Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Os CSMs (mapas de sombra em cascata) são a melhor maneira de combater um dos erros mais prevalentes com sombreamento: aliasing de perspectiva. Este artigo técnico, que pressupõe que o leitor esteja familiarizado com o mapeamento de sombra, aborda o tópico dos CSMs. Especificamente, ele:
- explica a complexidade dos CSMs;
- fornece detalhes sobre as possíveis variações dos algoritmos CSM;
- descreve as duas técnicas de filtragem mais comuns: PCF (filtragem mais próxima de porcentagem) e filtragem com VSMs (mapas de sombra de variação);
- identifica e aborda algumas das armadilhas comuns associadas à adição de filtragem a CSMs; e
- mostra como mapear CSMs para o Direct3D 10 até o hardware direct3D 11.
O código usado neste artigo pode ser encontrado no SDK (Kit de Desenvolvimento de Software) do DirectX nos exemplos CascadedShadowMaps11 e VarianceShadows11. Este artigo será mais útil depois de implementar as técnicas abordadas no artigo técnico, técnicas comuns para melhorar os mapas de profundidade de sombra, são implementadas.
Mapas de sombra em cascata e aliasing de perspectiva
O aliasing de perspectiva em um mapa de sombra é um dos problemas mais difíceis de superar. No artigo técnico, técnicas comuns para melhorar mapas de profundidade de sombra, o aliasing de perspectiva é descrito e algumas abordagens para atenuar o problema são identificadas. Na prática, os CSMs tendem a ser a melhor solução e geralmente são empregados em jogos modernos.
O conceito básico de CSMs é fácil de entender. Diferentes áreas do frusto da câmera exigem mapas de sombra com resoluções diferentes. Objetos mais próximos do olho exigem uma resolução maior do que objetos mais distantes. Na verdade, quando o olho se move muito perto da geometria, os pixels mais próximos do olho podem exigir tanta resolução que até mesmo um mapa de sombra 4096 × 4096 é insuficiente.
A ideia básica dos CSMs é particionar o frusto em várias frutosta. Um mapa de sombra é renderizado para cada subfrusto; o sombreador de pixel, em seguida, exemplos do mapa que mais correspondem à resolução necessária (Figura 2).
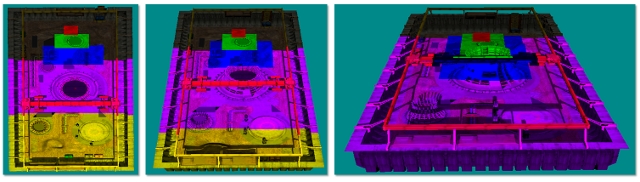
Figura 1. Cobertura do mapa de sombra
cobertura do mapa de sombra 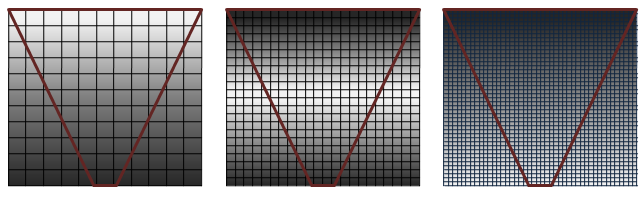
Na Figura 1, a qualidade é mostrada (da esquerda para a direita) da mais alta para a mais baixa. A série de grades que representam mapas de sombra com um frusto de exibição (cone invertido em vermelho) mostra como a cobertura de pixels é afetada com diferentes mapas de sombra de resolução. As sombras são da mais alta qualidade (pixels brancos) quando há uma proporção de pixels de mapeamento de 1:1 no espaço claro para texels no mapa de sombra. O aliasing de perspectiva ocorre na forma de mapas de textura grandes e bloqueados (imagem esquerda) quando muitos pixels são mapeados para o mesmo texel de sombra. Quando o mapa de sombra é muito grande, ele está sob amostragem. Nesse caso, os texels são ignorados, artefatos cintilantes são introduzidos e o desempenho é afetado.
