Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Observação
Este artigo refere-se principalmente às experiências do consumidor entregues no Windows 10 (versão 1909 e anteriores). Para obter mais informações, consulte Fim do suporte para a Cortana.
A Cortana, a plataforma de fala do Windows, capacita todas as experiências de fala no Windows 10, como Cortana e ditado. A ativação de voz é um recurso que permite que os usuários invoquem um mecanismo de reconhecimento de fala de vários estados de energia do dispositivo dizendo uma frase específica: "Ei Cortana". Para criar um hardware que dê suporte à tecnologia de ativação de voz, examine as informações neste artigo.
Observação
Implementar a ativação de voz é um projeto significativo e é uma tarefa concluída pelos fornecedores do SoC. Os OEMs podem entrar em contato com o fornecedor do SoC para obter informações sobre a implementação de ativação de voz do SoC.
Experiência do usuário final da Cortana
Para entender a experiência de interação de voz disponível no Windows, examine estes artigos.
| Artigo | Description |
|---|---|
| O que é a Cortana? | Fornece e visão geral e direção de uso para a Cortana |
Introdução à Ativação de Voz "Hey Cortana" e "Aprenda minha voz"
Ei Cortana" Ativação de Voz
O recurso de VA (Ativação de Voz) "Hey Cortana" permite que os usuários envolvam rapidamente a experiência da Cortana fora de seu contexto ativo (ou seja, o que está atualmente na tela) usando sua voz. Os usuários geralmente querem poder acessar instantaneamente uma experiência sem precisar interagir fisicamente ou tocar em um dispositivo. Os usuários de telefone podem estar dirigindo no carro e tendo sua atenção e mãos envolvidas com a operação do veículo. Talvez um usuário do Xbox não queira localizar e conectar um controlador. Os usuários de computador podem querer acesso rápido a uma experiência sem precisar executar várias ações de mouse, toque ou teclado. Por exemplo, um computador na cozinha sendo usado durante o cozimento.
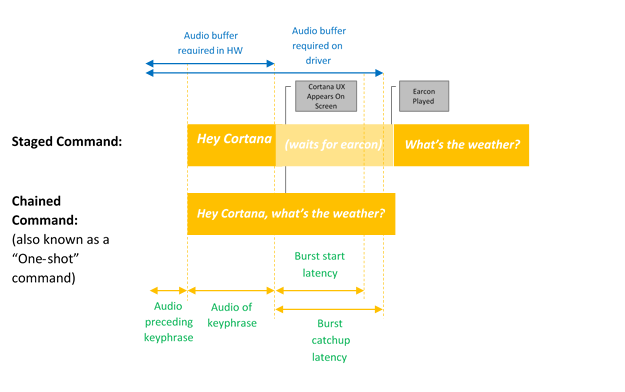
A ativação de voz proporciona entrada de áudio contínua, sempre em escuta, através de frases-chave predefinidas ou frases de ativação. Frases-chave podem ser proferidas por si mesmas ("Ei Cortana") como um comando em etapas ou seguidas por uma ação de fala, por exemplo, "Ei Cortana, onde está minha próxima reunião?", um comando encadeado.
O termo Detecção de Palavra-chave descreve a detecção da palavra-chave por hardware ou software.
Ativação apenas por palavra-chave ocorre quando apenas a palavra-chave Cortana é dita, Cortana é iniciada e reproduz o som EarCon para indicar que entrou no modo de escuta.
Um comando encadeado descreve a capacidade de emitir um comando imediatamente após a palavra-chave (como "Ei Cortana, chamar João") e iniciar a Cortana (se ainda não tiver iniciado) e seguir o comando (iniciando uma chamada telefônica com João).
Este diagrama ilustra a ativação encadeada e ativação apenas por palavra-chave.
A Microsoft fornece um localizador padrão de palavras-chave do sistema operacional (localizador de palavras-chave de software) que é usado para garantir a qualidade das detecções de palavras-chave de hardware e para fornecer a funcionalidade Hey Cortana nos casos em que a detecção de palavras-chave de hardware está ausente ou indisponível.
O recurso "Aprender minha voz"
O recurso "Aprenda minha voz" permite que o usuário treine a Cortana para reconhecer sua voz exclusiva. Isso é feito pelo usuário que seleciona Learn how I say "Hey Cortana" na tela de configurações da Cortana. Em seguida, o usuário repete seis frases cuidadosamente escolhidas que fornecem uma variedade suficiente de padrões fonéticos para identificar os atributos exclusivos da voz do usuário.
