Transformar dados com operadores
Embora muitos operadores no Data Wrangler sejam intuitivos e fáceis de usar, outros exigem uma compreensão mais profunda para usá-los completamente.
Usar um operador de codificação one-hot
Alguns modelos de machine learning, como regressão linear, exigem que todas as variáveis de entrada e saída sejam numéricas e não ofereçam suporte a variáveis categóricas. Dados categóricos referem-se a variáveis divididas em várias categorias que não carregam um valor numérico ou ordem.
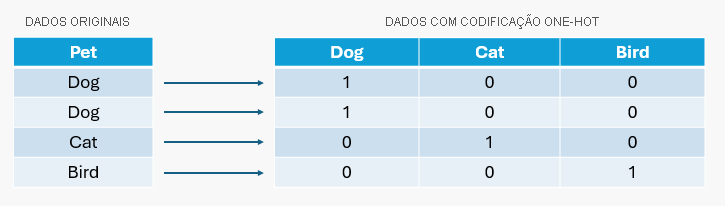
Em uma codificação one-hot, cada categoria em um recurso é representada como um vetor binário de 1 e 0.
Por exemplo, se você tiver uma variável de animal de estimação com os valores dog, cat e bird, três novas variáveis serão criadas (uma para cada tipo de animal de estimação). Para cada ponto de dados, ele marca 1 para o animal de estimação que ele representa e 0 para os outros. Portanto, se um ponto de dados representa um cão, ele é codificado como [1, 0, 0]. Se é um gato, é [0, 1, 0], e se é um pássaro, é [0, 0, 1].
Observação
A codificação one-hot pode levar a um aumento da dimensionalidade, que é quando o número de recursos no conjunto de dados se torna muito grande. Esse é particularmente o caso em que a variável categórica tem muitos valores exclusivos.
Vamos criar um dataframe com base no exemplo de pet acima e usar o Data Wrangler para gerar o código para codificação one-hot.
import pandas as pd
# Sample dataset with 50 data points, including duplicates
data = {'pet': ['dog', 'dog', 'cat', 'cat', 'bird', 'bird']*8 + ['bird', 'cat']}
df = pd.DataFrame(data)
print(df.head(10))
As etapas a seguir mostram como usar o operador de codificação one-hot para a pet variável.
Iniciar o Estruturador de Dados em um notebook do Microsoft Fabric para o dataframe
df.Selecione a
petvariável.No painel Operações, selecione Fórmulas e Codificação one-hot.
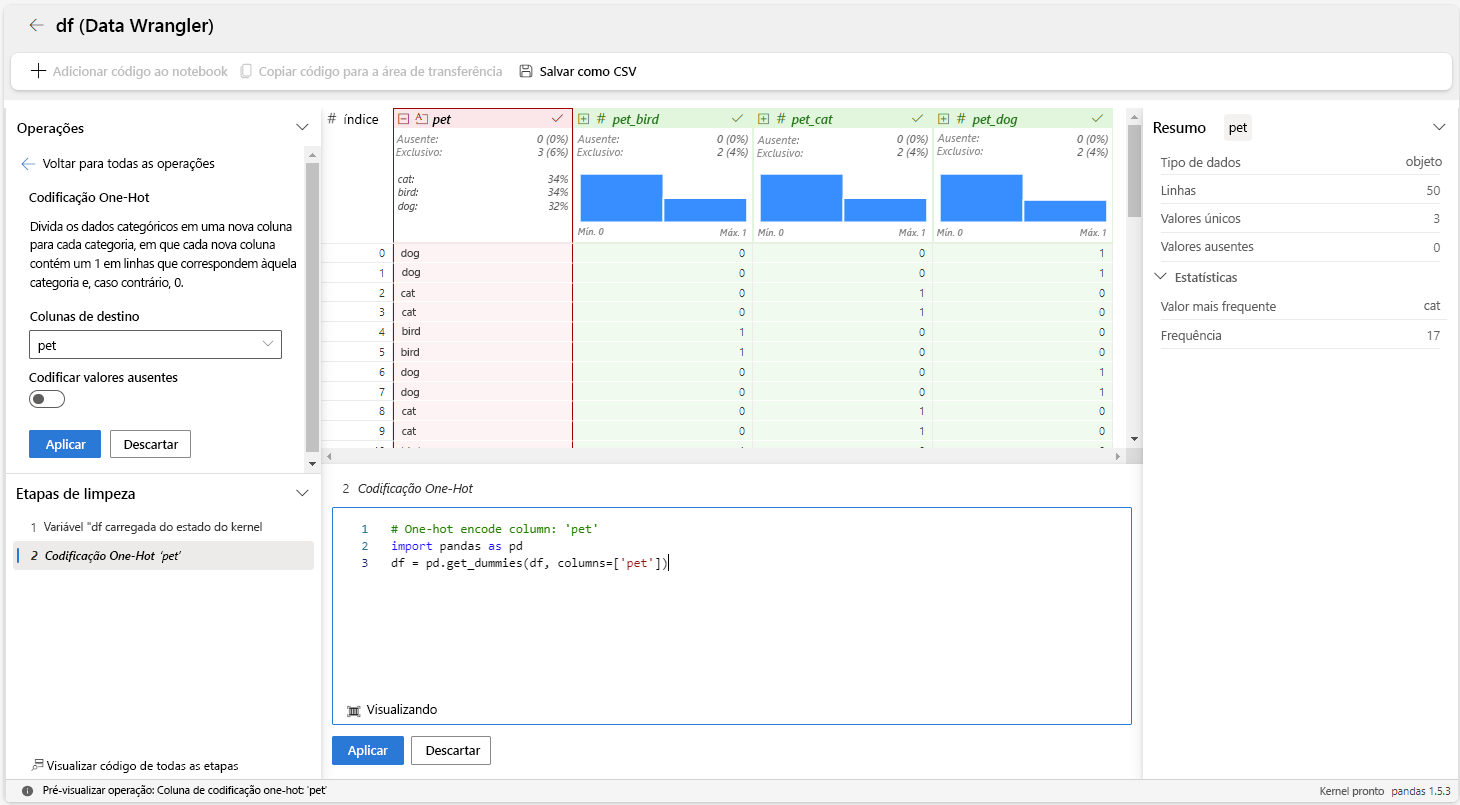
Selecione Aplicar.
Selecione + Adicionar código ao notebook na barra de ferramentas acima da grade do Data Wrangler. Isso gera uma função que você pode executar em seu pipeline de dados.
Usar o operador binarizador de vários rótulos
A codificação one-hot é usada quando cada ponto de dados pertence a exatamente uma categoria. Por outro lado, o operador de binarização para múltiplos rótulos é usado quando cada ponto de dados pode pertencer a várias categorias.
O operador binarizador de vários rótulos permite dividir dados categóricos em uma nova coluna para cada categoria usando um delimitador de divisão de texto, em que cada nova coluna contém um número um em linhas que correspondem a essa categoria e, caso contrário, 0.
Para fins de treinamento, vamos criar um dataframe sobre a categoria de alimentos e usar o Data Wrangler para gerar o código para binarizador de múltiplos rótulos.
import pandas as pd
#Sample data
data = {
'food': ['Pasta', 'Burger', 'Ice Cream', 'Salad'],
'category': ['Italian|Fine dining', 'American|Fast Food', 'Dessert', 'Healthy']
}
# Create DataFrame
restaurant = pd.DataFrame(data)
Em seguida, as etapas a seguir mostram como usar o operador binarizador de vários rótulos para a variável category.
Iniciar o Estruturador de Dados em um notebook do Microsoft Fabric para o dataframe
restaurant.Selecione a
categoryvariável.No painel Operações, selecione Fórmulas e, em seguida, Binarizador de Rótulos Múltiplos.
Digite | como delimeter.
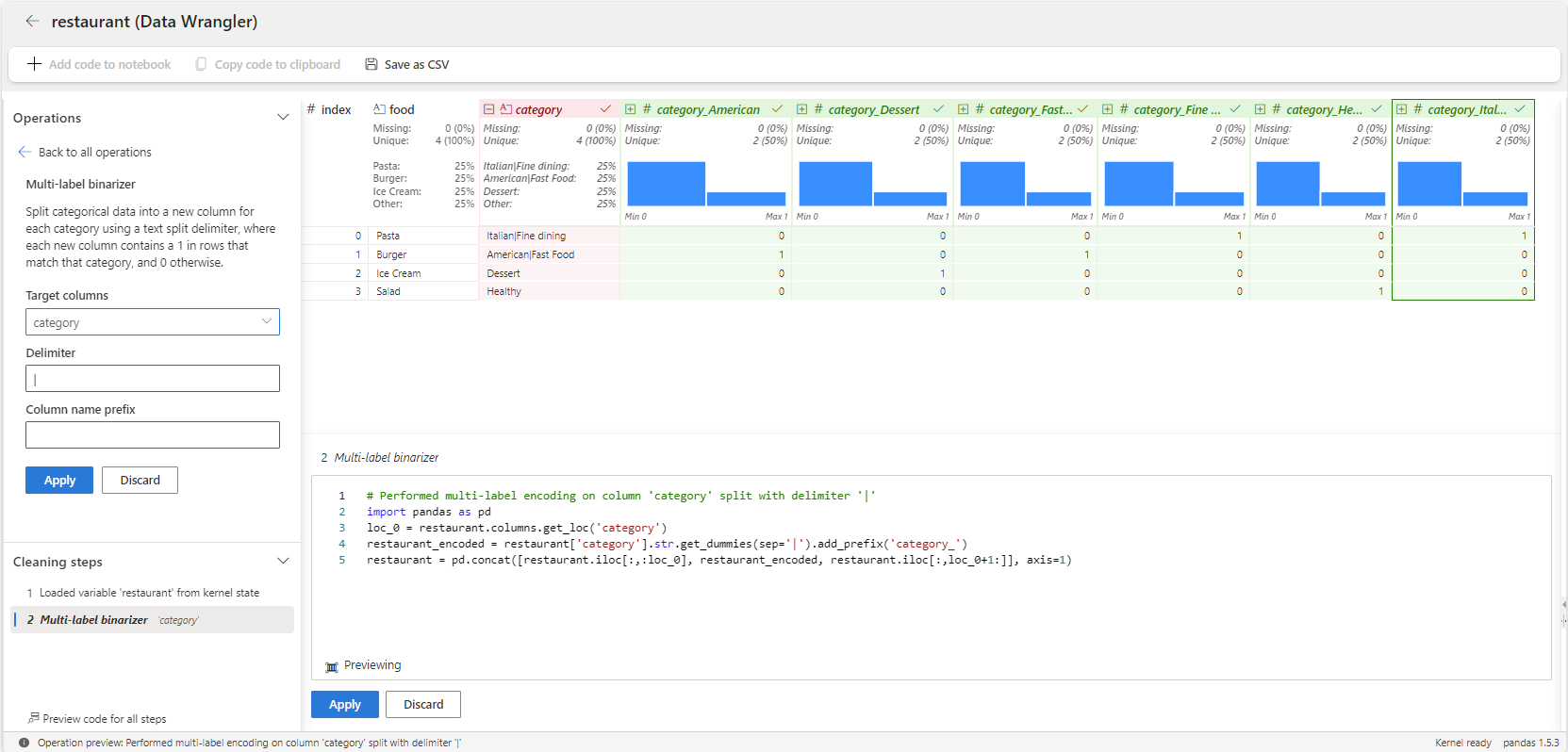
O resultado é um dataframe com variáveis para cada categoria, como Americano, Sobremesa, Fast Food, Íntegro e Italiano. Cada item de alimento é marcado com 1 ou 0 nestas colunas para mostrar a quais categorias ele pertence. Por exemplo, Pizza e Burger se enquadram em várias categorias.
Selecione Aplicar.