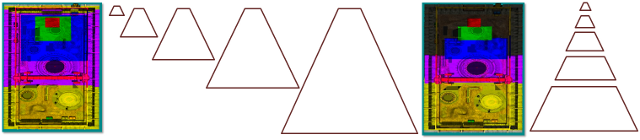
Figura 2. Qualidade da sombra do CSM
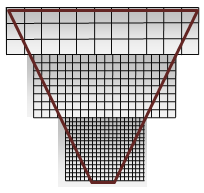 de qualidade de sombra csm
de qualidade de sombra csm
A Figura 2 mostra recortes da seção de mais alta qualidade em cada mapa de sombra na Figura 1. O mapa de sombra com os pixels mais colocados (no ápice) é mais próximo do olho. Tecnicamente, são mapas do mesmo tamanho, com branco e cinza usados para exemplificar o sucesso do mapa de sombra em cascata. O branco é ideal porque mostra uma boa cobertura: uma taxa de 1:1 para pixels de espaço nos olhos e texels de mapa de sombra.
Os CSMs exigem as seguintes etapas por quadro.
Particione o frusto em subfrusta.
Compute uma projeção ortográfica para cada subfrusto.
Renderize um mapa de sombra para cada subfrusto.
Renderize a cena.
Associe os mapas de sombra e a renderização.
O sombreador de vértice faz o seguinte:
- Calcula coordenadas de textura para cada subfrusto claro (a menos que a coordenada de textura necessária seja calculada no sombreador de pixel).
- Transforma e acende o vértice, e assim por diante.
O sombreador de pixel faz o seguinte:
- Determina o mapa de sombra adequado.
- Transforma as coordenadas de textura, se necessário.
- Amostra a cascata.
- Acende o pixel.
Particionando o Frustum
Particionar o frusto é o ato de criar subfrusta. Uma técnica para dividir o frusto é calcular intervalos de zero a cem por cento na direção Z. Cada intervalo, em seguida, representa um plano próximo e um plano distante como uma porcentagem do eixo Z.
Figura 3. Exibir frutos particionados arbitrariamente
Na prática, o recálculo das divisões de frutos por quadro faz com que as bordas da sombra brilquem. A prática geralmente aceita é usar um conjunto estático de intervalos em cascata por cenário. Nesse cenário, o intervalo ao longo do eixo Z é usado para descrever um subfrusto que ocorre ao particionar o frusto. Determinar os intervalos de tamanho corretos para uma determinada cena depende de vários fatores.
Orientação da Geometria da Cena
Em relação à geometria da cena, a orientação da câmera afeta a seleção de intervalo em cascata. Por exemplo, uma câmera muito perto do chão, como uma câmera terrestre em um jogo de futebol, tem um conjunto estático diferente de intervalos em cascata do que uma câmera no céu.
A Figura 4 mostra algumas câmeras diferentes e suas respectivas partições. Quando o intervalo Z da cena é muito grande, mais planos divididos são necessários. Por exemplo, quando o olho está muito próximo do plano terrestre, mas objetos distantes ainda são visíveis, várias cascatas podem ser necessárias. Dividir o frusto para que mais divisões estejam perto do olho (onde o aliasing de perspectiva está mudando mais rápido) também é valioso. Quando a maior parte da geometria é agrupada em uma pequena seção (como uma exibição de sobrecarga ou um simulador de voo) do frusto de exibição, menos cascatas são necessárias.
Figura 4. Configurações diferentes exigem divisões de frutos diferentes
(Esquerda) Quando a geometria tem um intervalo dinâmico alto em Z, muitas cascatas são necessárias. (Centro) Quando a geometria tem um intervalo dinâmico baixo em Z, há pouco benefício de vários frutos. (À direita) Somente três partições são necessárias quando o intervalo dinâmico é médio.
Orientação da luz e da câmera
A matriz de projeção de cada cascata é ajustada firmemente em torno de seu subfrusto correspondente. Em configurações em que a câmera de exibição e as direções de luz são ortogonais, as cascatas podem ser ajustadas firmemente com pouca sobreposição. A sobreposição fica maior à medida que a luz e a câmera de exibição se movem para o alinhamento paralelo (Figura 5). Quando a luz e a câmera de exibição são quase paralelas, ela é chamada de "frusta de duelo", e é um cenário muito difícil para a maioria dos algoritmos de sombreamento. Não é incomum restringir a luz e a câmera para que esse cenário não ocorra. No entanto, os CSMs têm um desempenho muito melhor do que muitos outros algoritmos nesse cenário.
Figura 5. A sobreposição em cascata aumenta à medida que a direção da luz se torna paralela à direção da câmera
Muitas implementações de CSM usam frusta de tamanho fixo. O sombreador de pixel pode usar a profundidade Z para indexar na matriz de cascatas quando o frusto é dividido em intervalos de tamanho fixo.
Calculando um limite de View-Frustum
Depois que os intervalos de frutos são selecionados, a subfrusta é criada usando um dos dois: ajustar à cena e ajustar-se à cascata.
Ajustar à cena
Todo o frusta pode ser criado com o mesmo plano próximo. Isso força as cascatas a se sobreporem. O exemplo CascadedShadowMaps11 chama essa técnica adequada à cena.
Ajustar-se à Cascata
Como alternativa, o frusta pode ser criado com o intervalo de partição real sendo usado como planos próximos e distantes. Isso causa um ajuste mais apertado, mas degenera para caber na cena no caso de frutosta de duelo. Os exemplos CascadedShadowMaps11 chamam essa técnica de adequada para cascata.
Esses dois métodos são mostrados na Figura 6. Ajustar-se a cascata desperdiça menos resolução. O problema com ajuste à cascata é que a projeção ortográfica cresce e encolhe com base na orientação do frusto de exibição. O ajuste à técnica de cena armazena a projeção ortográfica pelo tamanho máximo do frusto da exibição removendo os artefatos que aparecem quando a câmera de exibição se move. Técnicas Comuns para Melhorar Mapas de Profundidade de Sombra aborda os artefatos que aparecem quando a luz se move na seção "Movendo a luz em incrementos do tamanho de texel".
Figura 6. Ajustar-se à cena versus ajustar-se à cascata
 em cascata
em cascata
Renderizar o Mapa de Sombras
O exemplo CascadedShadowMaps11 renderiza os mapas de sombra em um buffer grande. Isso ocorre porque o PCF em matrizes de textura é um recurso do Direct3D 10.1. Para cada cascata, um visor é criado que abrange a seção do buffer de profundidade correspondente a essa cascata. Um sombreador de pixel nulo é associado porque apenas a profundidade é necessária. Por fim, o visor correto e a matriz de sombra são definidos para cada cascata à medida que os mapas de profundidade são renderizados um de cada vez no buffer de sombra principal.
Renderizar a cena
O buffer que contém as sombras agora está associado ao sombreador de pixel. Há dois métodos para selecionar a cascata implementada na amostra CascadedShadowMaps11. Esses dois métodos são explicados com código de sombreador.
Seleção em cascata Interval-Based
Figura 7. Seleção em cascata baseada em intervalo

Na seleção baseada em intervalo (Figura 7), o sombreador de vértice calcula a posição no espaço mundial do vértice.
Output.vDepth = mul( Input.vPosition, m_mWorldView ).z;
O sombreador de pixel recebe a profundidade interpolada.
fCurrentPixelDepth = Input.vDepth;
A seleção em cascata baseada em intervalo usa uma comparação de vetor e um produto de ponto para determinar a cacade correta. O CASCADE_COUNT_FLAG especifica o número de cascatas. O m_fCascadeFrustumsEyeSpaceDepths_data restringe as partições de frusto de exibição. Após a comparação, o fComparison contém um valor de 1 em que o pixel atual é maior que a barreira e um valor de 0 quando a cascata atual é menor. Um produto ponto soma esses valores em um índice de matriz.
float4 vCurrentPixelDepth = Input.vDepth;
float4 fComparison = ( vCurrentPixelDepth > m_fCascadeFrustumsEyeSpaceDepths_data[0]);
float fIndex = dot(
float4( CASCADE_COUNT_FLAG > 0,
CASCADE_COUNT_FLAG > 1,
CASCADE_COUNT_FLAG > 2,
CASCADE_COUNT_FLAG > 3)
, fComparison );
fIndex = min( fIndex, CASCADE_COUNT_FLAG );
iCurrentCascadeIndex = (int)fIndex;
Depois que a cascata for selecionada, a coordenada de textura deverá ser transformada na cascata correta.
vShadowTexCoord = mul( InterpolatedPosition, m_mShadow[iCascadeIndex] );
Essa coordenada de textura é usada para amostrar a textura com a coordenada X e a coordenada Y. A coordenada Z é usada para fazer a comparação de profundidade final.