Quando a ativação de voz é emparelhada com "Aprenda minha voz", os dois algoritmos funcionam juntos para reduzir as falsas ativações. Isso é especialmente valioso para o cenário da sala de reunião, onde uma pessoa diz "Ei Cortana" em uma sala cheia de dispositivos. Esse recurso está disponível apenas para o Windows 10 versão 1903 e anterior.
A ativação de voz é alimentada por um KWS (spotter de palavra-chave) que reage se a frase-chave for detectada. Se o KWS deve ativar o dispositivo a partir de um modo de baixa potência, a solução é conhecida como Wake on Voice (WoV). Para obter mais informações, consulte Wake on Voice.
Glossário de Termos
Esse glossário resume os termos relacionados à ativação de voz.
| Prazo | Exemplo/definição |
|---|---|
| Comando em etapas | Exemplo: Hey Cortana <pause, espere pelo som EarCon> Como está o tempo? Às vezes, isso é chamado de "Comando de duas etapas" ou "Exclusivo para palavra-chave" |
| Comando encadeado | Exemplo: Ei Cortana, qual é o clima? Às vezes, isso é chamado de "comando de um tiro" |
| Ativação de voz | O cenário de detecção de uma frase-chave de ativação predefinida. Por exemplo, "Hey Cortana" é o cenário de ativação de voz da Microsoft. |
| WoV | Wake-on-Voice – Tecnologia que permite a ativação por voz de uma tela desligada, estado de baixo consumo de energia, para uma tela em estado de plena energia. |
| WoV do Modo de Espera Moderno | Wake-on-Voice de um estado fora da tela com Modern Standby (S0ix) para um estado na tela com energia total (S0). |
| Modo de Espera Moderno | Infraestrutura ociosa do Windows Low Power – sucessora do CS (Connected Standby) no Windows 10. O primeiro estado de standby moderno é quando a tela está desativada. O estado de sono mais profundo é quando em DRIPS/Resiliência. Para obter mais informações, consulte Modern Standby |
| KWS | Detector de palavra-chave – o algoritmo que detecta "Hey Cortana" |
| SW KWS | Detecção de palavras-chave por software – uma implementação de reconhecimento de palavras-chave que é executada no processador central (CPU). Para "Hey Cortana", SW KWS é incluído como parte do Windows. |
| HW KWS | Detector de palavras-chave acelerado por hardware – uma implementação de KWS que é executada no hardware. |
| Buffer de intermitência | Um buffer circular usado para armazenar dados do PCM que podem "explodir" em uma detecção KWS, de modo que todo o áudio que disparou uma detecção de KWS seja incluído. |
| Adaptador OEM do Detector de Palavras-Chave | Um shim em nível de driver que permite que o hardware compatível com WoV se comunique com o Windows e a pilha Cortana. |
| Modelo | O arquivo de dados do modelo acústico usado pelo algoritmo KWS. O arquivo de dados é estático. Os modelos são localizados, um por localidade. |
Integrando um detector de palavras-chave de hardware
Para implementar um identificador de palavras-chave por hardware (HW KWS), conclua as tarefas a seguir.
- Crie um detector de palavras-chave personalizado com base no exemplo SYSVAD descrito posteriormente neste artigo. Você implementará esses métodos em uma DLL COM, descrita na Interface do Adaptador OEM do Detector de Palavras-Chave.
- Implemente aprimoramentos WAVE RT descritos em Aprimoramentos do WAVERT.
- Forneça entradas de arquivo INF para descrever as APOs personalizadas usadas para detecção de palavra-chave.
- PKEY_FX_KeywordDetector_StreamEffectClsid
- PKEY_FX_KeywordDetector_ModeEffectClsid
- PKEY_FX_KeywordDetector_EndpointEffectClsid
- PKEY_SFX_DetectorDePalavrasChave_ModosDeProcessamento_Suportados_Para_Transmissão
- PKEY_MFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- PKEY_EFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- Examine as recomendações de hardware e as diretrizes de teste na Recomendação de Dispositivo de Áudio. Este artigo fornece diretrizes e recomendações para o design e o desenvolvimento de dispositivos de entrada de áudio destinados a uso com a Plataforma de Fala da Microsoft.
- Dê suporte a comandos preparados e encadeados.
- Fornecer suporte a "Hey Cortana" para cada uma das localizações da Cortana com suporte.
- As APOs (objetos de processamento de áudio) devem fornecer os seguintes efeitos:
- AEC
- AGC
- NS
- Os efeitos para o modo de processamento de fala devem ser relatados pelo APO do MFX.
- O APO pode executar a conversão de formato para MFX.
- O APO deve gerar o seguinte formato:
- 16 kHz, mono, FLOAT.