Selecione + Adicionar código ao notebook na barra de ferramentas acima da grade do Data Wrangler. Isso gera uma função que você pode executar em seu pipeline de pré-processamento.
Usar operador de escala mín.–máx.
O dimensionamento mínimo máximo ou a normalização mínima máxima é o processo de transformação de um recurso numérico. Esse processo dimensiona o intervalo de seus dados preservando a forma da distribuição original e as relações entre variáveis.
Ele garante que a significância de um recurso seja determinada por seu valor relativo, não pelo seu valor absoluto. Em outras palavras, as características não são consideradas mais importantes simplesmente porque têm escalas maiores.
Ele usa cada valor em seus dados, subtrai o valor mínimo desses dados e, em seguida, divide pelo intervalo dos dados (o valor máximo menos o valor mínimo).
O resultado é que seus dados são redimensionados para um intervalo de 0 a 1 normalmente, o que pode ser útil para determinados tipos de algoritmos de aprendizado de máquina, particularmente aqueles que usam medidas de distância como K-Neighbors Mais Próximos.
Vamos considerar um dataframe que representa as notas dos alunos em uma classe. O dataframe tem três colunas: Student, , Math_Gradee English_GradeHours_Studied.
import pandas as pd
# Sample data
data = {
'Student': ['Bob', 'Mark', 'Anna', 'David', 'Sam'],
'Math_Grade': [85, 90, 78, 92, 88],
'English_Grade': [80, 85, 92, 88, 90],
'Hours_Studied': [250, 500, 355, 245, 199]
}
df = pd.DataFrame(data)
print(df)
A saída é:
Student Math_Grade English_Grade Hours_Studied
0 Bob 85 80 250
1 Mark 90 85 500
2 Anna 78 92 355
3 David 92 88 245
4 Sam 88 90 199
Agora, vamos aplicar o escalonador de min-max às variáveis Math_Grade, English_Grade e Hours_Studied usando o Data Wrangler. Para isso, você precisa usar o operador Dimensionar valores mínimos/máximos na categoria Numérica .
