Копирование данных из Amazon Redshift с помощью Фабрики данных Azure или Synapse Analytics
Область применения: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этой статье описывается, как с помощью действия копирования в конвейерах Фабрики данных Azure и Synapse Analytics копируются данные из Amazon Redshift. Это продолжение статьи об обзоре действия копирования, в которой представлены общие сведения о действии копирования.
Поддерживаемые возможности
Соединитель Amazon Redshift поддерживается для следующих возможностей:
| Поддерживаемые возможности | IR |
|---|---|
| Действие копирования (источник/-) | ① ② |
| Действие поиска | ① ② |
① Среда выполнения интеграции Azure ② Локальная среда выполнения интеграции
Список хранилищ данных, которые поддерживаются в качестве источников и приемников для действия копирования, приведен в таблице Поддерживаемые хранилища данных и форматы.
Этот соединитель Amazon Redshift поддерживает получение данных из Redshift с помощью запроса или встроенной поддержки операции UNLOAD Redshift.
Совет
Чтобы обеспечить наилучшую производительность при копировании больших объемов данных из Redshift, рекомендуется использовать встроенный механизм Redshift UNLOAD через Amazon S3. Дополнительные сведения см. в разделе Копирование данных из Amazon Redshift с помощью UNLOAD.
Необходимые компоненты
- При копировании данных в локальное хранилище данных с помощью локальной среды IR предоставьте среде выполнения интеграции доступ к кластеру Amazon Redshift (использовав IP-адрес компьютера). Инструкции см. в статье об авторизации доступа к кластеру.
- Если вы копируете данные в хранилище данных Azure, вам нужно знать IP-адреса вычислительных ресурсов и диапазоны SQL, используемые центрами обработки данных Azure. Диапазоны IP-адресов центра обработки данных Azure приведены на этой странице.
Начало работы
Чтобы выполнить действие копирования с конвейером, можно воспользоваться одним из приведенных ниже средств или пакетов SDK:
- средство копирования данных;
- Портал Azure
- Пакет SDK для .NET
- Пакет SDK для Python
- Azure PowerShell
- The REST API
- шаблон Azure Resource Manager.
Создание связанной службы для Amazon Redshift с помощью пользовательского интерфейса
Выполните следующие действия, чтобы создать связанную службу для Amazon Redshift в пользовательском интерфейсе портала Azure.
Перейдите на вкладку "Управление" в рабочей области Фабрики данных Azure или Synapse и выберите "Связанные службы", после чего нажмите "Создать":
Выполните поиск Amazon и выберите соединитель Amazon RedShift.
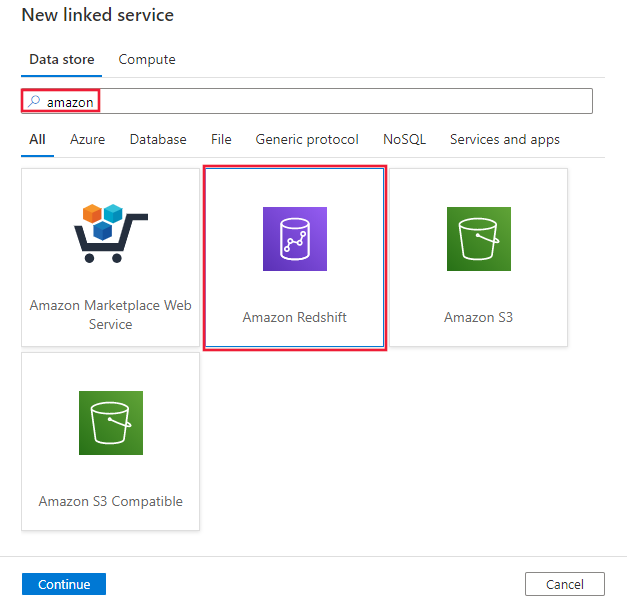
Настройте сведения о службе, проверьте подключение и создайте связанную службу.
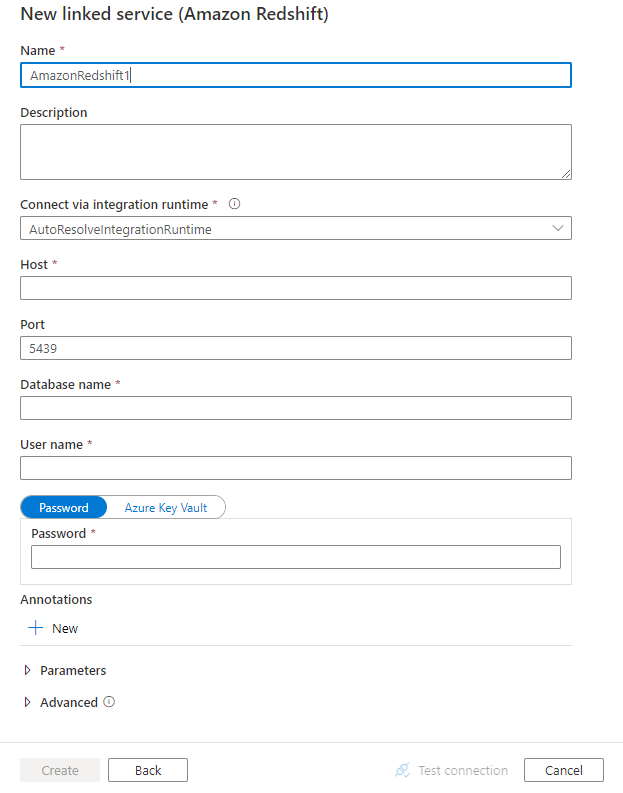
Сведения о конфигурации соединителя
Следующие разделы содержат сведения о свойствах, которые используются для определения сущностей фабрики данных, относящихся к соединителю Amazon Redshift.
Свойства связанной службы
Для связанной службы Amazon Redshift поддерживаются следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства типа необходимо задать значение AmazonRedshift. | Да |
| server | IP-адрес или имя узла сервера Amazon Redshift. | Да |
| port | Номер TCP-порта, используемого сервером Amazon Redshift для прослушивания клиентских подключений. | Нет, значение по умолчанию — 5439 |
| database | Имя базы данных Amazon Redshift. | Да |
| username | Имя пользователя, имеющего доступ к базе данных. | Да |
| password | Пароль для учетной записи пользователя. Пометьте это поле как SecureString, чтобы безопасно хранить его, или добавьте ссылку на секрет, хранящийся в Azure Key Vault. | Да |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Вы можете использовать среду выполнения интеграции Azure или локальную среду IR (если хранилище данных расположено в частной сети). Если не указано другое, по умолчанию используется интегрированная среда выполнения Azure. | No |
Пример:
{
"name": "AmazonRedshiftLinkedService",
"properties":
{
"type": "AmazonRedshift",
"typeProperties":
{
"server": "<server name>",
"database": "<database name>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Свойства набора данных
Полный список разделов и свойств, доступных для определения наборов данных, см. в статье о наборах данных. Этот раздел содержит список свойств, поддерживаемых набором данных Amazon Redshift.
Для копирования данных из Amazon Redshift поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type для набора данных должно быть AmazonRedshiftTable | Да |
| schema | Имя схемы. | Нет (если свойство query указано в источнике действия) |
| table | Имя таблицы. | Нет (если свойство query указано в источнике действия) |
| tableName | Имя таблицы со схемой. Это свойство поддерживается только для обеспечения обратной совместимости. Для новых рабочих нагрузок используйте schema и table. |
Нет (если свойство query указано в источнике действия) |
Пример
{
"name": "AmazonRedshiftDataset",
"properties":
{
"type": "AmazonRedshiftTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Amazon Redshift linked service name>",
"type": "LinkedServiceReference"
}
}
}
Если вы ранее использовали типизированный набор данных RelationalTable, он пока поддерживается и не требует изменений, но мы рекомендуем при любом удобном случае перейти на новую версию.
Свойства действия копирования
Полный список разделов и свойств, используемых для определения действий, см. в статье Конвейеры и действия в фабрике данных Azure. Этот раздел содержит список свойств, поддерживаемых источником Amazon Redshift.
Amazon Redshift в качестве источника
Чтобы скопировать данные из Amazon Redshift, задайте тип источника AmazonRedshiftSource в действии копирования. В разделе source действия копирования поддерживаются следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type источника действия копирования должно иметь значение AmazonRedshiftSource. | Да |
| query | Используйте пользовательский запрос для чтения данных. Например, select * from MyTable. | Нет (если для набора данных задано свойство tableName) |
| redshiftUnloadSettings | Группа свойств при использовании Amazon Redshift UNLOAD. | No |
| s3LinkedServiceName | Относится к службе Amazon S3, которую необходимо использовать в качестве промежуточного хранилища, указав имя связанной службы типа AmazonS3. | Да, если используется UNLOAD |
| bucketName | Укажите контейнер S3 для хранения промежуточных данных. Если не указано иное, служба создает его автоматически. | Да, если используется UNLOAD |
Пример. Источник Amazon Redshift в действии копирования с использованием UNLOAD
"source": {
"type": "AmazonRedshiftSource",
"query": "<SQL query>",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "<Amazon S3 linked service>",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
}
Дополнительные сведения о том, как использовать UNLOAD для эффективного копирования данных из Amazon Redshift, см. в следующем разделе.
Копирование данных из Amazon Redshift с помощью UNLOAD
UNLOAD — это механизм, предоставляемый Amazon Redshift, позволяющий выгрузить результаты запроса в один или несколько файлов в Amazon Simple Storage Service (Amazon S3). Компания Amazon рекомендует использовать этот способ для копирования большого набора данных из Redshift.
Пример. Копирование данных из Amazon Redshift в хранилище данных Azure Synapse Analytics с помощью UNLOAD, промежуточного копирования и PolyBase
В этом варианте использования действие копирования выгружает данные из Amazon Redshift в Amazon S3, как задано в redshiftUnloadSettings, а затем копирует данные из Amazon S3 в большой двоичный объект Azure, заданный в stagingSettings, и наконец, использует PolyBase для загрузки данных в Azure Synapse Analytics. Формат промежуточного хранения обрабатывается действием копирования должным образом.

"activities":[
{
"name": "CopyFromAmazonRedshiftToSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "AmazonRedshiftDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRedshiftSource",
"query": "select * from MyTable",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "AmazonS3LinkedService",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": "AzureStorageLinkedService",
"path": "adfstagingcopydata"
},
"dataIntegrationUnits": 32
}
}
]
Сопоставление типов данных для Amazon Redshift
При копировании данных из Amazon Redshift используются следующие сопоставления типов данных Amazon Redshift с промежуточными типами данных, используемыми службой для внутренних целей. Дополнительные сведения о том, как действие копирования сопоставляет исходную схему и типы данных для приемника, см. в статье Сопоставление схем в действии копирования.
| Тип данных Amazon Redshift | Промежуточный тип данных службы |
|---|---|
| BIGINT | Int64 |
| BOOLEAN | Строка |
| CHAR | Строка |
| DATE | Дата/время |
| DECIMAL | Десятичное число |
| DOUBLE PRECISION | Двойной |
| INTEGER | Int32 |
| real | Одна |
| SMALLINT | Int16 |
| ТЕКСТ | Строка |
| TIMESTAMP | Дата/время |
| VARCHAR | Строка |
Свойства действия поиска
Подробные сведения об этих свойствах см. в разделе Действие поиска.
Связанный контент
Список хранилищ данных, которые поддерживаются в качестве источников и приемников для действия Copy, приведен в таблице Поддерживаемые хранилища данных и форматы.