- Opcionalmente, projete APOs personalizadas para aprimorar o processo de captura de áudio. Para obter mais informações, consulte Objetos de Processamento de Áudio do Windows.
Requisitos para WoV do HW KWS (detector de palavras-chave com descarregamento por hardware)
- O HW KWS WoV tem suporte durante o estado de trabalho S0 e também durante o estado de suspensão em S0, conhecido como Espera Moderna.
- O HW KWS WoV não tem suporte do S3.
Requisitos de AEC para HW KWS
Para Windows Versão 1709
- Para dar suporte a HW KWS WoV para estado de suspensão S0 (Modern Standby), AEC não é necessário.
- O estado de trabalho do HW KWS WoV para S0 não é compatível com o Windows Versão 1709.
Para o Windows versão 1803
- O suporte está disponível para HW KWS WoV no estado de trabalho S0.
- Para habilitar o HW KWS WoV para o estado de trabalho S0, o APO deve dar suporte à AEC.
Visão geral do código de exemplo
Há um código de exemplo para um driver de áudio que implementa a ativação de voz no GitHub como parte do exemplo do adaptador de áudio virtual SYSVAD. É recomendável usar esse código como ponto de partida. O código está disponível neste local.
https://github.com/Microsoft/Windows-driver-samples/tree/main/audio/sysvad/
Para obter mais informações sobre o driver de áudio de exemplo do SYSVAD, consulte Drivers de Áudio de Exemplo.
Informações do sistema de reconhecimento de palavra-chave
Suporte a estrutura de áudio com comando de voz
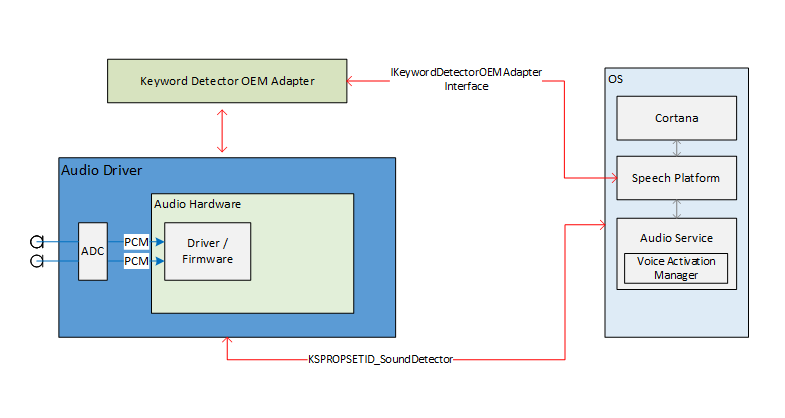
As interfaces externas da pilha de áudio para a ativação de voz funcionam como o canal de comunicação para a plataforma de voz e os drivers de áudio. As interfaces externas são divididas em três partes.
- Interface do Driver de Dispositivo (DDI) para Detector de Palavras-chave. A interface do driver de dispositivo do detector de palavras-chave é responsável por configurar e armar o KWS (Spotter de palavra-chave) do HW. Ele também é usado pelo driver para notificar o sistema de um evento de detecção.
- DLL do adaptador OEM do detector de palavras-chave. Essa DLL implementa uma interface COM para adaptar os dados opacos específicos do driver para uso pelo sistema operacional para ajudar na detecção de palavra-chave.
- Aprimoramentos de streaming do WaveRT. Os aprimoramentos permitem que o driver de áudio transmita em rajadas os dados de áudio bufferizados detectados pela palavra-chave.
Propriedades do ponto de extremidade de áudio
A construção do grafo do ponto de extremidade de áudio ocorre normalmente. O gráfico está preparado para lidar com uma captura mais rápida do que o tempo real. Os carimbos de data/hora em buffers capturados permanecem verdadeiros. Especificamente, os carimbos de data/hora refletem corretamente os dados que foram capturados no passado e armazenados em buffer e agora estão estourando.
Teoria do streaming de áudio por desvio no Bluetooth
O driver expõe um filtro KS para seu dispositivo de captura conforme o padrão. Esse filtro dá suporte a várias propriedades KS e a um evento KS para configurar, habilitar e sinalizar um evento de detecção. O filtro também inclui outra fábrica de pinos identificada como um pino KWS (localizador de palavra-chave). Esse pino é usado para transmitir áudio do detector de palavras-chave.
As propriedades são:
- Tipos de palavra-chave com suporte – KSPROPERTY_SOUNDDETECTOR_PATTERNS. O sistema operacional define essa propriedade para configurar as palavras-chave a serem detectadas.
