Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Use as informações a seguir para solucionar problemas de implantação de Espaços de Armazenamento Diretos.
Em geral, comece com as seguintes etapas:
- Confirme se a criação/modelo do SSD é certificado para Windows Server 2016 e Windows Server 2019 usando o Catálogo do Windows Server. Confirme com o fornecedor se as unidades têm suporte para Espaços de Armazenamento Diretos.
- Inspecione o armazenamento em busca de unidades com falha. Use o software de gerenciamento de armazenamento para verificar o status das unidades. Se qualquer uma das unidades estiver com falha, trabalhe com o fornecedor.
- Atualize o armazenamento e o firmware de unidade, se necessário. Verifique se as Atualizações mais recentes do Windows estão instaladas em todos os nós. Você pode obter as atualizações mais recentes para Windows Server 2016 do histórico de atualizações Windows 10 e Windows Server 2016 e para o Windows Server 2019 do histórico de atualizações do Windows 10 e do Windows Server 2019. Obtenha as atualizações mais recentes para o Windows Server 2019 a partir do histórico de atualizações do Windows 10 e do Windows Server 2019.
- Atualize os drivers e o firmware do adaptador de rede.
- Execute a validação de cluster e revise a seção Espaço de Armazenamento Direto. Certifique-se de que as unidades usadas para o cache sejam relatadas corretamente e não tenham erros.
Se você ainda estiver tendo problemas, revise as informações de solução de problemas para cada um dos problemas específicos neste artigo.
Os recursos de disco virtual estão no estado Sem Redundância
Os nós de um sistema Espaços de Armazenamento Diretos reiniciam inesperadamente devido a uma falha ou falha de energia. Em seguida, um ou mais discos virtuais podem não ficar online e você verá a descrição "Não há informações de redundância suficientes".
| Nome Amigável | ResiliencySettingName | OperationalStatus | Estado de Saúde | IsManualAttach | Tamanho | PSComputerName |
|---|---|---|---|---|---|---|
| Disco4 | Espelho | OKEY | Íntegros | verdadeiro | 10 TB (terabytes) | Nó-01.conto... |
| Disco 3 | Espelho | OKEY | Íntegros | verdadeiro | 10 TB (terabytes) | Node-01.conto... |
| Disco 2 | Espelho | Sem redundância | Insalubre | verdadeiro | 10 TB (terabytes) | Node-01.conto... |
| Disco1 | Espelho | {Sem redundância, InService} | Insalubre | verdadeiro | 10 TB (terabytes) | Node-01.conto... |
Além disso, após uma tentativa de colocar o disco virtual online, as informações a seguir são registradas no log do cluster (DiskRecoveryAction).
[Verbose] 00002904.00001040::YYYY/MM/DD-12:03:44.891 INFO [RES] Physical Disk <DiskName>: OnlineThread: SuGetSpace returned 0.
[Verbose] 00002904.00001040:: YYYY/MM/DD -12:03:44.891 WARN [RES] Physical Disk < DiskName>: Underlying virtual disk is in 'no redundancy' state; its volume(s) may fail to mount.
[Verbose] 00002904.00001040:: YYYY/MM/DD -12:03:44.891 ERR [RES] Physical Disk <DiskName>: Failing online due to virtual disk in 'no redundancy' state. If you would like to attempt to online the disk anyway, first set this resource's private property 'DiskRecoveryAction' to 1. We will try to bring the disk online for recovery, but even if successful, its volume(s) or CSV may be unavailable.
O Status Operacional Sem Redundância pode ocorrer se um disco falhou ou se o sistema não consegue acessar dados no disco virtual. Esse problema poderá ocorrer se houver uma reinicialização em um nó durante a manutenção nos nós.
Para corrigir o problema, siga estas etapas:
Remova os Discos Virtuais afetados do CSV. Isso os coloca no grupo de armazenamento disponível no cluster e começa a ser exibido como um ResourceType de
Physical Disk.Remove-ClusterSharedVolume -Name "CSV Name"No nó que tem o grupo Armazenamento Disponível, execute o comando a seguir em cada disco que está em um estado Sem Redundância. Para identificar em qual nó o grupo "Armazenamento Disponível" está, você pode executar o comando a seguir.
Get-ClusterGroupDefina a ação de recuperação de disco e inicie os discos.
Get-ClusterResource "Physical Disk Resource Name" | Set-ClusterParameter -Name DiskRecoveryAction -Value 1 Start-ClusterResource -Name "Physical Disk Resource Name"Um reparo deve ser iniciado automaticamente. Aguarde a conclusão do reparo. Ele pode entrar em um estado suspenso e começar novamente. Para monitorar o progresso:
- Execute Get-StorageJob para monitorar o status do reparo e ver quando ele é concluído.
