Modele lingvistice semantice
Notă
Consultați fila Text și imagini pentru mai multe detalii!
Pe măsură ce arta pentru NLP este avansată, capacitatea de a antrena modele care încapsulează relația semantică dintre simboluri a condus la apariția unor modele puternice de limbaj de învățare profundă. În inima acestor modele se află codificarea simbolurilor lingvistice ca vectori (matrice multi-valoare de numere) cunoscute ca încorporări.
Această abordare bazată pe vectori pentru modelarea textului a devenit comună cu tehnici precum Word2Vec și GloVe, în care tokenurile de text sunt reprezentate ca vectori denși cu multiple dimensiuni. În timpul antrenamentului modelului, valorile dimensiunilor sunt atribuite pentru a reflecta caracteristicile semantice ale fiecărui token în funcție de utilizarea lor în textul de antrenament. Relațiile matematice dintre vectori pot fi apoi exploatate pentru a efectua sarcini comune de analiză a textului mai eficient decât tehnicile pur statistice mai vechi. Un progres mai recent în această abordare este utilizarea unei tehnici numite atenție pentru a considera fiecare token în context și a calcula influența tokenurilor din jurul său. Încorporațiile contextualizate rezultate, precum cele găsite în familia de modele GPT, oferă baza inteligenței artificiale generative moderne.
Reprezentarea textului ca vectori
Vectorii reprezintă puncte în spațiul multidimensional, definite prin coordonate de-a lungul mai multor axe. Fiecare vector descrie o direcție și o distanță față de origine. Jetoane semantic similare ar trebui să ducă la vectori care au o orientare similară – cu alte cuvinte, aceștia indică în direcții similare.
De exemplu, să considerăm următoarele încorporații tridimensionale pentru câteva cuvinte comune:
| Word | Vector |
|---|---|
dog |
[0.8, 0.6, 0.1] |
puppy |
[0.9, 0.7, 0.4] |
cat |
[0.7, 0.5, 0.2] |
kitten |
[0.8, 0.6, 0.5] |
young |
[0.1, 0.1, 0.3] |
ball |
[0.3, 0.9, 0.1] |
tree |
[0.2, 0.1, 0.9] |
Putem vizualiza acești vectori în spațiu tridimensional, așa cum se arată aici:

Vectorii pentru "dog" și "cat" sunt similari (ambele animale domestice), la fel ca și "kitten" sunt "puppy" și (ambele animale tinere). Cuvintele "tree", "young", și ball" au orientări vectoriale distinct diferite, reflectând sensurile lor semantice diferite.
Caracteristica semantică codificată în vectori face posibilă utilizarea unor operații bazate pe vectori care compară cuvintele și permite comparații analitice.
Găsirea termenilor înrudiți
Deoarece orientarea vectorilor este determinată de valorile lor de dimensiune, cuvintele cu sensuri semantice similare tind să aibă orientări similare. Aceasta înseamnă că poți folosi calcule precum similaritatea cosinus dintre vectori pentru a face comparații semnificative.
De exemplu, pentru a determina "odd out" între "dog", "cat", și "tree", poți calcula similaritatea cosinus între perechi de vectori. Similaritatea cosinus se calculează astfel:
cosine_similarity(A, B) = (A · B) / (||A|| * ||B||)
Unde A · B este produsul scalar și ||A|| este magnitudinea vectorului A.