- Lista de GUIDs de padrões de palavras-chave – KSPROPERTY_SOUNDDETECTOR_SUPPORTEDPATTERNS. Essa propriedade é usada para obter uma lista de GUIDs que identificam os tipos de padrões com suporte.
- Armado - KSPROPERTY_SOUNDDETECTOR_ARMED. Esta propriedade de leitura/gravação é um status booliano que indica se o detector está armado. O sistema operacional define isso para ativar o detector de palavras-chave. O sistema operacional pode limpar isso para desativar. O driver limpa isso automaticamente quando os padrões de palavra-chave são definidos e também depois que uma palavra-chave é detectada. (O sistema operacional deve ser rearmado.)
- Resultado da correspondência – KSPROPERTY_SOUNDDETECTOR_MATCHRESULT. Essa propriedade de leitura contém os dados de resultado após a detecção.
O evento que é acionado quando uma palavra-chave é detectada é um evento KSEVENT_SOUNDDETECTOR_MATCHDETECTED .
Sequência de operação
Inicialização do sistema
- O sistema operacional lê os tipos de palavra-chave com suporte para verificar se ele tem palavras-chave nesse formato.
- O sistema operacional registra o evento de alteração de status do detector.
- O sistema operacional define os padrões de palavra-chave.
- O sistema operacional arma o detector.
Ao receber o evento KS
- O motorista desarma o detector.
- O sistema operacional lê o status do detector de palavras-chave, analisa os dados retornados e determina qual padrão foi detectado.
- O sistema operacional rearma o detector.
Operação interna de driver e hardware
Enquanto o detector está armado, o hardware pode capturar e armazenar continuamente dados de áudio em um pequeno buffer FIFO. (O tamanho desse buffer FIFO é determinado por requisitos fora deste documento, mas normalmente pode ser centenas de milissegundos a vários segundos.) O algoritmo de detecção opera no streaming de dados por meio desse buffer. O design do driver e do hardware é tal que, enquanto estiver armado, não existe interação entre o driver e o hardware, e nenhuma interrupção aos processadores de aplicação até que uma palavra-chave seja detectada. Isso permite que o sistema atinja um estado de energia mais baixo se não houver outra atividade.
Quando o hardware detecta uma palavra-chave, ele gera uma interrupção. Enquanto aguarda o driver atender à interrupção, o hardware continua a capturar áudio no buffer, garantindo que nenhum dado após a palavra-chave seja perdida, dentro dos limites de buffer.
Carimbos de data/hora da palavra-chave
Depois de detectar uma palavra-chave, todas as soluções de ativação de voz devem armazenar em buffer toda a palavra-chave falada, incluindo 250ms antes do início da palavra-chave. O driver de áudio deve fornecer marcadores de tempo que identifiquem o início e o fim da frase-chave no fluxo.
Para dar suporte aos carimbos de data/hora que marcam o início e término de uma palavra-chave, o software DSP pode precisar inserir carimbos de data/hora internamente em eventos com base em um relógio DSP. Depois que uma palavra-chave é detectada, o software DSP interage com o driver para preparar um evento KS. O driver e o software DSP precisam mapear os carimbos de data/hora DSP para um valor de contador de desempenho do Windows. O método de fazer isso é específico para o design de hardware. Uma solução possível é que o driver leia o contador de desempenho atual, consulte o carimbo de data/hora DSP atual, leia o contador de desempenho atual novamente e, em seguida, estime uma correlação entre o contador de desempenho e a hora DSP. Em seguida, considerando a correlação, o driver pode mapear os marcadores de tempo da palavra-chave DSP para marcadores de tempo do contador de desempenho do Windows.
Interface do adaptador OEM do detector de palavras-chave
O OEM fornece uma implementação de objeto COM que atua como um intermediário entre o sistema operacional e o driver, ajudando a calcular ou analisar os dados opacos que são gravados e lidos no driver de áudio por meio de KSPROPERTY_SOUNDDETECTOR_PATTERNS e KSPROPERTY_SOUNDDETECTOR_MATCHRESULT.
O CLSID do objeto COM é um GUID de tipo de padrão de detector retornado pelo KSPROPERTY_SOUNDDETECTOR_SUPPORTEDPATTERNS. O sistema operacional chama CoCreateInstance passando o GUID do tipo padrão para instanciar o objeto COM apropriado compatível com o tipo de padrão de palavra-chave e chama métodos na interface IKeywordDetectorOemAdapter do objeto.
Requisitos do modelo de threading COM
A implementação do OEM pode escolher qualquer um dos modelos de threading COM.