- Execute Get-VirtualDisk e verifique se o Espaço retorna um HealthStatus de Íntegro.
Depois que o reparo for concluído e os Discos Virtuais estiverem íntegros, altere os parâmetros do Disco Virtual novamente.
Get-ClusterResource "Physical Disk Resource Name" | Set-ClusterParameter -Name DiskRecoveryAction -Value 0Colocar os discos offline e, em seguida, online novamente para que o DiskRecoveryAction entre em vigor:
Stop-ClusterResource "Physical Disk Resource Name" Start-ClusterResource "Physical Disk Resource Name"Adicione os Discos Virtuais afetados de volta ao CSV.
Add-ClusterSharedVolume -Name "Physical Disk Resource Name"
DiskRecoveryAction é uma opção de substituição que permite anexar o volume Espaço no modo de leitura/gravação sem nenhuma verificação. A propriedade permite diagnosticar por que um volume não está ficando online. É muito semelhante ao Modo de Manutenção, mas você pode invocá-lo em um recurso em um estado com falha. Ele também permite que você acesse os dados para que você possa copiá-los. Esse acesso é útil em situações sem redundância. A propriedade DiskRecoveryAction foi adicionada em 22 de fevereiro de 2018, atualização, KB 4077525.
Status desanexado em um cluster
Quando você executa o cmdlet Get-VirtualDiskGet-VirtualDiskOperationalStatus, o OperationalStatus para um ou mais Espaços de Armazenamento Diretos discos virtuais é Desanexado. No entanto, o HealthStatus relatado pelo cmdlet Get-PhysicalDisk indica que todos os discos físicos estão em um estado Íntegro.
Este exemplo mostra a saída do Get-VirtualDisk cmdlet.
| Nome Amigável | ResiliencySettingName | OperationalStatus | Estado de Saúde | IsManualAttach | Tamanho | PSComputerName |
|---|---|---|---|---|---|---|
| Disco4 | Espelho | OKEY | Íntegros | verdadeiro | 10 TB (terabytes) | Node-01.conto... |
| Disco 3 | Espelho | OKEY | Íntegros | verdadeiro | 10 TB (terabytes) | Node-01.conto... |
| Disco 2 | Espelho | Desanexado | Desconhecido | verdadeiro | 10 TB (terabytes) | Node-01.conto... |
| Disco1 | Espelho | Desanexado | Desconhecido | verdadeiro | 10 TB (terabytes) | Node-01.conto... |
Além disso, os seguintes eventos podem ser registrados nos nós:
Log Name: Microsoft-Windows-StorageSpaces-Driver/Operational
Source: Microsoft-Windows-StorageSpaces-Driver
Event ID: 311
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: Virtual disk {GUID} requires a data integrity scan.
Data on the disk is out-of-sync and a data integrity scan is required.
To start the scan, run this command:
Get-ScheduledTask -TaskName "Data Integrity Scan for Crash Recovery" | Start-ScheduledTask
Once you have resolved that condition, you can online the disk by using these commands in PowerShell:
Get-VirtualDisk | ?{ $_.ObjectId -Match "{GUID}" } | Get-Disk | Set-Disk -IsReadOnly $false
Get-VirtualDisk | ?{ $_.ObjectId -Match "{GUID}" } | Get-Disk | Set-Disk -IsOffline $false
------------------------------------------------------------
Log Name: System
Source: Microsoft-Windows-ReFS
Event ID: 134
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: The file system was unable to write metadata to the media backing volume <VolumeId>. A write failed with status "A device which does not exist was specified." ReFS will take the volume offline. It might be mounted again automatically.
------------------------------------------------------------
Log Name: Microsoft-Windows-ReFS/Operational
Source: Microsoft-Windows-ReFS
Event ID: 5
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: ReFS failed to mount the volume.
Context: 0xffffbb89f53f4180
Error: A device which does not exist was specified.
Volume GUID:{00000000-0000-0000-0000-000000000000}
DeviceName:
Volume Name:
O Detached Operational Status ocorre se o log de rastreamento de região suja (DRT) estiver cheio. Os Espaços de Armazenamento usam o DRT (Dirty Region Tracking, rastreamento de região suja) para espaços espelhados para garantir que, quando ocorrer uma falha de energia, todas as atualizações de metadados em andamento sejam registradas. As atualizações registradas garantem que o espaço de armazenamento possa refazer ou desfazer operações. Eles retornam o espaço de armazenamento a um estado flexível e consistente após a restauração da energia e o sistema voltar a funcionar. Se o log DRT estiver cheio, o disco virtual não poderá ser colocado online até que os metadados DRT sejam sincronizados e liberados. Esse processo requer a execução de uma verificação completa, que pode levar várias horas para ser concluída.
Para corrigir o problema, siga estas etapas:
Remova os Discos Virtuais afetados do CSV.
Remove-ClusterSharedVolume -Name "CSV Name"Execute os comandos a seguir em todos os discos que não estão online.
Get-ClusterResource -Name "Physical Disk Resource Name" | Set-ClusterParameter DiskRunChkDsk 7 Start-ClusterResource -Name "Physical Disk Resource Name"Execute o comando a seguir em cada nó no qual o volume desanexado está online.
Get-ScheduledTask -TaskName "Data Integrity Scan for Crash Recovery" | Start-ScheduledTaskEssa tarefa deve ser iniciada em todos os nós nos quais o volume desanexado está online. Um reparo deve ser iniciado automaticamente. Aguarde a conclusão do reparo. Ele pode entrar em um estado suspenso e começar novamente. Para monitorar o progresso:
- Execute Get-StorageJob para monitorar o status do reparo e ver quando ele é concluído.
- Execute Get-VirtualDisk e verifique se o Espaço retorna um HealthStatus de Íntegro.
A "Verificação de Integridade dos Dados para Recuperação de Pane" é uma tarefa que não aparece como um trabalho de armazenamento e não há nenhum indicador de progresso. Se a tarefa estiver sendo exibida como em execução, ela estará em execução. Quando for concluído, ele será mostrado concluído.
Além disso, você pode exibir o status de uma tarefa de agendamento em execução usando o seguinte cmdlet:
Get-ScheduledTask | ? State -eq running
Depois que a verificação de integridade de dados para recuperação de falhas for concluída, o reparo será concluído e os discos virtuais estarão íntegros. Altere os parâmetros do disco virtual novamente.
Get-ClusterResource -Name "Physical Disk Resource Name" | Set-ClusterParameter DiskRunChkDsk 0Colocar os discos offline e, em seguida, online novamente para que o DiskRecoveryAction entre em vigor:
Stop-ClusterResource "Physical Disk Resource Name" Start-ClusterResource "Physical Disk Resource Name"Adicione os Discos Virtuais afetados de volta ao CSV.
Add-ClusterSharedVolume -Name "Physical Disk Resource Name"Use
DiskRunChkdsk value 7para anexar o volume Espaço e defina a partição para o modo somente leitura. Isso permite que o Spaces se descubra e repare a si próprio disparando um reparo. O reparo será executado automaticamente uma vez montado. Ele também permite que você acesse os dados para copiá-los. Para algumas condições de falha, como um log DRT completo, você precisa executar a tarefa agendada Verificação de Integridade dos Dados para Recuperação de Pane.
A tarefa Verificação de Integridade dos Dados para Recuperação de Pane é usada para sincronizar e limpar um log DRT (rastreamento de região suja) completo. Essa tarefa pode levar várias horas para ser concluída. A "Verificação de Integridade dos Dados para Recuperação de Pane" é uma tarefa que não aparece como um trabalho de armazenamento e não há nenhum indicador de progresso. Se a tarefa estiver sendo exibida como em execução, ela estará em execução. Quando for concluída, ela aparecerá como tal. Se você cancelar a tarefa ou reiniciar um nó enquanto essa tarefa estiver em execução, a tarefa precisará recomeçar desde o início.
Para mais informações, confira Solução de problemas de estados operacionais e de integridade de Espaços de Armazenamento Diretos.
Evento 5120 com STATUS_IO_TIMEOUT c00000b5
Importante
Para Windows Server 2016: para reduzir a chance de experimentar esses sintomas ao aplicar a atualização com a correção, use o procedimento modo de manutenção de armazenamento abaixo para instalar a atualização cumulativa de 18 de outubro de 2018 para Windows Server 2016 ou uma versão posterior quando os nós tiverem instalado uma atualização cumulativa do Windows Server 2016 lançada de 8 de maio de 2018 a 9 de outubro de 2018.
Você pode obter o evento 5120 com STATUS_IO_TIMEOUT c00000b5 depois de reiniciar um nó no Windows Server 2016 com a atualização cumulativa lançada de 8 de maio de 2018 KB 4103723 a 9 de outubro de 2018 KB 4462917 instalada.
Quando você reinicia o nó, o Evento 5120 é registrado no log de eventos do sistema e inclui um dos seguintes códigos de erro:
Event Source: Microsoft-Windows-FailoverClustering
Event ID: 5120
Description: Cluster Shared Volume 'CSVName' ('Cluster Virtual Disk (CSVName)') has entered a paused state because of 'STATUS_IO_TIMEOUT(c00000b5)'. All I/O will temporarily be queued until a path to the volume is reestablished.
Cluster Shared Volume 'CSVName' ('Cluster Virtual Disk (CSVName)') has entered a paused state because of 'STATUS_CONNECTION_DISCONNECTED(c000020c)'. All I/O will temporarily be queued until a path to the volume is reestablished.
Quando um Evento 5120 é registrado em log, um despejo dinâmico é gerado para coletar informações de depuração que podem causar sintomas adicionais ou ter um efeito de desempenho. Quando o despejo ao vivo gera, ele causa uma breve pausa. A pausa permite que um instantâneo de memória grave o arquivo de despejo. Sistemas que têm muita memória e estão sob estresse podem fazer com que os nós abandonem a associação ao cluster e também com que o evento 1135 a seguir seja registrado.
Event source: Microsoft-Windows-FailoverClustering
Event ID: 1135
Description: Cluster node 'NODENAME'was removed from the active failover cluster membership. The Cluster service on this node might have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Uma alteração introduzida em 8 de maio de 2018 ao Windows Server 2016, que foi uma atualização cumulativa para adicionar identificadores resilientes SMB para as sessões de rede SMB Espaços de Armazenamento Diretos dentro do cluster. Isso foi feito para melhorar a resiliência a falhas transitórias de rede e melhorar a forma como o RoCE lida com o congestionamento de rede. Essas melhorias também aumentaram inadvertidamente o tempo limite quando as conexões SMB tentam se reconectar e aguardam o tempo limite quando um nó é reiniciado. Esses problemas podem afetar um sistema sob estresse. Durante o tempo de inatividade não planejado, pausas de E/S de até 60 segundos também foram observadas enquanto o sistema aguarda o tempo limite das conexões. Para corrigir esse problema, instale a atualização cumulativa de 18 de outubro de 2018 para Windows Server 2016 ou uma versão posterior.
Observação
Observação Essa atualização alinha os tempos limite de CSV com tempos limite de conexão SMB para corrigir esse problema. Ela não implementa as alterações para desabilitar a geração de despejo dinâmico mencionada na seção Solução alternativa.
Fluxo do processo de desligamento
Execute o cmdlet Get-VirtualDisk e verifique se o valor HealthStatus é Íntegro.
Drene o nó executando este cmdlet:
Suspend-ClusterNode -DrainColoque os discos nesse nó no Modo de Manutenção de Armazenamento executando o seguinte cmdlet:
Get-StorageFaultDomain -Type StorageScaleUnit | Where-Object {$_.FriendlyName -eq "<NodeName>"} | Enable-StorageMaintenanceModeExecute o cmdlet e verifique se o
Get-PhysicalDiskOperationalStatusvalor éIn Maintenancemode.Execute o cmdlet para reiniciar o
Restart-Computernó.Depois que o nó for reiniciado, remova os discos nesse nó do Modo de Manutenção de Armazenamento executando o seguinte cmdlet:
Get-StorageFaultDomain -Type StorageScaleUnit | Where-Object {$_.FriendlyName -eq "<NodeName>"} | Disable-StorageMaintenanceModeRetome o nó executando o seguinte cmdlet:
Resume-ClusterNodeVerifique o status dos trabalhos de ressincronização executando o seguinte cmdlet:
Get-StorageJob
Como desabilitar despejos dinâmicos
Para atenuar o efeito da geração de despejo dinâmico em sistemas que têm muita memória e estão sob estresse, desabilite a geração de despejo dinâmico. Estas três opções são fornecidas:
Cuidado
Esse procedimento pode impedir a coleta de informações de diagnóstico de que o Suporte da Microsoft talvez precise para investigar esse problema. Um agente de suporte pode precisar solicitar que você habilite novamente a geração de despejo dinâmico com base em cenários específicos de solução de problemas.
Desabilite todos os sinalizadores.
Para desabilitar completamente todos os despejos, incluindo despejos dinâmicos em todo o sistema, siga estas etapas: Use este procedimento para esse cenário:
- Crie a seguinte chave do Registro: HKLM\System\CurrentControlSet\Control\CrashControl\ForceDumpsDisabled
- Na nova chave ForceDumpsDisabled, crie uma propriedade REG_DWORD como GuardedHost e defina seu valor como 0x10000000.
