Explorar a arquitetura da solução
Vamos revisar a arquitetura de MLOps (operações de machine learning) para entender a finalidade do que estamos tentando alcançar.
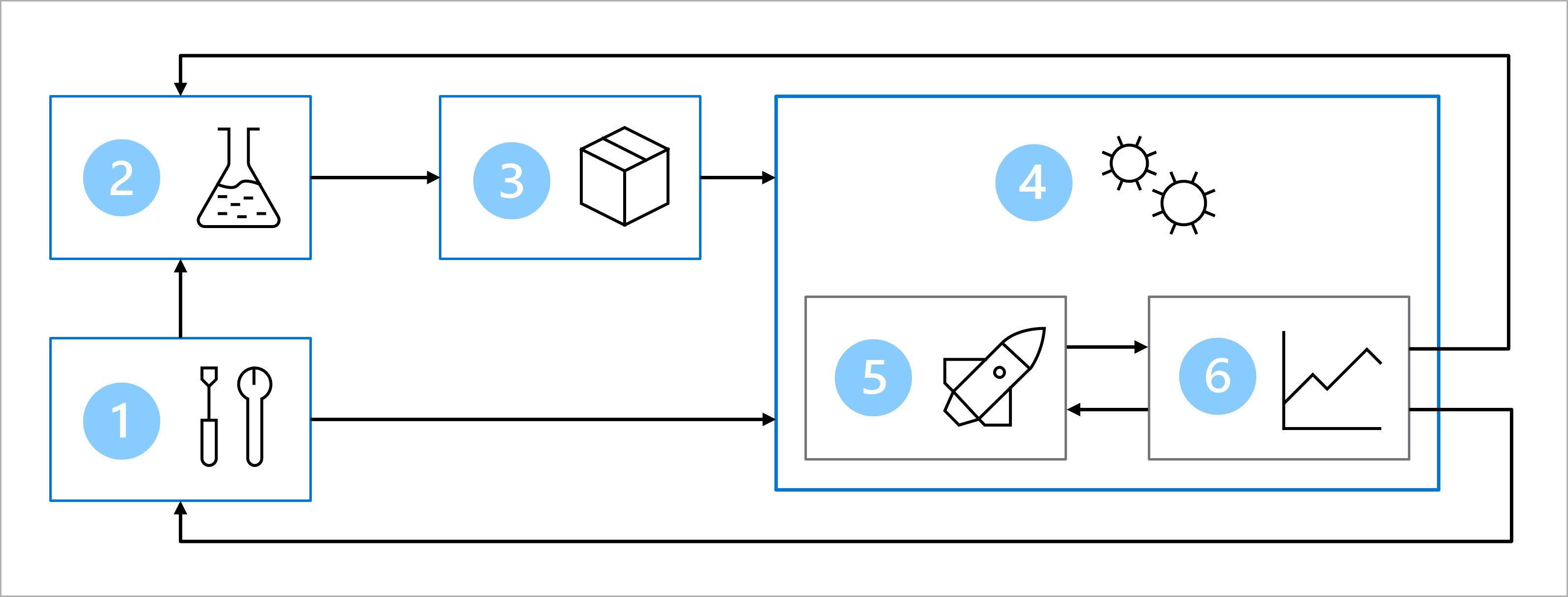
Imagine que, acompanhado da equipe de desenvolvimento de software e ciência de dados, você concordou com a seguinte arquitetura para treinar, testar e implantar o modelo de classificação de dados de diabetes:
Observação
O diagrama é uma representação simplificada de uma arquitetura de MLOps. Para ver uma arquitetura mais detalhada, explore os diversos casos de uso no acelerador de solução de MLOps (v2).
A arquitetura inclui:
- Instalação: criar todos os recursos do Azure necessários para a solução.
- Desenvolvimento de modelo (loop interno): explorar e processar os dados para treinar e avaliar o modelo.
- Integração contínua: empacotar e registrar o modelo.
- Implantação de modelo (loop externo): implantar o modelo.
- Implantação contínua: testar o modelo e promovê-lo ao ambiente de produção.
- Monitoramento: monitorar o desempenho do modelo e do ponto de extremidade.
A equipe de ciência de dados é responsável pelo desenvolvimento do modelo. A equipe de desenvolvimento de software é responsável por integrar o modelo implantado ao aplicativo Web usado pelos profissionais para avaliar se um paciente tem diabetes. Você é responsável por levar o modelo do desenvolvimento à implantação.
Você espera que a equipe de ciência de dados proponha constantemente alterações nos scripts usados para treinar o modelo. Sempre que houver uma alteração no script de treinamento, você precisará treinar novamente o modelo e reimplantar o modelo no ponto de extremidade existente.
Você deseja permitir que a equipe de ciência de dados faça experimentos, sem acessar o código pronto para produção. Você também deseja garantir que qualquer código novo ou atualizado passe automaticamente por verificações de qualidade acordadas. Depois de verificar o código para treinar o modelo, você usará o script de treinamento atualizado para treinar um novo modelo e implantá-lo.
Para controlar as alterações e verificar o código antes de atualizar o código de produção, é necessário trabalhar com branches. Você concordou com a equipe de ciência de dados que sempre que ela quiser fazer uma alteração, ela criará um branch de recursos para criar uma cópia do código e fazer as alterações na cópia.
Qualquer cientista de dados pode criar um branch de recursos e trabalhar nele. Depois que ele atualizar o código e desejar que esse código seja o novo código de produção, ele precisará criar uma solicitação de pull. Na solicitação de pull, as alterações propostas ficarão visíveis para outras pessoas, dando a elas a oportunidade de revisar e discutir as alterações.
Sempre que uma solicitação de pull for criada, o ideal será verificar automaticamente se o código funciona e se a qualidade do código está de acordo com os padrões da sua organização. Depois que o código for aprovado nas verificações de qualidade, o cientista de dados principal precisará analisar as alterações e aprovar as atualizações para que a solicitação de pull seja mesclada e o código na ramificação principal possa ser atualizado de acordo.
Importante
Ninguém nunca deve ter permissão para efetuar push das alterações na ramificação principal. Para proteger seu código, especialmente o código de produção, você deseja impor que a ramificação principal só poderá ser atualizada por meio de solicitações de pull que precisam ser aprovadas.