Использование Databricks SQL в задании Azure Databricks
Тип задачи SQL можно использовать в задании Azure Databricks, позволяя создавать, планировать, работать и отслеживать рабочие процессы, в том числе объекты Databricks SQL, такие как запросы, устаревшие панели мониторинга и оповещения. Например, рабочий процесс может получать данные, подготавливать данные, выполнять анализ с помощью запросов Databricks SQL, а затем отображать результаты на устаревшей панели мониторинга.
В этой статье представлен пример рабочего процесса, который создает устаревшую панель мониторинга, отображающую метрики для вкладов GitHub. В этом примере вы будете:
- Прием данных GitHub с помощью скрипта Python и REST API GitHub.
- Преобразуйте данные GitHub с помощью конвейера разностных динамических таблиц.
- Активируйте запросы Databricks SQL, выполняющие анализ подготовленных данных.
- Отображение анализа на устаревшей панели мониторинга.
Перед началом работы
Для выполнения данного пошагового руководства необходимо следующее:
- Личный маркер доступа GitHub. Этот маркер должен иметь разрешение на репозиторий.
- Бессерверное хранилище SQL или хранилище pro SQL. См . типы хранилища SQL.
- Область секрета Databricks. Область секрета используется для безопасного хранения токена GitHub. См . шаг 1. Хранение маркера GitHub в секрете.
Шаг 1. Хранение маркера GitHub в секрете
Вместо жесткого ввода учетных данных, таких как GitHub персональный маркер доступа в задании, Databricks рекомендует использовать секретную область для безопасного хранения секретов и управления ими. Следующие команды CLI Databricks — это пример создания области секрета и хранения маркера GitHub в секрете в этой области:
databricks secrets create-scope <scope-name>
databricks secrets put-secret <scope-name> <token-key> --string-value <token>
- Замените
<scope-nameименем области секрета Azure Databricks для хранения маркера. - Замените
<token-key>именем ключа, назначаемого маркеру. - Замените
<token>значением личного маркера доступа GitHub.
Шаг 2. Создание скрипта для получения данных GitHub
Следующий скрипт Python использует REST API GitHub для получения данных о фиксациях и вкладах из репозитория GitHub. Входные аргументы указывают репозиторий GitHub. Записи сохраняются в расположении в DBFS, указанном другим входным аргументом.
В этом примере dbFS используется для хранения скрипта Python, но вы также можете использовать папки Databricks Git или файлы рабочей области для хранения скрипта и управления им.
Сохраните этот скрипт в расположении на локальном диске:
import json import requests import sys api_url = "https://api.github.com" def get_commits(owner, repo, token, path): page = 1 request_url = f"{api_url}/repos/{owner}/{repo}/commits" more = True get_response(request_url, f"{path}/commits", token) def get_contributors(owner, repo, token, path): page = 1 request_url = f"{api_url}/repos/{owner}/{repo}/contributors" more = True get_response(request_url, f"{path}/contributors", token) def get_response(request_url, path, token): page = 1 more = True while more: response = requests.get(request_url, params={'page': page}, headers={'Authorization': "token " + token}) if response.text != "[]": write(path + "/records-" + str(page) + ".json", response.text) page += 1 else: more = False def write(filename, contents): dbutils.fs.put(filename, contents) def main(): args = sys.argv[1:] if len(args) < 6: print("Usage: github-api.py owner repo request output-dir secret-scope secret-key") sys.exit(1) owner = sys.argv[1] repo = sys.argv[2] request = sys.argv[3] output_path = sys.argv[4] secret_scope = sys.argv[5] secret_key = sys.argv[6] token = dbutils.secrets.get(scope=secret_scope, key=secret_key) if (request == "commits"): get_commits(owner, repo, token, output_path) elif (request == "contributors"): get_contributors(owner, repo, token, output_path) if __name__ == "__main__": main()Отправьте скрипт в DBFS:
- Перейдите на целевую страницу Azure Databricks и щелкните "
 Каталог" на боковой панели.
Каталог" на боковой панели. - Нажмите кнопку "Обзор DBFS".
- В браузере файлов DBFS нажмите кнопку "Отправить". Откроется диалоговое окно "Отправка данных в DBFS ".
- Введите путь в DBFS для хранения скрипта, нажмите кнопку "Удалить файлы", чтобы отправить, или щелкните, чтобы просмотреть и выбрать скрипт Python.
- Нажмите кнопку Готово.
