Таблицы вывода для моделей мониторинга и отладки
Внимание
Эта функция предоставляется в режиме общедоступной предварительной версии.
В этой статье описываются таблицы вывода для обслуживаемой модели мониторинга. На следующей схеме показан типичный рабочий процесс с таблицами вывода. Таблица вывода автоматически записывает входящие запросы и исходящие ответы для конечной точки обслуживания модели и регистрирует их в виде таблицы delta каталога Unity. Данные в этой таблице можно использовать для мониторинга, отладки и улучшения моделей машинного обучения.
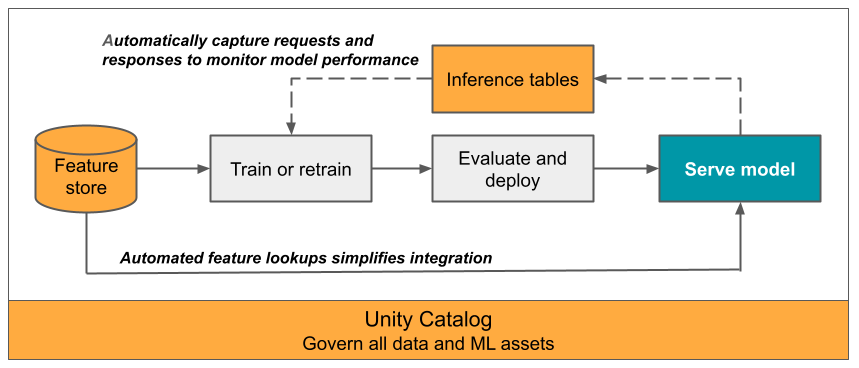
Что такое таблицы вывода?
Мониторинг производительности моделей в рабочих процессах является важным аспектом жизненного цикла модели искусственного интеллекта и машинного обучения. Таблицы вывода упрощают мониторинг и диагностика для моделей путем непрерывного ведения журнала входных и ответов запросов (прогнозов) из конечных точек службы модели ИИ Мозаики и сохранения их в таблице Delta в каталоге Unity. Затем можно использовать все возможности платформы Databricks, такие как запросы DBSQL, записные книжки и мониторинг Lakehouse для мониторинга, отладки и оптимизации моделей.
Таблицы вывода можно включить в любую существующую или только что созданную конечную точку обслуживания модели, а затем автоматически записывать запросы к этой конечной точке в таблице в UC.
Ниже приведены некоторые распространенные приложения для таблиц вывода:
- Мониторинг качества данных и моделей. Вы можете постоянно отслеживать производительность модели и смещение данных с помощью мониторинга Lakehouse. Мониторинг Lakehouse автоматически создает панели мониторинга качества данных и модели, которые можно поделиться с заинтересованными лицами. Кроме того, вы можете включить оповещения, чтобы узнать, когда необходимо переобучить модель на основе сдвигов входящих данных или уменьшения производительности модели.
- Отладка рабочих проблем. Данные журнала таблиц вывода, такие как коды состояния HTTP, время выполнения модели, запрос и ответ JSON-кода. Эти данные производительности можно использовать для отладки. Вы также можете использовать исторические данные в таблицах вывода для сравнения производительности модели по историческим запросам.
- Создайте обучающий корпус. Присоединившись к таблицам вывода с наземными метками истины, вы можете создать обучающий корпус, который можно использовать для повторного обучения или точной настройки и улучшения модели. С помощью рабочих процессов Databricks можно настроить цикл непрерывной обратной связи и автоматизировать повторное обучение.
Требования
- Рабочая область должна включать каталог Unity.
- Создатель конечной точки и модификатора должны иметь разрешение "Управление " на конечной точке. См. раздел Списки управления доступом.
- Создатель конечной точки и модификатора должны иметь следующие разрешения в каталоге Unity:
USE CATALOGразрешения для указанного каталога.USE SCHEMAразрешения на указанную схему.CREATE TABLEразрешения в схеме.
Включение и отключение таблиц вывода
В этом разделе показано, как включить или отключить таблицы вывода с помощью пользовательского интерфейса Databricks. Вы также можете использовать API; Инструкции см. в статье "Включение таблиц вывода для конечных точек обслуживания модели" с помощью API .
Владелец таблиц вывода — это пользователь, создавший конечную точку. Все списки управления доступом (ACL) в таблице соответствуют стандартным разрешениям каталога Unity и могут быть изменены владельцем таблицы.
Предупреждение
Таблица вывода может стать поврежденной, если выполнить одно из следующих действий:
- Измените схему таблицы.
- Измените имя таблицы.
- Удалите таблицу.
- Потеря разрешений на каталог или схему каталога Unity.
В этом случае auto_capture_config состояние конечной точки показывает FAILED состояние для таблицы полезных данных. В этом случае необходимо создать новую конечную точку для продолжения использования таблиц вывода.
Чтобы включить таблицы вывода во время создания конечной точки, выполните следующие действия.
Щелкните "Служить" в пользовательском интерфейсе Databricks Машинное обучение.
Нажмите кнопку "Создать конечную точку обслуживания".
Выберите " Включить таблицы вывода".
В раскрывающихся меню выберите нужный каталог и схему, в которой должна находиться таблица.
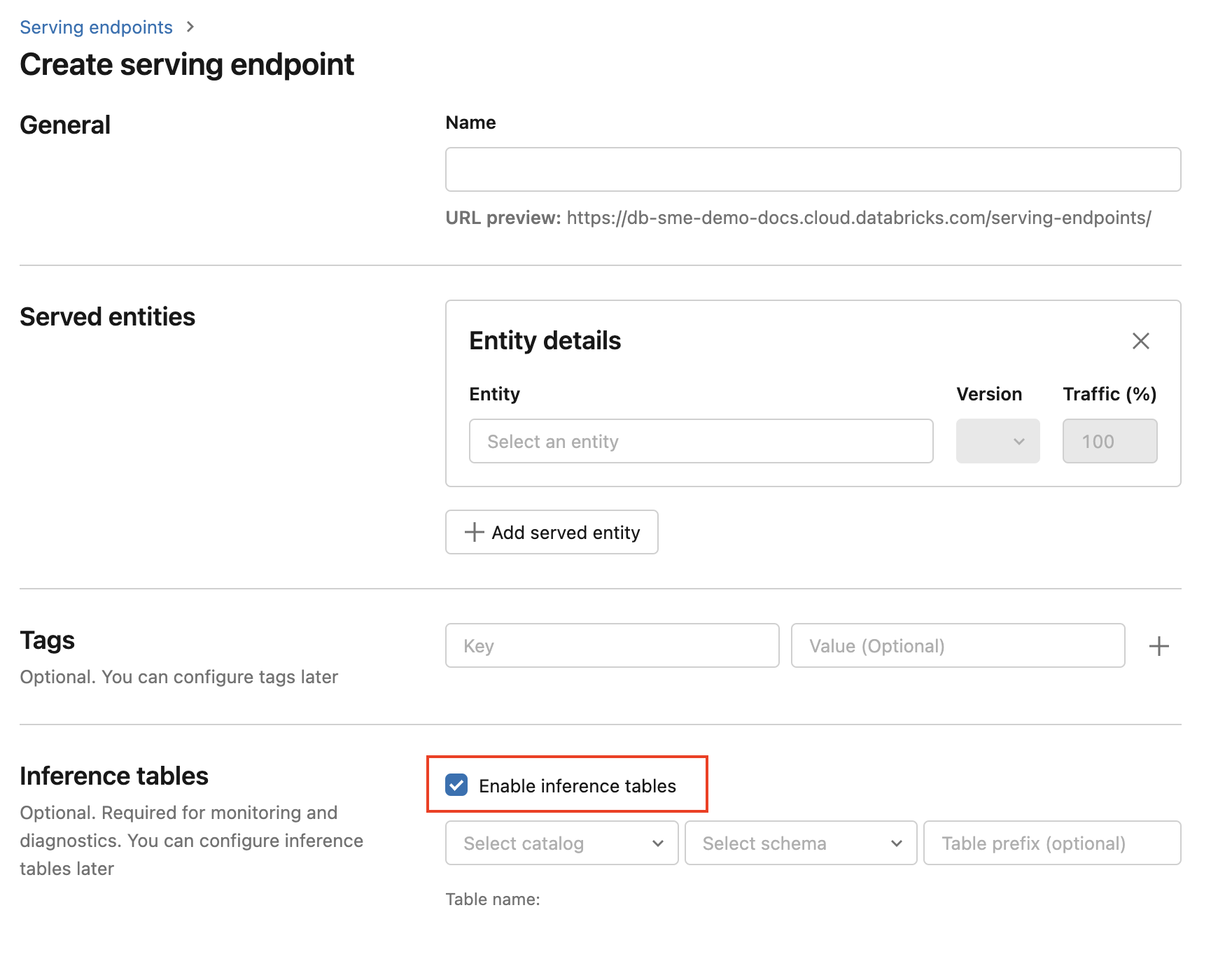
Имя
<catalog>.<schema>.<endpoint-name>_payloadтаблицы по умолчанию . При желании можно ввести настраиваемый префикс таблицы.Нажмите кнопку "Создать конечную точку обслуживания".
Вы также можете включить таблицы вывода в существующей конечной точке. Чтобы изменить существующую конфигурацию конечной точки, сделайте следующее:
- Перейдите на страницу конечной точки.
- Нажмите кнопку "Изменить конфигурацию".
- Выполните предыдущие инструкции, начиная с шага 3.
- По завершении нажмите кнопку "Обновить конечную точку обслуживания".
Выполните следующие инструкции, чтобы отключить таблицы вывода:
Внимание
При отключении таблиц вывода в конечной точке их нельзя повторно включить. Чтобы продолжить использование таблиц вывода, необходимо создать новую конечную точку и включить в ней таблицы вывода.
- Перейдите на страницу конечной точки.
- Нажмите кнопку "Изменить конфигурацию".
- Нажмите кнопку "Включить таблицу вывода", чтобы удалить флажок.
- После удовлетворения спецификаций конечной точки нажмите кнопку "Обновить".
Рабочий процесс: мониторинг производительности модели с помощью таблиц вывода
Чтобы отслеживать производительность модели с помощью таблиц вывода, выполните следующие действия.
- Включите таблицы вывода в конечной точке либо во время создания конечной точки, либо после обновления.
- Запланируйте рабочий процесс для обработки полезных данных JSON в таблице вывода, распаковав их в соответствии с схемой конечной точки.
- (Необязательно) Присоединяйтесь к распакованным запросам и ответам с метками с использованием меток "земляная истина", чтобы вычислить метрики качества модели.
- Создайте монитор по полученной таблице Delta и обновите метрики.
Начальные записные книжки реализуют этот рабочий процесс.
Начальная записная книжка для мониторинга таблицы вывода
Следующая записная книжка реализует описанные выше действия для распаковки запросов из таблицы вывода мониторинга Lakehouse. Записная книжка может выполняться по запросу или по регулярному расписанию с помощью рабочих процессов Databricks.
Начальная записная книжка для вывода таблицы Lakehouse Monitoring
Начальная записная книжка для мониторинга качества текста из конечных точек, обслуживающих LLM
Следующая записная книжка распаковывает запросы из таблицы вывода, вычисляет набор метрик оценки текста (например, удобочитаемость и токсичнысть), а также позволяет отслеживать эти метрики. Записная книжка может выполняться по запросу или по регулярному расписанию с помощью рабочих процессов Databricks.
Начальная записная книжка мониторинга LLM для вывода в Lakehouse
Запрос и анализ результатов в таблице вывода
После подготовки обслуживаемых моделей все запросы, сделанные для моделей, регистрируются автоматически в таблицу вывода вместе с ответами. Таблицу можно просмотреть в пользовательском интерфейсе, запросить таблицу из DBSQL или записной книжки или запросить таблицу с помощью REST API.
Чтобы просмотреть таблицу в пользовательском интерфейсе: на странице конечной точки щелкните имя таблицы вывода, чтобы открыть таблицу в обозревателе каталогов.

Чтобы запросить таблицу из DBSQL или записной книжки Databricks: можно выполнить код, аналогичный приведенному ниже, чтобы запросить таблицу вывода.
SELECT * FROM <catalog>.<schema>.<payload_table>
Если вы включили таблицы вывода с помощью пользовательского интерфейса, это имя таблицы, payload_table назначенное при создании конечной точки. Если вы включили таблицы вывода с помощью API, payload_table сообщается в state разделе auto_capture_config ответа. Пример см. в разделе "Включение таблиц вывода" для конечных точек обслуживания моделей с помощью API.
Примечание о производительности
После вызова конечной точки вы можете увидеть вызов, зарегистрированный в таблице вывода в течение часа после отправки запроса оценки. Кроме того, Azure Databricks гарантирует доставку журналов по крайней мере один раз, поэтому это возможно, хотя и маловероятно, что повторяющиеся журналы отправляются.
Схема таблицы вывода каталога Unity
Каждый запрос и ответ, который записывается в таблицу вывода, записывается в таблицу Delta со следующей схемой:
Примечание.
При вызове конечной точки с пакетом входных данных весь пакет регистрируется как одна строка.
| Имя столбца | Описание | Тип |
|---|---|---|
databricks_request_id |
Созданный идентификатор запроса Azure Databricks, подключенный ко всем запросам на обслуживание модели. | STRING |
client_request_id |
Необязательный идентификатор запроса, созданный клиентом, который можно указать в тексте запроса на обслуживание модели. Дополнительные сведения см. в разделе "Указание client_request_id ". |
STRING |
date |
Дата UTC, по которой был получен запрос на обслуживание модели. | DATE |
timestamp_ms |
Метка времени в миллисекундах эпохи при получении запроса на обслуживание модели. | LONG |
status_code |
Код состояния HTTP, возвращенный из модели. | INT |
sampling_fraction |
Дробь выборки, используемая в том случае, если запрос был понижен. Это значение составляет от 0 до 1, где 1 представляет, что 100% входящих запросов были включены. | DOUBLE |
execution_time_ms |
Время выполнения в миллисекундах, для которого модель выполнила вывод. Это не включает задержку накладных расходов на сеть и представляет только время, необходимое для модели для создания прогнозов. | LONG |
request |
Необработанный текст JSON запроса, отправленный в конечную точку обслуживания модели. | STRING |
response |
Текст JSON необработанного ответа, возвращаемый конечной точкой обслуживания модели. | STRING |
request_metadata |
Карта метаданных, связанных с конечной точкой обслуживания модели, связанной с запросом. Эта карта содержит имя конечной точки, имя модели и версию модели, используемую для конечной точки. | MAP<STRING, STRING> |
Уточнять client_request_id
Поле client_request_id является необязательным значением, которое пользователь может предоставить в тексте запроса на обслуживание модели. Это позволяет пользователю указать собственный идентификатор запроса, который отображается в конечной таблице вывода в разделе client_request_id и может использоваться для присоединения запроса к другим таблицам, которые используют client_request_idтакие, как присоединение метки конечной истины. Чтобы указать client_request_idзначение, добавьте его в качестве ключа верхнего уровня полезных данных запроса. Если значение не client_request_id указано, значение отображается как null в строке, соответствующей запросу.
{
"client_request_id": "<user-provided-id>",
"dataframe_records": [
{
"sepal length (cm)": 5.1,
"sepal width (cm)": 3.5,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.9,
"sepal width (cm)": 3,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.7,
"sepal width (cm)": 3.2,
"petal length (cm)": 1.3,
"petal width (cm)": 0.2
}
]
}
Позже client_request_id его можно использовать для соединения меток истинной истины при наличии других таблиц с метками, связанными с ним client_request_id.
Ограничения
- Управляемые клиентом ключи не поддерживаются.
- Для конечных точек, в которых размещаются базовые модели, таблицы вывода поддерживаются только в подготовленных рабочих нагрузках пропускной способности .
- Таблицы вывода не поддерживаются в конечных точках, на которых размещаются внешние модели.
- Брандмауэр Azure может привести к сбоям при создании таблицы delta каталога Unity, поэтому по умолчанию не поддерживается. Обратитесь к группе учетных записей Databricks, чтобы включить ее.
- Если таблицы вывода включены, ограничение для общего максимального параллелизма во всех обслуживаемых моделях в одной конечной точке равно 128. Обратитесь к группе учетных записей Azure Databricks, чтобы запросить увеличение этого ограничения.
- Если таблица вывода содержит более 500K файлов, дополнительные данные не регистрируются. Чтобы избежать превышения этого ограничения, выполните оптимизацию или настройте хранение в таблице, удалив старые данные. Чтобы проверить количество файлов в таблице, выполните команду
DESCRIBE DETAIL <catalog>.<schema>.<payload_table>.
Общие ограничения конечных точек обслуживания модели см. в разделе "Ограничения службы моделей" и "Регионы".
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по