Notă
Accesul la această pagină necesită autorizare. Puteți încerca să vă conectați sau să modificați directoarele.
Accesul la această pagină necesită autorizare. Puteți încerca să modificați directoarele.
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is the next generation of Azure Data Factory, with a simpler architecture, built-in AI, and new features. If you're new to data integration, start with Fabric Data Factory. Existing ADF workloads can upgrade to Fabric to access new capabilities across data science, real-time analytics, and reporting.
Follow this article when you want to parse the JSON files or write the data into JSON format.
JSON format is supported for the following connectors:
- Amazon S3
- Amazon S3 Compatible Storage,
- Azure Blob
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure Files
- File System
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
Dataset properties
For a full list of sections and properties available for defining datasets, see the Datasets article. This section provides a list of properties supported by the JSON dataset.
| Property | Description | Required |
|---|---|---|
| type | The type property of the dataset must be set to Json. | Yes |
| location | Location settings of the file(s). Each file-based connector has its own location type and supported properties under location. See details in connector article -> Dataset properties section. |
Yes |
| encodingName | The encoding type used to read/write test files. Allowed values are as follows: "UTF-8","UTF-8 without BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258". |
No |
| compression | Group of properties to configure file compression. Configure this section when you want to do compression/decompression during activity execution. | No |
| type (under compression) |
The compression codec used to read/write JSON files. Allowed values are bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy, or lz4. Default is not compressed. Note currently Copy activity doesn't support "snappy" & "lz4", and mapping data flow doesn't support "ZipDeflate"", "TarGzip" and "Tar". Note when using copy activity to decompress ZipDeflate/TarGzip/Tar file(s) and write to file-based sink data store, by default files are extracted to the folder: <path specified in dataset>/<folder named as source compressed file>/, use preserveZipFileNameAsFolder/preserveCompressionFileNameAsFolder on copy activity source to control whether to preserve the name of the compressed file(s) as folder structure. |
No. |
| level (under compression) |
The compression ratio. Allowed values are Optimal or Fastest. - Fastest: The compression operation should complete as quickly as possible, even if the resulting file is not optimally compressed. - Optimal: The compression operation should be optimally compressed, even if the operation takes a longer time to complete. For more information, see Compression Level topic. |
No |
Below is an example of JSON dataset on Azure Blob Storage:
{
"name": "JSONDataset",
"properties": {
"type": "Json",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compression": {
"type": "gzip"
}
}
}
}
Copy activity properties
For a full list of sections and properties available for defining activities, see the Pipelines article. This section provides a list of properties supported by the JSON source and sink.
Learn about how to extract data from JSON files and map to sink data store/format or vice versa from schema mapping.
JSON as source
The following properties are supported in the copy activity *source* section.
| Property | Description | Required |
|---|---|---|
| type | The type property of the copy activity source must be set to JSONSource. | Yes |
| formatSettings | A group of properties. Refer to JSON read settings table below. | No |
| storeSettings | A group of properties on how to read data from a data store. Each file-based connector has its own supported read settings under storeSettings. See details in connector article -> Copy activity properties section. |
No |
Supported JSON read settings under formatSettings:
| Property | Description | Required |
|---|---|---|
| type | The type of formatSettings must be set to JsonReadSettings. | Yes |
| compressionProperties | A group of properties on how to decompress data for a given compression codec. | No |
| preserveZipFileNameAsFolder (under compressionProperties->type as ZipDeflateReadSettings) |
Applies when input dataset is configured with ZipDeflate compression. Indicates whether to preserve the source zip file name as folder structure during copy. - When set to true (default), the service writes unzipped files to <path specified in dataset>/<folder named as source zip file>/.- When set to false, the service writes unzipped files directly to <path specified in dataset>. Make sure you don't have duplicated file names in different source zip files to avoid racing or unexpected behavior. |
No |
| preserveCompressionFileNameAsFolder (under compressionProperties->type as TarGZipReadSettings or TarReadSettings) |
Applies when input dataset is configured with TarGzip/Tar compression. Indicates whether to preserve the source compressed file name as folder structure during copy. - When set to true (default), the service writes decompressed files to <path specified in dataset>/<folder named as source compressed file>/. - When set to false, the service writes decompressed files directly to <path specified in dataset>. Make sure you don't have duplicated file names in different source files to avoid racing or unexpected behavior. |
No |
JSON as sink
The following properties are supported in the copy activity *sink* section.
