Descrieți normalizarea
Normalizarea bazei de date este un proces de proiectare utilizat pentru a organiza datele în tabele și coloane dintr-o bază de date. Fiecare tabel trebuie să conțină date legate de o anumită entitate și să includă doar informații care acceptă acea entitate. Scopul principal al normalizării este de a minimiza datele dublate din baza de date, ceea ce ajută la prevenirea degradării performanței în timpul inserărilor și actualizărilor. De exemplu, dacă adresa unui client trebuie actualizată, este mai simplu să implementați modificarea dacă adresa este stocată într-o singură locație, cum Customers ar fi tabelul.
Cele mai comune forme de normalizare sunt primele, al doilea și al treilea forme normale.
Prima formă normală
Prima formă normală are următoarele specificații:
- Crearea unui tabel separat pentru fiecare set de date asociate
- Eliminarea grupurilor repetiție din tabele individuale
- Identificați fiecare set de date asociate cu o cheie primară
În acest model, ar trebui să evitați utilizarea mai multor coloane într-un singur tabel pentru a stoca date similare. De exemplu, dacă un produs poate avea mai multe culori, nu ar trebui să aveți mai multe coloane într-un singur rând care conține diferitele valori de culoare. Primul tabel următor, ProductColors, nu este în prima formă normală, deoarece are valori care se repetă pentru culoare. Pentru produsele cu o singură culoare, există spațiu pierdut. În plus, dacă un produs are mai mult de trei culori, acesta devine impractical pentru a seta un număr maxim de coloane. În schimb, putem crea din nou tabelul așa cum se arată în al doilea tabel, ProductColor.
Prima formă normală necesită, de asemenea, să existe o cheie unică pentru tabel, care este o coloană (sau coloane) a cărei valoare identifică în mod unic fiecare rând. În al doilea tabel, niciunul dintre coloane nu este unic pe cont propriu, dar împreună, combinația de IDProdus și Color formează o cheie unică. Atunci când sunt necesare mai multe coloane pentru a crea o cheie unică, aceasta este denumită cheie compusă.
ProductColorsmasă:#B0 PRODUCTID #C1 #B0 Culoare1 #C1 #B0 Culoare2 #C1 #B0 Culoare3 #C1 1 Roșu Verde Galben 2 Galben 3 Albastru Roșu 4 Albastru 5 Roșu ProductColormasă:#B0 PRODUCTID #C1 Culoare 1 Roșu 1 Verde 1 Galben 2 Galben 3 Albastru 3 Roșu 4 Albastru 5 Roșu
Al treilea tabel, ProductInfo, este în prima formă normală, deoarece fiecare rând se referă la un anumit produs, nu există grupuri repetitiv și avem coloana IDProdus de utilizat ca cheie primară.
| #B0 PRODUCTID #C1 | #B0 ProductName #C1 | Preţ | #B0 ProductionCountry #C1 | #B0 shortLocation #C1 |
|---|---|---|---|---|
| 1 | Widget | 15.95 | Statele Unite ale Americii | NE |
| 2 | Foop | 41.95 | Regatul Unit | Regatul Unit |
| 3 | Glombit | 49.95 | Regatul Unit | Regatul Unit |
| 4 | Sorfin | 99.99 | Republica Filipine | RepPhil |
| 5 | Buloane stem | 29.95 | Statele Unite ale Americii | NE |
A doua formă normală
A doua formă normală are următoarea specificație, pe lângă cele cerute de prima formă normală:
- Dacă tabelul are o cheie compusă, toate atributele trebuie să depindă de cheia completă și nu doar de o parte a acestuia.
A doua formă normală este relevantă doar pentru tabelele cu chei compuse, cum ar fi în tabelul ProductColor, care este al doilea tabel. Luați în considerare cazul în ProductColor care tabelul include, de asemenea, prețul produsului. Acest tabel are o cheie compusă activată ProductID și Color, deoarece doar utilizând ambele valori de coloană putem identifica în mod unic un rând. Dacă prețul unui produs nu se modifică cu culoarea, este posibil să vedem datele așa cum se arată în acest tabel.
| #B0 PRODUCTID #C1 | Culoare | Preţ |
|---|---|---|
| 1 | Roșu | 15.95 |
| 1 | Verde | 15.95 |
| 1 | Galben | 15.95 |
| 2 | Galben | 41.95 |
| 3 | Albastru | 49.95 |
| 3 | Roșu | 49.95 |
| 4 | Albastru | 99.95 |
| 5 | Roșu | 29.95 |
Acest tabel nu este în a doua formă normală. Valoarea prețului este dependentă de , ProductID dar nu și de Color. Există trei rânduri pentru ProductID 1, astfel încât prețul produsului respectiv se repetă de trei ori. Problema cu încălcarea celei de-a doua forme normale este că, dacă trebuie să actualizăm prețul, trebuie să ne asigurăm că este actualizat peste tot. Dacă actualizăm prețul pe primul rând, dar nu și în al doilea sau al treilea, vom întâlni o anomalie de actualizare. După actualizare, nu am putea determina prețul real pentru ProductID 1. Soluția este să mutați Price coloana într-un tabel care are ProductID o singură cheie de coloană, deoarece aceasta este singura coloană care Price depinde de. De exemplu, am putea utiliza Tabelul 3 pentru a stoca Price.
Dacă prețul unui produs a fost diferit pe baza culorii sale, al patrulea tabel ar fi în a doua formă normală, deoarece prețul ar depinde de ambele părți ale cheii: și ProductID de Color.
A treia formă normală
A treia formă normală este de obicei scopul pentru majoritatea bazelor de date OLTP. A treia formă normală are următoarea specificație, în plus față de cele cerute de a doua formă normală:
- Toate coloanele non-cheie sunt dependente în mod netransitiv de cheia primară.
O relație tranzitivă implică faptul că o coloană dintr-un tabel este rudă cu alte coloane printr-o a doua coloană. Dependența înseamnă că o coloană își poate deriva valoarea din alta ca rezultat al acestei relații. De exemplu, vârsta dvs. poate fi determinată de la data nașterii, ceea ce face ca vârsta să depindă de data nașterii. Reveniți la al treilea tabel, ProductInfo. Acest tabel este în a doua formă normală, dar nu și în a treia. Coloana ShortLocation este dependentă de ProductionCountry coloană, care nu este cheia. La fel ca în cazul celei de-a doua forme normale, încălcarea celei de-a treia forme normale poate duce la actualizarea anomaliilor. Am ajunge cu date inconsistente dacă am actualizat într-un ShortLocation singur rând, dar nu le-am actualiza în toate rândurile unde s-a produs locația respectivă. Pentru a preveni acest lucru, am putea crea un tabel separat pentru a stoca numele țărilor/regiunilor și formularele lor scurtate.
Denormalizare
Deși a treia formă normală este dorită teoretic, nu este întotdeauna posibilă pentru toate datele. În plus, o bază de date normalizată nu vă oferă întotdeauna cea mai bună performanță. Datele normalizate necesită frecvent mai multe operațiuni de asociere pentru a obține toate datele necesare returnate într-o singură interogare. Există un compromis între normalizarea datelor atunci când numărul de asocieri necesare pentru a returna rezultatele interogării are o utilizare intensă a procesorului și date denormalizate care au mai puține asocieri și mai puțin CPU necesare, dar deschide posibilitatea de a actualiza anomalii.
Datele denormalizate pot fi mai eficiente pentru interogare, mai ales pentru a citi sarcini de lucru grele, cum ar fi un depozit de date. În aceste cazuri, existența de coloane suplimentare poate oferi modele de interogare mai bune și/sau mai simplestice.
Schemă stea
Deși majoritatea normalizării vizează sarcinile de lucru OLTP, depozitele de date au propria structură de modelare, care este de obicei un model denormalizat . Această proiectare utilizează tabele de fapt pentru a înregistra măsurători sau măsurători pentru anumite evenimente, cum ar fi vânzările, și le asociază la tabelele de dimensiune. Tabelele de dimensiune sunt mai mici în ceea ce privește numărul de rânduri, dar pot avea un număr mare de coloane pentru a descrie datele de fapt. Printre exemple de dimensiuni se numără inventarul, ora și geografia. Acest model de proiectare face baza de date mai ușor de interogat și oferă câștiguri de performanță pentru sarcinile de lucru citite.
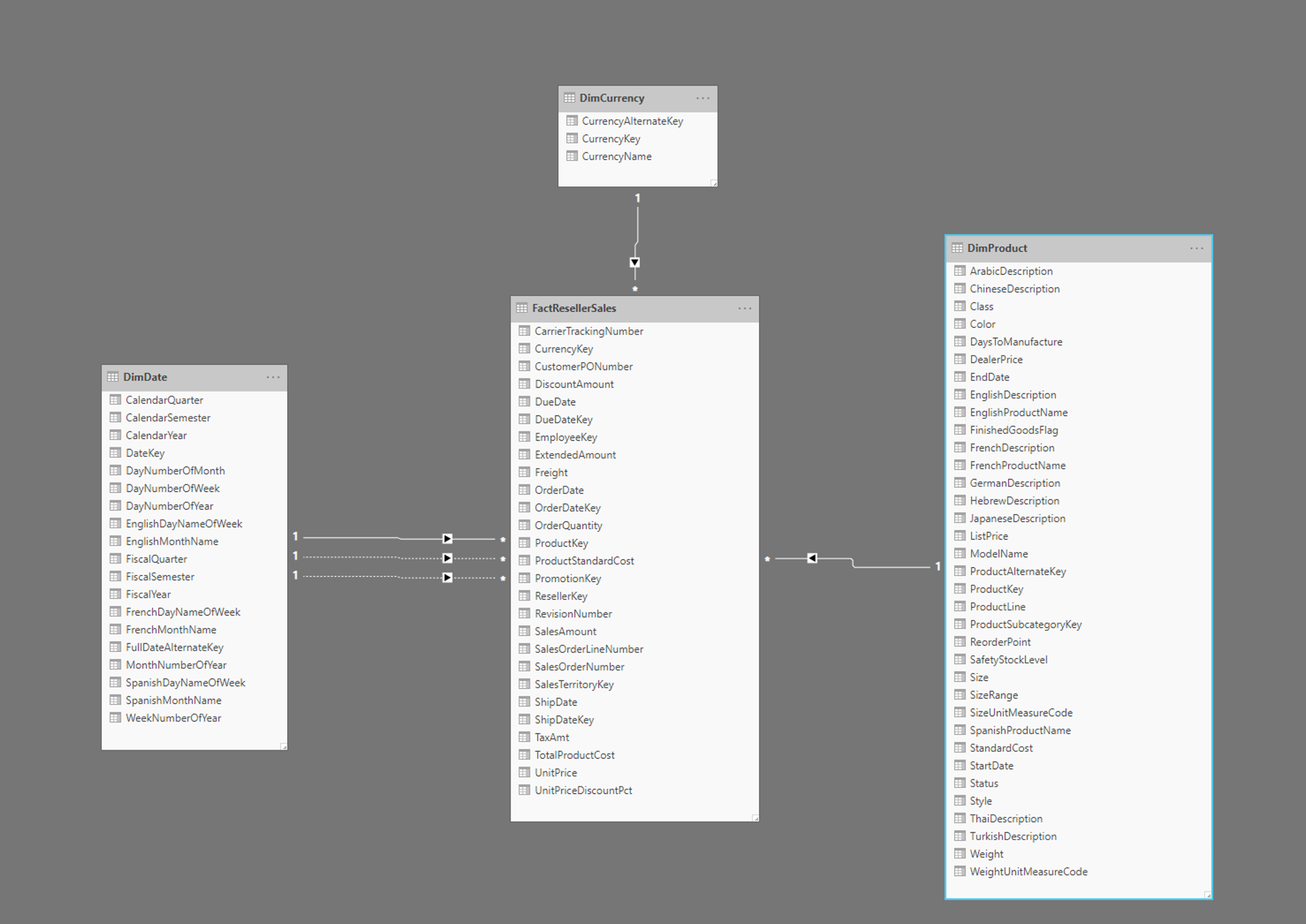
Imaginea ilustrează un exemplu de schemă de stele, cu un FactResellerSales tabel de fapt și dimensiuni pentru dată, monedă și produse. Tabelul informativ conține date legate de tranzacțiile de vânzări, în timp ce dimensiunile conțin doar date legate de anumite elemente ale datelor de vânzări. De exemplu, FactResellerSales tabelul include doar un ProductKey pentru a indica ce produs a fost vândut. Toate detaliile despre fiecare produs sunt stocate în DimProduct tabel și sunt asociate cu tabelul fapt utilizând ProductKey coloana.
Corelat cu proiectarea schemei stea este schema fulgi de zăpadă, care utilizează un set de tabele mai normalizate pentru o singură entitate de afaceri. Următoarea imagine ilustrează un exemplu de dimensiune unică într-o schemă de fulgi de zăpadă. Dimensiunea Produse este normalizată și stocată în trei tabele: DimProductCategory, DimProductSubcategoryși DimProduct.
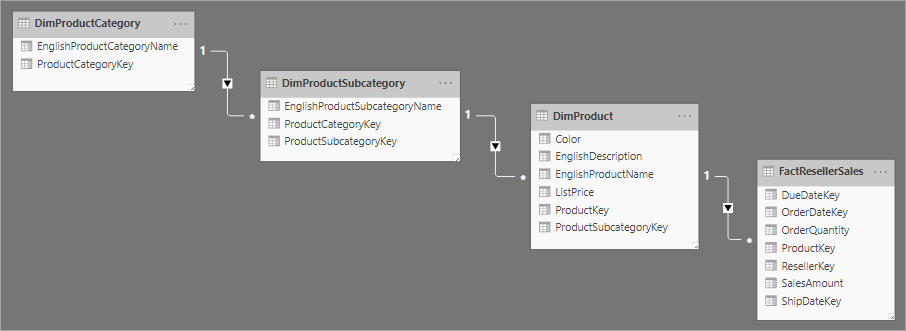
Principala diferență dintre schemele stea și fulgi de zăpadă este că dimensiunile dintr-o schemă de fulg de zăpadă sunt normalizate pentru a reduce redundanța, ceea ce economisește spațiu de stocare. Compromisul este că interogările necesită mai multe asocieri, ceea ce poate crește complexitatea și poate scădea performanța.