências de arquivo relativas possam ser resolvidas durante a pesquisa de arquivos. Para o armazenamento do Azure, você deve especificar um contêiner de blob como o sistema de arquivos padrão.
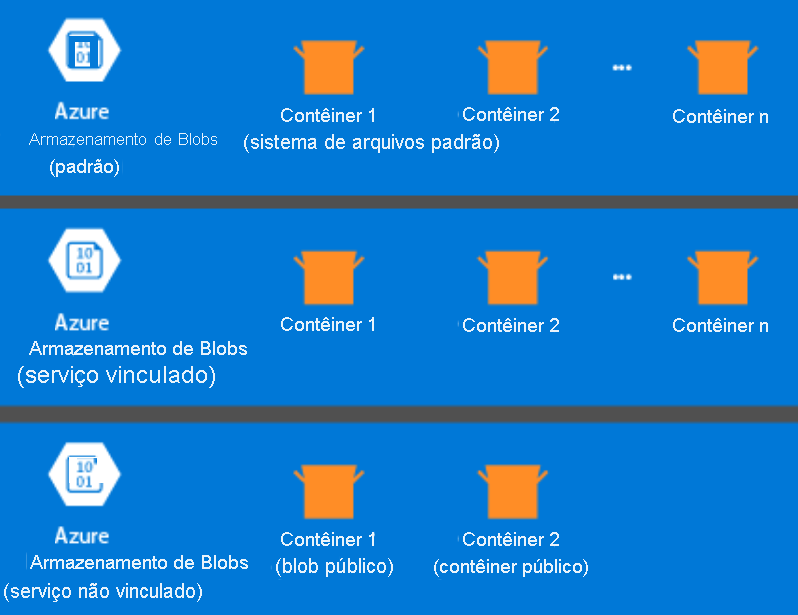
A maioria das configurações usa o Azure Data Lake Storage Gen2. Esse tipo de configuração usa os principais recursos de um sistema de arquivos compatíveis com Hadoop, integração do Microsoft Entra e ACLs (listas de controle de acesso) baseadas em POSIX. Você pode usar o Armazenamento de Blobs do Azure para compatibilidade com versões anteriores, mas é altamente recomendável usar o Azure Data Lake Storage Gen2 sempre que possível.
Processing
Durante o processamento de dados, o aspecto de computação de um cluster do Hadoop no HDInsight é dividido em duas áreas lógicas. Nós de cabeçalho (mestres) e nós de trabalho. O nó de cabeçalho (mestre) é responsável por aceitar e gerenciar solicitações de cliente e passar a solicitação para os nós de trabalho para executar o processamento dos dados. Normalmente, há dois nós mestres. Um nó mestre ativo que gerenciará as conexões do cliente. Um segundo nó mestre passivo que fornece resiliência no evento o primário deve ficar offline.
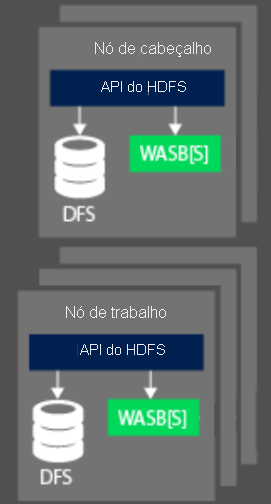
O nó de trabalho é responsável por processar os dados que foram atribuídos a ele pelo nó mestre. Os dados gerenciados dependem de como o modelo de programação MapReduce definiu como trabalhar com os dados e como o nó mestre aloca o trabalho. O nó de trabalho e cabeçalho pode se conectar diretamente a um DFS (Sistema de Arquivos Distribuído) anexado localmente ou acessar dados armazenados no Blob do Azure ou no Azure Data Lake.
Do ponto de vista do software livre, as funcionalidades de gerenciamento de recursos de um cluster HDInsight são executadas pelo YARN. Esse serviço gerencia os recursos e a programação de trabalho que é executada quando você está processando dados. Ele fica entre o HDFS e o sistema de computação do cluster do HDInsight. O serviço funciona com outras tecnologias de software livre para garantir que os recursos para processar o trabalho do HDInsight estejam disponíveis. O YARN funciona com o nó de cabeçalho para distribuir o trabalho entre os nós de trabalho do cluster para garantir que os trabalhos de processamento de dados sejam paralelizados.
HDFS, YARN e MapReduce são os três principais serviços necessários para o Hadoop no HDInsight. É comum usar tecnologias de software livre adicionais para facilitar a criação de uma solução. Por exemplo, você pode usar o Hive como uma camada de abstração. Uma que fica sobre o MapReduce para que você possa escrever construções de linguagem do tipo SQL para executar o processamento e a análise de dados ad hoc. Outra opção é pode usar o Apache Ambari para executar o monitoramento no cluster do HDInsight.