Explorați arhitectura soluției
Să revizuim arhitectura operațiunilor de învățare programată (MLOps) pentru a înțelege scopul a ceea ce încercăm să obținem.
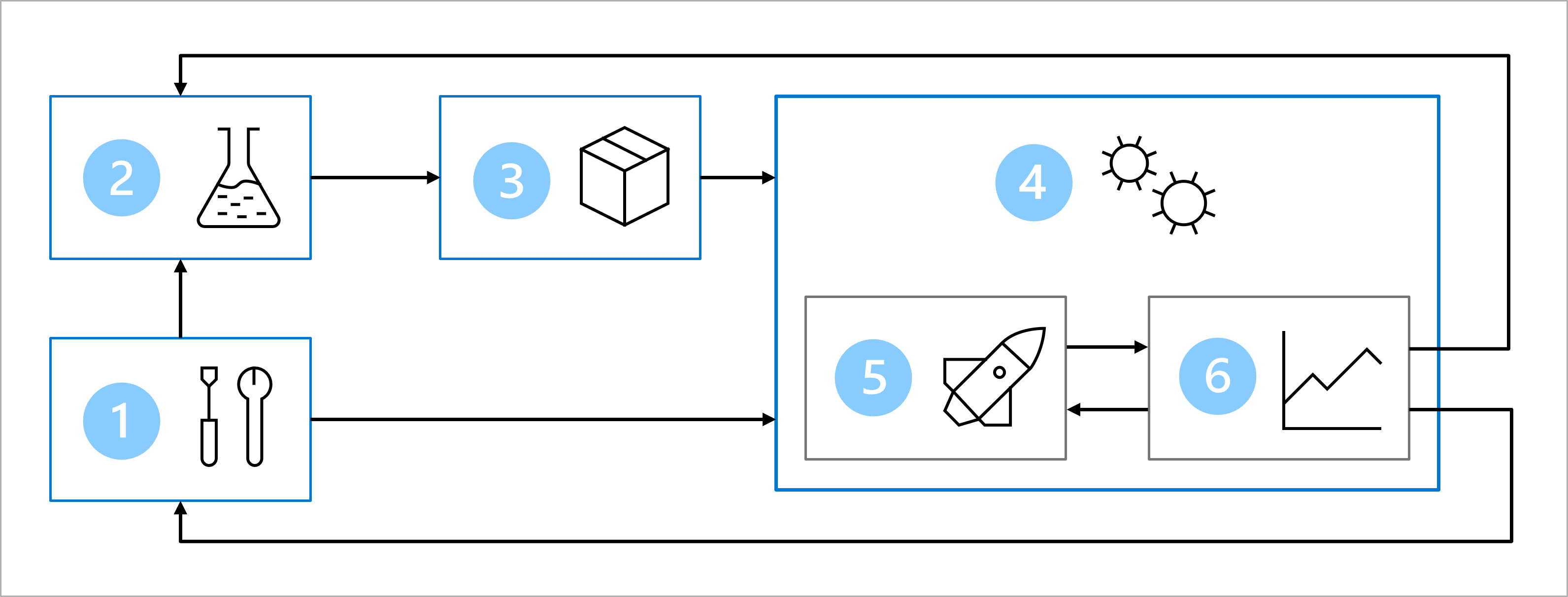
Imaginați-vă că, împreună cu echipa de dezvoltare a datelor și de dezvoltare software, ați convenit asupra următoarei arhitecturi pentru a instrui, testa și implementa modelul de clasificare a diabetului zaharat:
Notă
Diagrama este o reprezentare simplificată a unei arhitecturi MLOps. Pentru a vedea o arhitectură mai detaliată, explorați diferitele cazuri de utilizare din acceleratorul de soluții mlOps (v2).
Arhitectura include:
- configurare: creați toate resursele Azure necesare pentru soluție.
- Dezvoltarea modelelor (bucla interioară): explorați și procesați datele pentru a instrui și evalua modelul.
- Integrare continuă: Împachetarea și înregistrarea modelului.
- implementare model (buclă exterioară): Implementați modelul.
- implementare continuă: testați modelul și promovați-l în mediul de producție.
- monitorizarea: monitorizarea performanței modelului și punctului final.
Echipa de știință a datelor este responsabilă pentru dezvoltarea modelului. Echipa de dezvoltare software este responsabilă pentru integrarea modelului implementat cu aplicația web utilizată de practicieni pentru a evalua dacă un pacient are diabet zaharat. Sunteți responsabil să luați modelul de la dezvoltarea modelului la implementarea modelului.
Vă așteptați ca echipa de știință a datelor să propună în mod constant modificări la scripturile utilizate pentru a instrui modelul. Ori de câte ori există o modificare a scriptului de instruire, trebuie să reintroduceți modelul și să reimlocați modelul la punctul final existent.
Doriți să permiteți echipei de știință a datelor să experimenteze, fără a atinge codul gata de producție. De asemenea, doriți să vă asigurați că orice cod nou sau actualizat trece automat prin verificările de calitate convenite. După ce verificați codul pentru a instrui modelul, veți utiliza scriptul de instruire actualizat pentru a instrui un model nou și a-l implementa.
Pentru a urmări modificările și a verifica codul înainte de a actualiza codul de producție, este necesar să lucrați cu ramurile. Ați fost de acord cu echipa de știință a datelor că, de fiecare dată când doresc să efectueze o modificare, vor crea o ramură de caracteristici pentru a crea o copie a codului și a efectua modificările lor în copie.
Orice om de știință de date poate să creeze o ramură de caracteristici și să lucreze acolo. După ce au actualizat codul și doresc ca acel cod să fie noul cod de producție, va trebui să creeze o solicitare de extragere . În solicitarea de tragere, aceasta va fi vizibilă pentru alții ce sunt modificările propuse, oferindu-le altora posibilitatea de a revizui și discuta modificările.
Ori de câte ori se creează o solicitare de extragere, doriți să verificați automat dacă funcționează codul și dacă calitatea codului depinde de standardele organizației dvs. După ce codul trece de verificările calității, omul de știință principal trebuie să revizuiască modificările și să aprobe actualizările înainte de îmbinarea solicitării de tragere, iar codul din ramura principală poate fi actualizat în consecință.
Important
Nimeni nu ar trebui să aibă vreodată permisiunea de a împinge modificările la ramura principală. Pentru a vă proteja codul, mai ales codul de producție, se recomandă să impuneți ca ramura principală să poată fi actualizată doar prin solicitări de extragere care trebuie aprobate.