Modelos de linguagem semântica
Observação
Consulte a guia Texto e imagens para obter mais detalhes!
Como o estado da arte para NLP avançou, a capacidade de treinar modelos que encapsulam a relação semântica entre tokens levou ao surgimento de poderosos modelos de linguagem de aprendizado profundo. No cerne desses modelos está a codificação dos tokens de linguagem como vetores (matrizes de valores múltiplos) conhecidos como inserções.
Essa abordagem baseada em vetor para modelagem de texto tornou-se comum com técnicas como Word2Vec e GloVe, nas quais tokens de texto são representados como vetores densos com várias dimensões. Durante o treinamento de modelo, os valores de dimensão são atribuídos para refletir características semânticas de cada token com base em seu uso no texto de treinamento. As relações matemáticas entre os vetores podem então ser exploradas para executar tarefas comuns de análise de texto com mais eficiência do que técnicas puramente estatísticas mais antigas. Um avanço mais recente nessa abordagem é usar uma técnica chamada atenção para considerar cada token no contexto e calcular a influência dos tokens ao seu redor. As inserções contextualizadas resultantes, como as encontradas na família gpt de modelos, fornecem a base da IA generativa moderna.
Representando o texto como vetores
Os vetores representam pontos no espaço multidimensional, definidos por coordenadas ao longo de vários eixos. Cada vetor descreve uma direção e uma distância da origem. Tokens semanticamente semelhantes devem resultar em vetores que têm uma orientação semelhante– em outras palavras, eles apontam em direções semelhantes.
Por exemplo, considere as seguintes inserções tridimensionais para algumas palavras comuns:
| Palavra | Vector |
|---|---|
dog |
[0.8, 0.6, 0.1] |
puppy |
[0.9, 0.7, 0.4] |
cat |
[0.7, 0.5, 0.2] |
kitten |
[0.8, 0.6, 0.5] |
young |
[0.1, 0.1, 0.3] |
ball |
[0.3, 0.9, 0.1] |
tree |
[0.2, 0.1, 0.9] |
Podemos visualizar esses vetores no espaço tridimensional, conforme mostrado aqui:

Os vetores para "dog" e "cat" são semelhantes (ambos animais domésticos), como são "puppy" e "kitten" (ambos animais jovens). As palavras "tree", "young"e ball" têm orientações vetoriais distintamente diferentes, refletindo seus diferentes significados semânticos.
A característica semântica codificada nos vetores possibilita o uso de operações baseadas em vetor que comparam palavras e permitem comparações analíticas.
Localizando termos relacionados
Como a orientação dos vetores é determinada por seus valores de dimensão, palavras com significados semânticos semelhantes tendem a ter orientações semelhantes. Isso significa que você pode usar cálculos como a similaridade de cosseno entre vetores para fazer comparações significativas.
Por exemplo, para determinar o "elemento destoante" entre "dog", "cat" e "tree", você pode calcular a similaridade do cosseno entre pares de vetores. A similaridade do cosseno é calculada como:
cosine_similarity(A, B) = (A · B) / (||A|| * ||B||)
Onde A · B está o produto ponto e ||A|| é a magnitude do vetor A.
Calculando semelhanças entre as três palavras:
dog[0.8, 0.6, 0.1] ecat[0.7, 0.5, 0.2]:- Produto ponto: (0,8 × 0,7) + (0,6 × 0,5) + (0,1 × 0,2) = 0,56 + 0,30 + 0,02 = 0,88
- Magnitude de
dog: √(0,8² + 0,6² + 0,1²) = √(0,64 + 0,36 + 0,01) = √1,01 ≈ 1,005 - Magnitude de
cat: √(0,7² + 0,5² + 0,2²) = √(0,49 + 0,25 + 0,04) = √0,78 ≈ 0,883 - Similaridade cosseno: 0,88 / (1,005 × 0,883) ≈ 0,992 (alta similaridade)
dog[0.8, 0.6, 0.1] etree[0.2, 0.1, 0.9]:- Produto ponto: (0,8 × 0,2) + (0,6 × 0,1) + (0,1 × 0,9) = 0,16 + 0,06 + 0,09 = 0,31
- Magnitude de
tree: √(0,2² + 0,1² + 0,9²) = √(0,04 + 0,01 + 0,81) = √0,86 ≈ 0,927 - Similaridade cosseno: 0,31 / (1,005 × 0,927) ≈ 0,333 (similaridade baixa)
cat[0.7, 0.5, 0.2] etree[0.2, 0.1, 0.9]:- Produto ponto: (0,7 × 0,2) + (0,5 × 0,1) + (0,2 × 0,9) = 0,14 + 0,05 + 0,18 = 0,37
- Similaridade cosseno: 0,37 / (0,883 × 0,927) ≈ 0,452 (similaridade baixa)
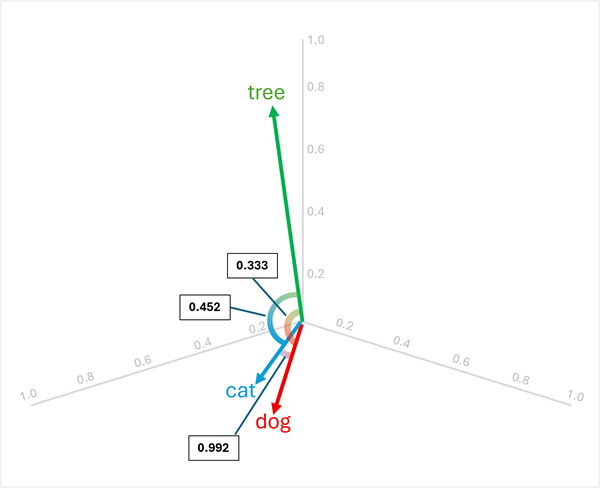
Os resultados mostram isso "dog" e "cat" são altamente semelhantes (0,992), enquanto "tree" têm menor semelhança com ambos "dog" (0,333) e "cat" (0,452). Portanto, tree é claramente a exceção.
Tradução de vetor por meio de adição e subtração
Você pode adicionar ou subtrair vetores para produzir novos resultados baseados em vetor; que podem ser usados para localizar tokens com vetores correspondentes. Essa técnica permite que a lógica baseada em aritmética intuitiva determine os termos apropriados com base nas relações linguísticas.
Por exemplo, usando os vetores anteriores:
-
dog+young= [0,8, 0,6, 0,1] + [0,1, 0,1, 0,3] = [0,9, 0,7, 0,4] =puppy -
cat+young= [0,7, 0,5, 0,2] + [0,1, 0,1, 0,3] = [0,8, 0,6, 0,5] =kitten
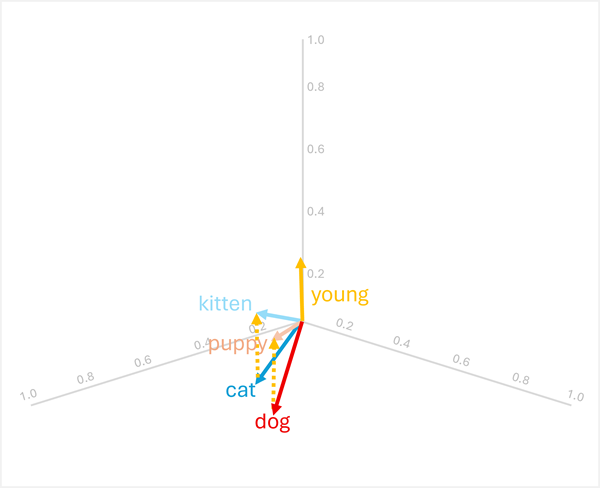
Essas operações funcionam porque o vetor para "young" codifica a transformação semântica de um animal adulto para seu jovem equivalente.