Seleção em cascata Map-Based
A seleção baseada em mapa (Figura 8) testa os quatro lados das cascatas para encontrar o mapa mais apertado que abrange o pixel específico. Em vez de calcular a posição no espaço mundial, o sombreador de vértice calcula a posição de espaço de exibição para cada cascata. O sombreador de pixel itera sobre as cascatas para dimensionar e deslocar as coordenadas de textura para que indexem a cascata atual. Em seguida, a coordenada de textura é testada em relação aos limites de textura. Quando os valores X e Y da coordenada de textura se enquadram em uma cascata, eles são usados para amostrar a textura. A coordenada Z é usada para fazer a comparação de profundidade final.
Figura 8. Seleção em cascata baseada em mapa
 de seleção em cascata baseada em mapa
de seleção em cascata baseada em mapa
Seleção Interval-Based vs. Seleção Map-Based
A seleção baseada em intervalo é um pouco mais rápida do que a seleção baseada em mapa porque a seleção em cascata pode ser feita diretamente. A seleção baseada em mapa deve cruzar a coordenada de textura com os limites em cascata.
A seleção baseada em mapa usa a cascata com mais eficiência quando os mapas de sombra não se alinham perfeitamente (consulte a Figura 8).
Mesclar entre cascatas
OS VSMs (discutidos posteriormente neste artigo) e técnicas de filtragem, como PCF, podem ser usados com CSMs de baixa resolução para produzir sombras suaves. Infelizmente, isso resulta em uma costura visível (Figura 9) entre camadas em cascata porque a resolução não corresponde. A solução é criar uma faixa entre mapas de sombra em que o teste de sombra é executado para ambas as cascatas. Em seguida, o sombreador interpola linearmente entre os dois valores com base na localização do pixel na banda de combinação. Os exemplos CascadedShadowMaps11 e VarianceShadows11 fornecem um controle deslizante de GUI que pode ser usado para aumentar e diminuir essa faixa de desfoque. O sombreador executa um branch dinâmico para que a grande maioria dos pixels só seja lida da cascata atual.
Figura 9. Costuras em cascata
 de costuras em cascata
de costuras em cascata
(Esquerda) Uma costura visível pode ser vista onde as cascatas se sobrepõem. (À direita) Quando as cascatas são misturadas entre elas, nenhuma costura ocorre.
Filtrando mapas de sombra
PCF
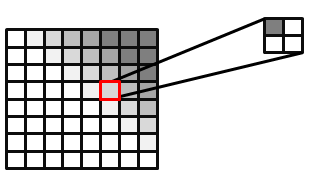
Filtrar mapas de sombra comuns não produz sombras suaves e desfocadas. O hardware de filtragem desfoca os valores de profundidade e compara esses valores desfocados com o texel de espaço claro. A borda dura resultante do teste de aprovação/falha ainda existe. Mapas de sombra desfocados só servem para mover erroneamente a borda dura. O PCF habilita a filtragem em mapas de sombra. A ideia geral do PCF é calcular uma porcentagem do pixel na sombra com base no número de subsamplas que passam no teste de profundidade sobre o número total de subsamplas.
O hardware Direct3D 10 e Direct3D 11 pode executar PCF. A entrada para um exemplo de PCF consiste na coordenada de textura e em um valor de profundidade de comparação. Para simplificar, o PCF é explicado com um filtro de quatro toques. O amostrador de textura lê a textura quatro vezes, semelhante a um filtro padrão. No entanto, o resultado retornado é uma porcentagem dos pixels que passaram no teste de profundidade. A Figura 10 mostra como um pixel aprovado em um dos quatro testes de profundidade é de 25% na sombra. O valor real retornado é uma interpolação linear com base nas coordenadas de subtexto das leituras de textura para produzir um gradiente suave. Sem essa interpolação linear, o PCF de quatro toques só seria capaz de retornar cinco valores: { 0.0, 0.25, 0.5, 0.75, 1.0 }.
Figura 10. Imagem filtrada por PCF, com 25% dos pixels selecionados cobertos
Também é possível fazer PCF sem suporte de hardware ou estender o PCF para kernels maiores. Algumas técnicas até são amostradas com um kernel ponderado. Para fazer isso, crie um kernel (como um gaussiano) para uma grade N × N. Os pesos devem somar 1. Em seguida, a textura é amostrada N2 vezes. Cada amostra é dimensionada pelos pesos correspondentes no kernel. O exemplo CascadedShadowMaps11 usa essa abordagem.
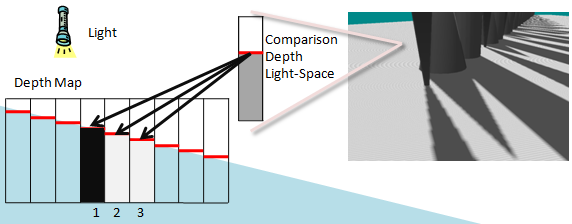
Viés de profundidade
O viés de profundidade torna-se ainda mais importante quando kernels PCF grandes são usados. É válido apenas comparar a profundidade do espaço claro de um pixel com o pixel que ele mapeia no mapa de profundidade. Os vizinhos do texel do mapa de profundidade referem-se a uma posição diferente. É provável que essa profundidade seja semelhante, mas pode ser muito diferente dependendo da cena. A Figura 11 realça os artefatos que ocorrem. Uma única profundidade é comparada a três texels vizinhos no mapa de sombra. Um dos testes de profundidade falha erroneamente porque sua profundidade não se correlaciona com a profundidade computada do espaço leve da geometria atual. A solução recomendada para esse problema é usar um deslocamento maior. Um deslocamento muito grande, no entanto, pode resultar em Peter Panning. Calcular um plano próximo apertado e plano distante ajuda a reduzir os efeitos do uso de um deslocamento.
Figura 11. Auto-sombreamento errôneo
 de auto-sombreamento errôneo
de auto-sombreamento errôneo
A auto-sombra errônea resulta da comparação de pixels na profundidade do espaço claro com os texels no mapa de sombra que não se correlacionam. A profundidade no espaço leve correlaciona-se ao texel de sombra 2 no mapa de profundidade. Texel 1 é maior que a profundidade do espaço leve, enquanto 2 é igual e 3 é menor. Texels 2 e 3 passam no teste de profundidade, enquanto Texel 1 falha.
Calculando um viés de profundidade Per-Texel com DDX e DDY para PCFs grandes
Calcular um viés de profundidade por texel com ddx e de qualidade para PCFs grandes é uma técnica que calcula o viés de profundidade correto, supondo que a superfície seja planar, para o texel do mapa de sombra adjacente.
Essa técnica ajusta a profundidade de comparação a um plano usando as informações derivadas. Como essa técnica é computacionalmente complexa, ela só deve ser usada quando uma GPU tem ciclos de computação de sobra. Quando kernels muito grandes são usados, essa pode ser a única técnica que funciona para remover artefatos de auto-sombreamento sem causar Peter Panning.
A Figura 12 realça o problema. A profundidade no espaço leve é conhecida por um texel que está sendo comparado. As profundidades de espaço leve que correspondem aos texels vizinhos no mapa de profundidade são desconhecidas.
Figura 12. Mapa de cena e profundidade

A cena renderizada é mostrada à esquerda e o mapa de profundidade com um bloco texel de exemplo é mostrado à direita. O texel de espaço nos olhos é mapeado para o pixel rotulado como D no centro do bloco. Essa comparação é precisa. A profundidade correta no espaço ocular correlacionando-se aos pixels que o vizinho D é desconhecido. Mapear os texels vizinhos de volta ao espaço ocular só será possível se assumirmos que o pixel pertence ao mesmo triângulo que D.
A profundidade é conhecida pelo texel que se correlaciona com a posição do espaço claro. A profundidade é desconhecida para os texels vizinhos no mapa de profundidade.
Em um alto nível, essa técnica usa o ddx e operações HLSL de ddy para encontrar o derivado da posição do espaço leve. Isso não étrivial porque as operações derivadas retornam o gradiente da profundidade do espaço claro em relação ao espaço de tela. Para convertê-lo em um gradiente da profundidade do espaço leve em relação ao espaço leve, uma matriz de conversão deve ser calculada.
Explicação com o código do sombreador
Os detalhes do restante do algoritmo são fornecidos como uma explicação do código de sombreador que executa essa operação. Esse código pode ser encontrado na amostra CascadedShadowMaps11. A Figura 13 mostra como as coordenadas de textura de espaço claro são mapeadas para o mapa de profundidade e como os derivados em X e Y podem ser usados para criar uma matriz de transformação.
Figura 13. Espaço de tela para matriz de espaço claro
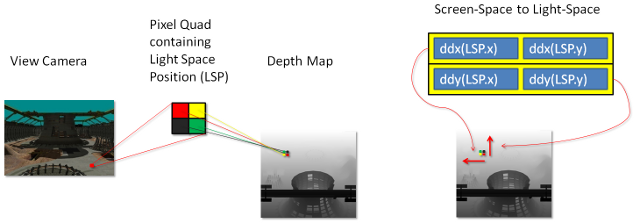
Os derivados da posição de espaço leve em X e Y são usados para criar essa matriz.
A primeira etapa é calcular o derivado da posição light-view-space.
float3 vShadowTexDDX = ddx (vShadowMapTextureCoordViewSpace);
float3 vShadowTexDDY = ddy (vShadowMapTextureCoordViewSpace);
As GPUs da classe Direct3D 11 calculam esses derivados executando 2 × 2 quad de pixels em paralelo e subtraindo as coordenadas de textura do vizinho em X para ddx e do vizinho em Y para de ddy. Esses dois derivados compõem as linhas de uma matriz 2 × 2. Em sua forma atual, essa matriz pode ser usada para converter pixels vizinhos de espaço de tela em encostas de espaço claro. No entanto, o inverso dessa matriz é necessário. Uma matriz que transforma pixels vizinhos de espaço claro em encostas de espaço de tela é necessária.
float2x2 matScreentoShadow = float2x2( vShadowTexDDX.xy, vShadowTexDDY.xy );
float fInvDeterminant = 1.0f / fDeterminant;
float2x2 matShadowToScreen = float2x2 (
matScreentoShadow._22 * fInvDeterminant,
matScreentoShadow._12 * -fInvDeterminant,
matScreentoShadow._21 * -fInvDeterminant,
matScreentoShadow._11 * fInvDeterminant );
Figura 14. Espaço claro para espaço na tela
 de espaço na tela
de espaço na tela
Essa matriz é então usada para transformar os dois texels acima e à direita do texel atual. Esses vizinhos são representados como um deslocamento do texel atual.
float2 vRightShadowTexelLocation = float2( m_fTexelSize, 0.0f );
float2 vUpShadowTexelLocation = float2( 0.0f, m_fTexelSize );
float2 vRightTexelDepthRatio = mul( vRightShadowTexelLocation,
matShadowToScreen );
float2 vUpTexelDepthRatio = mul( vUpShadowTexelLocation,
matShadowToScreen );
A proporção criada pela matriz é finalmente multiplicada pelos derivados de profundidade para calcular os deslocamentos de profundidade para os pixels vizinhos.
float fUpTexelDepthDelta =
vUpTexelDepthRatio.x * vShadowTexDDX.z
+ vUpTexelDepthRatio.y * vShadowTexDDY.z;
float fRightTexelDepthDelta =
vRightTexelDepthRatio.x * vShadowTexDDX.z
+ vRightTexelDepthRatio.y * vShadowTexDDY.z;
Esses pesos agora podem ser usados em um loop pcf para adicionar um deslocamento à posição.
for( int x = m_iPCFBlurForLoopStart; x < m_iPCFBlurForLoopEnd; ++x )
{
for( int y = m_iPCFBlurForLoopStart; y < m_iPCFBlurForLoopEnd; ++y )
{
if ( USE_DERIVATIVES_FOR_DEPTH_OFFSET_FLAG )
{
depthcompare += fRightTexelDepthDelta * ( (float) x ) +
fUpTexelDepthDelta * ( (float) y );
}
// Compare the transformed pixel depth to the depth read
// from the map.
fPercentLit += g_txShadow.SampleCmpLevelZero( g_samShadow,
float2(
vShadowTexCoord.x + ( ( (float) x ) * m_fNativeTexelSizeInX ) ,
vShadowTexCoord.y + ( ( (float) y ) * m_fTexelSize )
),
depthcompare
);
}
}
PCF e CSMs
O PCF não funciona em matrizes de textura no Direct3D 10. Para usar o PCF, todas as cascatas são armazenadas em um atlas de textura grande.
Deslocamento de Derivative-Based
Adicionar os deslocamentos baseados em derivativos para CSMs apresenta alguns desafios. Isso ocorre devido a um cálculo derivado dentro do controle de fluxo divergente. O problema ocorre devido a uma maneira fundamental que as GPUs operam. As GPUs Direct3D11 operam em 2 × 2 quads de pixels. Para executar um derivado, as GPUs geralmente subtraem a cópia do pixel atual de uma variável da cópia do pixel vizinho da mesma variável. Como isso acontece varia de GPU para GPU. As coordenadas de textura são determinadas pela seleção em cascata baseada em mapa ou com base em intervalo. Alguns pixels em um quad pixel escolhem uma cascata diferente do restante dos pixels. Isso resulta em costuras visíveis entre mapas de sombra porque os deslocamentos baseados em derivados agora estão completamente errados. A solução é executar o derivado em coordenadas de textura de espaço de exibição de luz. Essas coordenadas são as mesmas para cada cascata.
Preenchimento para kernels pcf
Índice de kernels PCF fora de uma partição em cascata se o buffer de sombra não for acolchoado. A solução é adicionar a borda externa da cascata pela metade do tamanho do kernel pcf. Isso deve ser implementado no sombreador que seleciona a cascata e na matriz de projeção que deve renderizar a cascata grande o suficiente para que a borda seja preservada.
Mapas de sombra de variação
Os VSMs (consulte mapas de sombra de variação de Donnelly e Lauritzen para obter mais informações) permitem a filtragem direta do mapa de sombra. Ao usar VSMs, todo o poder do hardware de filtragem de textura pode ser usado. A filtragem trilinear e anisotrópica (Figura 15) pode ser usada. Além disso, os VSMs podem ser desfocados diretamente por meio da convolução. Os VSMs têm algumas desvantagens; dois canais de dados de profundidade devem ser armazenados (profundidade e profundidade ao quadrado). Quando sombras se sobrepõem, sangramento leve é comum. Eles funcionam bem, no entanto, com resoluções mais baixas e podem ser combinados com CSMs.
Figura 15. Filtragem anisotrópica
 de filtragem anisotrópica
de filtragem anisotrópica
Detalhes do algoritmo
Os VSMs funcionam renderizando a profundidade e a profundidade ao quadrado em um mapa de sombra de dois canais. Esse mapa de sombra de dois canais pode ser desfocado e filtrado como uma textura normal. Em seguida, o algoritmo usa a Desigualdade de Chebychev no sombreador de pixels para estimar a fração da área de pixel que passaria no teste de profundidade.
O sombreador de pixel busca os valores de profundidade e profundidade ao quadrado.
float fAvgZ = mapDepth.x; // Filtered z
float fAvgZ2 = mapDepth.y; // Filtered z-squared
A comparação de profundidade é executada.
if ( fDepth <= fAvgZ )
{
fPercentLit = 1;
}
Se a comparação de profundidade falhar, a porcentagem do pixel que está aceso será estimada. A variação é calculada como média de quadrados menos quadrado de média.
float variance = ( fAvgZ2 ) − ( fAvgZ * fAvgZ );
variance = min( 1.0f, max( 0.0f, variance + 0.00001f ) );
O valor fPercentLit é estimado com a Desigualdade de Chebychev.
float mean = fAvgZ;
float d = fDepth - mean;
float fPercentLit = variance / ( variance + d*d );
Sangramento leve
A maior desvantagem dos VSMs é o sangramento leve (Figura 16). A hemorragia leve ocorre quando vários conversores de sombra ocluem uns aos outros ao longo das bordas. Os VSMs sombream as bordas das sombras com base nas disparidades de profundidade. Quando as sombras se sobrepõem, existe uma disparidade de profundidade no centro de uma região que deve ser sombreada. Esse é um problema com o uso do algoritmo VSM.
Figura 16. Sangramento de luz VSM
 de sangramento leve
de sangramento leve
Uma solução parcial para o problema é elevar o fPercentLit a uma potência. Isso tem o efeito de amortecer o desfoque, o que pode causar artefatos onde a disparidade de profundidade é pequena. Às vezes, existe um valor mágico que alivia o problema.
fPercentLit = pow( p_max, MAGIC_NUMBER );
Uma alternativa para elevar a porcentagem de luz para uma potência é evitar configurações em que as sombras se sobrepõem. Até mesmo as configurações de sombra altamente ajustadas têm várias restrições sobre luz, câmera e geometria. O sangramento leve também é diminuído usando texturas de resolução mais alta.
Mapas de sombra de variância em camadas (LVSMs) resolvem o problema em detrimento da quebra do frusto em camadas perpendiculares à luz. O número de mapas necessários seria bastante grande quando CSMs também estão sendo usados.
Além disso, Andrew Lauritzen, coautor do artigo sobre VSMs e autor de um artigo sobre LVSMs, discutiu a combinação de ESMs (mapas de sombra exponencial) com VSMs para combater a mistura de luz em um fórum Beyond3D.
