Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
No estágio anterior deste tutorial, adquirimos o conjunto de dados que usaremos para treinar nosso modelo de análise de dados com o PyTorch. Agora, é hora de colocar esses dados em uso.
Para treinar o modelo de análise de dados com o PyTorch, você precisa concluir as seguintes etapas:
- Carregue os dados. Se você concluiu a etapa anterior deste tutorial, já lidou com isso.
- Defina uma rede neural.
- Defina uma função de perda.
- Treine o modelo nos dados de treinamento.
- Teste a rede nos dados de teste.
Definir uma rede neural
Neste tutorial, você criará um modelo de rede neural básico com três camadas lineares. A estrutura do modelo é a seguinte:
Linear -> ReLU -> Linear -> ReLU -> Linear
Uma camada Linear aplica uma transformação linear aos dados de entrada. Você precisa especificar o número de recursos de entrada e o número de recursos de saída que devem corresponder ao número de classes.
A camada ReLu é uma função de ativação para definir todos os recursos de entrada como zero ou mais. Assim, quando uma camada reLU é aplicada, qualquer número menor que 0 é alterado para zero, enquanto outros são mantidos iguais. Aplicaremos a camada de ativação nas duas camadas ocultas e nenhuma ativação na última camada linear.
Parâmetros de modelo
Os parâmetros de modelo dependem de nossa meta e dos dados de treinamento. O tamanho da entrada depende do número de recursos que alimentamos o modelo – quatro em nosso caso. O tamanho da saída é de três, pois há três espécies possíveis de Íris.
Com três camadas lineares, (4,24) -> (24,24) -> (24,3)a rede terá 744 pesos (96+576+72).
A taxa de aprendizado (lr) define o controle de quanto você está ajustando os pesos da nossa rede em relação ao gradiente de perda. Quanto menor for, mais lento será o treinamento. Você definirá lr como 0.01 neste tutorial.
Como funciona a rede?
Aqui, você está criando uma rede direta. Durante o processo de treinamento, a rede processará a entrada através de todas as camadas, calculará a perda para entender a diferença entre o rótulo previsto da imagem e o correto, e propagará os gradientes de volta para a rede para atualizar os pesos das camadas. Ao iterar em um grande conjunto de dados de entradas, a rede aprenderá a definir seus pesos para obter os melhores resultados.
Uma função forward calcula o valor da função de perda, e uma função backward calcula os gradientes dos parâmetros que podem ser aprendidos. Ao criar nossa rede neural com PyTorch, você só precisa definir a função forward. A função backward será definida automaticamente.
- Copie o código a seguir no arquivo
DataClassifier.pyno Visual Studio para definir os parâmetros do modelo e a rede neural.
# Define model parameters
input_size = list(input.shape)[1] # = 4. The input depends on how many features we initially feed the model. In our case, there are 4 features for every predict value
learning_rate = 0.01
output_size = len(labels) # The output is prediction results for three types of Irises.
# Define neural network
class Network(nn.Module):
def __init__(self, input_size, output_size):
super(Network, self).__init__()
self.layer1 = nn.Linear(input_size, 24)
self.layer2 = nn.Linear(24, 24)
self.layer3 = nn.Linear(24, output_size)
def forward(self, x):
x1 = F.relu(self.layer1(x))
x2 = F.relu(self.layer2(x1))
x3 = self.layer3(x2)
return x3
# Instantiate the model
model = Network(input_size, output_size)
Você também precisará definir o dispositivo de execução com base no disponível em seu computador. O PyTorch não tem uma biblioteca dedicada para GPU, mas você pode definir manualmente o dispositivo de execução. Esse dispositivo será uma GPU Nvidia, se você a tiver em seu computador, ou a CPU, caso não tenha.
- Copie o seguinte código para definir o dispositivo de execução:
# Define your execution device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("The model will be running on", device, "device\n")
model.to(device) # Convert model parameters and buffers to CPU or Cuda
- Como a última etapa, defina uma função para salvar o modelo:
# Function to save the model
def saveModel():
path = "./NetModel.pth"
torch.save(model.state_dict(), path)
Observação
Interessado em saber mais sobre rede neural com PyTorch? Confira a documentação do PyTorch.
Definir uma função de perda
Uma função de perda calcula um valor que estima o quão longe a saída está do alvo. O objetivo principal é reduzir o valor da função de perda alterando os valores de vetor de peso por meio de retropropagação em redes neurais.