| Property | Description | Required |
|---|---|---|
| type | The type property of the copy activity source must be set to JSONSink. | Yes |
| formatSettings | A group of properties. Refer to JSON write settings table below. | No |
| storeSettings | A group of properties on how to write data to a data store. Each file-based connector has its own supported write settings under storeSettings. See details in connector article -> Copy activity properties section. |
No |
Supported JSON write settings under formatSettings:
| Property | Description | Required |
|---|---|---|
| type | The type of formatSettings must be set to JsonWriteSettings. | Yes |
| filePattern | Indicate the pattern of data stored in each JSON file. Allowed values are: setOfObjects (JSON Lines) and arrayOfObjects. The default value is setOfObjects. See JSON file patterns section for details about these patterns. | No |
JSON file patterns
When copying data from JSON files, copy activity can automatically detect and parse the following patterns of JSON files. When writing data to JSON files, you can configure the file pattern on copy activity sink.
Type I: setOfObjects
Each file contains single object, JSON lines, or concatenated objects.
single object JSON example
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }JSON Lines (default for sink)
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}concatenated JSON example
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
Type II: arrayOfObjects
Each file contains an array of objects.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
Mapping data flow properties
In mapping data flows, you can read and write to JSON format in the following data stores: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 and SFTP, and you can read JSON format in Amazon S3.
Source properties
The below table lists the properties supported by a json source. You can edit these properties in the Source options tab.
| Name | Description | Required | Allowed values | Data flow script property |
|---|---|---|---|---|
| Wild card paths | All files matching the wildcard path will be processed. Overrides the folder and file path set in the dataset. | no | String[] | wildcardPaths |
| Partition root path | For file data that is partitioned, you can enter a partition root path in order to read partitioned folders as columns | no | String | partitionRootPath |
| List of files | Whether your source is pointing to a text file that lists files to process | no | true or false |
fileList |
| Column to store file name | Create a new column with the source file name and path | no | String | rowUrlColumn |
| After completion | Delete or move the files after processing. File path starts from the container root | no | Delete: true or false Move: ['<from>', '<to>'] |
purgeFiles moveFiles |
| Filter by last modified | Choose to filter files based upon when they were last altered | no | Timestamp | modifiedAfter modifiedBefore |
| Single document | Mapping data flows read one JSON document from each file | no | true or false |
singleDocument |
| Unquoted column names | If Unquoted column names is selected, mapping data flows reads JSON columns that aren't surrounded by quotes. | no | true or false |
unquotedColumnNames |
| Has comments | Select Has comments if the JSON data has C or C++ style commenting | no | true or false |
asComments |
| Single quoted | Reads JSON columns that aren't surrounded by quotes | no | true or false |
singleQuoted |
| Backslash escaped | Select Backslash escaped if backslashes are used to escape characters in the JSON data | no | true or false |
backslashEscape |
| Allow no files found | If true, an error is not thrown if no files are found | no | true or false |
ignoreNoFilesFound |
Inline dataset
Mapping data flows supports "inline datasets" as an option for defining your source and sink. An inline JSON dataset is defined directly inside your source and sink transformations and is not shared outside of the defined dataflow. It is useful for parameterizing dataset properties directly inside your data flow and can benefit from improved performance over shared ADF datasets.
When you are reading large numbers of source folders and files, you can improve the performance of data flow file discovery by setting the option "User projected schema" inside the Projection | Schema options dialog. This option turns off ADF's default schema auto-discovery and will greatly improve the performance of file discovery. Before setting this option, make sure to import the JSON projection so that ADF has an existing schema for projection. This option does not work with schema drift.
