Folosește API-ul de Voce în Text
Azure Speech în Foundry Tools suportă recunoașterea vocală prin API-ul Speech to text*. Deși detaliile specifice variază, în funcție de SDK-ul utilizat (Python, C#, etc.); există un model consistent pentru utilizarea API-ului Vorbire în text :
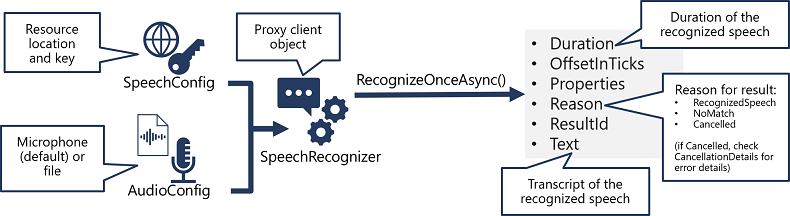
- Folosește un obiect SpeechConfig pentru a încapsula informațiile necesare pentru a te conecta la resursa ta Foundry. Mai exact, punctul său final (sau regiune) și cheia.
- Opțional, utilizați o AudioConfig pentru a defini sursa de intrare pentru componenta audio de transcris. În mod implicit, acesta este microfonul de sistem implicit, dar puteți specifica și un fișier audio.
- Utilizați SpeechConfig și AudioConfig pentru a crea un obiect SpeechRecognizer . Acest obiect este un client proxy pentru API-ul vorbire în text .
- Utilizați metodele obiectului SpeechRecognizer pentru a apela funcțiile API subiacente. De exemplu, metoda RecognizeOnceAsync() folosește serviciul Azure Speech pentru a transcrie asincron o singură expresie rostită.
- Procesează răspunsul. În cazul metodei RecognizeOnceAsync(), rezultatul este un obiect SpeechRecognitionResult care include următoarele proprietăți:
- Durată
- OffsetInTicks
- Proprietăți
- Motiv
- ResultId
- SMS
Dacă operațiunea a reușit, proprietatea Reason are valoarea enumerată RecunoscuteSpeech, iar proprietatea Text conține transcrierea. Alte valori posibile pentru Rezultat includ NoMatch (care indică faptul că fișierul audio a fost analizat cu succes, dar nu s-a recunoscut vorbirea) sau Anulat, indicând faptul că s-a produs o eroare (caz în care, puteți verifica colecția Properties pentru proprietatea CancelReason pentru a determina ce nu a funcționat corect).
Exemplu - Transcrierea unui fișier audio
Următorul exemplu Python folosește Azure Speech în Foundry Tools pentru a transcrie vorbirea într-un fișier audio.
import azure.cognitiveservices.speech as speech_sdk
# Speech config encapsulates the connection to the resource
speech_config = speech_sdk.SpeechConfig(subscription="YOUR_FOUNDRY_KEY",
endpoint="YOUR_FOUNDRY_ENDPOINT")
# Audio config determines the audio stream source (defaults to system mic)
file_path = "audio.wav"
audio_config = speech_sdk.audio.AudioConfig(filename=file_path)
# Use a speech recognizer to transcribe the audio
speech_recognizer = speech_sdk.SpeechRecognizer(speech_config=speech_config,
audio_config=audio_config)
result = speech_recognizer.recognize_once_async().get()
# Did it succeeed
if result.reason == speech_sdk.ResultReason.RecognizedSpeech:
# Yes!
print(f"Transcription:\n{result.text}")
else:
# No. Try to determine why.
print("Error transcribing message: {}".format(result.reason))