IKeywordDetectorOemAdapter
O design da interface tenta manter a implementação do objeto sem estado. Em outras palavras, a implementação não deve exigir que nenhum estado seja armazenado entre chamadas de método. Na verdade, as classes C++ internas provavelmente não precisam de variáveis de membro além daquelas necessárias para implementar um objeto COM em geral.
Methods
Implemente os métodos a seguir.
- IKeywordDetectorOemAdapter::BuildArmingPatternData
- IKeywordDetectorOemAdapter::ComputeAndAddUserModelData
- IKeywordDetectorOemAdapter::GetCapabilities
- IKeywordDetectorOemAdapter::ParseDetectionResultData
- IKeywordDetectorOemAdapter::VerifyUserKeyword
KEYWORDID
A enumeração KEYWORDID identifica o texto/função da frase de uma palavra-chave e também é usada nos adaptadores do Serviço Biométrico do Windows. Para obter mais informações, consulte a Visão geral da Estrutura Biométrica – Componentes principais da plataforma
typedef enum {
KwInvalid = 0,
KwHeyCortana = 1,
KwSelect = 2
} KEYWORDID;
KEYWORDSELECTOR
O struct KEYWORDSELECTOR é um conjunto de IDs que selecionam exclusivamente uma palavra-chave e um idioma específicos.
typedef struct
{
KEYWORDID KeywordId;
LANGID LangId;
} KEYWORDSELECTOR;
Manipulando dados do modelo
Modelo independente do usuário estático – a DLL OEM normalmente incluiria alguns dados de modelo independentes do usuário estático integrados à DLL ou em um arquivo de dados separado incluído com a DLL. O conjunto de IDs de palavra-chave com suporte retornados pela rotina GetCapabilities dependeria desses dados. Por exemplo, se a lista de IDs de palavra-chave com suporte retornadas por GetCapabilities incluir KwHeyCortana, os dados de modelo independentes do usuário estático incluirão dados para "Hey Cortana" (ou sua tradução) para todos os idiomas com suporte.
Modelo dependente de usuário dinâmico – O IStream fornece um modelo de armazenamento de acesso aleatório. O sistema operacional passa um ponteiro de interface IStream para muitos dos métodos na interface IKeywordDetectorOemAdapter. O sistema operacional faz backup da implementação do IStream com armazenamento apropriado para até 1 MB de dados.
O conteúdo e a estrutura dos dados dentro desse armazenamento são definidos pelo OEM. A finalidade pretendida é o armazenamento persistente de dados de modelo dependentes do usuário computados ou recuperados pela DLL OEM.
O sistema operacional pode chamar os métodos de interface com um IStream vazio, especialmente se o usuário nunca tiver treinado uma palavra-chave. O sistema operacional cria um armazenamento IStream separado para cada usuário. Em outras palavras, IStream armazena dados de modelo para um único usuário.
O desenvolvedor de DLL OEM decide como gerenciar os dados independentes do usuário e dependentes do usuário. No entanto, ele nunca armazenará dados do usuário em qualquer lugar fora do IStream. Um possível design de DLL OEM alternaria internamente entre acessar o IStream e os dados estáticos independentes do usuário, dependendo dos parâmetros do método atual. Uma abordagem de design alternativo pode verificar o IStream no início de cada chamada de método e adicionar ao IStream os dados estáticos independentes de usuário, caso ainda não estejam presentes, o que permite que o restante do método acesse apenas o IStream para todos os dados do modelo.
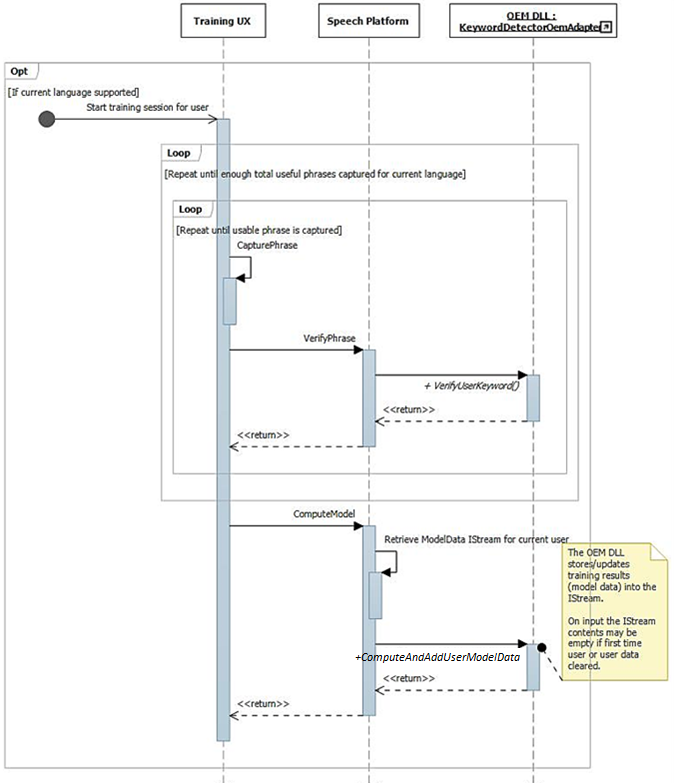
Treinamento e operação de processamento de áudio
Conforme descrito anteriormente, o fluxo de UI de treinamento resulta em frases completamente ricas em fonemas disponíveis no fluxo de áudio. Cada frase é transmitida individualmente para IKeywordDetectorOemAdapter::VerifyUserKeyword para verificar se ela contém a palavra-chave esperada e tem uma qualidade aceitável. Depois que todas as frases são coletadas e verificadas pela interface do usuário, todas elas são passadas em uma chamada para IKeywordDetectorOemAdapter::ComputeAndAddUserModelData.
O áudio é processado de maneira exclusiva para treinamento de ativação de voz. A tabela a seguir resume as diferenças entre o treinamento de ativação de voz e o uso regular de reconhecimento de voz.
| Treinamento de voz | Reconhecimento de voz | |
|---|---|---|
| Modo | Cru | Raw ou Speech |
| Fixar | Normal | KWS |
| Formato de áudio | Ponto Flutuante de 32 bits (tipo = áudio, subtipo = IEEE_FLOAT, taxa de amostragem = 16 kHz, bits = 32) | Gerenciado pela pilha de áudio do sistema operacional |
| Mic | Microfone 0 | Todos os microfones na matriz ou mono |
Visão geral do sistema de reconhecimento de palavras-chave
Este diagrama fornece uma visão geral do sistema de reconhecimento de palavra-chave.
Diagramas de sequência de reconhecimento de palavra-chave
Nesses diagramas, o módulo de execução de fala é apresentado como a plataforma de fala. Conforme mencionado anteriormente, a plataforma de fala do Windows é usada para alimentar todas as experiências de fala no Windows 10, como Cortana e ditado.
Durante a inicialização, os recursos são coletados usando IKeywordDetectorOemAdapter::GetCapabilities.
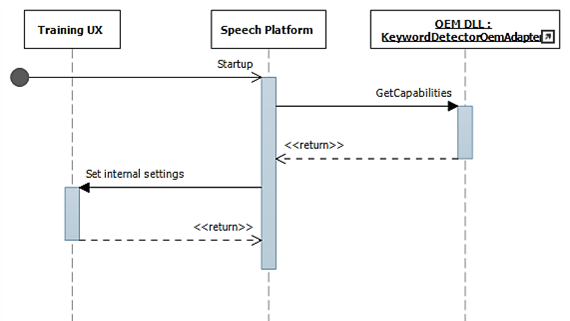
Posteriormente, quando o usuário seleciona "Aprender minha voz", o fluxo de treinamento é invocado.
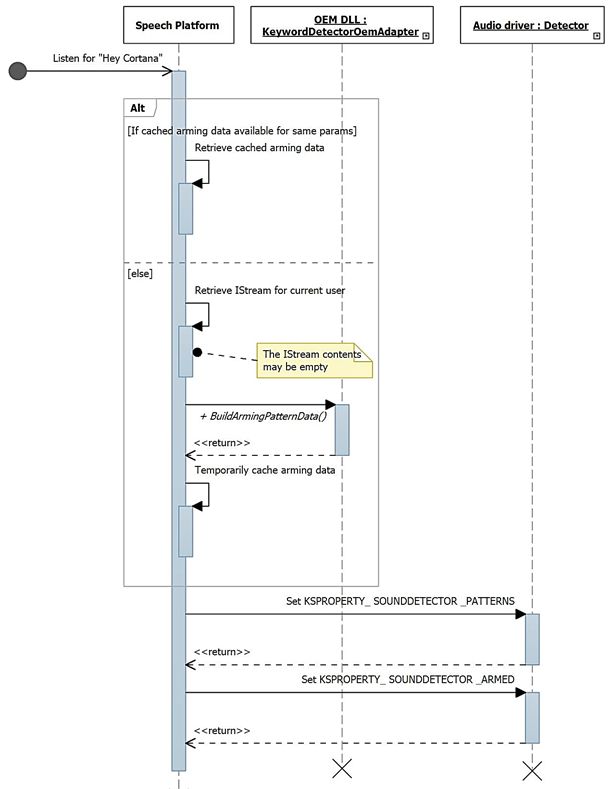
Este diagrama descreve o processo de ativação para detecção de palavra-chave.
Aprimoramentos do WAVERT
As interfaces Miniport são definidas para serem implementadas por drivers WaveRT Miniport. Essas interfaces fornecem métodos para simplificar o driver de áudio, melhorar o desempenho e a confiabilidade do pipeline de áudio do sistema operacional ou dar suporte a novos cenários. Uma nova propriedade de interface do dispositivo PnP é definida permitindo que o driver forneça expressões estáticas de suas restrições de tamanho de buffer para o sistema operacional.
Tamanhos de buffer
Um driver opera sob várias restrições ao mover dados de áudio entre o sistema operacional, o driver e o hardware. Essas restrições podem ser devido ao transporte de hardware físico que move dados entre memória e hardware e/ou devido aos módulos de processamento de sinal dentro do hardware ou DSP associado.
HW-KWS soluções devem dar suporte a tamanhos de captura de áudio de pelo menos 100ms e até 200ms.
O driver expressa as restrições de tamanho do buffer definindo a propriedade de dispositivo DEVPKEY_KsAudio_PacketSize_Constraints na interface de dispositivo PnP KSCATEGORY_AUDIO do filtro KS que tem os pinos de streaming do KS. Essa propriedade deve permanecer válida e estável enquanto a interface de filtro KS estiver habilitada. O sistema operacional pode ler esse valor a qualquer momento sem precisar abrir um identificador para o driver e chamar o driver.
DEVPKEY_KsAudio_PacketSize_Constraints
O valor da propriedade DEVPKEY_KsAudio_PacketSize_Constraints contém uma estrutura KSAUDIO_PACKETSIZE_CONSTRAINTS que descreve as restrições de hardware físico (ou seja, devido à mecânica de transferência de dados do buffer WaveRT para o hardware de áudio). A estrutura inclui uma matriz de 0 ou mais estruturas KSAUDIO_PACKETSIZE_PROCESSINGMODE_CONSTRAINT que descrevem restrições específicas a quaisquer modos de processamento de sinal. O driver define essa propriedade antes de chamar PcRegisterSubdevice ou de habilitar sua interface de filtro KS para seus pinos de streaming.
IMiniportWaveRTInputStream
Um driver implementa essa interface para melhor coordenação do fluxo de dados de áudio do driver para o sistema operacional. Se essa interface estiver disponível em um fluxo de captura, o sistema operacional usará métodos nessa interface para acessar dados no buffer WaveRT. Para obter mais informações, consulte IMiniportWaveRTInputStream::GetReadPacket
IMiniportWaveRTOutputStream
Opcionalmente, um miniporto WaveRT implementa essa interface para receber informações sobre o progresso da gravação do sistema operacional e retornar a posição precisa do fluxo de dados. Para obter mais informações, consulte IMiniportWaveRTOutputStream::SetWritePacket, IMiniportWaveRTOutputStream::GetOutputStreamPresentationPosition e IMiniportWaveRTOutputStream::GetPacketCount.
Carimbos de data/hora do contador de desempenho
Várias das rotinas de driver retornam carimbos de data/hora do contador de desempenho do Windows, que refletem o momento em que as amostras são capturadas ou apresentadas pelo dispositivo.
Em dispositivos com pipelines DSP complexos e processamento de sinal, calcular um timestamp preciso pode ser desafiador e deve ser feito cuidadosamente. Os carimbos de data/hora não devem refletir o tempo em que as amostras foram transferidas para ou do sistema operacional para o DSP.
- No DSP, acompanhe os carimbos de data/hora de amostra usando algum relógio interno de referência DSP.
- Entre o driver e o DSP, calcule uma correlação entre o contador de desempenho do Windows e o relógio de parede DSP. Os procedimentos para isso podem variar de simples (mas menos precisos) a bastante complexos ou novos (mas mais precisos).
- Considere quaisquer atrasos constantes que possam ocorrer devido a algoritmos de processamento de sinal, transporte por pipeline ou hardware, a menos que esses atrasos já tenham sido contabilizados de outra forma.
Operação de leitura em rajada
Esta seção descreve a interação entre o sistema operacional e o driver para leituras de intermitência. A leitura em rajada pode acontecer fora do cenário de ativação de voz, desde que o driver dê suporte ao modelo WaveRT de streaming baseado em pacote, incluindo a função IMiniportWaveRTInputStream::GetReadPacket.
Dois cenários de leitura de exemplo de intermitência são discutidos. Em um cenário, se o miniporto der suporte a um pino cuja categoria seja KSNODETYPE_AUDIO_KEYWORDDETECTOR, o driver começará a capturar e a armazenar dados em buffer internamente quando uma palavra-chave for detectada. Em outro cenário, o driver poderá armazenar dados em buffer internamente fora do buffer WaveRT se o sistema operacional não estiver lendo dados rapidamente o suficiente chamando IMiniportWaveRTInputStream::GetReadPacket.
Para descarregar dados que foram capturados antes da transição para KSSTATE_RUN, o driver deve reter informações precisas de carimbo de data/hora de amostra, além dos dados em buffer capturados. Os carimbos de data/hora identificam o instante de amostragem dos exemplos capturados.
Depois que o fluxo faz a transição para KSSTATE_RUN, o driver define imediatamente o evento de notificação de buffer porque ele já tem dados disponíveis.
Nesse evento, o sistema operacional chama GetReadPacket() para obter informações sobre os dados disponíveis.
O driver retorna o número de pacote dos dados capturados válidos (0 para o primeiro pacote após a transição de KSSTATE_STOP para KSSTATE_RUN), do qual o sistema operacional pode derivar a posição do pacote dentro do buffer WaveRT e a posição do pacote em relação ao início do fluxo.
O driver também retorna o valor do contador de desempenho que corresponde ao instante de amostragem da primeira amostra no pacote. Esse valor do contador de desempenho pode ser relativamente antigo, dependendo de quantos dados de captura foram armazenados em buffer dentro do hardware ou driver (fora do buffer WaveRT).
Se houver mais dados não lidos em buffer disponíveis, o driver fará uma das seguintes opções:
- Transfere imediatamente esses dados para o espaço disponível do buffer WaveRT (ou seja, espaço não usado pelo pacote retornado do GetReadPacket), retorna true para MoreData e define o evento de notificação de buffer antes de retornar dessa rotina. Ou
- Programa o hardware para estourar o próximo pacote no espaço disponível do buffer WaveRT, retorna false para MoreData e, posteriormente, define o evento de buffer quando a transferência é concluída.
O sistema operacional lê dados do buffer WaveRT usando as informações retornadas por GetReadPacket().
O sistema operacional aguarda o próximo evento de notificação de buffer. A espera poderá ser encerrada imediatamente se o driver definir a notificação de buffer na etapa (2c).
Se o driver não definiu imediatamente o evento na etapa (2c), o driver define o evento depois de transferir mais dados capturados para o buffer WaveRT e disponibilizá-lo para o sistema operacional ler
Vá para (2). Para KSNODETYPE_AUDIO_KEYWORDDETECTOR pinos de detector de palavras-chave, os drivers devem alocar buffers de intermitência interna suficientes para pelo menos 5.000m de dados de áudio. Se o sistema operacional não iniciar o streaming no pino antes que o buffer exceda sua capacidade, o driver poderá encerrar a atividade de armazenamento temporário interno e liberar os recursos associados.
Ativar por Voz
O WoV (Wake On Voice) permite que o usuário ative e consulte um mecanismo de reconhecimento de fala de uma tela desligada, estado de energia inferior, para uma tela ativada, estado de energia total, dizendo uma determinada palavra-chave, como "Hey Cortana".
Esse recurso permite que o dispositivo esteja sempre escutando a voz do usuário enquanto o dispositivo estiver em um estado de baixa potência, inclusive quando a tela estiver desativada e o dispositivo ficar ocioso. Ele faz isso usando um modo de escuta, que é de menor potência quando comparado com o maior uso de energia visto durante a gravação normal do microfone. O reconhecimento de fala de baixo consumo de energia permite que um usuário diga uma frase-chave predefinida como "Hey Cortana", seguida por uma frase de fala encadeada como "quando é meu próximo compromisso" para invocar a fala de forma hands-free. Isso funciona independentemente se o dispositivo está em uso ou ocioso com a tela desativada.
A estrutura de áudio é responsável por comunicar os dados de ativação (ID do locutor, gatilho por palavra-chave, nível de confiança) e notificar os clientes interessados quando a palavra-chave for detectada.
Validação em sistemas de espera modernos
O WoV de um estado ocioso do sistema pode ser validado em sistemas Modern Standby usando o Teste Básico de Ativação por Voz em Espera Moderna com Fonte de Energia AC e o Teste Básico de Ativação por Voz em Espera Moderna com Fonte de Energia DC no HLK. Esses testes verificam se o sistema possui um ativador de palavras-chave de hardware (HW-KWS), é capaz de entrar no DRIPS (Estado de Plataforma Ociosa do Tempo de Execução Mais Profundo) e de ativar a partir do Modo de Espera Moderno através de comando de voz, com latência de retomada do sistema inferior ou igual a um segundo.