Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a: .NET Core 2.1, .NET Core 3.1, .NET 5
Este artigo apresenta o processo de reprodução do problema de falha do .NET Core no Linux. Este artigo também discute como verificar a ferramenta Nginx e os logs do sistema em busca de sintomas e indicações de falha.
Pré-requisitos
O requisito mínimo para seguir esses laboratórios de solução de problemas é ter um aplicativo ASP.NET Core para demonstrar problemas de desempenho de baixa CPU e alta CPU.
Você pode encontrar vários aplicativos de amostra para atingir esse objetivo na Internet. Por exemplo, você pode baixar e configurar o exemplo de webapi simples da Microsoft para demonstrar um comportamento indesejável. Ou você pode usar o aplicativo BuggyAmb ASP.NET Core como o projeto de exemplo.
Se você seguiu as partes anteriores desta série, deve ter a seguinte configuração pronta para uso:
- O Nginx está configurado para hospedar dois sites:
- O primeiro escuta solicitações usando o cabeçalho de host myfirstwebsite (
http://myfirstwebsite) e roteando solicitações para o aplicativo de demonstração ASP.NET Core que escuta na porta 5000. - O segundo escuta solicitações usando o cabeçalho de host buggyamb (
http://buggyamb) e roteando solicitações para o segundo aplicativo com bugs de amostra ASP.NET Core que escuta na porta 5001.
- O primeiro escuta solicitações usando o cabeçalho de host myfirstwebsite (
- Ambos os aplicativos ASP.NET Core devem estar em execução como serviços que reiniciam automaticamente quando o servidor é reiniciado ou o aplicativo para de responder.
- O firewall local do Linux é habilitado e configurado para permitir tráfego SSH e HTTP.
Observação
Se sua configuração não estiver pronta, vá para "Parte 2 Criar e executar aplicativos ASP.NET Core".
Para continuar este laboratório, você deve ter pelo menos um aplicativo Web ASP.NET Core problemático que esteja sendo executado por trás do Nginx.
Objetivo deste laboratório
Este artigo é a primeira de duas partes de laboratório. O trabalho de laboratório é dividido da seguinte forma:
Parte 1: Você reproduzirá o problema de travamento, verificará o Nginx e os logs do sistema para pesquisar os sintomas e indicadores de travamento e, em seguida, solucionará o problema gerando um arquivo de despejo de memória. Por fim, você reunirá o arquivo de despejo principal gerado pelo sistema a partir do relatório de falhas gerado pelo gerenciador do Ubuntu, apport.
Parte 2: você instalará e configurará o lldb para trabalhar em conjunto com uma extensão do depurador do .NET Core chamada SOS. Você também analisará o arquivo de despejo em lldb.
Reproduzir um problema de travamento
Ao navegar até a URL http://buggyamb/do site e selecionar o link Páginas de Problemas , você verá links para alguns cenários de problemas. Existem três cenários de travamento diferentes. No entanto, para este laboratório, você solucionará apenas o terceiro cenário de falha.
Antes de selecionar qualquer link, selecione Resultados Esperados e verifique se o aplicativo está funcionando conforme o esperado. Você deve ver uma saída semelhante à seguinte.
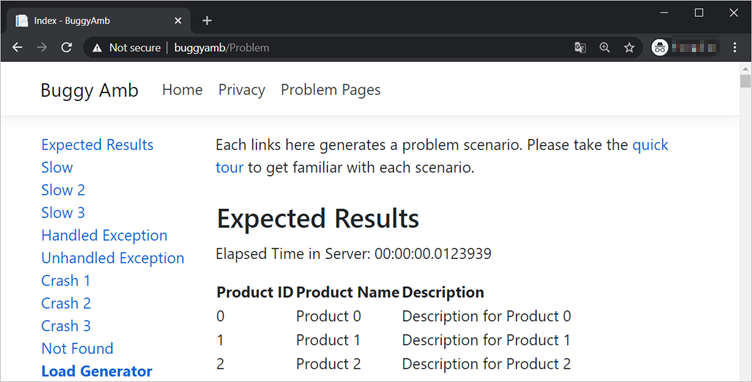
A página deve carregar rapidamente (em menos de um segundo) e exibir uma lista de produtos.
Para testar o primeiro cenário de "página lenta", selecione o link Lento . A página acabará mostrando a mesma saída que a página Resultados esperados, mas será renderizada muito mais lentamente do que o esperado.