Observação
Na prática, a aritmética de vetor raramente produz correspondências exatas; em vez disso, você procuraria a palavra cujo vetor está mais próximo (mais semelhante) ao resultado.
A aritmética também funciona no sentido inverso:
-
puppy-young= [0,9, 0,7, 0,4] - [0,1, 0,1, 0,3] = [0,8, 0,6, 0,1] =dog -
kitten-young= [0,8, 0,6, 0,5] - [0,1, 0,1, 0,3] = [0,7, 0,5, 0,2] =cat
Raciocínio analógico
A aritmética vetorial também pode responder a perguntas de analogia como "
Para resolver isso, calcule: kitten - puppy + dog
- [0.8, 0.6, 0.5] - [0.9, 0.7, 0.4] + [0.8, 0.6, 0.1]
- = [-0,1, -0,1, 0,1] + [0,8, 0,6, 0,1]
- = [0,7, 0,5, 0,2]
- =
cat
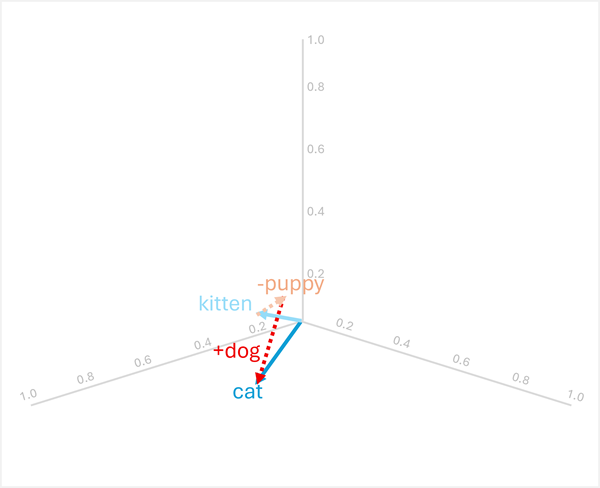
Esses exemplos demonstram como as operações de vetor podem capturar relações linguísticas e habilitar o raciocínio sobre padrões semânticos.
Usando modelos semânticos para análise de texto
Os modelos semânticos baseados em vetor fornecem recursos avançados para muitas tarefas comuns de análise de texto.
Resumo de texto
As incorporações semânticas permitem o resumo extrativo identificando sentenças com vetores que são mais representativos do documento como um todo. Ao codificar cada frase como um vetor (geralmente fazendo uma média ou agrupando as inserções de suas palavras constituintes), você pode calcular quais frases são mais centrais para o significado do documento. Essas frases centrais podem ser extraídas para formar um resumo que captura os principais temas.
Extração de palavras-chave
A similaridade de vetor pode identificar os termos mais importantes em um documento comparando a inserção de cada palavra à representação semântica geral do documento. Palavras cujos vetores são mais semelhantes ao vetor do documento, ou mais centrais ao considerar todos os vetores de palavra no documento, provavelmente serão termos-chave que representam os principais tópicos.
Reconhecimento de entidade nomeada
Modelos semânticos podem ser ajustados para reconhecer entidades nomeadas (pessoas, organizações, locais etc.) aprendendo representações de vetor que agrupam tipos de entidade semelhantes. Durante a inferência, o modelo examina a inserção de cada token e seu contexto para determinar se ele representa uma entidade nomeada e, em caso afirmativo, qual tipo.
Classificação de texto
Para tarefas como análise de sentimento ou categorização de tópicos, os documentos podem ser representados como vetores agregados (como a média de todas as inserções de palavras no documento). Esses vetores de documento podem então ser usados como recursos para classificadores de machine learning ou comparados diretamente com vetores de protótipo de classe para atribuir categorias. Como documentos semanticamente semelhantes têm orientações de vetor semelhantes, essa abordagem efetivamente agrupa conteúdo relacionado e distingue diferentes categorias.