O valor de perda é diferente da precisão do modelo. A função de perda representa o desempenho do nosso modelo após cada iteração de otimização no conjunto de treinamento. A precisão do modelo é calculada nos dados de teste e mostra o percentual de previsões corretas.
No PyTorch, o pacote de rede neural contém várias funções de perda que formam os blocos de construção de redes neurais profundas. Se você quiser saber mais sobre essas especificidades, comece com a observação acima. Aqui, vamos usar as funções existentes otimizadas para classificação desta maneira, além de usar uma função de perda de classificação de entropia cruzada e um otimizador Adam. No otimizador, a taxa de aprendizado (lr) define o controle de quanto você está ajustando os pesos da nossa rede em relação ao gradiente de perda. Você vai defini-lo como 0,001 aqui - quanto menor for, mais lento será o treinamento.
- Copie o código a seguir no arquivo
DataClassifier.pyno Visual Studio para definir a função de perda e um otimizador.
# Define the loss function with Classification Cross-Entropy loss and an optimizer with Adam optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
Treine o modelo nos dados de treinamento.
Para treinar o modelo, você precisa fazer um loop em nosso iterador de dados, alimentar as entradas na rede e otimizar. Para validar os resultados, basta comparar os rótulos previstos com os rótulos reais no conjunto de dados de validação após cada época de treinamento.
O programa exibirá a perda de treinamento, a perda de validação e a precisão do modelo para cada época ou para cada iteração completa no conjunto de treinamento. Ele salvará o modelo com a precisão mais alta e, após 10 épocas, o programa exibirá a precisão final.
- Adicione o seguinte código ao arquivo
DataClassifier.py
# Training Function
def train(num_epochs):
best_accuracy = 0.0
print("Begin training...")
for epoch in range(1, num_epochs+1):
running_train_loss = 0.0
running_accuracy = 0.0
running_vall_loss = 0.0
total = 0
# Training Loop
for data in train_loader:
#for data in enumerate(train_loader, 0):
inputs, outputs = data # get the input and real species as outputs; data is a list of [inputs, outputs]
optimizer.zero_grad() # zero the parameter gradients
predicted_outputs = model(inputs) # predict output from the model
train_loss = loss_fn(predicted_outputs, outputs) # calculate loss for the predicted output
train_loss.backward() # backpropagate the loss
optimizer.step() # adjust parameters based on the calculated gradients
running_train_loss +=train_loss.item() # track the loss value
# Calculate training loss value
train_loss_value = running_train_loss/len(train_loader)
# Validation Loop
with torch.no_grad():
model.eval()
for data in validate_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
val_loss = loss_fn(predicted_outputs, outputs)
# The label with the highest value will be our prediction
_, predicted = torch.max(predicted_outputs, 1)
running_vall_loss += val_loss.item()
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
# Calculate validation loss value
val_loss_value = running_vall_loss/len(validate_loader)
# Calculate accuracy as the number of correct predictions in the validation batch divided by the total number of predictions done.
accuracy = (100 * running_accuracy / total)
# Save the model if the accuracy is the best
if accuracy > best_accuracy:
saveModel()
best_accuracy = accuracy
# Print the statistics of the epoch
print('Completed training batch', epoch, 'Training Loss is: %.4f' %train_loss_value, 'Validation Loss is: %.4f' %val_loss_value, 'Accuracy is %d %%' % (accuracy))
Teste o modelo com base nos dados de teste.
Agora que treinamos o modelo, podemos testar o modelo com o conjunto de dados de teste.
Adicionaremos duas funções de teste. A primeira testa o modelo salvo na parte anterior. Ele testará o modelo com o conjunto de dados de teste de 45 itens e imprimirá a precisão do modelo. A segunda é uma função opcional para testar a confiança do modelo na previsão de cada uma das três espécies de íris, representada pela probabilidade de classificação bem-sucedida de cada espécie.
- Adicione o seguinte código ao arquivo
DataClassifier.py.
# Function to test the model
def test():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
running_accuracy = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
outputs = outputs.to(torch.float32)
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
print('Accuracy of the model based on the test set of', test_split ,'inputs is: %d %%' % (100 * running_accuracy / total))
# Optional: Function to test which species were easier to predict
def test_species():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
labels_length = len(labels) # how many labels of Irises we have. = 3 in our database.
labels_correct = list(0. for i in range(labels_length)) # list to calculate correct labels [how many correct setosa, how many correct versicolor, how many correct virginica]
labels_total = list(0. for i in range(labels_length)) # list to keep the total # of labels per type [total setosa, total versicolor, total virginica]
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
label_correct_running = (predicted == outputs).squeeze()
label = outputs[0]
if label_correct_running.item():
labels_correct[label] += 1
labels_total[label] += 1
label_list = list(labels.keys())
for i in range(output_size):
print('Accuracy to predict %5s : %2d %%' % (label_list[i], 100 * labels_correct[i] / labels_total[i]))
Por fim, adicione o código principal. Isso inicia o treinamento do modelo, salva o modelo e exibe os resultados na tela. Executaremos apenas duas iterações [num_epochs = 25] no conjunto de treinamento, assim o processo de treinamento não levará muito tempo.
- Adicione o seguinte código ao arquivo
DataClassifier.py.
if __name__ == "__main__":
num_epochs = 10
train(num_epochs)
print('Finished Training\n')
test()
test_species()
Vamos executar o teste! Verifique se os menus suspensos na barra de ferramentas superior estão definidos como Debug. Altere de Solution Platform para x64 para executar o projeto em seu computador local se o dispositivo for de 64 bits, ou x86 se for de 32 bits.
- Para executar o projeto, clique no
Start Debuggingbotão na barra de ferramentas ou pressioneF5.
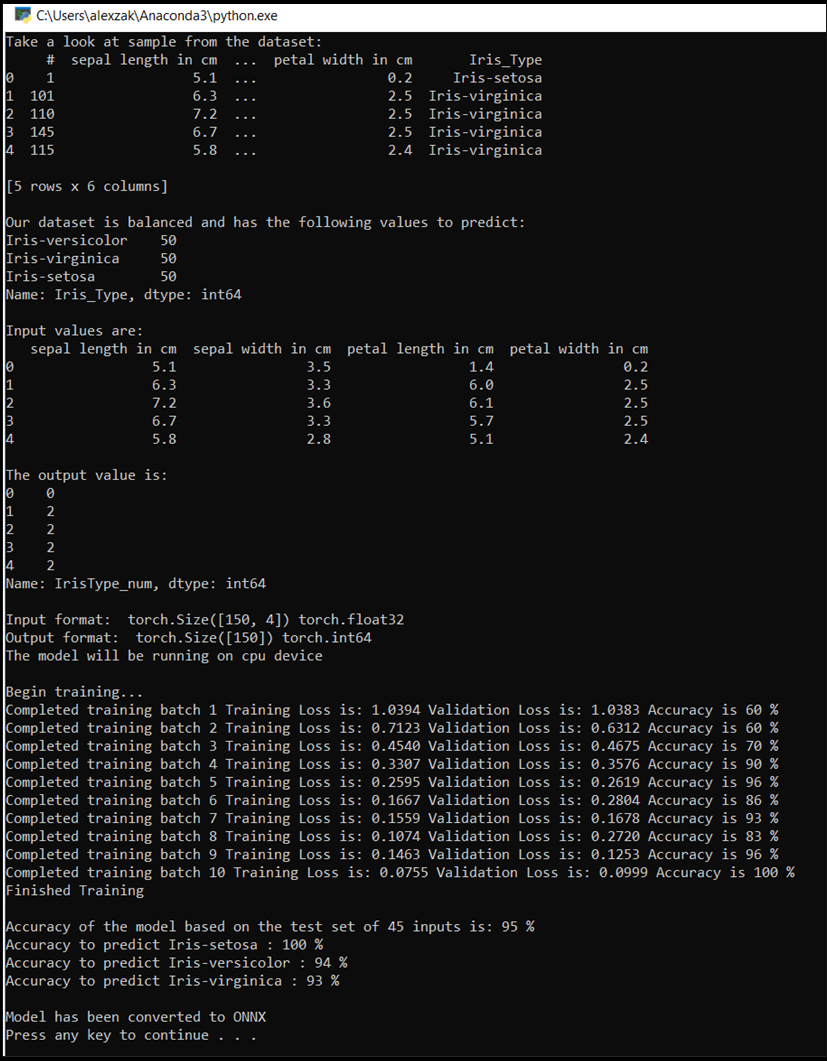
Isso abre a janela do console, em que é possível ver o processo de treinamento. Como você definiu, o valor de perda será impresso a cada época. A expectativa é que o valor da perda diminua a cada loop.
Depois que o treinamento terminar, você deverá ver uma saída semelhante à abaixo. Seus números não serão exatamente os mesmos - o treinamento depende de muitos fatores e nem sempre retornará resultados idênticos - mas a aparência deve ser semelhante.
Próximas etapas
Agora que temos um modelo de classificação, a próxima etapa é converter o modelo no formato ONNX.