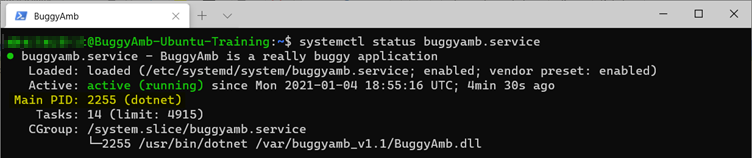
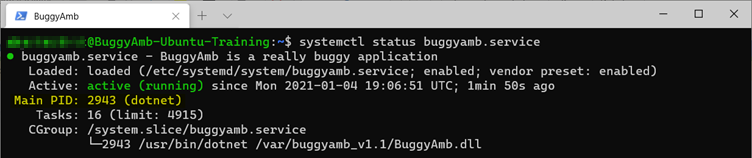
Antes de reproduzir o problema de travamento, anote a ID do processo do aplicativo com bugs. Você usará essas informações para verificar se o aplicativo foi reiniciado. Execute o systemctl status buggyamb.service comando para obter o PID atual. Nos resultados a seguir, o PID do processo que está executando o serviço é 2255.
Selecione o link Crash 3 . A página é carregada e exibe a seguinte mensagem:
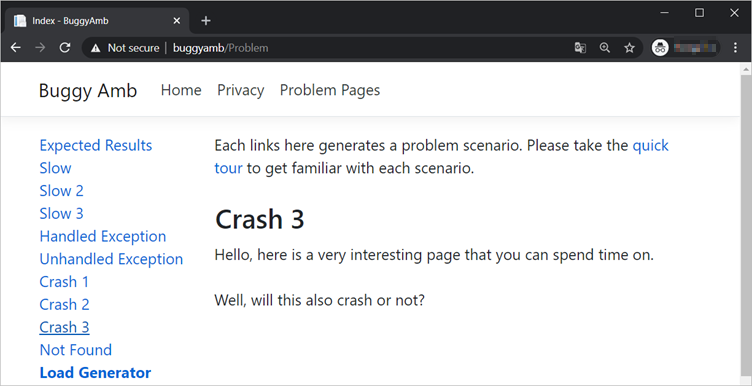
Esta mensagem pede ao usuário que considere a seguinte pergunta: Esta página fará com que o processo falhe? Execute o mesmo systemctl status buggyamb.service comando e você verá o mesmo PID. Isso indica que não ocorreu uma falha.
Selecione Resultados Esperados e, em seguida, selecione Lento. Embora você deva ver a página correta depois de selecionar Resultados esperados, selecionar Lento deve gerar a seguinte mensagem de erro.
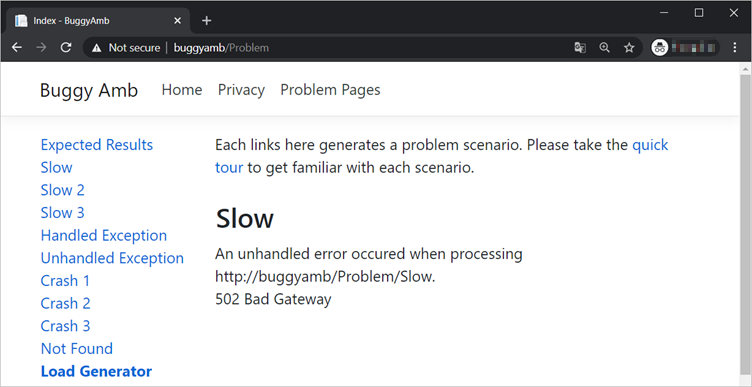
Mesmo se você selecionar qualquer outro link na página da web, você experimentará o mesmo erro por um curto período de tempo. Após 10 a 15 segundos, tudo começará a responder conforme o esperado novamente.
Para verificar se o PID foi alterado, execute systemctl status buggyamb.service novamente. Desta vez, você deve notar que o processo parece ter parado porque o PID foi alterado. No exemplo anterior, o PID do processo era 2255. No exemplo a seguir, ele foi alterado para 2943. Aparentemente, o site cumpriu sua promessa de travar o processo.
Solução de problemas das etapas de reprodução
Aqui está um resumo das etapas de reprodução:
- Selecione Crash 3. A página é carregada corretamente, mas retorna uma mensagem confusa que sugere que o processo irá travar.
- Selecione Lento. Você recebe uma mensagem de erro "HTTP 502 - Gateway inválido" em vez da tabela de produtos.
- Depois que o problema começar, nenhuma das páginas será renderizada pelos próximos 10 a 15 segundos.
- Após 10 a 15 segundos, o aplicativo começa a responder corretamente.
A mensagem de erro "HTTP 502 - Bad Gateway" por si só não diz muito. No entanto, ele deve fornecer uma primeira pista: esse é um erro de proxy e pode ocorrer se um proxy não puder se comunicar com o aplicativo que está sendo executado por trás do proxy. Na configuração proposta, o Nginx está funcionando como um proxy reverso para o aplicativo ASP.NET Core. Portanto, esse erro do Nginx indica que ele não conseguiu acessar o aplicativo de back-end quando encaminhou as solicitações recebidas.
Verifique se o Nginx funciona corretamente
Antes de continuar, você pode querer verificar se o Nginx está funcionando corretamente. Esta etapa não é obrigatória porque você sabe que o aplicativo está falhando. No entanto, você ainda pode verificar o status do Nginx verificando os logs do Nginx. Você praticou etapas de solução de problemas semelhantes anteriormente na seção "Instalando e configurando o Nginx".
O Nginx tem dois tipos de logs: logs de acesso e logs de erros. Eles são armazenados na /var/log/nginx/ pasta.
Os logs de acesso são como os arquivos de log do IIS. Abra e examine-os, assim como você fez na seção anterior. Os logs não mostram nenhuma informação nova além do código de status de resposta "HTTP 502" que você já encontrou durante as tentativas de navegação nas páginas do site.
Inspecione os logs de erros usando o cat /var/log/nginx/error.log comando. Este registro é mais útil e claro. Isso mostra que o Nginx foi capaz de processar a solicitação, mas a conexão entre o Nginx e o aplicativo com bugs foi fechada antes que a resposta final fosse enviada.

Este log indica claramente que o que você vê não é um problema do Nginx.
Verifique os logs do sistema usando o comando journalctl
Se o aplicativo ASP.NET Core estiver falhando, os sintomas devem aparecer em algum lugar.
Como o aplicativo com bugs está sendo executado como um serviço do sistema, sua operação é registrada nos arquivos de log do sistema. Os arquivos de log do sistema são como logs de eventos do sistema no Windows. O journalctl comando é usado para visualizar e manipular logs do systemd.
Você pode executar o journalctl comando sem opções para ver todos os logs. No entanto, a saída será um arquivo grande. É do seu interesse aprender a filtrar o conteúdo. Por exemplo, você pode executar o seguinte código:
journalctl -r --identifier=buggyamb-identifier --since "10 minute ago"
Estão disponíveis os seguintes comutadores:
-r: Imprima os logs na ordem inversa para que o mais recente seja listado primeiro.--identifier: Lembre-se daSyslogIdentifier=buggyamb-identifierlinha no arquivo de serviço do aplicativo de teste. (Você pode usar isso para forçar os logs a mostrar apenas as entradas que se aplicam ao aplicativo problemático.)--since: Mostra as informações que foram registradas durante o período anterior especificado. Exemplo:--since "10 minute ago"ou--since "2 hour ago".
Existem várias opções úteis para o journalctl comando que podem ajudá-lo a filtrar os logs. Para se familiarizar com este comando, recomendamos que você consulte a página de ajuda executando man journalctl.
Execute journalctl -r --identifier=buggyamb-identifier --since today -o cat. Você deve observar que algumas mensagens de aviso são geradas.
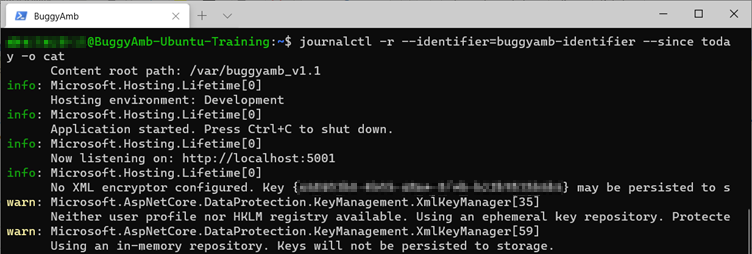
Para ver os detalhes, role para baixo usando as teclas de seta. Você encontrará uma System.Net.WebException exceção.
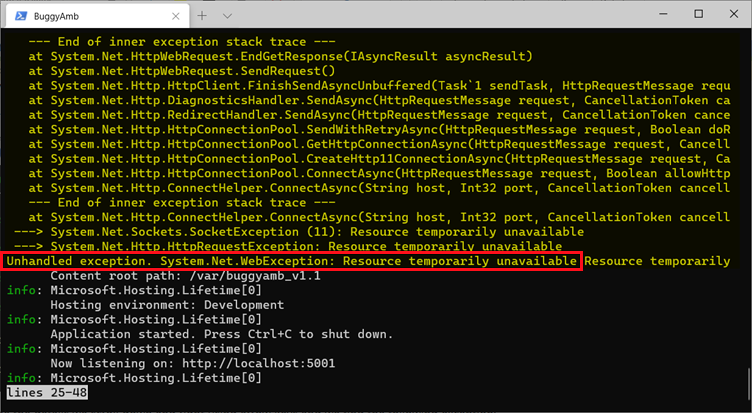
Se você examinar atentamente os logs, verá o nome do arquivo de código e o número da linha em que o problema ocorreu. Para este laboratório, vamos supor que essas informações não estejam disponíveis. Isso ocorre porque, em cenários do mundo real, talvez você não consiga recuperar esse tipo de informação. Portanto, o objetivo é continuar analisando um despejo de memória para saber a causa da falha.
Obter um arquivo de despejo principal após uma falha
Lembre-se de alguns dos principais comportamentos do sistema quando um processo é encerrado:
- Por padrão, um arquivo de despejo principal é gerado.
- O despejo de memória é chamado de núcleo e é criado na pasta de trabalho atual ou na /var/lib/systemd/coredump pasta.
Embora o comportamento padrão seja que o sistema gere um arquivo de despejo de memória, essa configuração pode ser substituída para /proc/sys/kernel/core_pattern canalizar diretamente o arquivo de despejo de memória resultante para outro aplicativo. Quando você usou o Ubuntu nas partes anteriores desta série, aprendeu que o apport gerencia a geração de arquivos de despejo principal no Ubuntu. O core_pattern arquivo é substituído para canalizar o despejo principal para o apport.

O Apport usa /var/crash a pasta para armazenar seus arquivos de relatório. Se você inspecionar essa pasta, deverá ver um arquivo que já foi gerado após uma falha.

No entanto, este não é o arquivo de despejo principal. Este é um arquivo de relatório que contém várias informações junto com o arquivo de despejo. Você precisa descompactar esse arquivo para obter o arquivo de despejo principal.
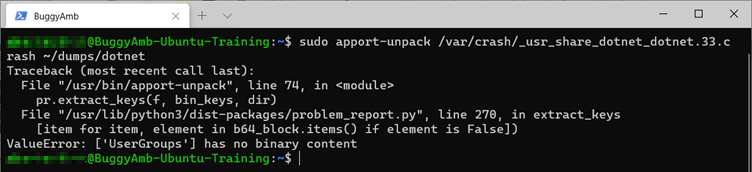
Crie uma pasta de despejos em sua pasta pessoal. Você será instruído a extrair o relatório lá. O comando para descompactar o arquivo de relatório apport é apport-unpack. Execute o comando a seguir:
sudo apport-unpack /var/crash/_usr_share_dotnet_dotnet.33.crash ~/dumps/dotnet
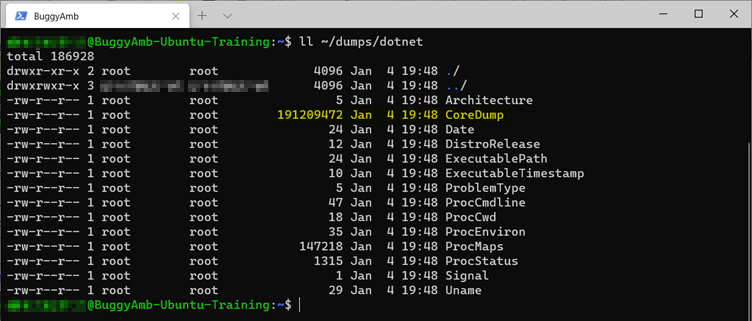
Esse comando cria a pasta /dumps . O apport-unpack comando criará a pasta /dumps/dotnet . Consulte o resultado.
Na pasta ~/dumps/dotnet, você deve ver o arquivo de despejo. O arquivo é chamado CoreDump e deve ter cerca de 191 MB.
Extrair o arquivo de despejo principal gerado automaticamente pode ser um processo complicado. No próximo laboratório, você verá que é mais fácil capturar arquivos de despejo de memória usando createdumpo .
Próximas etapas
Laboratório 1.2 Abra e analise arquivos de despejo de memória gerados pelo sistema no depurador lldb, você verá como abrir esse arquivo de despejo no depurador lldb para fazer uma análise rápida.