Индексаторы в поиске ИИ Azure
Индексатор в службе "Поиск ИИ Azure" — это обходчик, который извлекает текстовые данные из облачных источников данных и заполняет индекс поиска с помощью сопоставлений между исходными данными и индексом поиска. Этот подход иногда называется "моделью извлечения", так как служба поиска извлекает данные без необходимости писать код, добавляющий данные в индекс.
Индексаторы также управляют выполнением набора навыков и обогащением ИИ, где можно настроить навыки для интеграции дополнительной обработки содержимого в индекс. Ниже приведены некоторые примеры OCR для файлов изображений, навык разделения текста для фрагментирования данных, перевода текста для нескольких языков.
Индексаторы предназначены для поддерживаемых источников данных. Конфигурация индексатора указывает источник данных (источник) и индекс поиска (назначение). Несколько источников, таких как Хранилище BLOB-объектов Azure, имеют дополнительные свойства конфигурации, относящиеся к типу контента.
Вы можете запускать индексаторы по требованию или при регулярном обновлении данных, выполняемом каждые пять минут. Для более частых обновлений требуется "push-модель", которая одновременно обновляет данные как в поиске ИИ Azure, так и во внешнем источнике данных.
Служба поиска выполняет одно задание индексатора на единицу поиска. Если требуется одновременная обработка, убедитесь, что у вас достаточно реплика. Индексаторы не выполняются в фоновом режиме, поэтому можно обнаружить больше регулирования запросов, чем обычно, если служба находится под давлением.
Сценарии индексатора и варианты использования
Индексатор можно использовать в качестве единственного средства приема данных или в сочетании с другими методами. В следующей таблице перечислены основные сценарии.
| Сценарий | Стратегия |
|---|---|
| Один источник данных | Эта схема является самой простой: один источник данных служит единственным поставщиком содержимого для поискового индекса. Большинство поддерживаемых источников данных предоставляют некоторую форму обнаружения изменений, чтобы последующий индексатор запускал разницу при добавлении или обновлении содержимого в источнике. |
| Несколько источников данных | Спецификация индексатора может иметь только один источник данных, но сам индекс поиска может принимать содержимое из нескольких источников, где каждый запуск индексатора приносит новое содержимое из другого поставщика данных. Каждый источник может внести свой общий доступ к полным документам или заполнить выбранные поля в каждом документе. Дополнительные сведения об этом сценарии см. в руководстве по индексу из нескольких источников данных. |
| Несколько индексаторов | Несколько источников данных обычно связаны с несколькими индексаторами, если необходимо изменить параметры времени выполнения, расписание или сопоставления полей. Горизонтальное масштабирование между регионами в службе "Поиск ИИ Azure" — это другой сценарий. У вас могут быть копии одного поискового индекса в разных регионах. Чтобы синхронизировать содержимое индекса поиска, можно получить несколько индексаторов из одного источника данных, где каждый индексатор предназначен для разного индекса поиска в каждом регионе. Параллельное индексирование очень больших наборов данных также требует стратегии многоиндексатора, где каждый индексатор предназначен для подмножества данных. |
| Преобразование содержимого | Индексаторы управляют выполнением набора навыков и обогащением ИИ. Преобразования содержимого определяются в наборе навыков, присоединенном к индексатору. Вы можете использовать навыки для включения блокирования данных и векторизации. |
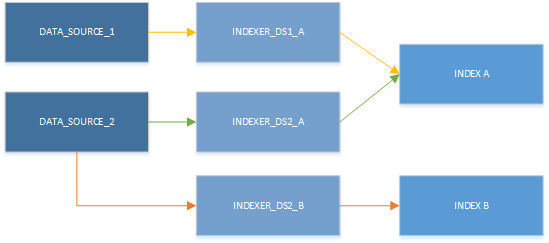
Для каждой комбинации целевого индекса и источника данных необходимо запланировать создание одного индексатора. Можно использовать несколько индексаторов, записывающих сведения в один и тот же индекс, а также повторно использовать один и тот же источник данных для нескольких индексаторов. Однако индексатор может одновременно использовать только один источник данных и записывать сведения только в один индекс. Как показано на следующем рисунке, один источник данных предоставляет входные данные для одного индексатора, который затем заполняет один индекс:

Хотя одновременно можно использовать только один индексатор, ресурсы можно использовать в разных сочетаниях. Основной вывод следующей иллюстрации заключается в том, что источник данных можно связать с несколькими индексаторами, а несколько индексаторов могут записывать в один и тот же индекс.
Поддерживаемые источники данных
Индексаторы обходят хранилища данных в Azure и за пределами Azure.
- Хранилище BLOB-объектов Azure
- Azure Cosmos DB
- Azure Data Lake Storage 2-го поколения
- База данных SQL Azure
- Хранилище таблиц Azure
- Управляемый экземпляр SQL Azure
- SQL Server на виртуальных машинах Azure
- Файлы Azure (в предварительной версии)
- Azure MySQL (предварительная версия)
- SharePoint в Microsoft 365 (в предварительной версии)
- Azure Cosmos DB для MongoDB (в предварительной версии)
- Azure Cosmos DB для Apache Gremlin (в предварительной версии)
Azure Cosmos DB для Cassandra не поддерживается.
Индексаторы принимают плоские наборы строк, такие как таблица или представление, или элементы в контейнере или папке. В большинстве случаев он создает один документ поиска для каждой строки, записи или элемента.
Подключения индексатора к удаленным источникам данных можно сделать с помощью стандартных интернет-подключений (общедоступных) или зашифрованных частных подключений при использовании общей приватной связи. Вы также можете настроить подключения для проверки подлинности с помощью управляемого удостоверения. Дополнительные сведения о безопасных подключениях см. в статье Индексатор доступа к содержимому, защищенному функциями безопасности сети Azure, и Подключение к источнику данных с помощью управляемого удостоверения.
Этапы индексирования
При начальном запуске, когда индекс пуст, индексатор считывает все данные, доступные в таблице или контейнере. При последующих запусках индексатор обычно обнаруживает и извлекает только измененные данные. Для больших двоичных объектов обнаружение изменений происходит автоматически. Для других источников данных, таких как Azure SQL или Azure Cosmos DB, необходимо включить обнаружение изменений.
Для каждого получаемого документа индексатор реализует или координирует несколько этапов: от извлечения документа до финальной выдачи в поисковую систему для индексирования. При необходимости индексатор также служит для выполнения набора навыков и генерации выходных данных (при условии, что набор навыков определен).

Этап 1. Распознавание документов
Распознавание документов — это процесс открытия файлов и извлечения содержимого. Текстовое содержимое можно извлечь из файлов в службе, строк в таблице либо элементов в контейнере или коллекции. Если вы добавляете набор навыков и навыки изображения, создание документов также может извлекать изображения и ставить их в очередь для обработки изображений.
В зависимости от источника данных индексатор попытается выполнить различные операции для извлечения потенциально индексируемого содержимого:
Если документ представляет собой файл со встроенными изображениями, такими как PDF, индексатор извлекает текст, изображения и метаданные. Индексаторы могут открывать файлы из Хранилище BLOB-объектов Azure, Azure Data Lake Storage 2-го поколения и SharePoint.
Когда документ является записью в Azure SQL, индексатор извлекает недвоичное содержимое из каждого поля в каждой записи.
Если документ является записью в Azure Cosmos DB, индексатор извлекает не двоичное содержимое из полей и подфилдов из документа Azure Cosmos DB.
Этап 2. Сопоставление полей
Индексатор извлекает текст из исходного поля и отправляет его в поле назначения в индексе или в хранилище знаний. Если имена полей и типы данных совпадают, путь очищается. Однако в выходных данных для полей можно выбрать другие имена или типы, и в этом случае необходимо сообщить индексатору, как именно следует сопоставлять поле.
Чтобы указать сопоставления полей, введите исходные и целевые поля в определении индексатора.
Сопоставление полей происходит после взлома документа, но до преобразований, когда индексатор считывается из исходных документов. При определении сопоставления полей значение исходного поля отправляется в целевое поле "как есть" без изменений.
Этап 3. Выполнение набора навыков
Выполнение набора навыков — это необязательный шаг, который вызывает встроенную или настраиваемую обработку искусственного интеллекта. Наборы навыков могут добавлять оптическое распознавание символов (OCR) или другие формы анализа изображений, если содержимое является двоичным. Наборы навыков также могут добавлять обработку естественного языка. Например, можно добавить перевод текста или извлечение ключевых фраз.
Каким бы ни было преобразование, при выполнении набора навыков происходит обогащение. Если индексатор является конвейером, набор навыков можно представить в виде "конвейера в конвейере".
Этап 4. Сопоставление полей вывода
Если вы включаете набор навыков, необходимо указать сопоставления полей выходных данных в определении индексатора. Выходные данные набора навыков манифестируются внутренне как структура дерева, называемая обогащенным документом. Сопоставления полей вывода позволяют выбрать, какие части этого дерева следует сопоставлять с полями в индексе.
Несмотря на сходство имен, сопоставления полей выходных данных и сопоставления полей создают связи из разных источников. Сопоставления полей связывают содержимое исходного поля с целевым полем в индексе поиска. Сопоставления полей вывода связывают содержимое внутреннего обогащенного документа (выходные данные навыка) с полями назначения в индексе. В отличие от сопоставлений полей, которые считаются необязательными, для любого преобразованного содержимого, которое должно находиться в индексе, требуется сопоставление выходных полей.
На изображении ниже показан пример индексатора сеанса отладки с различными этапами: распознавание документов, сопоставление полей, выполнение набора навыков и сопоставление полей вывода.

Базовый рабочий процесс
В индексаторах реализованы уникальные функции для работы с источниками данных. Поэтому тип индексатора будет определять особенности настройки источника данных или индексатора. Тем не менее всем индексаторам присущи сходные структура и требования. Ниже описаны действия, общие для всех индексаторов.
Шаг 1. Создание источника данных
Для индексаторов необходим объект источника данных, предоставляющий строку подключения и, возможно, учетные данные. Источники данных являются независимыми объектами. Несколько индексаторов могут использовать один и тот же объект источника данных для загрузки нескольких индексов одновременно.
Вы можете создать источник данных с помощью любого из следующих подходов:
- С помощью портал Azure на вкладке "Источники данных" на страницах службы поиска выберите "Добавить источник данных", чтобы указать определение источника данных.
- С помощью портал Azure мастер импорта данных выводит источник данных.
- Используя ИНТЕРФЕЙСы REST API, вызовите создание источника данных.
- С помощью пакета SDK Azure для .NET вызовите класс SearchIndexerDataSource Подключение ion
Шаг 2. Создание индекса
Хотя индексатор автоматизирует некоторые задачи, связанные с приемом данных, это обычно не распространяется на создание индекса. В качестве необходимого условия необходимо иметь предопределенный индекс, содержащий соответствующие целевые поля для любых исходных полей во внешнем источнике данных. Поля должны совпадать по имени и типу данных. В противном случае можно настроить сопоставление полей, чтобы установить связь.
Дополнительные сведения см. в разделе "Создание индекса".
Шаг 3. Создание и запуск (или планирование) индексатора
Определение индексатора состоит из свойств, уникальных для идентификации индексатора, указания источника данных и индекса для использования и предоставления других параметров конфигурации, влияющих на поведение времени выполнения, включая выполнение индексатора по запросу или по расписанию.
Все ошибки или предупреждения о доступе к данным или проверке набора навыков будут возникать во время выполнения индексатора. До запуска выполнения индексатора зависимые объекты, такие как источники данных, индексы и наборы навыков, являются пассивными в службе поиска.
Дополнительные сведения см. в разделе "Создание индексатора"
После первого запуска индексатора его можно повторно запустить по запросу или настроить расписание.
Вы можете отслеживать состояние индексатора на портале или с помощью API получения состояния индексатора. Следует также выполнить запросы к индексу для проверки соответствия результатов ожиданиям.
Индексаторы не имеют выделенных ресурсов обработки. На основе этого состояние индексаторов может отображаться как простой перед выполнением (в зависимости от других заданий в очереди) и время выполнения может не быть предсказуемым. Другие факторы определяют производительность индексатора, например размер документа, сложность документа, анализ изображений, среди прочего.
Следующие шаги
Теперь, когда вы познакомились с индексаторами, следующим шагом является просмотр свойств и параметров индексатора, планирования и мониторинга индексатора. Кроме того, можно вернуться к списку поддерживаемых источников данных, чтобы узнать больше о конкретном источнике.