- Aplique a nova chave do Registro a cada nó de cluster.
Observação
Reinicie o computador para que a alteração de nregistry entre em vigor.
Depois que essa chave do Registro for definida, a criação do despejo dinâmico falhará e gerará um erro de "STATUS_NOT_SUPPORTED".
Permitir apenas um LiveDump
Por padrão, Relatório de Erros do Windows permitirá apenas um LiveDump por tipo de relatório por sete dias e apenas um LiveDump por computador por cinco dias. Você pode alterar isso definindo as chaves do Registro a seguir para permitir apenas um LiveDump no computador para sempre.
reg add "HKLM\Software\Microsoft\Windows\Windows Error Reporting\FullLiveKernelReports" /v SystemThrottleThreshold /t REG_DWORD /d 0xFFFFFFFF /f
reg add "HKLM\Software\Microsoft\Windows\Windows Error Reporting\FullLiveKernelReports" /v ComponentThrottleThreshold /t REG_DWORD /d 0xFFFFFFFF /f
Observação
Você deve reiniciar o computador para que essas alterações tenham efeito.
Desabilitar a geração de cluster
Para desabilitar a geração de despejos dinâmico do cluster (como quando um Evento 5120 é registrado), execute o seguinte cmdlet:
(Get-Cluster).DumpPolicy = ((Get-Cluster).DumpPolicy -Band 0xFFFFFFFFFFFFFFFE)
Esse cmdlet tem um efeito imediato em todos os nós de cluster sem uma reinicialização do computador.
Desempenho lento de E/S
Se você vir um desempenho lento de E/S, verifique se o cache está habilitado em sua configuração de Espaços de Armazenamento Diretos.
Há duas maneiras de verificar:
Usando o log do cluster. Abra o log do cluster com um editor de texto de sua escolha e procure por "[=== SBL Disks ===]". Você verá uma lista do disco no nó em que o log foi gerado.
Exemplo de discos habilitados para cache: observe que o estado é
CacheDiskStateInitializedAndBounde há um GUID presente aqui.[=== SBL Disks ===] {26e2e40f-a243-1196-49e3-8522f987df76},3,false,true,1,48,{1ff348f1-d10d-7a1a-d781-4734f4440481},CacheDiskStateInitializedAndBound,1,8087,54,false,false,HGST,HUH721010AL4200,7PG3N2ER,A21D,{d5e27a3b-42fb-410a-81c6-9d8cc12da20c},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],Cache Não Habilitado: aqui podemos ver que não há NENHUM GUID presente e o estado é CacheDiskStateNonHybrid.
[=== SBL Disks ===] {426f7f04-e975-fc9d-28fd-72a32f811b7d},12,false,true,1,24,{00000000-0000-0000-0000-000000000000},CacheDiskStateNonHybrid,0,0,0,false,false,HGST,HUH721010AL4200,7PGXXG6C,A21D,{d5e27a3b-42fb-410a-81c6-9d8cc12da20c},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],Cache Não Habilitado: quando todos os discos são do mesmo caso de tipo não está habilitado por padrão. Aqui você pode ver que não há GUID presente e o estado é
CacheDiskStateIneligibleDataPartition.{d543f90c-798b-d2fe-7f0a-cb226c77eeed},10,false,false,1,20,{00000000-0000-0000-0000-000000000000},CacheDiskStateIneligibleDataPartition,0,0,0,false,false,NVMe,INTEL SSDPE7KX02,PHLF7330004V2P0LGN,0170,{79b4d631-976f-4c94-a783-df950389fd38},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],Usando Get-PhysicalDisk.xml do SDDCDiagnosticInfo
- Abra o arquivo XML usando "$d = Import-Clixml GetPhysicalDisk.XML"
- Execute
ipmo storage. - Execute
$d. Observe que Uso é Seleção Automática, não Diário.
Você deverá ver uma saída semelhante a esta:
Nome Amigável Número de Série Tipo de Mídia CanPool OperationalStatus Estado de Saúde Uso Tamanho NVMe INTEL SSDPE7KX02 PHLF733000372P0LGN Unidade de Estado Sólido (SSD) Falso OKEY Íntegros Selecionar automaticamente 1,82 TB NVMe INTEL SSDPE7KX02 PHLF7504008J2P0LGN Unidade de Estado Sólido (SSD) Falso OKEY Íntegros Selecionar automaticamente 1,82 TB NVMe INTEL SSDPE7KX02 PHLF7504005F2P0LGN Unidade de Estado Sólido (SSD) Falso OKEY Íntegros Selecionar automaticamente 1,82 TB NVMe INTEL SSDPE7KX02 PHLF7504002A2P0LGN Unidade de Estado Sólido (SSD) Falso OKEY Íntegros Selecionar automaticamente 1,82 TB NVMe INTEL SSDPE7KX02 PHLF7504004T2P0LGN Unidade de Estado Sólido (SSD) Falso OKEY Íntegros Selecionar automaticamente 1,82 TB NVMe INTEL SSDPE7KX02 PHLF7504002E2P0LGN Unidade de Estado Sólido (SSD) Falso OKEY Íntegros Selecionar automaticamente 1,82 TB NVMe INTEL SSDPE7KX02 PHLF7330002Z2P0LGN Unidade de Estado Sólido (SSD) Falso OKEY Íntegros Selecionar automaticamente 1,82 TB NVMe INTEL SSDPE7KX02 PHLF733000272P0LGN Unidade de Estado Sólido (SSD) Falso OKEY Íntegros Selecionar automaticamente 1,82 TB NVMe INTEL SSDPE7KX02 PHLF7330001J2P0LGN Unidade de Estado Sólido (SSD) Falso OKEY Íntegros Selecionar automaticamente 1,82 TB NVMe INTEL SSDPE7KX02 PHLF733000302P0LGN Unidade de Estado Sólido (SSD) Falso OKEY Íntegros Selecionar automaticamente 1,82 TB NVMe INTEL SSDPE7KX02 PHLF7330004D2P0LGN Unidade de Estado Sólido (SSD) Falso OKEY Íntegros Selecionar automaticamente 1,82 TB
Como destruir um cluster para que você possa usar os mesmos discos novamente
Em um cluster de Espaços de Armazenamento Diretos, desabilite os Espaços de Armazenamento Diretos e use o processo de limpeza descrito em Unidades limpas. O pool de armazenamento clusterizado ainda permanece em um estado Offline e o Serviço de Integridade é removido do cluster.
A próxima etapa é remover o pool de armazenamento fantasma:
Get-ClusterResource -Name "Cluster Pool 1" | Remove-ClusterResource
Agora, se você executar Get-PhysicalDisk em qualquer um dos nós, verá todos os discos que estavam no pool. Considere um laboratório com um cluster de quatro nós com quatro discos SAS e 100 GB em cada, apresentado a cada nó. Nesse caso, depois que o Espaço de Armazenamento Direto estiver desabilitado, o que removerá a SBL (Camada do Barramento de Armazenamento), mas deixará o filtro, se você executar Get-PhysicalDisk, ele deverá relatar quatro discos, excluindo o disco do SO local. Em vez disso, foram relatados 16. Isso é o mesmo para todos os nós no cluster. Ao executar um comando Get-Disk, você verá os discos anexados localmente numerados como 0, 1, 2 etc., conforme visto nesta saída de exemplo:
| Número | Nome amigável | Número de Série | Estado de Saúde | OperationalStatus | Tamanho total | Estilo de Partição |
|---|---|---|---|---|---|---|
| 0 | Msft Virtu... | Íntegros | Online | 127 GB | GPT | |
| Msft Virtu... | Íntegros | Offline | 100 GB | CRU | ||
| Msft Virtu... | Íntegros | Offline | 100 GB | CRU | ||
| Msft Virtu... | Íntegros | Offline | 100 GB | CRU | ||
| Msft Virtu... | Íntegros | Offline | 100 GB | CRU | ||
| 1 | Msft Virtu... | Íntegros | Offline | 100 GB | CRU | |
| Msft Virtu... | Íntegros | Offline | 100 GB | CRU | ||
| 2 | Msft Virtu... | Íntegros | Offline | 100 GB | CRU | |
| Msft Virtu... | Íntegros | Offline | 100 GB | CRU | ||
| Msft Virtu... | Íntegros | Offline | 100 GB | CRU | ||
| Msft Virtu... | Íntegros | Offline | 100 GB | CRU | ||
| Msft Virtu... | Íntegros | Offline | 100 GB | CRU | ||
| 4 | Msft Virtu... | Íntegros | Offline | 100 GB | CRU | |
| 3 | Msft Virtu... | Íntegros | Offline | 100 GB | CRU | |
| Msft Virtu... | Íntegros | Offline | 100 GB | CRU | ||
| Msft Virtu... | Íntegros | Offline | 100 GB | CRU | ||
| Msft Virtu... | Íntegros | Offline | 100 GB | CRU |
Mensagem de erro sobre "tipo de mídia sem suporte" ao criar um cluster Espaços de Armazenamento Diretos usando Enable-ClusterS2D
Você pode ver erros semelhantes a esse ao executar o cmdlet Enable-ClusterS2D:
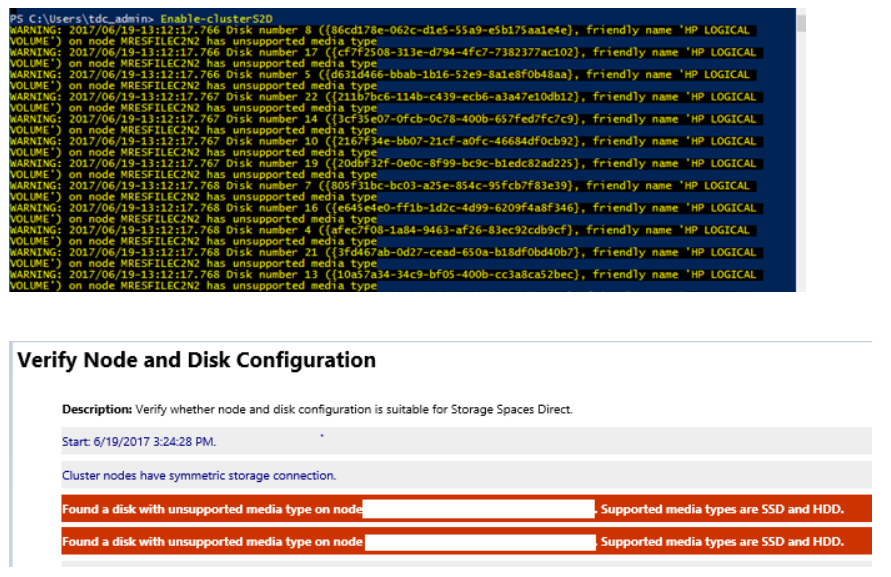
Para corrigir o problema, verifique se o adaptador HBA está configurado no modo HBA. Nenhum HBA deve ser configurado no modo RAID.
Enable-ClusterStorageSpacesDirect trava em "Aguardando até que os discos SBL sejam exibidos" ou em 27%
Você verá as seguintes informações no relatório de validação:
O disco <identifier> conectado ao nó <nodename> retornou uma Associação de Porta SCSI e o dispositivo de compartimento correspondente não foi encontrado. O hardware não é compatível com Espaços de Armazenamento Diretos (S2D). Entre em contato com o fornecedor do hardware para verificar o suporte para SCSI Enclosure Services (SES).
O problema é com o cartão expansor SAS hpe que está entre os discos e o cartão HBA. O expansor SAS cria uma ID duplicada entre a primeira unidade conectada ao expansor e o próprio expansor. Isso foi resolvido no Firmware do Expansor SAS dos Controladores de Matriz Inteligente do HPE: 4.02.
A série Intel SSD DC P4600 tem um NGUID não exclusivo
Você pode ver um problema em que um dispositivo intel SSD DC série P4600 parece estar relatando NGUID de 16 bytes semelhantes para vários namespaces, como 0100000001000000E4D25C000014E214 ou 0100000001000000E4D25C0000EEE214 no exemplo abaixo.
| Identificação única | ID do dispositivo | Tipo de Mídia | TipoDeÔnibus | Número de Série | Tamanho | CanPool | Nome Amigável | OperationalStatus |
|---|---|---|---|---|---|---|---|---|
| 5000CCA251D12E30 | 0 | Disco Rígido (HDD) | SAS | 7PKR197G | 10000831348736 | Falso | HGST | HUH721010AL4200 |
| eui.01000000001000000E4D25C000014E214 | 4 | Unidade de Estado Sólido (SSD) | NVMe | 0100_0000_0100_0000_E4D2_5C00_0014_E214. | 1600321314816 | verdadeiro | INTELIGÊNCIA | SSDPE2KE016T7 |
| eui.01000000001000000E4D25C000014E214 | 5 | Unidade de Estado Sólido (SSD) | NVMe | 0100_0000_0100_0000_E4D2_5C00_0014_E214. | 1600321314816 | verdadeiro | INTELIGÊNCIA | SSDPE2KE016T7 |
| eui.01000000001000000E4D25C0000EEE214 | 6 | Unidade de Estado Sólido (SSD) | NVMe | 0100_0000_0100_0000_E4D2_5C00_00EE_E214. | 1600321314816 | verdadeiro | INTELIGÊNCIA | SSDPE2KE016T7 |
| eui.01000000001000000E4D25C0000EEE214 | 7 | Unidade de Estado Sólido (SSD) | NVMe | 0100_0000_0100_0000_E4D2_5C00_00EE_E214. | 1600321314816 | verdadeiro | INTELIGÊNCIA | SSDPE2KE016T7 |
Para corrigir esse problema, atualize o firmware nas unidades Intel para a versão mais recente. A versão de firmware QDV101B1 de maio de 2018 resolve esse problema.
A versão de maio de 2018 da Intel SSD Data Center Tool inclui uma atualização de firmware, QDV101B1, para a série Intel SSD DC P4600.
HealthStatus para o disco físico e OperationalStatus
Em um cluster de Espaços de Armazenamento Diretos do Windows Server 2016, você pode ver o HealthStatus para um ou mais discos físicos como "Íntegro", enquanto o OperationalStatus é "(Removendo do pool, OK)".
"Removendo do Pool" é uma intenção definida quando Remove-PhysicalDisk é chamado, mas armazenado em Integridade para manter o estado e permitir a recuperação se a operação de remoção falhar. Você pode alterar manualmente o OperationalStatus para Íntegro com um dos seguintes métodos:
- Remova o disco físico do pool e adicione-o novamente.
- Import-Module Clear-PhysicalDiskHealthData.ps1
- Execute o script Clear-PhysicalDiskHealthData.ps1 para limpar a intenção. Este script está disponível para download como um arquivo .txt. Você deve salvá-lo como um arquivo ps1 antes de executá-lo.
Aqui estão alguns exemplos mostrando como executar o script:
Use o parâmetro SerialNumber para especificar o disco que você precisa definir como Íntegro. Você pode obter o número de série de
WMI MSFT_PhysicalDiskouGet-PhysicalDisk. Este exemplo usa zeros para representar o número de série.Clear-PhysicalDiskHealthData -Intent -Policy -SerialNumber 000000000000000 -Verbose -ForceUse o parâmetro para especificar o
UniqueIddisco, novamente deWMI MSFT_PhysicalDiskouGet-PhysicalDisk.Clear-PhysicalDiskHealthData -Intent -Policy -UniqueId 00000000000000000 -Verbose -Force
A cópia do arquivo está lenta
Você pode ver um problema ao usar Explorador de Arquivos para copiar um VHD grande para o disco virtual – a cópia do arquivo está demorando mais do que o esperado.
Não recomendamos que você use o Explorador de Arquivos, Robocopy ou Xcopy para copiar um VHD grande para o disco virtual. Desempenho de nova transferência mais lento do que o esperado O processo de cópia não passa pela pilha de Espaços de Armazenamento Diretos, que fica mais baixa na pilha de armazenamento e, em vez disso, atua como um processo de cópia local.
Se você quiser testar o desempenho de Espaços de Armazenamento Diretos, recomendamos usar VMFleet e Diskspd para fazer teste de carga e estresse dos servidores para obter uma linha de base e definir as expectativas do desempenho do Espaços de Armazenamento Diretos.
Eventos esperados que você veria no restante dos nós durante a reinicialização de um nó.
É seguro ignorar estes eventos:
Event ID 205: Windows lost communication with physical disk {XXXXXXXXXXXXXXXXXXXX}. This can occur if a cable failed or was disconnected, or if the disk itself failed.
Event ID 203: Windows lost communication with physical disk {XXXXXXXXXXXXXXXXXXXX}. This can occur if a cable failed or was disconnected, or if the disk itself failed.
Se você estiver executando VMs do Azure, poderá ignorar este evento: ID do Evento 32: o driver detectou que o dispositivo \Device\Harddisk5\DR5 tem seu cache de gravação habilitado. Pode ocorrer corrupção de dados.
Erros de desempenho lento ou "Comunicação Perdida", "Erro de E/S", "Desanexado" ou "Sem Redundância" para implantações que usam dispositivos Intel P3x00 NVMe
Identificamos um problema crítico que afeta alguns usuários Espaços de Armazenamento Diretos que estão usando hardware com base na família Intel P3x00 de dispositivos NVM Express (NVMe) com versões de firmware anteriores à "Versão de Manutenção 8".
Observação
Os OEMs individuais podem ter dispositivos baseados na família Intel P3x00 de dispositivos NVMe com cadeias de caracteres de versão de firmware exclusivas. Entre em contato com o OEM para obter mais informações sobre a versão mais recente do firmware.
Se você estiver usando hardware em sua implantação com base na família Intel P3x00 de dispositivos NVMe, recomendamos aplicar imediatamente o firmware disponível mais recente (pelo menos a Versão de Manutenção 8).