Руководство. Обнаружение и анализ аномалий с помощью возможностей машинного обучения KQL в Azure Monitor
Язык запросов Kusto (KQL) включает операторы машинного обучения, функции и подключаемые модули для анализа временных рядов, обнаружения аномалий, прогнозирования и анализа первопричин. Используйте эти возможности KQL для выполнения расширенного анализа данных в Azure Monitor без дополнительных затрат на экспорт данных во внешние средства машинного обучения.
В этом руководстве описано следующее:
- Создание временных рядов
- Определение аномалий во временных рядах
- Настройка параметров обнаружения аномалий для уточнения результатов
- Анализ первопричины аномалий
Примечание
В этом руководстве содержатся ссылки на демонстрационную среду Log Analytics, в которой можно выполнять примеры запросов KQL. Однако вы можете реализовать одни и те же KQL-запросы и субъекты во всех средствах Azure Monitor, использующих KQL.
Предварительные требования
- Учетная запись Azure с активной подпиской. Создайте учетную запись бесплатно.
- Рабочая область с данными журнала.
Необходимые разрешения
У вас Microsoft.OperationalInsights/workspaces/query/*/read должны быть разрешения для запрашиваемых рабочих областей Log Analytics, например, предоставляемые встроенной ролью Читатель Log Analytics.
Создание временных рядов
Используйте оператор KQL make-series для создания временных рядов.
Давайте создадим временные ряды на основе журналов в таблице "Использование", в которой содержатся сведения о том, сколько данных каждый час будет принимать каждая таблица в рабочей области, включая оплачиваемые и не оплачиваемые данные.