Calcularea asemănărilor între cele trei cuvinte:
dog[0.8, 0.6, 0.1] șicat[0.7, 0.5, 0.2]:- Produsul scalar: (0,8 × 0,7) + (0,6 × 0,5) + (0,1 × 0,2) = 0,56 + 0,30 + 0,02 = 0,88
- Magnitudinea :
dog√(0,8² + 0,6² + 0,1²) = √(0,64 + 0,36 + 0,01) = √1,01 ≈ 1,005 - Magnitudinea :
cat√(0,7² + 0,5² + 0,2²) = √(0,49 + 0,25 + 0,04) = √0,78 ≈ 0,883 - Similaritate cosinus: 0,88 / (1,005 × 0,883) ≈ 0,992 (similaritate ridicată)
dog[0.8, 0.6, 0.1] șitree[0.2, 0.1, 0.9]:- Produs scalar: (0,8 × 0,2) + (0,6 × 0,1) + (0,1 × 0,9) = 0,16 + 0,06 + 0,09 = 0,31
- Magnitudinea :
tree√(0,2² + 0,1² + 0,9²) = √(0,04 + 0,01 + 0,81) = √0,86 ≈ 0,927 - Similaritate cosinus: 0,31 / (1,005 × 0,927) ≈ 0,333 (similaritate scăzută)
cat[0.7, 0.5, 0.2] șitree[0.2, 0.1, 0.9]:- Produsul scalar: (0,7 × 0,2) + (0,5 × 0,1) + (0,2 × 0,9) = 0,14 + 0,05 + 0,18 = 0,37
- Similaritate cosinus: 0,37 / (0,883 × 0,927) ≈ 0,452 (similaritate scăzută)
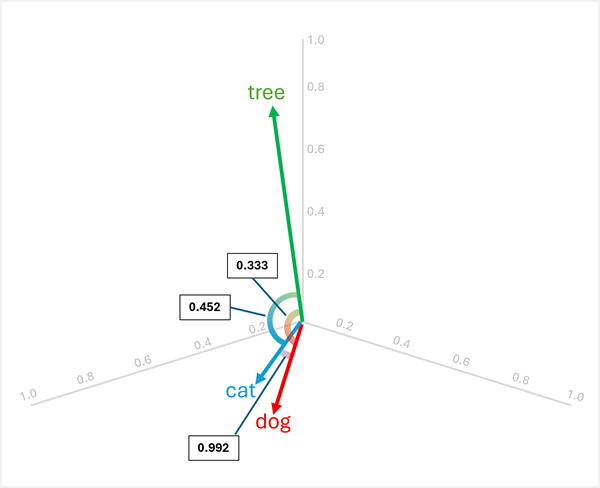
Rezultatele arată că "dog" și "cat" sunt foarte asemănătoare (0,992), în timp ce "tree" are o similaritate mai mică cu ambele "dog" (0,333) și "cat" (0,452). Prin urmare, tree este clar cel diferit.
Translație vectorială prin adunare și scădere
Poți adăuga sau scădea vectori pentru a produce rezultate noi bazate pe vectori; care pot fi apoi folosite pentru a găsi jetoane cu vectori potriviți. Această tehnică permite logicii intuitive bazate pe aritmetică pentru a determina termenii potriviți pe baza relațiilor lingvistice.
De exemplu, folosind vectorii de mai devreme:
-
dog+young= [0.8, 0.6, 0.1] + [0.1, 0.1, 0.3] = [0.9, 0.7, 0.4] =puppy -
cat+young= [0.7, 0.5, 0.2] + [0.1, 0.1, 0.3] = [0.8, 0.6, 0.5] =kitten
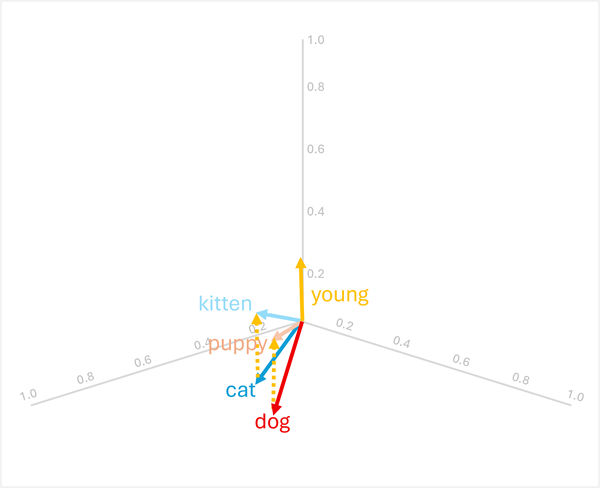
Aceste operații funcționează deoarece vectorul codifică "young" transformarea semantică de la un animal adult la omologul său tânăr.
Notă
În practică, aritmetica vectorială rareori produce potriviri exacte; în schimb, ai căuta cuvântul al cărui vector este cel mai apropiat (cel mai asemănător) de rezultat.
Aritmetica funcționează și invers:
-
puppy-young= [0.9, 0.7, 0.4] - [0.1, 0.1, 0.3] = [0.8, 0.6, 0.1] =dog -
kitten-young= [0.8, 0.6, 0.5] - [0.1, 0.1, 0.3] = [0.7, 0.5, 0.2] =cat
Raționamentul analogic
Aritmetica vectorială poate răspunde și la întrebări analogice precum "puppy este la dog așa kitten cum este la ?"
Pentru a rezolva acest lucru, calculați: kitten - puppy + dog
- [0.8, 0.6, 0.5] - [0.9, 0.7, 0.4] + [0.8, 0.6, 0.1]
- = [-0.1, -0.1, 0.1] + [0.8, 0.6, 0.1]
- = [0.7, 0.5, 0.2]
- =
cat
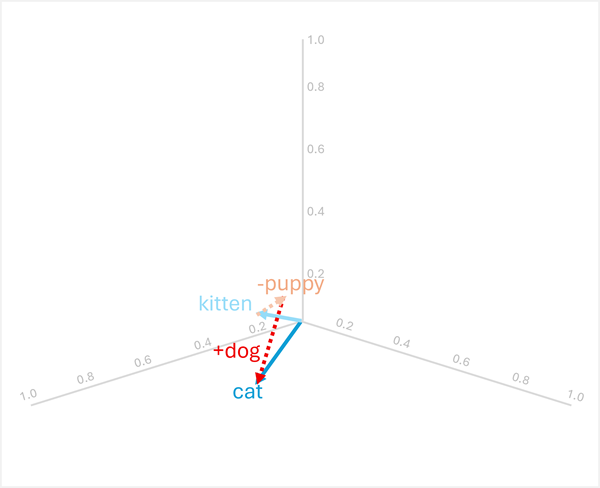
Aceste exemple demonstrează cum operațiile vectoriale pot surprinde relații lingvistice și pot permite raționamentul despre tipare semantice.
Utilizarea modelelor semantice pentru analiza textului
Modelele semantice bazate pe vectori oferă capabilități puternice pentru multe sarcini comune de analiză a textului.
Rezumatul textului
Încorporațiile semantice permit rezumatul extractiv prin identificarea propozițiilor cu vectori care sunt cel mai reprezentativ pentru întregul document. Prin codificarea fiecărei propoziții ca un vector (adesea prin media sau gruparea încorporațiilor cuvintelor componente), poți calcula care propoziții sunt cele mai centrale pentru sensul documentului. Aceste propoziții centrale pot fi extrase pentru a forma un rezumat care surprinde temele cheie.
Extragerea cuvintelor cheie
Similaritatea vectorială poate identifica cei mai importanți termeni dintr-un document comparând încorporarea fiecărui cuvânt cu reprezentarea semantică generală a documentului. Cuvintele ale căror vectori sunt cel mai asemănători cu vectorul documentului sau cei mai centrali dacă se iau în considerare toți vectorii de cuvinte din document, sunt probabil termeni-cheie care reprezintă subiectele principale.
Recunoașterea entității denumite
Modelele semantice pot fi ajustate fin pentru a recunoaște entități denumite (persoane, organizații, locații etc.) prin învățarea reprezentărilor vectoriale care grupează tipuri de entități similare. În timpul inferenței, modelul examinează încorporarea fiecărui token și contextul său pentru a determina dacă reprezintă o entitate denumită și, dacă da, ce tip.
Clasificarea textului
Pentru sarcini precum analiza sentimentului sau categorisirea subiectelor, documentele pot fi reprezentate ca vectori agregați (cum ar fi media tuturor încorporilor de cuvinte din document). Acești vectori de documente pot fi apoi folosiți ca caracteristici pentru clasificatoare de învățare automată sau comparați direct cu vectorii prototip de clasă pentru a atribui categorii. Deoarece documentele semantic similare au orientări vectoriale similare, această abordare grupează efectiv conținutul înrudit și distinge categorii diferite.