Avaliar o desempenho da consulta com planos de execução e DMVs
Quando uma consulta é executada mais lentamente do que o esperado, a primeira etapa é entender como o mecanismo de banco de dados o executa. Os planos de execução mostram os operadores exatos, os métodos de acesso a dados e os custos de recursos que o otimizador escolheu para uma consulta. As DMVs (visões de gerenciamento dinâmico) complementam isso expondo dados de desempenho em tempo de execução em todas as consultas no banco de dados, para que você possa encontrar as mais caras antes de se aprofundar em qualquer plano específico.
Ler planos de execução
Um plano de execução é o conjunto de instruções que o otimizador de consulta produz para recuperar e processar dados. Ele define quais tabelas acessar primeiro, se devem usar índices ou tabelas de verificação e como unir, filtrar, classificar e agregar resultados. O otimizador avalia vários planos candidatos e seleciona aquele com o menor custo estimado.
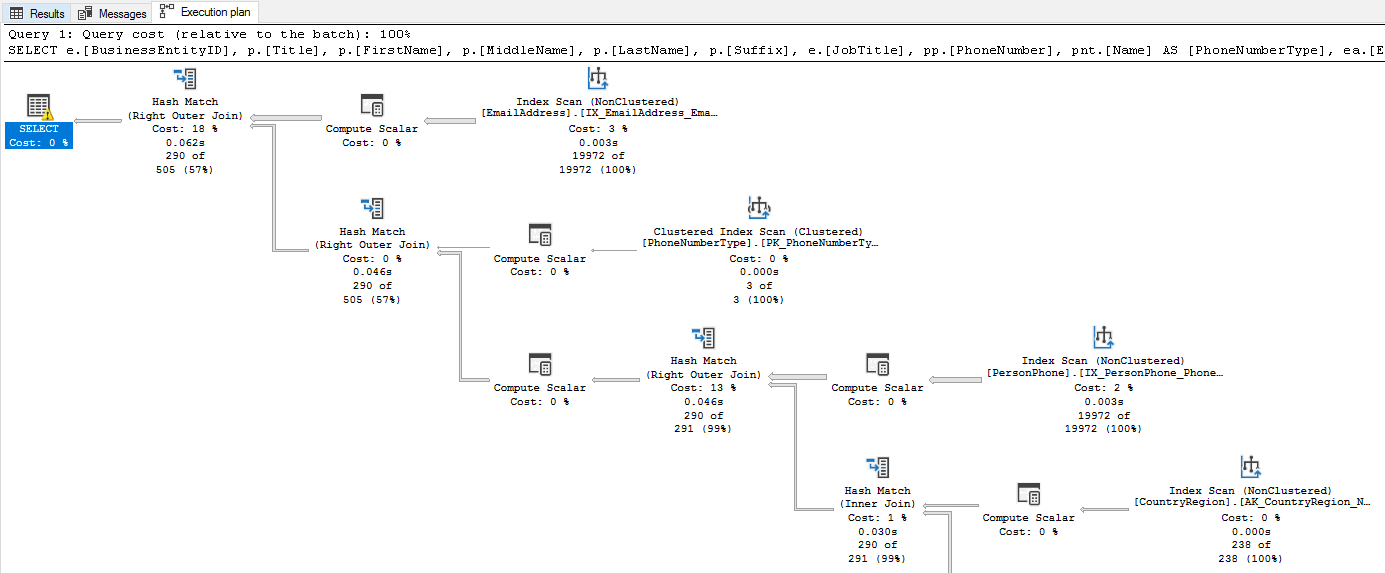
Há dois tipos de planos de execução:
- Plano de execução estimado: gerado sem executar a consulta. Mostra os operadores planejados e as contagens de linhas estimadas com base nas estatísticas. Use planos estimados para análise rápida sem afetar o banco de dados.
- Plano de execução real: capturado durante a execução da consulta. Ele inclui o plano estimado mais contagens de linhas reais, tempos de execução reais, concessões de memória e avisos. O plano real revela discrepâncias entre o que o otimizador esperava e o que realmente aconteceu.
Para exibir um plano estimado, execute SET SHOWPLAN_XML ON antes da consulta ou selecione Exibir Plano de Execução Estimado no SSMS (SQL Server Management Studio). Para capturar um plano real, execute SET STATISTICS XML ON ou selecione Incluir Plano de Execução Real no SSMS antes de executar a consulta.
Embora os planos estimados e reais sejam semelhantes, as métricas de runtime do plano real são cruciais para diagnosticar problemas de desempenho. Por exemplo, se a contagem de linhas estimada para uma verificação de tabela for 100, mas a contagem real de linhas for de 10.000, isso poderá indicar estatísticas desatualizadas que levam a uma escolha de plano inválida. O otimizador compila o plano com base em estatísticas na primeira vez que encontra uma consulta. Se essas estatísticas não refletirem a distribuição de dados atual, o plano poderá ter um desempenho ruim.
Identificar problemas comuns em planos de execução
Os planos de execução são lidos da esquerda para a direita, de cima para baixo. Os primeiros operadores acessam as tabelas base e o operador final produz o resultado da consulta. Verifique estes problemas comuns:
Os tipos de operador informam como o mecanismo acessa os dados. Há muitos tipos de operador, cada um representando um método diferente de recuperação ou processamento de dados. Por exemplo, um operador index seek representa um método altamente eficiente que direciona linhas específicas usando chaves de índice. Um operador de Verificação de Tabela ou Verificação de Índice , por outro lado, representa um método menos eficiente que lê todas as linhas. Se você vir uma verificação em uma tabela grande, provavelmente precisará de um índice. Por exemplo, se o aplicativo de comércio eletrônico consultar pedidos por data e o plano mostrar um Exame de índice clusterizado na tabela Orders, adicionar um índice não clusterizado na coluna OrderDate poderá transformar essa verificação em uma busca. Nem todas as verificações são ruins. Se uma tabela for pequena ou a condição de pesquisa retornar a maioria das linhas em uma tabela, uma verificação poderá ser o método de acesso mais eficiente. Sempre considere o contexto da consulta e o tamanho dos dados. Conheça seus dados e use planos de execução para confirmar se o método de acesso faz sentido.
As contagens de linhas estimadas versus reais revelam se as suposições do otimizador correspondem à realidade. O otimizador baseia seu plano em estatísticas, metadados que descrevem a distribuição e a densidade de dados em suas tabelas. Se essas estatísticas estiverem obsoletas, as contagens de linhas estimadas e reais divergirão. Quando o otimizador subestima a contagem de linhas, ele pode escolher uma junção de loop aninhado (que processa uma linha de cada vez da tabela interna de uma junção) quando uma junção hash (que cria uma tabela de hash na memória para buscas rápidas) seria mais rápida, ou pode alocar pouca memória para uma operação de classificação. As estatísticas podem ficar obsoletas após alterações significativas de dados, portanto, atualizar estatísticas com UPDATE STATISTICS ou habilitar atualizações automáticas de estatísticas pode ajudar o otimizador a tomar decisões melhores.
Os operadores de Pesquisa de Chave aparecem quando o mecanismo encontra linhas por meio de um índice não clusterizado, mas precisa de colunas extras do índice clusterizado. Para cada linha correspondente, o mecanismo executa uma viagem de ida e volta extra para o índice clusterizado para recuperar essas colunas. Se o filtro retornar muitas linhas, essas consultas extras se acumularão rapidamente. Por exemplo, se o aplicativo de comércio eletrônico filtrar os pedidos por CustomerID, mas também selecionar OrderDate, TotalAmount e ShippingAddress, e o índice não clusterizado em CustomerID não incluir essas colunas, o plano mostrará uma Pesquisa de Chave para cada pedido correspondente. Você pode eliminar pesquisas de chave adicionando as colunas ausentes como colunas incluídas no índice. Tenha em mente que as colunas incluídas aumentam o tamanho do índice, o que pode diminuir a velocidade das gravações, portanto, avalie o benefício de desempenho de leitura em relação à sobrecarga de gravação.
Setas espessas entre operadores representam o número de linhas que fluem entre eles. Uma seta inesperadamente grossa no início do plano (lendo da esquerda para a direita, de cima para baixo) geralmente significa que um filtro ou índice ausente está deixando muitas linhas passarem.
As sugestões de índice ausentes aparecem como texto realçado verde na parte superior do plano de execução gráfica no SSMS. Quando o otimizador detecta que um índice poderia reduzir significativamente o custo de uma consulta, ele apresenta uma recomendação diretamente no plano. Clique com o botão direito do mouse na sugestão e selecione Detalhes de índice ausentes para gerar uma CREATE INDEX instrução que você pode avaliar e executar. Essas sugestões são uma das vitórias mais fáceis que você pode obter lendo um plano de execução.
Os avisos aparecem como um triângulo amarelo com um ponto de exclamação (⚠) no operador afetado. Cada aviso aponta para uma oportunidade de otimização. Os avisos comuns incluem:
- Estatísticas ausentes: o otimizador não conseguiu encontrar estatísticas para uma coluna, portanto, ele adivinhou em contagens de linhas em vez de usar a distribuição de dados real. Para corrigir esse problema, crie estatísticas nas colunas usadas em suas consultas ou atualize as estatísticas existentes se elas estiverem obsoletas.
- Concessão excessiva de memória: a consulta solicitou mais memória do que precisava, desperdiçando recursos que outras consultas poderiam usar. Esse problema geralmente acontece quando o otimizador superestima as contagens de linhas. Atualizar estatísticas ou reescrever a consulta para filtrar linhas anteriormente pode ajudar a reduzir as concessões de memória.
-
Sem Predicado de Junção: duas tabelas são unidas sem uma condição adequada, produzindo um produto Cartesiano que retorna todas as combinações de linhas possíveis. Verifique se há uma cláusula
ONausente ou incorreta na consulta. -
Conversão implícita: uma incompatibilidade de tipo de dados força o mecanismo a converter valores em runtime, o que pode transformar uma busca de índice em uma verificação. Por exemplo, se uma
WHEREcláusula comparar umnvarcharparâmetro a umavarcharcoluna, o mecanismo converte cada linha da coluna paranvarcharantes da comparação. Para corrigir conversões implícitas, alinhe os tipos de dados dos seus parâmetros de consulta com as definições de coluna. -
Classificar ou derramar hash: uma operação de classificação ou hash ficou sem sua memória concedida e derramou resultados intermediários para tempdb. Essas operações são o segundo driver mais comum de alta CPU após verificações. Se você vir um aviso de derramamento, o otimizador provavelmente subestimou as contagens de linhas e solicitou pouca memória. A execução de
UPDATE STATISTICSpara atualizar as estatísticas da tabela ou reescrever a consulta para reduzir o número de linhas antes da classificação frequentemente pode eliminar o derramamento.
Os planos de execução são uma ferramenta poderosa para entender o desempenho da consulta. Eles mostram exatamente como o mecanismo executa uma consulta e onde estão os gargalos. Ao aprender a ler os planos de execução com eficiência, você pode identificar e corrigir rapidamente problemas de desempenho em suas consultas de banco de dados.
Consultar DMVs para dados de desempenho de tempo de execução
As DMVs expõem dados de desempenho em tempo real e acumulados do mecanismo de banco de dados. O Banco de Dados SQL do Azure requer VIEW DATABASE STATE permissão para consultá-los. Embora os planos de execução mostrem como uma única consulta é executada, os DMVs mostram o que está acontecendo em todas as consultas, o que ajuda você a encontrar as mais caras primeiro.
Localizar as consultas mais caras
Tempo de CPU, leituras lógicas e contagem de execução são as métricas mais comuns para identificar consultas caras. O tempo alto da CPU ou as leituras lógicas indicam que uma consulta é intensiva em recursos, enquanto uma alta contagem de execução significa que até mesmo uma consulta moderadamente cara pode ter um grande impacto no desempenho geral. Comece examinando as principais consultas por tempo médio de CPU ou leituras lógicas para localizar candidatos à otimização.
sys.dm_exec_query_stats retorna estatísticas de desempenho agregadas para planos de consulta armazenados em cache. Una-o a sys.dm_exec_sql_text para ver o texto da consulta e sys.dm_exec_query_plan para recuperar o plano de execução.
A consulta a seguir localiza as 10 principais consultas por tempo médio de CPU:
SELECT TOP 10
qs.total_worker_time / qs.execution_count AS avg_cpu_time,
qs.execution_count,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
SUBSTRING(st.text, (qs.statement_start_offset / 2) + 1,
((CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset) / 2) + 1) AS query_text
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS st
ORDER BY avg_cpu_time DESC;
Esse script ajuda você a identificar quais consultas merecem sua atenção. Valores elevados avg_logical_reads em relação ao tamanho do conjunto de resultados geralmente apontam para índices ausentes ou planos ineficazes. No entanto, tenha cuidado ao interpretar esses resultados. Uma consulta com tempo médio alto de CPU que é executada apenas uma vez por dia pode importar menos do que uma consulta moderada que é executada milhares de vezes por hora. Sempre considere o custo médio e a contagem de execução quando você priorizar. Você também pode ordenar por avg_logical_reads para encontrar consultas que são intensas em E/S, o que frequentemente indica índices ausentes ou métodos de acesso ineficientes.
Verificar as consultas em execução no momento
Embora a consulta anterior mostre as consultas históricas mais caras no cache de planos, sys.dm_exec_requests fornece um instantâneo de cada solicitação que está em execução no momento. Ele inclui colunas para tempo de CPU, leituras, gravações, tipo de espera, tempo de espera e ID de sessão de bloqueio. Use essa exibição para detectar consultas ativas que estão consumindo muitos recursos ou aguardando bloqueios. Esta visualização é uma das DMVs mais importantes para o monitoramento de desempenho em tempo real e a solução de problemas.
SELECT
r.session_id,
r.status,
r.command,
r.wait_type,
r.wait_time,
r.blocking_session_id,
r.cpu_time,
r.logical_reads,
t.text AS query_text
FROM sys.dm_exec_requests AS r
CROSS APPLY sys.dm_exec_sql_text(r.sql_handle) AS t
WHERE r.session_id > 50
ORDER BY r.cpu_time DESC;
Essa consulta filtra as sessões do sistema (IDs de sessão 1 a 50) e os pedidos por tempo de CPU. Você também pode ordenar por logical_reads para localizar consultas de E/S pesadas. As colunas wait_type e wait_time ajudam a identificar se uma consulta está esperando por bloqueios, operações de E/S ou outros recursos.
Descobrir índices ausentes
Anteriormente, vimos como os planos de execução podem mostrar sugestões de índice ausentes para uma única consulta. As DMVs de índice ausentes oferecem uma visão mais ampla de quais índices o otimizador usaria em todas as consultas se elas existissem. Essas visualizações são uma excelente maneira de identificar oportunidades de otimização que impactam várias consultas.
sys.dm_db_missing_index_details mostra a tabela, bem como as colunas de igualdade, desigualdade e as colunas incluídas.
sys.dm_db_missing_index_group_stats fornece uma medida de melhoria que estima a redução de custos.
SELECT
mid.statement AS table_name,
mid.equality_columns,
mid.inequality_columns,
mid.included_columns,
migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans) AS improvement_measure
FROM sys.dm_db_missing_index_groups AS mig
INNER JOIN sys.dm_db_missing_index_group_stats AS migs
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid
ON mig.index_handle = mid.index_handle
ORDER BY improvement_measure DESC;
Essa consulta calcula uma improvement_measure para cada recomendação de índice ausente, que é um produto do custo médio das consultas que se beneficiariam do índice, da melhoria média do percentual e do número de vezes que essas consultas foram executadas. A classificação por essa medida ajuda você a priorizar quais índices ausentes criar primeiro. No entanto, lembre-se de que esses resultados são apenas recomendações com base nas consultas atualmente no cache do plano. Analise sempre as colunas de índice sugeridas e teste o impacto delas no desempenho da consulta e na sobrecarga de gravação antes de adicioná-las à produção.
Observação
Recomendações de índice ausentes são sugestões, não diretivas. Sempre teste o impacto de um novo índice tanto no desempenho de consultas quanto na carga de gravação antes de adicioná-lo à produção.
Monitorar sessões ativas e tarefas de espera
sys.dm_exec_sessions fornece informações sobre todas as sessões autenticadas, incluindo tempo de início de sessão, nome do host, nome do programa, e CPU e leituras cumulativas. Combine com sys.dm_os_waiting_tasks para ver quais tarefas estão aguardando e quais recursos estão esperando. Essas visualizações se tornam essenciais quando você diagnostica bloqueio e contenção de recursos em uma unidade futura.
Colocar tudo isso junto
Planos de execução e DMVs fornecem uma visão completa do comportamento da consulta. Comece com as DMVs para identificar as consultas mais caras. Em seguida, analise seus planos de execução para entender por que eles são caros. É um índice ausente que está causando uma verificação? Estatísticas desatualizadas causando erros de estimativa de linhas? Uma pesquisa de chave que você pode eliminar? Essa abordagem sistemática, da visão de todo o sistema à análise de consulta individual, é a maneira mais eficiente de encontrar e corrigir gargalos de desempenho.
Principais conclusões
Os planos de execução revelam a estratégia do otimizador para uma consulta e os planos reais incluem métricas de runtime que expõem discrepâncias entre contagens de linhas estimadas e reais. Ao ler um plano, concentre-se nos tipos de operador (busca versus escaneamento), estimativas de contagem de linhas, avisos e operadores de Key Lookup. As DMVs fornecem dados de desempenho em todo o sistema: use sys.dm_exec_query_stats para localizar as consultas mais caras, sys.dm_exec_requests para consultas em execução no momento e as DMVs de índice ausentes para oportunidades de otimização. Comece com as DMVs para identificar onde estão os maiores problemas e, em seguida, analise os planos de execução individuais para entender o motivo.