Этот запрос использует make-series для диаграммы общий объем оплачиваемых данных, ежедневно принятых каждой таблицей в рабочей области за последние 21 день:
Щелкните, чтобы выполнить запрос
let starttime = 21d; // The start date of the time series, counting back from the current date
let endtime = 0d; // The end date of the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Include only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| render timechart // Renders results in a timechart
На результирующей диаграмме можно четко увидеть некоторые аномалии, например в AzureDiagnostics типах данных и SecurityEvent :
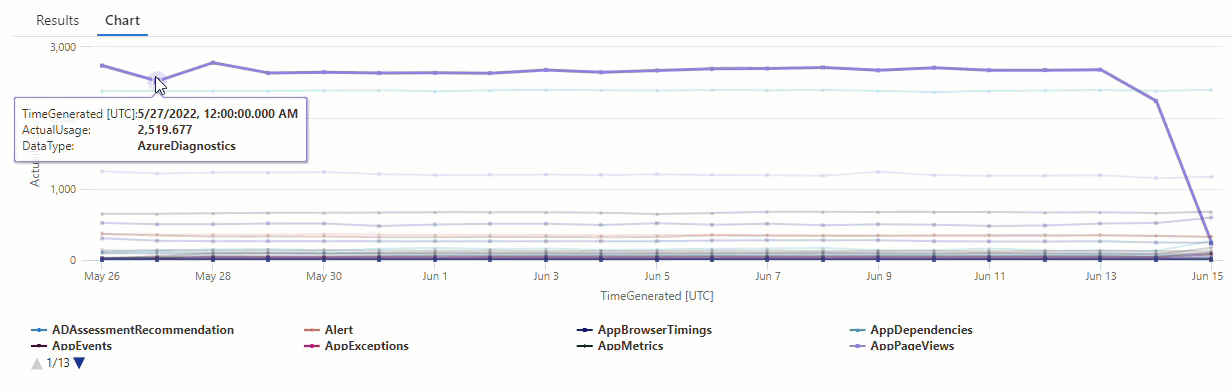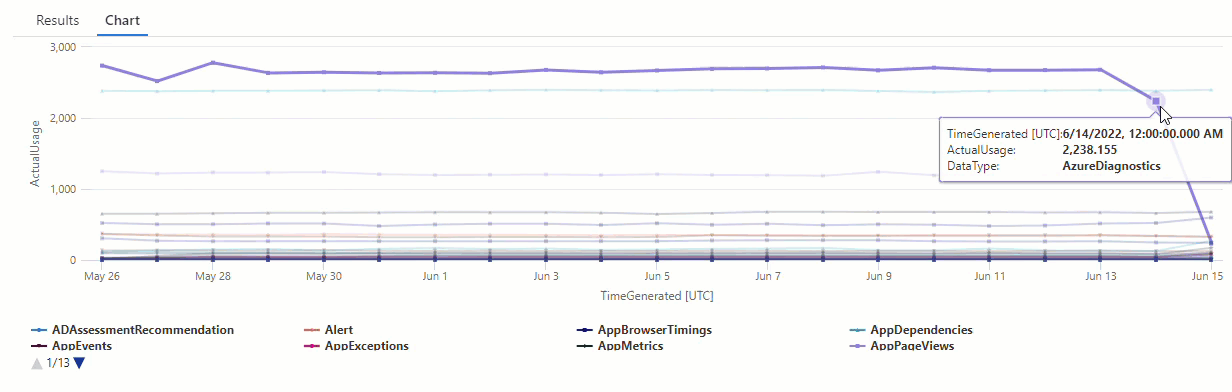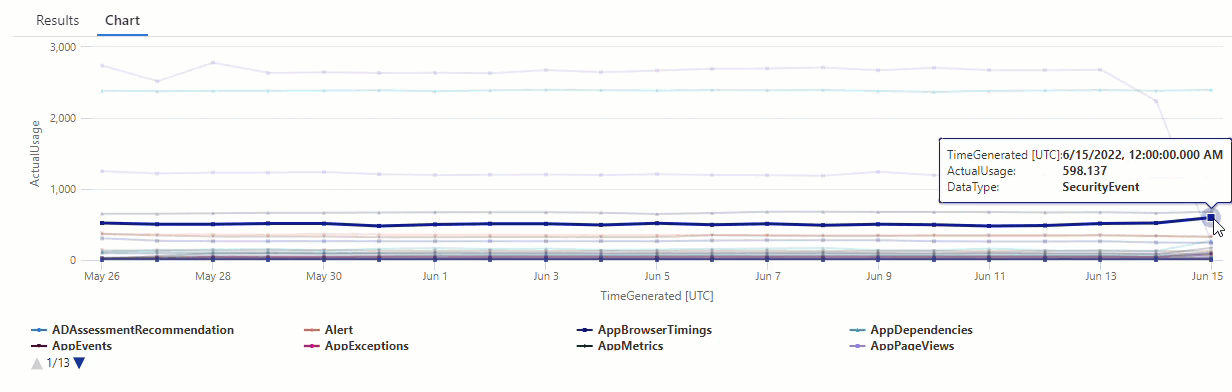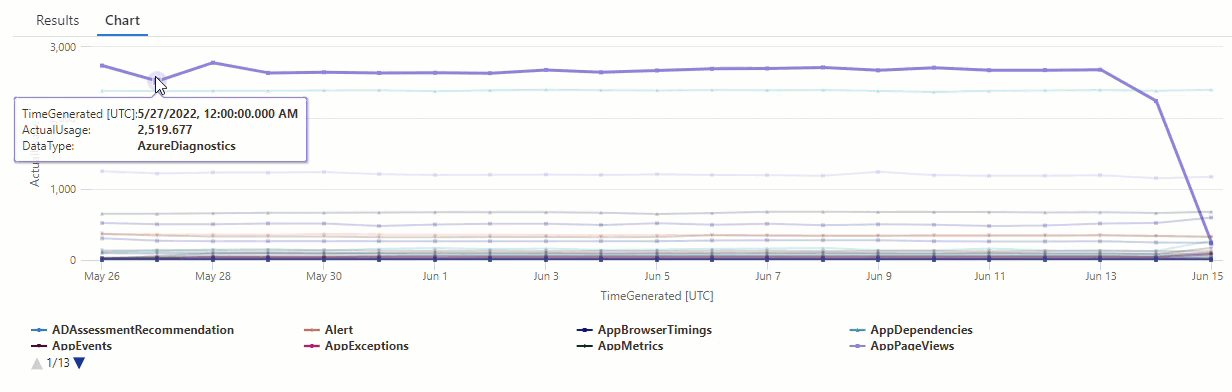
Далее мы будем использовать функцию KQL для перечисления всех аномалий во временных рядах.
Примечание
Дополнительные сведения о make-series синтаксисе и использовании см. в разделе Оператор make-series.
Поиск аномалий во временных рядах
Функция series_decompose_anomalies() принимает ряд значений в качестве входных данных и извлекает аномалии.
Давайте предоставим результирующий набор запроса временного ряда в качестве входных данных series_decompose_anomalies() для функции:
Щелкните, чтобы выполнить запрос
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage) // Scores and extracts anomalies based on the output of make-series
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Этот запрос возвращает все аномалии использования для всех таблиц за последние три недели:

Просмотрев результаты запроса, можно увидеть, что функция:
- Вычисляет ожидаемое ежедневное использование для каждой таблицы.
- Сравнивает фактическое ежедневное использование с ожидаемым использованием.
- Присваивает каждой точке данных оценку аномалий, указывая степень отклонения фактического использования от ожидаемого использования.
- Определяет положительные (
1) и отрицательные () аномалии в-1каждой таблице.
Примечание
Дополнительные сведения о series_decompose_anomalies() синтаксисе и использовании см. в разделе series_decompose_anomalies().
Настройка параметров обнаружения аномалий для уточнения результатов
Рекомендуется проверять первоначальные результаты запроса и при необходимости вносить в него корректировки. Выбросы входных данных могут повлиять на обучение функции, и вам может потребоваться настроить параметры обнаружения аномалий функции, чтобы получить более точные результаты.
Отфильтруйте результаты series_decompose_anomalies() запроса на наличие аномалий в типе AzureDiagnostics данных:

Результаты показывают две аномалии 14 июня и 15 июня. Сравните эти результаты с диаграммой из нашего первого make-series запроса, где можно увидеть другие аномалии 27 и 28 мая:

Разница в результатах возникает потому, что series_decompose_anomalies() функция оценивает аномалии относительно ожидаемого значения использования, которое функция вычисляет на основе полного диапазона значений во входном ряду.
Чтобы получить более точные результаты от функции, исключите использование 15 июня, что является выбросом по сравнению с другими значениями ряда, из процесса обучения функции.
series_decompose_anomalies() Синтаксис функции:
series_decompose_anomalies (Series[Threshold,Seasonality,Trend,Test_points,AD_method,Seasonality_threshold])
Test_points указывает количество точек в конце ряда, исключаемых из процесса обучения (регрессии).
Чтобы исключить последнюю точку данных, задайте для 1значение Test_points :
Щелкните, чтобы выполнить запрос
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage,1.5,-1,'avg',1) // Scores and extracts anomalies based on the output of make-series, excluding the last value in the series - the Threshold, Seasonality, and Trend input values are the default values for the function
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Отфильтруйте результаты по типу AzureDiagnostics данных:

Все аномалии на диаграмме из первого make-series запроса теперь отображаются в результирующем наборе.
Анализ первопричины аномалий
Сравнение ожидаемых значений с аномальными помогает понять причину различий между двумя наборами.
Подключаемый модуль KQL diffpatterns() сравнивает два набора данных одной структуры и находит шаблоны, характеризующие различия между двумя наборами данных.
В этом запросе сравнивается AzureDiagnostics использование за 15 июня( крайнее выбросы в нашем примере) с использованием таблицы в другие дни:
Щелкните, чтобы выполнить запрос
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let anomalyDate = datetime_add('day',-1, make_datetime(startofday(ago(endtime)))); // Start of day of the anomaly date, which is the last full day in the time range in our example (you can replace this with a specific hard-coded anomaly date)
AzureDiagnostics
| extend AnomalyDate = iff(startofday(TimeGenerated) == anomalyDate, "AnomalyDate", "OtherDates") // Adds calculated column called AnomalyDate, which splits the result set into two data sets – AnomalyDate and OtherDates
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Defines the time range for the query
| project AnomalyDate, Resource // Defines which columns to return
| evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate") // Compares usage on the anomaly date with the regular usage pattern
Запрос определяет, что каждая запись в таблице происходит в AnomalyDate (15 июня) или OtherDates. Затем подключаемый diffpatterns() модуль разделяет эти наборы данных , называемые A (OtherDates в нашем примере) и B (AnomalyDate в нашем примере), и возвращает несколько шаблонов, которые влияют на различия в двух наборах:

При просмотре результатов запроса можно увидеть следующие отличия:
- Существует 24 892 147 экземпляров приема из ресурса CH1-GEARAMAAKS за все остальные дни в диапазоне времени запроса, и не принимать данные из этого ресурса 15 июня. Данные из ресурса CH1-GEARAMAAKS составляют 73,36 % от общего приема в другие дни в диапазоне времени запроса и 0 % от общего приема 15 июня.
- Существует 2 168 448 экземпляров приема из ресурса NSG-TESTSQLMI519 во все остальные дни в диапазоне времени запроса и 110 544 экземпляра приема из этого ресурса 15 июня. Данные из ресурса NSG-TESTSQLMI519 составляют 6,39 % от общего приема в другие дни в диапазоне времени запроса и 25,61 % от приема 15 июня.
Обратите внимание, что в среднем существует 108 422 экземпляра приема из ресурса NSG-TESTSQLMI519 в течение 20 дней, составляющих период других дней (разделите 2 168 448 на 20). Таким образом, прием данных из ресурса NSG-TESTSQLMI519 15 июня существенно не отличается от приема этого ресурса в другие дни. Тем не менее, так как 15 июня ch1-GEARAMAAKS не принимает данные, прием из NSG-TESTSQLMI519 составляет значительно больший процент от общего приема данных на дату аномалии по сравнению с другими днями.
В столбце PercentDiffAB показана абсолютная разница в процентах между A и B (|PercentA — PercentB|), который является main мерой разницы между двумя наборами. По умолчанию подключаемый diffpatterns() модуль возвращает разницу более 5 % между двумя наборами данных, но это пороговое значение можно изменить. Например, чтобы возвращать только различия в 20 % или более между двумя наборами данных, можно задать | evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate", "~", 0.20) в приведенном выше запросе. Теперь запрос возвращает только один результат:

Примечание
Дополнительные сведения о diffpatterns() синтаксисе и использовании см. в разделе подключаемый модуль diff шаблонов.
Дальнейшие действия
См. также: