Копирование и преобразование данных в Базе данных Azure для PostgreSQL с помощью Фабрики данных Azure или Synapse Analytics
Область применения: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этой статье описано, как использовать действие Copy в конвейерах Фабрики данных Azure и Synapse Analytics для копирования данных в Базу данных Azure для PostgreSQL и из нее, а также как использовать Поток данных для преобразования данных в Базе данных Azure для PostgreSQL. Дополнительные сведения см. в вводных статьях о Фабрике данных Azure и Synapse Analytics.
Этот соединитель предназначен только для службы База данных Azure для PostgreSQL. Чтобы скопировать данные из универсальной базы данных PostgreSQL, расположенной в локальной среде или в облаке, используйте соединитель PostgreSQL.
Поддерживаемые возможности
Этот соединитель Базы данных Azure для PostgreSQL поддерживается для следующих возможностей.
| Поддерживаемые возможности | IR | Управляемая частная конечная точка |
|---|---|---|
| Действие копирования (источник/приемник) | ① ② | ✓ |
| Поток данных для сопоставления (источник/приемник) | ① | ✓ |
| Действие поиска | ① ② | ✓ |
① Среда выполнения интеграции Azure ② Локальная среда выполнения интеграции
Эти три действия подходят для всех вариантов развертывания Базы данных Azure для PostgreSQL:
Начало работы
Чтобы выполнить действие копирования с конвейером, можно воспользоваться одним из приведенных ниже средств или пакетов SDK:
- средство копирования данных;
- Портал Azure
- Пакет SDK для .NET
- Пакет SDK для Python
- Azure PowerShell
- The REST API
- шаблон Azure Resource Manager.
Создание связанной службы для База данных Azure для PostgreSQL с помощью пользовательского интерфейса
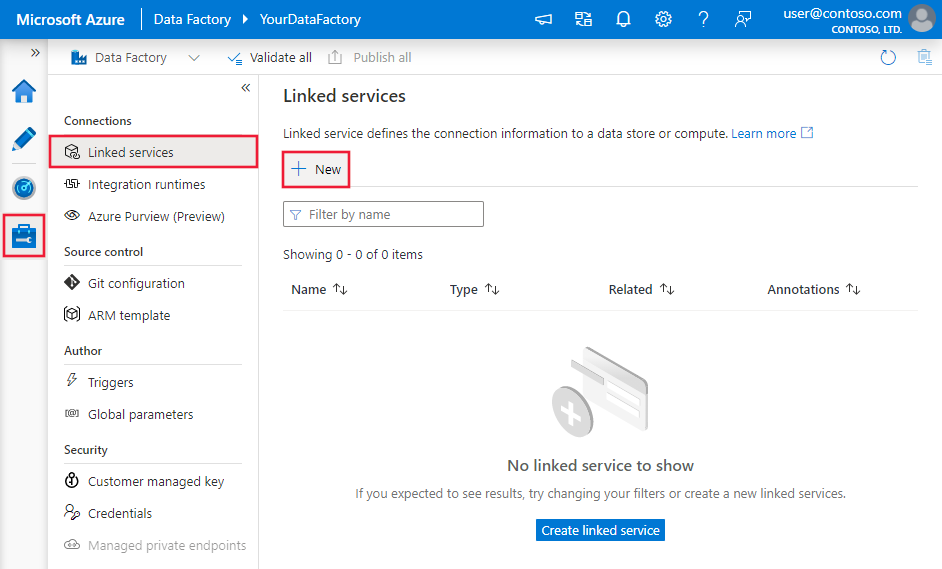
С помощью указанных ниже действий можно создать связанную службу для Базы данных Azure для PostgreSQL в пользовательском интерфейсе на портале Azure.
Перейдите на вкладку "Управление" в рабочей области Фабрики данных Azure или Synapse и выберите "Связанные службы", после чего нажмите "Создать":
Выполните поиск по слову "PostgreSQL" и выберите соединитель Базы данных Azure для PostgreSQL.
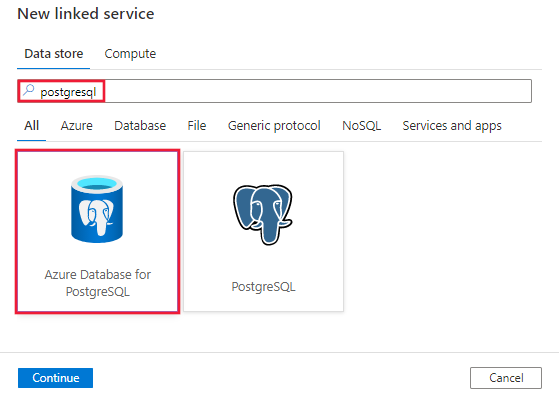
Настройте сведения о службе, проверьте подключение и создайте связанную службу.
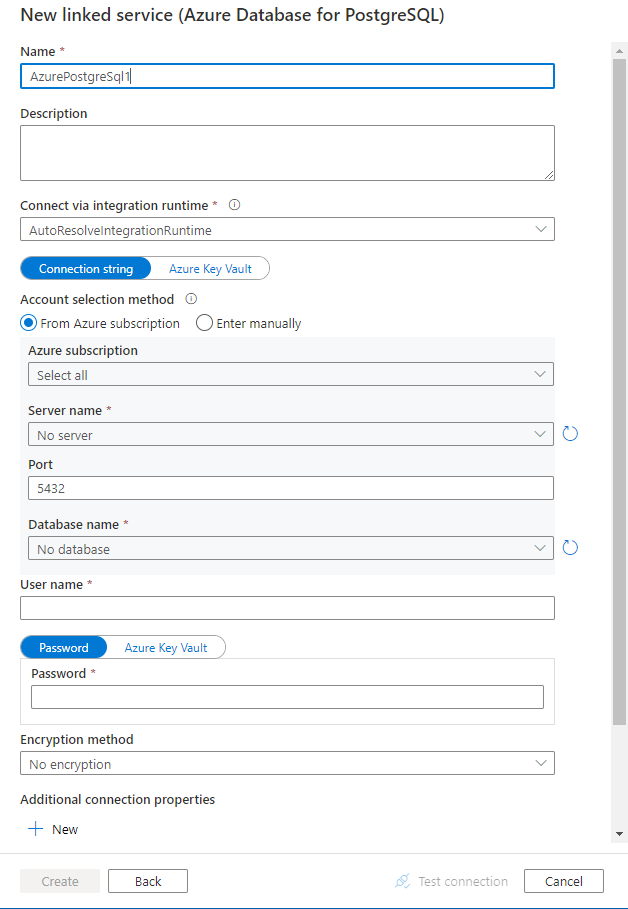
Сведения о конфигурации соединителя
Следующие разделы содержат сведения о свойствах, которые используются для определения записей в фабрике данных, относящихся к соединителю базы данных Azure для PostgreSQL.
Свойства связанной службы
Для связанной службы базы данных Azure для PostgreSQL поддерживаются следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type необходимо задать значение AzurePostgreSql. | Да |
| connectionString | Строка подключения к базе данных Azure для PostgreSQL через интерфейс ODBC. Вы можете также поместить пароль в Azure Key Vault и извлечь конфигурацию password из строки подключения. Для получения более подробной информации см. приведенные ниже примеры и статью Хранение учетных данных в Azure Key Vault. |
Да |
| connectVia | Это свойство представляет среду integration runtime, используемую для подключения к хранилищу данных. Вы можете использовать среду выполнения интеграции Azure или локальную среду IR (если хранилище данных расположено в частной сети). Если не указано другое, по умолчанию используется интегрированная среда выполнения Azure. | No |
Типичная строка подключения — Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;Password=<Password>. Ниже приведены дополнительные свойства, которые вы можете установить в вашем случае:
| Свойство | Description | Параметры | Обязательное поле |
|---|---|---|---|
| EncryptionMethod (EM) | Метод, используемый драйвером для шифрования данных, отправленных между драйвером и сервером базы данных. Пример: EncryptionMethod=<0/1/6>; |
0 (без шифрования) (по умолчанию) -1 (SSL) или 6 (RequestSSL) | No |
| ValidateServerCertificate (VSC) | Определяет, проверяет ли драйвер сертификат, отправленный сервером базы данных, когда включено шифрование SSL (метод шифрования = 1). Пример: ValidateServerCertificate=<0/1>; |
0 (отключено) (по умолчанию) -1 (включено) | No |
Пример:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"typeProperties": {
"connectionString": "Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;Password=<Password>"
}
}
}
Пример:
Сохранение пароля в Azure Key Vault
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"typeProperties": {
"connectionString": "Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
Свойства набора данных
Полный список разделов и свойств, доступных для определения наборов данных, см. в разделе Наборы данных в фабрике данных Azure. Этот раздел содержит список свойств, поддерживаемых в наборах данных в Базе данных Azure для PostgreSQL.
Чтобы скопировать данные из базы данных Azure для PostgreSQL, задайте для свойства type набора данных значение AzurePostgreSqlTable. Поддерживаются следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type для набора данных должно иметь значение AzurePostgreSqlTable | Да |
| tableName | Имя таблицы | Нет (если свойство query указано в источнике действия) |
Пример:
{
"name": "AzurePostgreSqlDataset",
"properties": {
"type": "AzurePostgreSqlTable",
"linkedServiceName": {
"referenceName": "<AzurePostgreSql linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
Свойства действия копирования
Полный список разделов и свойств, доступных для определения действий, см. в разделе Конвейеры и действия. Этот раздел содержит список свойств, поддерживаемых источником базы данных Azure для PostgreSQL.
База данных Azure для PostgreSQL в качестве источника
Чтобы скопировать данные из базы данных Azure для PostgreSQL, задайте для типа источника в действии копирования значение AzurePostgreSqlSource. В разделе source действия копирования поддерживаются следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type источника действия копирования должно иметь значение AzurePostgreSqlSource | Да |
| query | Используйте пользовательский SQL-запрос для чтения данных. Пример: SELECT * FROM mytable или SELECT * FROM "MyTable". Обратите внимание, что в PostgreSQL регистр в имени объекта не учитывается, если оно не заключено в кавычки. |
Нет (если в наборе данных задано свойство tableName) |
| partitionOptions | Задает параметры секционирования данных, используемые для загрузки данных из Базы данных SQL Microsoft Azure. Допустимые значения: Нет (по умолчанию), PhysicalPartitionsOfTable и DynamicRange. Если параметр секционирования включен (любое значение, кроме None), степень параллелизма для параллельной загрузки данных из Базы данных SQL Microsoft Azure управляется параметром parallelCopies в действии Copy. |
No |
| partitionSettings | Позволяет указать группу параметров для секционирования данных. Применяется, если параметр секционирования имеет значение, отличное от None. |
No |
В разделе partitionSettings: |
||
| partitionNames | Список физических секций, которые необходимо скопировать. Применяется, если параметр секции имеет значение PhysicalPartitionsOfTable. Если для получения исходных данных используется запрос, подключите ?AdfTabularPartitionName в предложении WHERE. Пример см. в разделе Параллельное копирование из Базы данных Azure для PostgreSQL. |
No |
| partitionColumnName | Укажите имя исходного столбца в виде целого числа или типа date/datetime (int, smallint, bigint, date, timestamp without time zone, timestamp with time zone или time without time zone), которое будет использоваться для секционирования по диапазонам при параллельном копировании. Если значение не указано, автоматически определяется первичный ключ таблицы, который используется в качестве столбца секционирования.Применяется, если параметр секции имеет значение DynamicRange. Если для получения исходных данных используется запрос, подключите ?AdfRangePartitionColumnName в предложении WHERE. Пример см. в разделе Параллельное копирование из Базы данных Azure для PostgreSQL. |
No |
| partitionUpperBound | Максимальное значение столбца секционирования для копирования данных. Применяется, если параметр секции имеет значение DynamicRange. Если для получения исходных данных используется запрос, подключите ?AdfRangePartitionUpbound в предложении WHERE. Пример см. в разделе Параллельное копирование из Базы данных Azure для PostgreSQL. |
No |
| partitionLowerBound | Минимальное значение столбца секционирования для копирования данных. Применяется, если параметр секции имеет значение DynamicRange. Если для получения исходных данных используется запрос, подключите ?AdfRangePartitionLowbound в предложении WHERE. Пример см. в разделе Параллельное копирование из Базы данных Azure для PostgreSQL. |
No |
Пример:
"activities":[
{
"name": "CopyFromAzurePostgreSql",
"type": "Copy",
"inputs": [
{
"referenceName": "<AzurePostgreSql input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzurePostgreSqlSource",
"query": "<custom query e.g. SELECT * FROM mytable>"
},
"sink": {
"type": "<sink type>"
}
}
}
]
База данных Azure для PostgreSQL в качестве приемника
Для копирования данных в Базу данных Azure для PostgreSQL можно использовать следующие свойства, доступные в разделе sink для действия Copy:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type приемника действия Copy должно иметь значение AzurePostgreSQLSink. | Да |
| preCopyScript | Укажите SQL-запрос для действия Copy, выполняемый перед записью данных в Базу данных Azure для PostgreSQL при каждом выполнении. Это свойство можно использовать для очистки предварительно загруженных данных. | No |
| writeMethod | Метод, используемый для записи данных в базу данных Azure для PostgreSQL. Допустимые значения: CopyCommand (используется по умолчанию; это вариант с максимальной производительностью), BulkInsert. |
No |
| writeBatchSize | Число строк, загруженных в базу данных Azure для PostgreSQL, на пакет. Допустимо целочисленное значение, представляющее количество строк. |
Нет (значение по умолчанию — 1 000 000) |
| writeBatchTimeout | Время ожидания до выполнения операции пакетной вставки, пока не завершится срок ее действия. Допустимые значения: строковые значения временного диапазона. Например, 00:30:00 (30 минут). |
Нет (значение по умолчанию — 00:30:00) |
Пример:
"activities":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure PostgreSQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzurePostgreSQLSink",
"preCopyScript": "<custom SQL script>",
"writeMethod": "CopyCommand",
"writeBatchSize": 1000000
}
}
}
]
Параллельное копирование из Базы данных Azure для PostgreSQL
Соединитель Базы данных Azure для PostgreSQL в действии Copy обеспечивает встроенное секционирование данных для параллельного копирования данных. Параметры секционирования данных можно найти на вкладке Источник действия Copy.
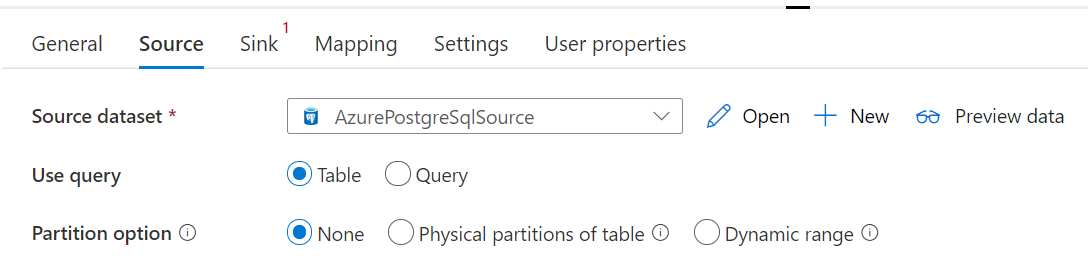
Если включено копирование с секционированием, действие Copy выполняет параллельные запросы к источнику Базы данных Azure для PostgreSQL для загрузки данных по секциям. Степень параллелизма определяется с помощью параметра parallelCopies для действия копирования. Например, если parallelCopies имеет значение 4, служба будет создавать и выполнять четыре запроса с учетом указанного способа и параметров секционирования, где каждый запрос извлекает часть данных из Базы данных Azure для PostgreSQL.
Рекомендуется включить параллельное копирование с секционированием данных, особенно при загрузке большого объема данных из Базы данных Azure для PostgreSQL. Ниже приведены рекомендуемые конфигурации для разных сценариев. Если данные копируются в файловое хранилище данных, то рекомендуется сохранять данные в папку несколькими файлами (указывая только имя папки), так как производительность в таком случае будет выше, чем при записи в один файл.
| Сценарий | Предлагаемые параметры |
|---|---|
| Полная загрузка из большой таблицы с физическими секциями. | Параметр секционирования. Физические секции таблицы. Во время выполнения служба автоматически определяет физические секции и копирует данные по секциям. |
| Полная загрузка из большой таблицы без физических секций, когда таблица содержит столбец целочисленного типа для секционирования данных. | Параметры секции: секция динамического диапазона. Столбец секционирования: укажите столбец, используемый для секционирования данных. Если значение не указано, то используется столбец с первичным ключом. |
| Загрузка большого объема данных с помощью пользовательского запроса с физическими секциями. | Параметр секционирования. Физические секции таблицы. Запрос: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>.Имя секции: укажите имена секций, из которых следует копировать данные. Если не указано, служба автоматически обнаруживает физические секции в таблице, указанной в наборе данных PostgreSQL. Во время выполнения служба данных заменяет ?AdfTabularPartitionName фактическим именем секции и отправляет данные в Базу данных Azure для PostgreSQL. |
| Загрузка большого объема данных пользовательским запросом без использования физических секций, однако с использованием столбца целочисленного типа для секционирования данных. | Параметры секции: секция динамического диапазона. Запрос: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Столбец секционирования: укажите столбец, используемый для секционирования данных. Секционирование можно выполнять по столбцу с целочисленным типом данных или типом date/datetime. Верхняя граница секции и Нижняя граница секции: укажите эти значения, если нужно добавить фильтрацию по столбцу секционирования, чтобы получить данные только в пределах между нижним и верхним значениями. Во время выполнения служба заменяет ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbound и ?AdfRangePartitionLowbound фактическим именем столбца и диапазонами значений для каждой секции, а затем отправляет их в Базу данных Azure для PostgreSQL. Например, если указан столбец секционирования ID с нижней границей 1 и верхней границей 80 при этом для параллельного копирования указано значение 4, служба будет извлекать данные по 4 секциям. Для них будут применены следующие диапазоны значений идентификаторов: [1, 20], [21, 40], [41, 60] и [61, 80]. |
Ниже приведены рекомендации по загрузке данных с параметром секционирования.
- Чтобы избежать неравномерного распределения данных, выбирайте в качестве столбца секционирования отличительный столбец (например, первичный ключ или уникальный ключ).
- Если таблица имеет встроенную секцию, используйте параметр секционирования "Физические секции таблицы" для повышения производительности.
- Если для копирования данных используется Azure Integration Runtime, то в параметре Единицы интеграции данных (DIU) можно задать большее значение (>4), чтобы задействовать больше вычислительных ресурсов. Ознакомьтесь со сценариями использования этого механизма.
- Параметр "Степень параллелизма копирования" контролирует номера секций. Если это число слишком велико, это может существенно сказаться на производительности. Рекомендуется задавать это число следующим образом: (DIU или число узлов локальной среды IR) * (от 2 до 4).
Пример. Полная загрузка из большой таблицы с физическими секциями
"source": {
"type": "AzurePostgreSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Пример: запрос с секционированием по динамическому диапазону
"source": {
"type": "AzurePostgreSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Свойства потока данных для сопоставления
При преобразовании данных в потоке данных для сопоставления можно выполнять операции чтения и записи в таблицах из Базы данных Azure для PostgreSQL. Дополнительные сведения см. в описаниях преобразования источника и преобразования приемника в разделе, посвященном потокам данных для сопоставления. Можно выбрать использование набора данных Базы данных Azure для PostgreSQL или встроенного набора данных в качестве типа источника и приемника.
Преобразование источника
В таблице ниже перечислены свойства, поддерживаемые источником Базы данных Azure для PostgreSQL. Изменить эти свойства можно на вкладке Source options (Параметры источника).
| Имя | Описание | Обязательное поле | Допустимые значения | Свойство скрипта для потока данных |
|---|---|---|---|---|
| Таблицу | Если выбрать таблицу в качестве входных данных, поток данных извлекает все данные из таблицы, указанной в наборе данных. | No | - | (только для встроенного набора данных) tableName |
| Query | При выборе запроса в качестве входных данных укажите SQL-запрос для выборки данных из источника, переопределяющий любую таблицу, указанную в наборе данных. Использование запросов — отличный способ сокращения количества строк для тестирования или поиска. Предложение Order By не поддерживается, но можно задать полную инструкцию SELECT FROM. Кроме того, можно использовать табличные функции, определяемые пользователем. select * from udfGetData() — определяемая пользователем функция в SQL, возвращающая таблицу, которую можно использовать в потоке данных. Пример запроса: select * from mytable where customerId > 1000 and customerId < 2000 или select * from "MyTable". Обратите внимание, что в PostgreSQL регистр в имени объекта не учитывается, если оно не заключено в кавычки. |
Нет | Строка | query |
| Имя схемы | Если в качестве типа входных данных выбран "Хранимая процедура", укажите имя схемы для хранимой процедуры или щелкните "Обновить", чтобы служба выполнила обнаружение имен схем. | Нет | Строка | schemaName |
| Хранимая процедура | Если для входных данных выбран тип "Хранимая процедура", укажите имя хранимой процедуры для чтения данных из исходной таблицы или нажмите кнопку "Обновить", чтобы служба выполнила обнаружение имен процедур. | Да (при выборе типа входных данных "Хранимая процедура") | Строка | procedureName |
| Параметры процедуры | Если для входных данных выбран тип "Хранимая процедура", укажите входные параметры для хранимой процедуры в том порядке, в котором они заданы в используемой процедуре, или щелкните "Импорт", чтобы импортировать все параметры процедуры в формате @paraName. |
No | Массив | входные данные |
| Размер пакета | Укажите размер пакета для разделения больших наборов данных на пакеты. | No | Целое | batchSize |
| Уровень изоляции | Выберите один из следующих уровней изоляции: - Read Committed (чтение зафиксированных данных) - Read Uncommitted (по умолчанию) - Repeatable Read (повторяющаяся операция чтения) - Serializable (сериализуемый) - None (игнорировать уровень изоляции) |
No | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZABLE NONE |
isolationLevel |
Пример сценария источника Базы данных Azure для PostgreSQL
При использовании Базы данных Azure для PostgreSQL в качестве типа источника связанным сценарием потока данных будет:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzurePostgreSQLSource
Преобразование приемника
В таблице ниже перечислены свойства, поддерживаемые приемником Базы данных Azure для PostgreSQL. Эти свойства можно изменить на вкладке Параметры приемника.
| Имя | Описание | Обязательное поле | Допустимые значения | Свойство скрипта для потока данных |
|---|---|---|---|---|
| Метод обновления | Укажите, какие операции разрешены в назначении базы данных. По умолчанию разрешены только операции вставки. Для выполнения обновления (update), обновления или вставки (upsert) или удаления (delete) строк требуется преобразование alter-row, чтобы отметить строки для этих действий. |
Да | true или false |
deletable Вставляемый Обновляемым подлежит обновлению или вставке |
| Ключевые столбцы | Для выполнения обновления (update), обновления или вставки (upsert) или удаления (delete) должен быть установлен ключевой столбец или столбцы, позволяющие определить строки для изменения. Имя столбца, которой вы выберете в качестве ключа, будет использоваться при выполнении последующих операций обновления и удаления, а также операции upsert. Поэтому необходимо выбрать столбец, существующий в сопоставлении приемника. |
No | Массив | клиентом |
| Пропустить запись ключевых столбцов | Если вы не хотите записывать значение в ключевой столбец, выберите "Skip writing key columns" (Пропустить запись ключевых столбцов). | No | true или false |
skipKeyWrites |
| Действие таблицы | Определяет, следует ли повторно создавать или удалять все строки в целевой таблице перед записью. - Нет: действия с таблицей не будут выполняться. - Создать повторно: таблица будет удалена и создана повторно. Это действие необходимо, если новая таблица создается динамически. - Усечь: все строки из целевой таблицы будут удалены. |
No | true или false |
создать повторно truncate |
| Размер пакета | Укажите, сколько строк записывается в каждый пакет. Более крупные размеры пакетов улучшают сжатие и оптимизацию памяти, но при кэшировании данных возникает риск нехватки памяти. | No | Целое | batchSize |
| Выбрать схему базы данных пользователя | По умолчанию в схеме приемника будет создана временная таблица в качестве промежуточной. Кроме того, можно отменить выбор параметра Использовать схему приемника и вместо этого указать имя схемы, с которым Фабрика данных создаст промежуточную таблицу для загрузки вышестоящих данных и автоматической их очистки после завершения. Убедитесь, что у вас есть разрешение на создание таблицы в базе данных и разрешение на изменение для схемы. | Нет | Строка | stagingSchemaName |
| Скрипты SQL предобработки и постобработки | Укажите многострочные скрипты SQL, которые будут выполняться до (предобработка) и после (постобработка) записи данных в базу данных-приемник. | Нет | Строка | preSQLs postSQLs |
Совет
- Рекомендуется разбивать пакетные скрипты с несколькими командами на несколько пакетов.
- В качестве части пакета могут выполняться только инструкции языка описания данных DDL и языка обработки данных DML, возвращающие простой счетчик обновлений. Узнайте больше о выполнении пакетных операций.
Включить добавочное извлечение. Используйте этот параметр, чтобы ADF обрабатывала только строки, которые изменились с момента последнего выполнения конвейера.
Добавочный столбец. При использовании функции добавочного извлечения необходимо выбрать дату и время или числовый столбец, который вы хотите использовать в качестве подложки в исходной таблице.
Начать чтение с самого начала. При установке этого параметра вместе с добавочным извлечением ADF будет считывать все строки при первом выполнении конвейера с включенным добавочным извлечением.
Пример сценария приемника Базы данных Azure для PostgreSQL
При использовании Базы данных Azure для PostgreSQL в качестве типа приемника связанным сценарием потока данных будет:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzurePostgreSQLSink
Свойства действия поиска
Дополнительные сведения о свойствах см. в статье об действии поиска.
Связанный контент
Список хранилищ данных, поддерживаемых в рамках функции копирования в качестве источников и приемников, см. в разделе Поддерживаемые хранилища данных.