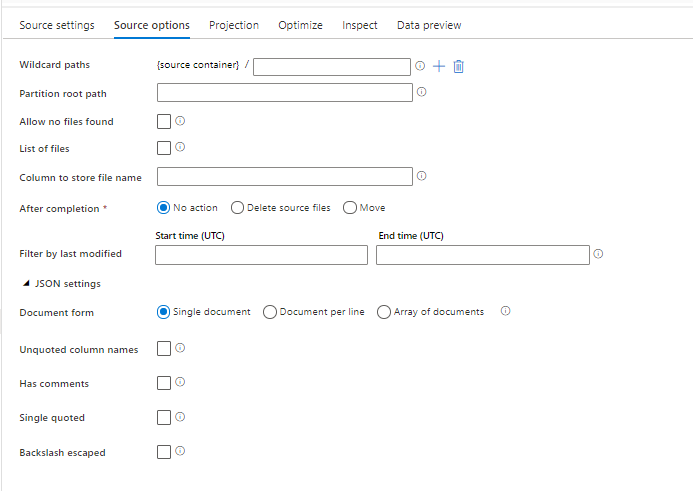
Source format options
Using a JSON dataset as a source in your data flow allows you to set five additional settings. These settings can be found under the JSON settings accordion in the Source Options tab. For Document Form setting, you can select one of Single document, Document per line and Array of documents types.
Default
By default, JSON data is read in the following format.
{ "json": "record 1" }
{ "json": "record 2" }
{ "json": "record 3" }
Single document
If Single document is selected, mapping data flows read one JSON document from each file.
File1.json
{
"json": "record 1"
}
File2.json
{
"json": "record 2"
}
File3.json
{
"json": "record 3"
}
If Document per line is selected, mapping data flows read one JSON document from each line in a file.
File1.json
{"json": "record 1"}
File2.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
File3.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
{"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}
If Array of documents is selected, mapping data flows read one array of document from a file.
File.json
[
{
"time": "2015-04-29T07:12:20.9100000Z",
"callingimsi": "466920403025604",
"callingnum1": "678948008",
"callingnum2": "567834760",
"switch1": "China",
"switch2": "Germany"
},
{
"time": "2015-04-29T07:13:21.0220000Z",
"callingimsi": "466922202613463",
"callingnum1": "123436380",
"callingnum2": "789037573",
"switch1": "US",
"switch2": "UK"
},
{
"time": "2015-04-29T07:13:21.4370000Z",
"callingimsi": "466923101048691",
"callingnum1": "678901578",
"callingnum2": "345626404",
"switch1": "Germany",
"switch2": "UK"
}
]
Note
If data flows throw an error stating "corrupt_record" when previewing your JSON data, it is likely that your data contains a single document in your JSON file. Setting "single document" should clear that error.
Unquoted column names
If Unquoted column names is selected, mapping data flows reads JSON columns that aren't surrounded by quotes.
{ json: "record 1" }
{ json: "record 2" }
{ json: "record 3" }
Has comments
Select Has comments if the JSON data has C or C++ style commenting.
{ "json": /** comment **/ "record 1" }
{ "json": "record 2" }
{ /** comment **/ "json": "record 3" }
Single quoted
Select Single quoted if the JSON fields and values use single quotes instead of double quotes.
{ 'json': 'record 1' }
{ 'json': 'record 2' }
{ 'json': 'record 3' }
Backslash escaped
Select Backslash escaped if backslashes are used to escape characters in the JSON data.
{ "json": "record 1" }
{ "json": "\} \" \' \\ \n \\n record 2" }
{ "json": "record 3" }
Sink Properties
The below table lists the properties supported by a json sink. You can edit these properties in the Settings tab.
| Name | Description | Required | Allowed values | Data flow script property |
|---|---|---|---|---|
| Clear the folder | If the destination folder is cleared prior to write | no | true or false |
truncate |
| File name option | The naming format of the data written. By default, one file per partition in format part-#####-tid-<guid> |
no | Pattern: String Per partition: String[] As data in column: String Output to single file: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Creating JSON structures in a derived column
You can add a complex column to your data flow via the derived column expression builder. In the derived column transformation, add a new column and open the expression builder by clicking on the blue box. To make a column complex, you can enter the JSON structure manually or use the UX to add subcolumns interactively.
Using the expression builder UX
In the output schema side pane, hover over a column and click the plus icon. Select Add subcolumn to make the column a complex type.
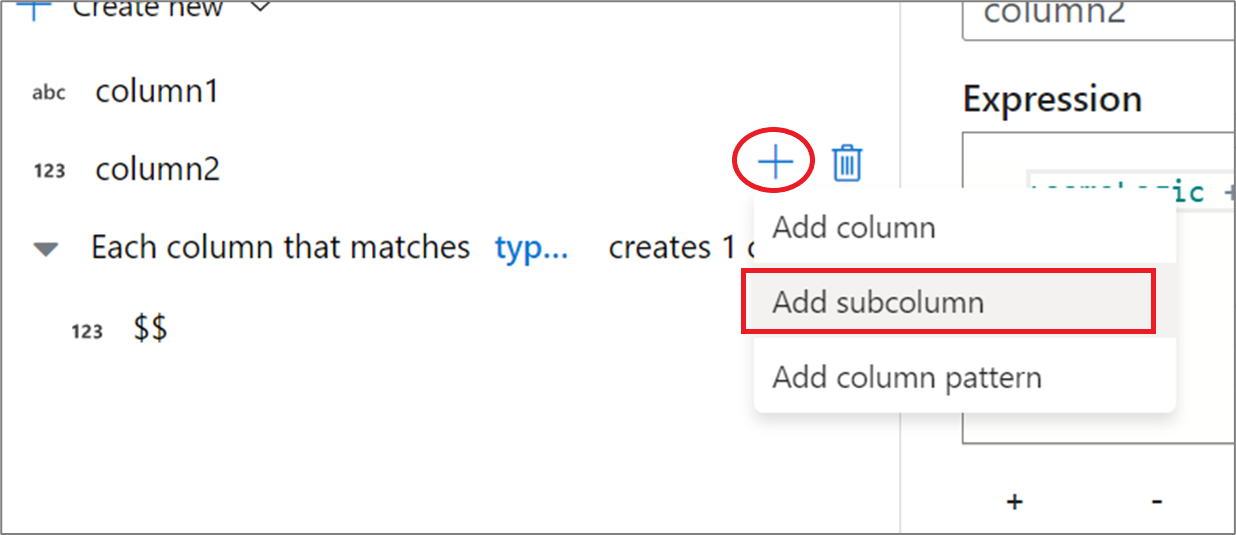
You can add additional columns and subcolumns in the same way. For each non-complex field, an expression can be added in the expression editor to the right.
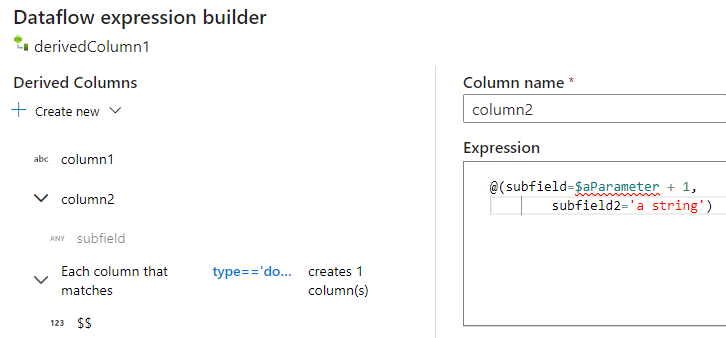
Entering the JSON structure manually
To manually add a JSON structure, add a new column and enter the expression in the editor. The expression follows the following general format:
@(
field1=0,
field2=@(
field1=0
)
)
If this expression were entered for a column named "complexColumn", then it would be written to the sink as the following JSON:
{
"complexColumn": {
"field1": 0,
"field2": {
"field1": 0
}
}
}
Sample manual script for complete hierarchical definition
@(
title=Title,
firstName=FirstName,
middleName=MiddleName,
lastName=LastName,
suffix=Suffix,
contactDetails=@(
email=EmailAddress,
phone=Phone
),
address=@(
line1=AddressLine1,
line2=AddressLine2,
city=City,
state=StateProvince,
country=CountryRegion,
postCode=PostalCode
),
ids=[
toString(CustomerID), toString(AddressID), rowguid
]
)
Related connectors and formats
Here are some common connectors and formats related to the JSON format: