Автоматическое масштабирование HDInsight в кластерах AKS
Внимание
Эта функция в настоящее время доступна для предварительного ознакомления. Дополнительные условия использования для предварительных версий Microsoft Azure включают более юридические термины, применимые к функциям Azure, которые находятся в бета-версии, в предварительной версии или в противном случае еще не выпущены в общую доступность. Сведения об этой конкретной предварительной версии см. в статье Azure HDInsight в предварительной версии AKS. Для вопросов или предложений функций отправьте запрос на AskHDInsight с подробными сведениями и следуйте за нами для получения дополнительных обновлений в сообществе Azure HDInsight.
Размер любого кластера для удовлетворения производительности заданий и управления затратами впереди всегда сложно и трудно определить! Одним из прибыльных преимуществ строительства озера данных по сравнению с Облаком является его эластичность, что означает использование функции автомасштабирования для максимально эффективного использования ресурсов на руках. Автомасштабирование с помощью Kubernetes является одним из ключей для создания оптимизированной для затрат экосистемы. С различными шаблонами использования в любом предприятии могут быть вариации нагрузок кластера с течением времени, которые могут привести к недостаточной подготовке кластеров (неуправляемой производительности) или чрезмерной подготовке (ненужные затраты из-за простоя ресурсов).
Функция автомасштабирования, предлагаемая в HDInsight в AKS, может автоматически увеличивать или уменьшать количество рабочих узлов в кластере. Автомасштабирование использует метрики кластера и политику масштабирования, используемую клиентами.
Эта функция хорошо подходит для критически важных рабочих нагрузок, которые могут иметь
- Переменные или непредсказуемые шаблоны трафика и требуют соглашения об уровне обслуживания для высокой производительности и масштабирования или
- Предопределенное расписание для обеспечения доступности необходимых рабочих узлов для успешного выполнения заданий в кластере.
Автоматическое масштабирование с помощью HDInsight в кластерах AKS делает кластеры экономичными и эластичными в Azure.
С помощью автоматического масштабирования клиенты могут уменьшать масштаб кластеров, не затрагивая рабочие нагрузки. Она включена с расширенными возможностями, такими как льготный период списания и охлаждения. Эти возможности позволяют пользователям принимать обоснованные решения о добавлении и удалении узлов на основе текущей нагрузки кластера.
Принцип работы
Эта функция работает путем масштабирования числа узлов в предустановленных ограничениях на основе метрик кластера или определенного расписания операций масштабирования и уменьшения масштаба. Существует два типа условий для активации событий автомасштабирования: триггеры на основе порога для различных метрик производительности кластера (называется масштабированием на основе нагрузки) и триггеров на основе времени (называется масштабированием на основе расписания).
Масштабирование на основе нагрузки изменяет количество узлов в кластере в пределах заданного диапазона с целью обеспечения оптимального использования ЦП и снижения стоимости владения.
Масштабирование на основе расписания изменяет количество узлов в кластере на основе расписания операций увеличения и уменьшения масштаба.
Примечание.
Автоматическое масштабирование не поддерживает изменение типа SKU существующего кластера.
Совместимость кластера
В следующей таблице описываются типы кластеров, совместимые с функцией автомасштабирования, и доступные или запланированные.
| Рабочая нагрузка | Загрузка на основе | На основе расписания |
|---|---|---|
| Flink | Плановое | Да |
| Трино | Да** | Да** |
| Spark | Да** | Да** |
**Грациозная отмена эксплуатации настраивается.
Методы масштабирования
Масштабирование на основе расписания:
Если задания должны выполняться по фиксированным расписаниям и в течение прогнозируемой длительности или когда ожидается низкое использование в течение определенного времени дня, например тестовые среды и среды разработки в рабочих часах после работы, задания окончания дня.

Масштабирование на основе нагрузки:
Когда шаблоны нагрузки существенно и непредсказуемо изменяются в течение дня, например заказ обработки данных с случайными колебаниями шаблонов нагрузки на основе различных факторов.

С помощью нового параметра правила масштабирования можно настроить правила масштабирования.
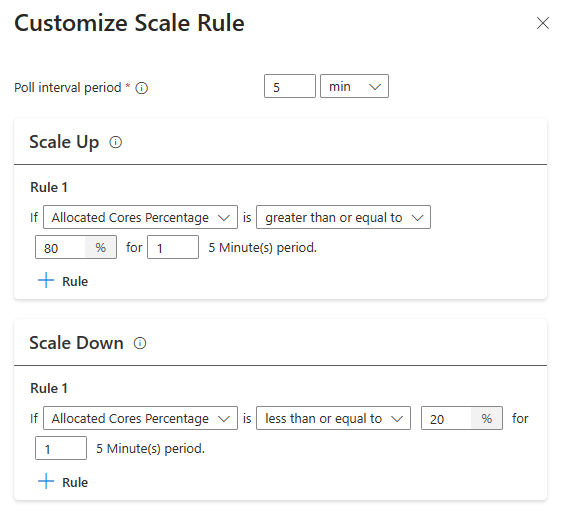
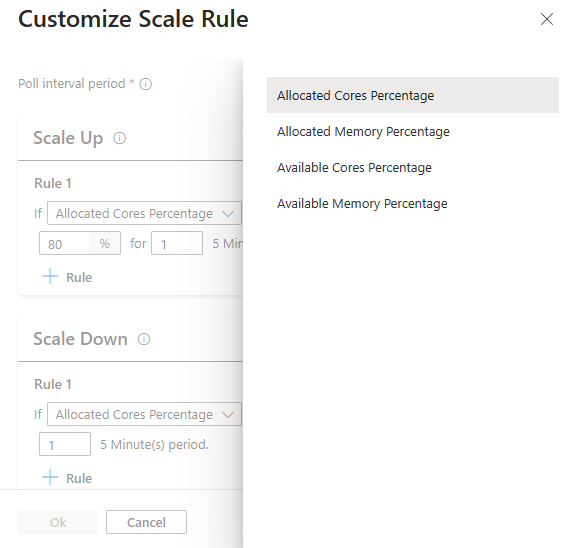
Совет
- Правила масштабирования имеют приоритет при активации одного или нескольких правил. Даже если только одно из правил для увеличения масштаба предлагаемого кластера не подготовлено, кластер попытается увеличить масштаб. Для уменьшения масштаба не следует активировать правило увеличения масштаба.


Условия масштабирования на основе нагрузки
При обнаружении следующих условий автоматическое масштабирование выдает запрос на масштабирование
| Вертикальное масштабирование | Вертикальное уменьшение масштаба |
|---|---|
| Выделенные ядра больше 80 % для интервала опроса 5 минут (1-минутный проверка период) | Выделенные ядра меньше или равны 20% для интервала опроса в 5 минут (1 минуты проверка период) |
Для горизонтального масштабирования автоматически возникает запрос на масштабирование, чтобы добавить требуемое количество узлов. Увеличение масштаба зависит от числа новых рабочих узлов, необходимого для удовлетворения текущих требований к ЦП и памяти. Это значение ограничено максимальным числом рабочих узлов.
Для уменьшения масштаба автоматически выполняется запрос на удаление некоторых узлов. Рекомендации по масштабированию включают количество модулей pod на узел, текущие требования к ЦП и памяти, а также рабочие узлы, которые являются кандидатами на удаление на основе текущего выполнения задания. При вертикальном уменьшении масштаба сначала узлы выводятся из эксплуатации, а затем они удаляются из кластера.
Внимание
Модуль правил автомасштабирования заранее очищает старые события каждые 30 минут для оптимизации системной памяти. В результате на интервале правила масштабирования существует ограничение верхнего предела в 30 минут. Чтобы обеспечить согласованный и надежный триггер действий масштабирования, необходимо задать интервал правила масштабирования значением, которое меньше предела. Следуя этому руководству, вы можете гарантировать гладкий и эффективный процесс масштабирования, эффективно управляя системными ресурсами.
Метрики кластера
Автоматическое масштабирование постоянно отслеживает кластер и собирает следующие метрики для автомасштабирования на основе нагрузки:
Метрики кластера, доступные для масштабирования
| Метрическая | Description |
|---|---|
| Процент доступных ядер | Общее количество ядер, доступных в кластере, по сравнению с общим количеством ядер в кластере. |
| Процент доступной памяти | Общая память (в МБ), доступная в кластере по сравнению с общим объемом памяти в кластере. |
| Процент выделенных ядер | Общее количество ядер, выделенных в кластере, по сравнению с общим количеством ядер в кластере. |
| Процент выделенной памяти | Объем памяти, выделенной в кластере, по сравнению с общим объемом памяти в кластере. |
По умолчанию указанные выше метрики проверка каждые 300 секунд, он также настраивается при настройке интервала опроса с параметром автомасштабирования. Автоматическое масштабирование принимает решения по масштабированию или уменьшению масштаба на основе этих метрик.
Примечание.
По умолчанию автомасштабирование использует калькулятор ресурсов по умолчанию для YARN для Apache Spark. Масштабирование на основе нагрузки доступно для кластеров Apache Spark.
Грациозное списание
Предприятиям нужны способы достижения масштабирования петабайтов с помощью автомасштабирования и вывода ресурсов из эксплуатации, когда они больше не нужны. В таких случаях удобно использовать функцию вывода из эксплуатации.
Грациозное списание позволяет заданиям выполняться даже после того, как автомасштабирование активировало списание рабочих узлов. Эта функция позволяет узлам продолжать подготовку до завершения заданий.
Trino : рабочие имеют грациозную отмену эксплуатации, включенную по умолчанию. Координатор позволяет завершать работу рабочей роли в течение заданного времени перед удалением рабочей роли из кластера. Вы можете настроить время ожидания с помощью собственного параметра
shutdown.grace-periodTrino или на странице конфигурации службы портал Azure.Apache Spark : уменьшение масштаба может повлиять на все выполняемые задания в кластере. Если в портал Azure включена функция "Благостная отмена эксплуатации", она включает в себя удостоверение узлов YARN и гарантирует, что все действия, выполняемые на рабочем узле, завершены до удаления узла из HDInsight в кластере AKS.
Период охлаждения
Чтобы избежать непрерывных операций масштабирования, подсистема автомасштабирования ожидает настраиваемого интервала перед инициированием другого набора операций масштабирования. Значение по умолчанию — 180 секунд
Примечание.
- В пользовательских правилах масштабирования триггер правил не может иметь интервал триггера, превышающий 30 минут. После автоматического масштабирования события время ожидания перед применением другой политики масштабирования.
- Период охлаждения должен быть больше интервала политики, поэтому метрики кластера могут сбросить.
Начать
Для автоматического масштабирования необходимо назначить владельца или участник разрешение MSI (используемое во время создания кластера) на уровне кластера с помощью IAM на левой панели.
Ознакомьтесь со следующим рисунком и инструкциями по добавлению назначения ролей
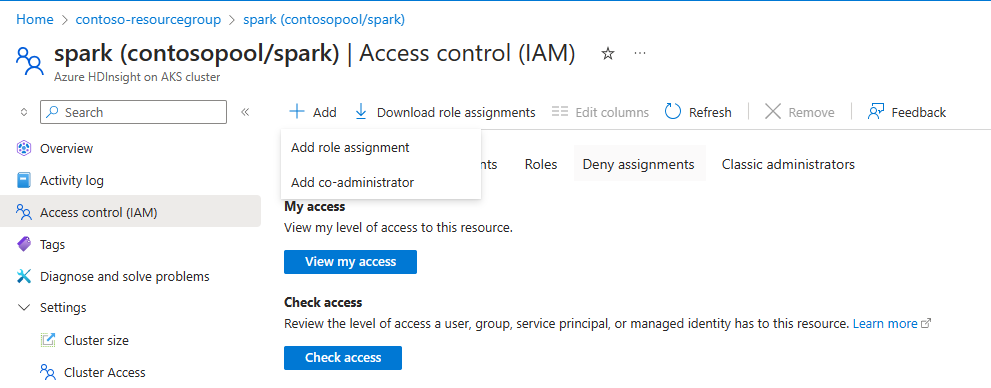
Выберите назначение роли,
- Тип назначения: роли привилегированного администратора
- Роль: владелец или участник
- Участники: выберите управляемое удостоверение и выберите управляемое удостоверение, назначаемое пользователем, которое было дано на этапе создания кластера.
- Назначьте роль.

Создание кластера с автоматическим масштабированием на основе расписания
После создания пула кластеров создайте кластер с требуемой рабочей нагрузкой (в типе кластера) и выполните другие действия в рамках обычного процесса создания кластера.
На вкладке "Конфигурация" включите переключатель автомасштабирования .
Выбор автомасштабирования на основе расписания
Выберите часовой пояс и нажмите кнопку +Добавить правило
Выберите дни недели, к которым должно применяться новое условие.
Измените время вступления условия в силу и число узлов, до которого необходимо масштабировать кластер.
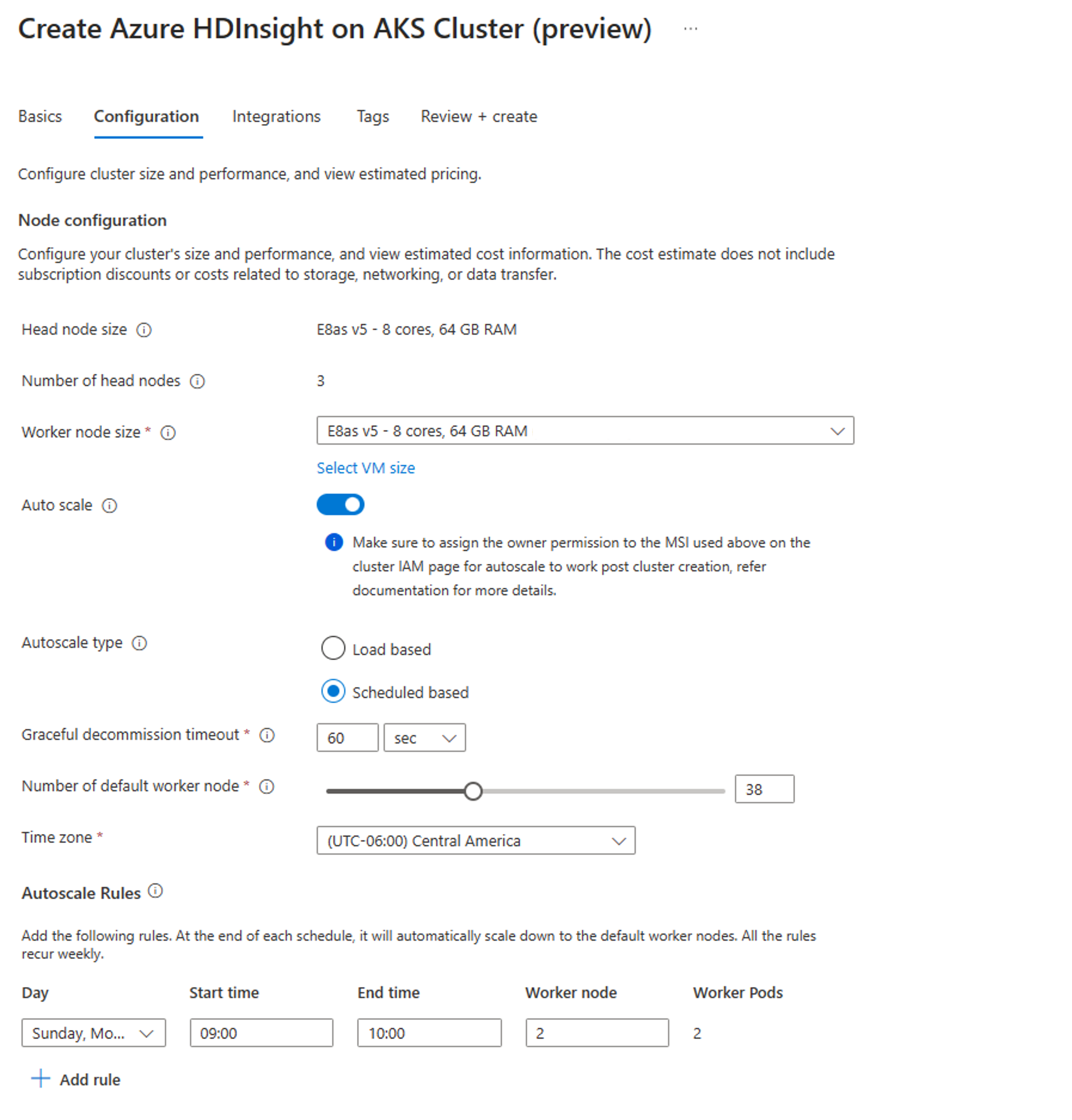
Примечание.
- У пользователя должна быть роль "владелец" или "участник" в MSI кластера для автоматического масштабирования.
- Это стандартное значение определяет начальный размер кластера при его создании.
- Разница между двумя расписаниями устанавливается по умолчанию на 30 минут.
- Значение времени соответствует формату 24 часа
- В случае непрерывного периода продолжительностью более 24 часов в течение нескольких дней необходимо установить расписание автомасштабирования по дням, при этом автомасштабирование предполагает 23:59 как 00:00 (с тем же количеством узлов), охватывающее два дня с 22:00 до 23:59, с 00:00 до 02:00 как 22:00 до 02:00.
- Расписания задаются по умолчанию в формате UTC. Вы всегда можете выбрать другой часовой пояс в раскрывающемся списке, который будет соответствовать вашему региону. Если вы находитесь в часовом поясе, который наблюдает Daylight Savings, расписание не настраивается автоматически, необходимо управлять обновлениями расписания соответствующим образом.

Создание кластера с автомасштабированием на основе нагрузки
После создания пула кластеров создайте кластер с требуемой рабочей нагрузкой (в типе кластера) и выполните другие действия в рамках обычного процесса создания кластера.
На вкладке "Конфигурация" включите переключатель автомасштабирования .
Выбор автомасштабирования на основе нагрузки
В зависимости от типа рабочей нагрузки у вас есть варианты добавления времени ожидания вывода из эксплуатации, периода охлаждения
Выберите минимальные и максимальные узлы и при необходимости настройте правила масштабирования для настройки автоматического масштабирования в соответствии с вашими потребностями.

Совет
- Ваша подписка имеет квоту емкости для каждого региона. Общее число ядер на головных узлах в сочетании с максимальным числом рабочих узлов не может превышать квоту емкости. Тем не менее эта квота — нестрогое ограничение. Вы всегда можете создать запрос в службу поддержки, чтобы легко ее повысить.
- Если превышен общий предел квоты ядра, вы получите сообщение
The maximum node count you can select is {maxCount} due to the remaining quota in the selected subscription ({remaining} cores)об ошибке. - Правила масштабирования имеют приоритет при активации одного или нескольких правил. Даже если только одно из правил для увеличения масштаба предлагаемого кластера не подготовлено, кластер попытается увеличить масштаб. Для уменьшения масштаба не следует активировать правило увеличения масштаба.
- В общедоступной предварительной версии HDInsight в AKS поддерживает до 500 узлов в кластере.

Создание кластера с помощью шаблона Resource Manager
Автоматическое масштабирование на основе расписания
Вы можете создать HDInsight в кластере AKS с автоматическим масштабированием на основе расписаний с помощью шаблона Azure Resource Manager, добавив автомасштабирование в кластерProfile —> раздел autoscaleProfile.
Узел автомасштабирования содержит повторение, содержащее часовой пояс и расписание, описывающее, когда происходит изменение. Полный шаблон Resource Manager см. в примере JSON
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "ScheduleBased",
"gracefulDecommissionTimeout": 60,
"scheduleBasedConfig": {
"schedules": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday"
],
"startTime": "09:00",
"endTime": "10:00",
"count": 2
},
{
"days": [
"Sunday",
"Saturday"
],
"startTime": "12:00",
"endTime": "22:00",
"count": 5
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "22:00",
"endTime": "23:59",
"count": 6
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "00:00",
"endTime": "05:00",
"count": 6
}
],
"timeZone": "UTC",
"defaultCount": 110
}
}
}
Совет
- Чтобы избежать сбоев операций масштабирования, необходимо задать не конфликтующие расписания с помощью развертываний ARM.
Автомасштабирование на основе нагрузки
Вы можете создать HDInsight в кластере AKS с автомасштабированием на основе нагрузки с помощью шаблона Azure Resource Manager, добавив автомасштабирование в кластерProfile —> раздел autoscaleProfile.
Узел автомасштабирования содержит
- интервал опроса, период охлаждения,
- грациозное списание,
- минимальные и максимальные узлы,
- стандартные правила порогового значения,
- Масштабирование метрик, описывающих, когда происходит изменение.
Полный шаблон Resource Manager см. в примере JSON, как показано ниже.
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "LoadBased",
"gracefulDecommissionTimeout": 60,
"loadBasedConfig": {
"minNodes": 2,
"maxNodes": 157,
"pollInterval": 300,
"cooldownPeriod": 180,
"scalingRules": [
{
"actionType": "scaleup",
"comparisonRule": {
"threshold": 80,
"operator": " greaterThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
},
{
"actionType": "scaledown",
"comparisonRule": {
"threshold": 20,
"operator": " lessThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
}
]
}
}
}
Использование REST API
Чтобы включить или отключить автомасштабирование в работающем кластере с помощью REST API, выполните запрос PATCH к конечной точке автомасштабирования: https://management.azure.com/subscriptions/{{USER_SUB}}/resourceGroups/{{USER_RG}}/providers/Microsoft.HDInsight/clusterpools/{{CLUSTER_POOL_NAME}}/clusters/{{CLUSTER_NAME}}?api-version={{HILO_API_VERSION}}
- Используйте в полезных данных запроса надлежащие параметры. Полезные данные json можно использовать для включения автоматического масштабирования.
- Используйте полезные данные (autoscaleProfile: NULL) или используйте флаг (включено, false), чтобы отключить автомасштабирование.
- Дополнительные сведения см. в примерах JSON, упоминание приведенных выше.
Приостановка автоматического масштабирования для работающего кластера
Мы представили функцию приостановки в автоматическом масштабировании. Теперь с помощью портал Azure можно приостановить автомасштабирование в работающем кластере. На следующей схеме показано, как выбрать приостановку и возобновить автомасштабирование

Вы можете возобновить работу после возобновления операций автомасштабирования.

Совет
При настройке нескольких расписаний и приостановке автомасштабирования он не активирует следующее расписание. Число узлов остается одинаковым, даже если узлы находятся в отключенном состоянии.
Копирование конфигураций автомасштабирования
Используя портал Azure, теперь можно скопировать те же конфигурации автомасштабирования для одной и той же фигуры кластера в пуле кластеров, вы можете использовать эту функцию и экспортировать или импортировать те же конфигурации.

Мониторинг действий автоматического масштабирования
Состояние кластера
Состояние кластера, указанное в портал Azure, поможет отслеживать действия автомасштабирования. Все сообщения о состоянии кластера, которые могут появиться в списке.
| Состояние кластера | Description |
|---|---|
| Выполнено | Кластер работает в обычном режиме. Все предыдущие действия автомасштабирования успешно завершены. |
| Акцептировано | Операция кластера (например, увеличение масштаба) принимается, ожидая завершения операции. |
| Неудачно | Это означает, что текущая операция завершилась ошибкой из-за какой-то причины, кластер, возможно, не работает. |
| Отменено | Текущая операция отменяется. |
Чтобы просмотреть текущее число узлов в кластере, откройте диаграмму Размер кластера на странице Обзор для кластера.

Журнал операций
Журнал операций увеличения и уменьшения масштаба кластера можно просматривать как часть метрик кластера. Вы также можете перечислить все действия масштабирования за последний день, неделю или другой период.

Дополнительные ресурсы