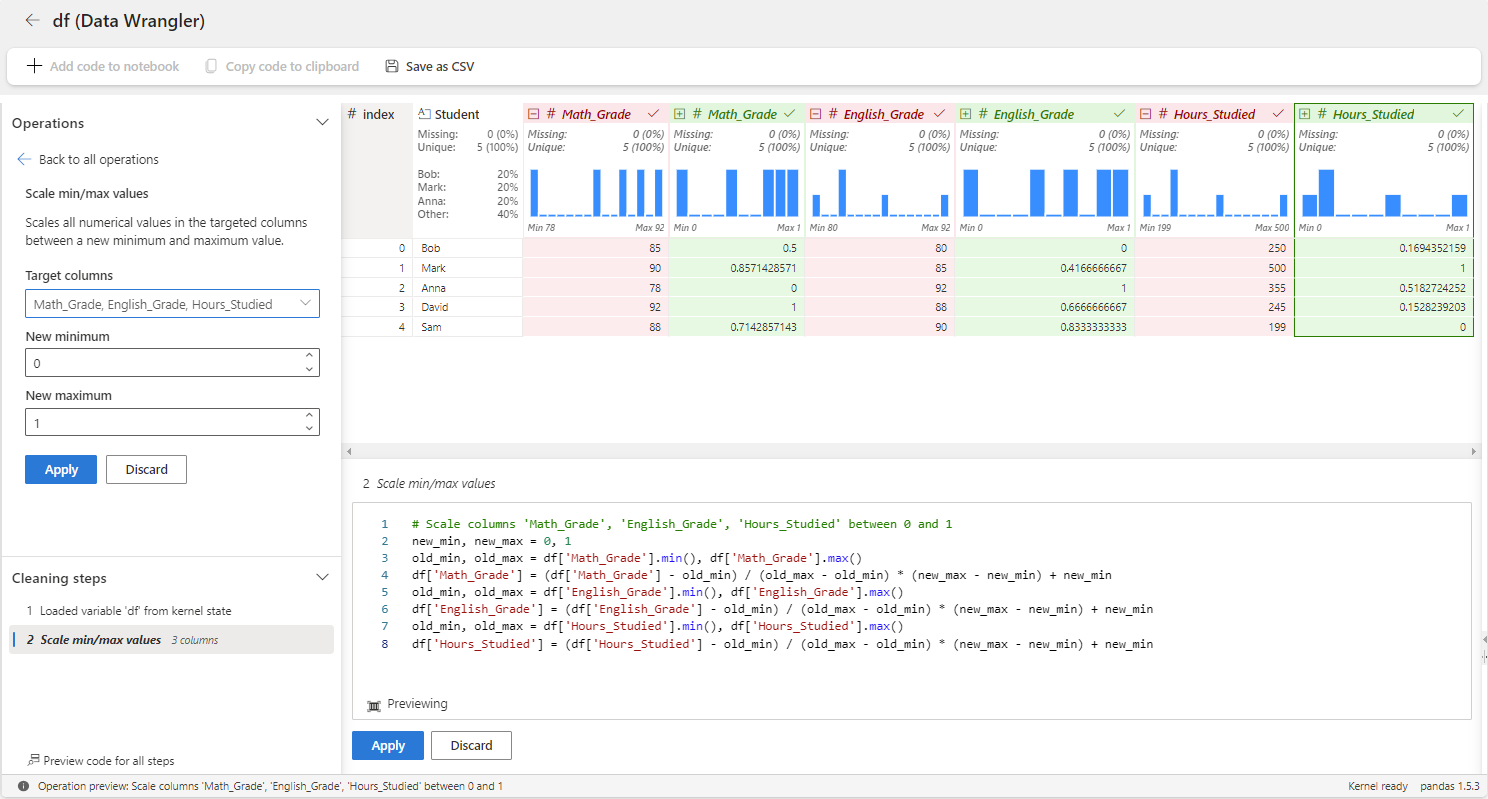
No acima, as notas são dimensionadas para se enquadrarem dentro do intervalo de [0, 1], com a nota mínima mapeada para 0 e a nota máxima mapeada para 1. Outras notas são dimensionadas proporcionalmente dentro desse intervalo. Você também pode ajustar o intervalo mínimo e máximo.
Se você usar recursos como Math_Grade, English_Gradee Hours_Studied em um algoritmo de machine learning baseado em distância, como K-Neighbors mais próximos sem primeiro dimensioná-los, você poderá encontrar alguns problemas.
O Hours_Studied recurso poderia potencialmente dominar os outros recursos devido à sua maior variedade de valores. Isso pode levar a um modelo que depende muito de Hours_Studied, ignorando Math_Grade e English_Grade. Portanto, é importante dimensionar seus dados nesses casos para garantir que todos os recursos recebam igual importância.
Para saber mais sobre a normalização de dados para modelos de machine learning, consulte Transformações de dados.