VSMs com CSMs
O exemplo VarianceShadow11 combina VSMs e CSMs. A combinação é bastante simples. O exemplo segue as mesmas etapas que o exemplo CascadedShadowMaps11. Como o PCF não é usado, as sombras são desfocadas em uma convolução separável de duas passões. Não usar PCF também permite que o exemplo use matrizes de textura em vez de um atlas de textura. PCF em matrizes de textura é um recurso direct3D 10.1.
Gradientes com CSMs
O uso de gradientes com CSMs pode produzir uma costura ao longo da borda entre duas cascatas, como visto na Figura 17. A instrução de exemplo usa derivados entre pixels para calcular informações, como o nível de mipmap, necessário para o filtro. Isso causa um problema em particular para seleção de mipmap ou filtragem anisotrópica. Quando pixels em um quad tomam ramificações diferentes no sombreador, os derivados calculados pelo hardware de GPU são inválidos. Isso resulta em uma costura irregular ao longo do mapa de sombra.
Figura 17. Costuras em bordas em cascata devido à filtragem anisotrópica com controle de fluxo divergente

Esse problema é resolvido calculando os derivados na posição no espaço de exibição de luz; a coordenada de espaço de exibição de luz não é específica para a cascata selecionada. Os derivados computados podem ser dimensionados pela parte de escala da matriz projeção-textura para o nível de mipmap correto.
float3 vShadowTexCoordDDX = ddx( vShadowMapTextureCoordViewSpace );
vShadowTexCoordDDX *= m_vCascadeScale[iCascade].xyz;
float3 vShadowTexCoordDDY = ddy( vShadowMapTextureCoordViewSpace );
vShadowTexCoordDDY *= m_vCascadeScale[iCascade].xyz;
mapDepth += g_txShadow.SampleGrad( g_samShadow, vShadowTexCoord.xyz,
vShadowTexCoordDDX, vShadowTexCoordDDY );
VSMs comparados com sombras padrão com PCF
Os VSMs e o PCF tentam aproximar a fração da área de pixel que passaria no teste de profundidade. Os VSMs funcionam com hardware de filtragem e podem ser desfocados com kernels separados. Kernels de convolução separados são consideravelmente mais baratos de implementar do que um kernel completo. Além disso, os VSMs comparam uma profundidade de espaço leve com um valor no mapa de profundidade do espaço claro. Isso significa que os VSMs não têm os mesmos problemas de deslocamento que o PCF. Tecnicamente, os VSMs são uma profundidade de amostragem em uma área maior, além de executar uma análise estatística. Isso é menos preciso do que o PCF. Na prática, os VSMs fazem um trabalho muito bom de mesclagem, o que resulta em menos deslocamento sendo necessário. Conforme descrito acima, a desvantagem número um para VSMs é o sangramento leve.
VSMs e PCF representam uma compensação entre a potência de computação de GPU e a largura de banda de textura de GPU. Os VSMs exigem mais matemática para calcular a variação. O PCF requer mais largura de banda de memória de textura. Kernels pcf grandes podem rapidamente se tornar gargalos pela largura de banda de textura. Com o poder de computação de GPU crescendo mais rapidamente do que a largura de banda de GPU, os VSMs estão se tornando os mais práticos dos dois algoritmos. Os VSMs também ficam melhor com mapas de sombra de resolução inferior devido à mesclagem e filtragem.
Resumo
Os CSMs oferecem uma solução para o problema de aliasing de perspectiva. Há várias configurações possíveis para obter a fidelidade visual necessária para um título. PCF e VSMs são amplamente usados e devem ser combinados com CSMs para reduzir o aliasing.
Referências
Donnelly, W. e Lauritzen, A. mapas de sombra de variância. No SI3D '06: Proceedings of the 2006 symposium on Interactive 3D graphics and games. 2006. pp. 161–165. Nova York, NY, EUA: ACM Press.
Lauritzen, Andrew e McCool, Michael. mapas de sombra de variância em camadas. Proceedings of graphics interface 2008, May 28-30, 2008, Windsor, Ontario, Canada.
Engel, Woflgang F. Seção 4. Mapas de Sombra em Cascata. ShaderX5 , Técnicas avançadas de renderização, Wolfgang F. Engel, Ed. Charles River Media, Boston, Massachusetts. 2006. pp. 197–206.