- Перейдите на целевую страницу Azure Databricks и щелкните "
Шаг 3. Создание конвейера разностных динамических таблиц для обработки данных GitHub
В этом разделе вы создадите конвейер разностных динамических таблиц для преобразования необработанных данных GitHub в таблицы, которые можно проанализировать с помощью запросов SQL Databricks. Чтобы создать конвейер, выполните следующие действия.
На боковой панели нажмите кнопку "Создать" и выберите
 "Записная книжка" в меню. Откроется диалоговое окно Создание записной книжки.
"Записная книжка" в меню. Откроется диалоговое окно Создание записной книжки.В языке по умолчанию введите имя и выберите Python. Для параметра Кластер можно оставить значение по умолчанию. Перед запуском конвейера среда выполнения Delta Live Tables создает кластер.
Нажмите кнопку Создать.
Скопируйте пример кода Python и вставьте его в новую записную книжку. Можно добавить пример кода в одну или в несколько ячеек записной книжки.
import dlt from pyspark.sql.functions import * def parse(df): return (df .withColumn("author_date", to_timestamp(col("commit.author.date"))) .withColumn("author_email", col("commit.author.email")) .withColumn("author_name", col("commit.author.name")) .withColumn("comment_count", col("commit.comment_count")) .withColumn("committer_date", to_timestamp(col("commit.committer.date"))) .withColumn("committer_email", col("commit.committer.email")) .withColumn("committer_name", col("commit.committer.name")) .withColumn("message", col("commit.message")) .withColumn("sha", col("commit.tree.sha")) .withColumn("tree_url", col("commit.tree.url")) .withColumn("url", col("commit.url")) .withColumn("verification_payload", col("commit.verification.payload")) .withColumn("verification_reason", col("commit.verification.reason")) .withColumn("verification_signature", col("commit.verification.signature")) .withColumn("verification_verified", col("commit.verification.signature").cast("string")) .drop("commit") ) @dlt.table( comment="Raw GitHub commits" ) def github_commits_raw(): df = spark.read.json(spark.conf.get("commits-path")) return parse(df.select("commit")) @dlt.table( comment="Info on the author of a commit" ) def commits_by_author(): return ( dlt.read("github_commits_raw") .withColumnRenamed("author_date", "date") .withColumnRenamed("author_email", "email") .withColumnRenamed("author_name", "name") .select("sha", "date", "email", "name") ) @dlt.table( comment="GitHub repository contributors" ) def github_contributors_raw(): return( spark.readStream.format("cloudFiles") .option("cloudFiles.format", "json") .load(spark.conf.get("contribs-path")) )На боковой панели щелкните
 "Рабочие процессы", перейдите на вкладку "Разностные динамические таблицы" и нажмите кнопку "Создать конвейер".
"Рабочие процессы", перейдите на вкладку "Разностные динамические таблицы" и нажмите кнопку "Создать конвейер". Укажите имя конвейера, например
Transform GitHub data.В поле библиотек записной книжки введите путь к записной книжке или щелкните
 , чтобы выбрать записную книжку.
, чтобы выбрать записную книжку.Нажмите кнопку "Добавить конфигурацию". В текстовом
Keyполе введитеcommits-path. В текстовомValueполе введите путь к DBFS, в котором записываются записи GitHub. Это может быть любой путь, который вы выбрали, и это тот же путь, который вы будете использовать при настройке первой задачи Python при создании рабочего процесса.Снова нажмите кнопку "Добавить конфигурацию ". В текстовом
Keyполе введитеcontribs-path. В текстовомValueполе введите путь к DBFS, в котором записываются записи GitHub. Это может быть любой путь, который вы выбрали, и это тот же путь, который вы будете использовать при настройке второй задачи Python при создании рабочего процесса.В поле "Целевой " введите целевую базу данных, например
github_tables. Установка целевой базы данных публикует выходные данные в хранилище метаданных и требуется для подчиненных запросов, анализируемых данными, созданными конвейером.Нажмите кнопку Сохранить.
Шаг 4. Создание рабочего процесса для приема и преобразования данных GitHub
Прежде чем анализировать и визуализировать данные GitHub с помощью Databricks SQL, необходимо принять и подготовить данные. Чтобы создать рабочий процесс для выполнения этих задач, выполните следующие действия.
Создание задания Azure Databricks и добавление первой задачи
Перейдите на целевую страницу Azure Databricks и выполните одно из следующих действий:
- На боковой панели щелкните "Рабочие процессы" и щелкните .

- На боковой панели нажмите кнопку "Создать " и выберите "Задание " в меню.
- На боковой панели щелкните "Рабочие процессы" и щелкните .
В диалоговом окне задачи, которое отображается на вкладке "Задачи ", замените имя задания... именем задания, например
GitHub analysis workflow.В поле "Имя задачи" введите имя задачи, например
get_commits.В поле " Тип" выберите скрипт Python.
В источнике выберите DBFS /S3.
В поле Path введите путь к скрипту в DBFS.
В параметрах введите следующие аргументы для скрипта Python:
["<owner>","<repo>","commits","<DBFS-output-dir>","<scope-name>","<github-token-key>"]- Замените
<owner>именем владельца репозитория. Например, чтобы получить записи изgithub.com/databrickslabs/overwatchрепозитория, введитеdatabrickslabs. - Замените
<repo>именем репозитория, напримерoverwatch. - Замените
<DBFS-output-dir>путь в DBFS для хранения записей, полученных из GitHub. - Замените
<scope-name>именем области секрета, созданной для хранения маркера GitHub. - Замените
<github-token-key>именем ключа, назначенного маркеру GitHub.
- Замените
Нажмите кнопку " Сохранить задачу".
Добавление другой задачи
Щелкните
 под только что созданной задачей.
под только что созданной задачей.В поле "Имя задачи" введите имя задачи, например
get_contributors.Введите тип задачи скрипта Python.
В источнике выберите DBFS /S3.
В поле Path введите путь к скрипту в DBFS.
В параметрах введите следующие аргументы для скрипта Python:
["<owner>","<repo>","contributors","<DBFS-output-dir>","<scope-name>","<github-token-key>"]- Замените
<owner>именем владельца репозитория. Например, чтобы получить записи изgithub.com/databrickslabs/overwatchрепозитория, введитеdatabrickslabs. - Замените
<repo>именем репозитория, напримерoverwatch. - Замените
<DBFS-output-dir>путь в DBFS для хранения записей, полученных из GitHub. - Замените
<scope-name>именем области секрета, созданной для хранения маркера GitHub. - Замените
<github-token-key>именем ключа, назначенного маркеру GitHub.
- Замените
Нажмите кнопку " Сохранить задачу".
Добавление задачи для преобразования данных
- Щелкните под только что созданной задачей.
- В поле "Имя задачи" введите имя задачи, например
transform_github_data. - В поле "Тип" выберите конвейер delta Live Tables и введите имя для задачи.
- В конвейере выберите конвейер, созданный на шаге 3. Создайте конвейер разностных динамических таблиц для обработки данных GitHub.
- Нажмите кнопку Создать.
Шаг 5. Запуск рабочего процесса преобразования данных
Щелкните  , чтобы запустить рабочий процесс. Чтобы просмотреть сведения о выполнении, щелкните ссылку в столбце "Время начала" для запуска в представлении выполнения задания. Щелкните каждую задачу, чтобы просмотреть сведения о выполнении задачи.
, чтобы запустить рабочий процесс. Чтобы просмотреть сведения о выполнении, щелкните ссылку в столбце "Время начала" для запуска в представлении выполнения задания. Щелкните каждую задачу, чтобы просмотреть сведения о выполнении задачи.
Шаг 6. (Необязательно) Чтобы просмотреть выходные данные после завершения выполнения рабочего процесса, выполните следующие действия.
- В представлении сведений о выполнении щелкните задачу "Разностные динамические таблицы".
- На панели сведений о выполнении задачи щелкните имя конвейера в разделе "Конвейер". Появится страница Сведения о конвейере.
- Выберите таблицу
commits_by_authorв DAG конвейера. - Щелкните имя таблицы рядом с хранилищем метаданных на панели commits_by_author . Откроется страница обозревателя каталогов.
В обозревателе каталогов можно просмотреть схему таблицы, примеры данных и другие сведения о данных. Выполните те же действия, чтобы просмотреть данные для github_contributors_raw таблицы.
Шаг 7. Удаление данных GitHub
В реальном приложении вы можете постоянно прием и обработку данных. Так как этот пример загружает и обрабатывает весь набор данных, необходимо удалить уже скачанные данные GitHub, чтобы предотвратить ошибку при повторном запуске рабочего процесса. Чтобы удалить скачанные данные, выполните следующие действия.
Создайте записную книжку и введите следующие команды в первой ячейке:
dbutils.fs.rm("<commits-path", True) dbutils.fs.rm("<contributors-path", True)Замените
<commits-path>и<contributors-path>на пути DBFS, настроенные при создании задач Python.Щелкните и выберите
 "Выполнить ячейку".
"Выполнить ячейку".
Эту записную книжку также можно добавить в рабочий процесс.
Шаг 8. Создание запросов SQL Databricks
После выполнения рабочего процесса и создания необходимых таблиц создайте запросы для анализа подготовленных данных. Чтобы создать примеры запросов и визуализаций, выполните следующие действия.
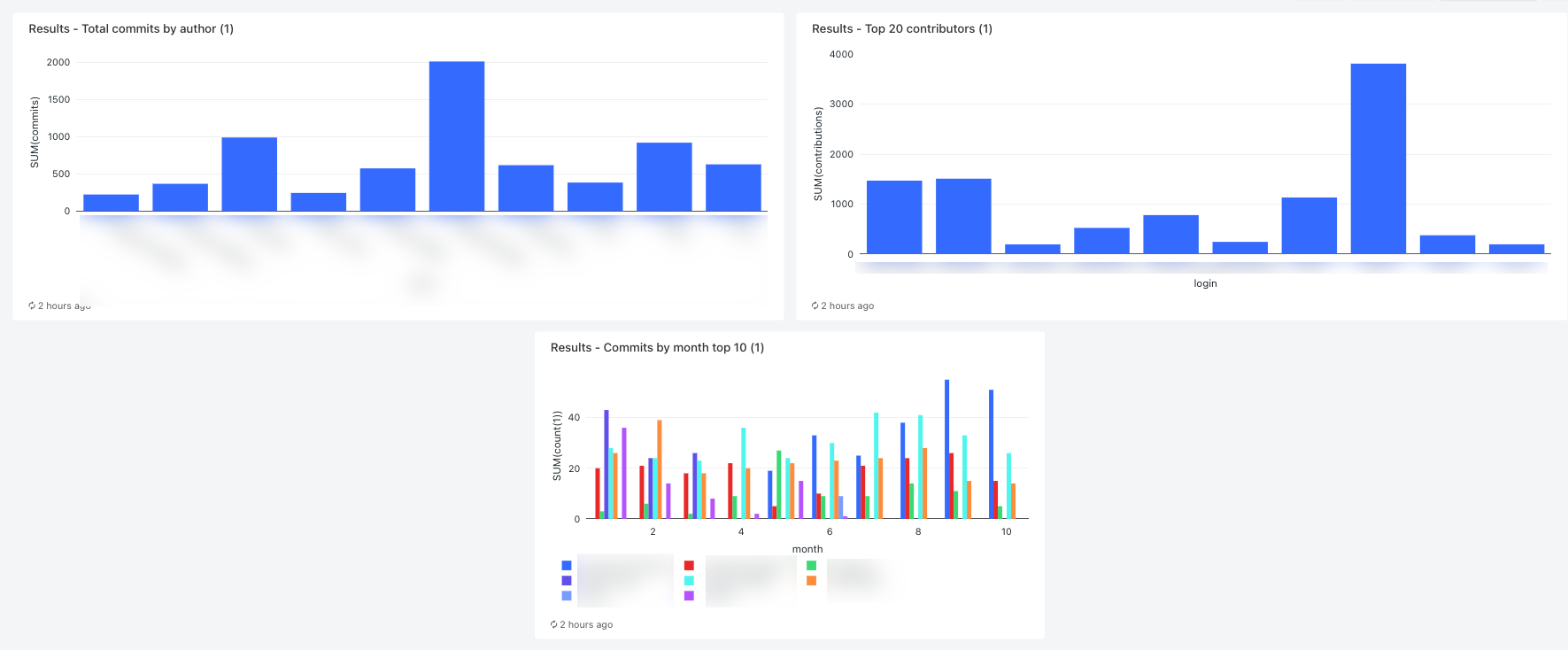
Отображение первых 10 участников по месяцам
Щелкните значок под логотипом
 Databricks на боковой панели и выберите SQL.
Databricks на боковой панели и выберите SQL.Нажмите кнопку "Создать запрос ", чтобы открыть редактор sql-запросов Databricks.
Убедитесь, что для каталога задано значение hive_metastore. Щелкните по умолчанию рядом с hive_metastore и задайте для базы данных значение Target , заданное в конвейере Delta Live Tables.
На вкладке "Создать запрос" введите следующий запрос:
SELECT date_part('YEAR', date) AS year, date_part('MONTH', date) AS month, name, count(1) FROM commits_by_author WHERE name IN ( SELECT name FROM commits_by_author GROUP BY name ORDER BY count(name) DESC LIMIT 10 ) AND date_part('YEAR', date) >= 2022 GROUP BY name, year, month ORDER BY year, month, nameЩелкните вкладку "Создать запрос" и переименуйте запрос, например
Commits by month top 10 contributors.По умолчанию результаты отображаются в виде таблицы. Чтобы изменить способ визуализации данных, например с помощью линейчатой диаграммы, на панели результатов щелкните и нажмите
 кнопку " Изменить".
кнопку " Изменить".В типе визуализации выберите панель.
В столбце X выберите месяц.
В столбцах Y выберите count(1).
В группе по имени.
Нажмите кнопку Сохранить.
Отображение первых 20 участников
Нажмите кнопку +>Создать запрос и убедитесь, что для каталога задано значение hive_metastore. Щелкните по умолчанию рядом с hive_metastore и задайте для базы данных значение Target , заданное в конвейере Delta Live Tables.
Введите следующий запрос:
SELECT login, cast(contributions AS INTEGER) FROM github_contributors_raw ORDER BY contributions DESC LIMIT 20Щелкните вкладку "Создать запрос" и переименуйте запрос, например
Top 20 contributors.Чтобы изменить визуализацию из таблицы по умолчанию, на панели результатов нажмите кнопку
" Изменить".В типе визуализации выберите панель.
В столбце X выберите имя входа.
В столбцах Y выберите вклад.
Нажмите кнопку Сохранить.
Отображение общих фиксаций по автору
Нажмите кнопку +>Создать запрос и убедитесь, что для каталога задано значение hive_metastore. Щелкните по умолчанию рядом с hive_metastore и задайте для базы данных значение Target , заданное в конвейере Delta Live Tables.
Введите следующий запрос:
SELECT name, count(1) commits FROM commits_by_author GROUP BY name ORDER BY commits DESC LIMIT 10Щелкните вкладку "Создать запрос" и переименуйте запрос, например
Total commits by author.Чтобы изменить визуализацию из таблицы по умолчанию, на панели результатов нажмите кнопку
" Изменить".В типе визуализации выберите панель.
В столбце X выберите имя.
В столбцах Y выберите фиксации.
Нажмите кнопку Сохранить.
Шаг 9. Создание панели мониторинга
- На боковой панели щелкните
 панели мониторинга
панели мониторинга - Нажмите кнопку " Создать панель мониторинга".
- Введите имя панели мониторинга, например
GitHub analysis. - Для каждого запроса и визуализации, созданного на шаге 8. Создайте запросы SQL Databricks, нажмите кнопку "Добавить > визуализацию " и выберите каждую визуализацию.
Шаг 10. Добавление задач SQL в рабочий процесс
Чтобы добавить новые задачи запроса в рабочий процесс, созданный в процессе создания задания Azure Databricks, и добавить первую задачу для каждого запроса, созданного на шаге 8. Создание запросов SQL Databricks:
- Щелкните рабочие процессы на боковой панели.
- В столбце Имя нажмите на имя задания.
- Перейдите на вкладку "Задачи ".
- Щелкните под последней задачей.
- Введите имя задачи, введите в поле "Тип SQL" и в задаче SQL выберите запрос.
- Выберите запрос в SQL-запросе.
- В хранилище SQL выберите бессерверное хранилище SQL или хранилище pro SQL для выполнения задачи.
- Нажмите кнопку Создать.
Шаг 11. Добавление задачи панели мониторинга
- Щелкните под последней задачей.
- Введите имя задачи в поле "Тип", выберите SQL и в задаче SQL выберите панель мониторинга прежних версий.
- Выберите панель мониторинга, созданную на шаге 9. Создание панели мониторинга.
- В хранилище SQL выберите бессерверное хранилище SQL или хранилище pro SQL для выполнения задачи.
- Нажмите кнопку Создать.
Шаг 12. Запуск полного рабочего процесса
Чтобы запустить рабочий процесс, нажмите кнопку . Чтобы просмотреть сведения о выполнении, щелкните ссылку в столбце "Время начала" для запуска в представлении выполнения задания.
Шаг 13. Просмотр результатов
Чтобы просмотреть результаты после завершения выполнения, щелкните окончательную задачу панели мониторинга и щелкните имя панели мониторинга в области мониторинга SQL в правой панели.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по