Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Итоги
Azure HDInsight является одной из самых популярных среди корпоративных клиентов служб для аналитики с открытым кодом в Azure. Подпишитесь на заметки о выпуске HDInsight, чтобы получить актуальные сведения о HDInsight и всех версиях HDInsight.
Чтобы подписаться, нажмите кнопку "Смотреть" в баннере и следите за выпусками HDInsight.
Сведения о выпуске
Дата выпуска: 06 октября 2025 г.
Azure HDInsight периодически выпускает обновления обслуживания, включая исправления ошибок, улучшения производительности и обновления безопасности, чтобы вы всегда были в курсе последних изменений. Обеспечение актуальности этих обновлений гарантирует оптимальную производительность и надежность.
Это примечание о выпуске относится к
![]() версия HDInsight 5.1.
версия HDInsight 5.1.
Выпуск HDInsight будет доступен всем регионам в течение нескольких дней. Это примечание о выпуске применимо для номера образа 2508190809. Как проверить номер образа?
HDInsight использует методы безопасного развертывания, которые предполагают постепенное развертывание по регионам. Для нового выпуска или новой версии в всех регионах может потребоваться до 10 рабочих дней.
Версии ОС
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Примечание.
Ubuntu 18.04 поддерживается в рамках расширенного обслуживания безопасности (ESM) командой Azure Linux начиная с выпуска Azure HDInsight от июля 2023.
Для версий, специфичных для рабочих нагрузок, см. версии компонентов HDInsight 5.x.
Новые возможности
Проверка подлинности Entra включена для кластеров Azure HDInsight. Теперь пользователь может выбрать проверку подлинности пользователя с помощью идентификатора Entra.
Теперь поддерживается вход с помощью Grafana для кластеров Entra.
Проверка C++ CodeQL активирована для улучшения охвата статического анализа.
Проверка подлинности на основе управляемого удостоверения (MI) для баз данных SQL теперь поддерживается в недоступных облаках. Дополнительные сведения см. в статье "Использование управляемого удостоверения для проверки подлинности базы данных SQL в Azure HDInsight"
Исправленные проблемы
Исправлены несколько уязвимостей на уровне ОС в зависимостях (qs, braces, connect, debug и т. д.).
По умолчанию отключено создание локального пользователя для укрепления контроля доступа.
Обновления
- Следующие автономные драйверы больше не поддерживаются в HDInsight.
Напоминание
Служба HDInsight перешла на использование стандартных балансировщиков нагрузки для всех конфигураций кластера в связи с объявлением о снятии с поддержки базовой подсистемы балансировки нагрузки Azure.
Внимание
Кластеры HDInsight по умолчанию создаются с использованием стандартных балансировщиков нагрузки. Мы рекомендуем ссылаться на руководство по миграции для повторного создания кластера. Для любой помощи обратитесь в службу поддержки.
Если у вас есть дополнительные вопросы, обратитесь в службу поддержки Azure.
Вы всегда можете попросить нас о HDInsight в Azure HDInsight — Microsoft Q&A.
Мы слушаем: вы можете добавить дополнительные идеи и другие темы здесь и проголосовать за них - HDInsight Ideas и следовать нам за дополнительными обновлениями в сообществе AzureHDInsight.
Примечание.
Мы советуем клиентам использовать последние версии образов HDInsight, так как они включают лучшие обновления с открытым исходным кодом, обновления Azure и исправления безопасности. Дополнительные сведения см. в статье " Рекомендации".
Дата выпуска: 28 мая 2025 г.
Примечание.
Это выпуск исправлений и технического обслуживания для поставщика ресурсов. Дополнительные сведения см. в разделе "Поставщик ресурсов".
Azure HDInsight периодически выпускает обновления обслуживания, включая исправления ошибок, улучшения производительности и обновления безопасности, чтобы вы всегда были в курсе последних изменений. Обеспечение актуальности этих обновлений гарантирует оптимальную производительность и надежность.
Это примечание о выпуске относится к
![]() версия HDInsight 5.1.
версия HDInsight 5.1.
![]() Версия HDInsight 5.0.
Версия HDInsight 5.0.
![]() Версия HDInsight 4.0.
Версия HDInsight 4.0.
Выпуск HDInsight будет доступен всем регионам в течение нескольких дней. Примечание о выпуске применимо к идентификатору образа 2501080039. Как проверить номер образа?
HDInsight использует методы безопасного развертывания, которые предполагают постепенное развертывание по регионам. Для нового выпуска или новой версии в всех регионах может потребоваться до 10 рабочих дней.
Версии ОС
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Примечание.
Ubuntu 18.04 поддерживается в рамках расширенного обслуживания безопасности (ESM) командой Azure Linux начиная с выпуска Azure HDInsight от июля 2023.
Для версий, специфичных для рабочих нагрузок, см. версии компонентов HDInsight 5.x.
Исправленные проблемы
- Проблема проверки подлинности для баз данных SQL при использовании управляемой идентичности.
Обновления
- Активные запросы ПИН-кода для создания кластеров HDInsight с предопределенными версиями образов отозваны или отменены с 26 мая 2025 года. Клиенты могут создавать кластеры только с помощью обновленных (совместимых) образов каждой версии HDInsight. Эта мера предназначена для повышения безопасности кластера и предотвращения потенциальных проблем с кластерами и узлами шлюза.
Напоминание
Служба HDInsight перешла на использование стандартных балансировщиков нагрузки для всех конфигураций кластера в связи с объявлением о снятии с поддержки базовой подсистемы балансировки нагрузки Azure.
Внимание
Кластеры HDInsight по умолчанию создаются с использованием стандартных балансировщиков нагрузки. Мы рекомендуем ссылаться на руководство по миграции для повторного создания кластера. Для любой помощи обратитесь в службу поддержки.
Если у вас есть дополнительные вопросы, обратитесь в службу поддержки Azure.
Вы всегда можете попросить нас о HDInsight в Azure HDInsight — Microsoft Q&A.
Мы слушаем: вы можете добавить дополнительные идеи и другие темы здесь и проголосовать за них - HDInsight Ideas и следовать нам за дополнительными обновлениями в сообществе AzureHDInsight.
Примечание.
Мы советуем клиентам использовать последние версии образов HDInsight, так как они включают лучшие обновления с открытым исходным кодом, обновления Azure и исправления безопасности. Дополнительные сведения см. в статье " Рекомендации".
Дата выпуска: 28 апреля 2025 г.
Примечание.
Это выпуск исправлений и технического обслуживания для поставщика ресурсов. Дополнительные сведения см. в разделе "Поставщик ресурсов".
Azure HDInsight периодически выпускает обновления обслуживания, включая исправления ошибок, улучшения производительности и обновления безопасности, чтобы вы всегда были в курсе последних изменений. Обеспечение актуальности этих обновлений гарантирует оптимальную производительность и надежность.
Это примечание о выпуске относится к
![]() версия HDInsight 5.1.
версия HDInsight 5.1.
![]() Версия HDInsight 5.0.
Версия HDInsight 5.0.
![]() Версия HDInsight 4.0.
Версия HDInsight 4.0.
Выпуск HDInsight будет доступен всем регионам в течение нескольких дней. Примечание о выпуске применимо к идентификатору образа 2501080039. Как проверить номер образа?
HDInsight использует методы безопасного развертывания, которые предполагают постепенное развертывание по регионам. Для нового выпуска или новой версии в всех регионах может потребоваться до 10 рабочих дней.
Версии ОС
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Примечание.
Ubuntu 18.04 поддерживается в рамках расширенного обслуживания безопасности (ESM) командой Azure Linux начиная с выпуска Azure HDInsight от июля 2023.
Для версий, специфичных для рабочих нагрузок, см. версии компонентов HDInsight 5.x.
Исправленные проблемы
- Аутентификация на основе управляемых удостоверений для WASB сталкивается с проблемами при включении сетевого ACL в хранилище.
- Аутентификация, основанная на управляемых удостоверениях для баз данных SQL, сталкивается с проблемами при использовании зон доступности.
- Несколько исправлений безопасности.
Обновления
- Активные запросы на ПИН для создания кластеров HDInsight с предопределенными версиями образа будут отменены 26 мая 2025 года. После этой даты клиенты смогут создавать кластеры только с помощью обновленных (совместимых) образов каждой версии HDInsight. Эта мера предназначена для повышения безопасности кластера и предотвращения потенциальных проблем с кластерами и узлами шлюза.
Напоминание
Служба HDInsight была переведена на использование стандартных балансировщиков нагрузки для всех конфигураций кластера из-за объявления о прекращении поддержки базового балансировщика нагрузки Azure.
Внимание
Кластеры HDInsight по умолчанию создаются с использованием стандартных балансировщиков нагрузки. Мы рекомендуем ссылаться на руководство по миграции для повторного создания кластера. Для любой помощи обратитесь в службу поддержки.
Вывод из эксплуатации базовых и стандартных виртуальных машин серии A.
- 31 августа 2024 г. мы прекратим использование виртуальных машин A-серии типов 'Базовый' и 'Стандартный'. До этой даты необходимо перенести рабочие нагрузки на виртуальные машины серии Av2, которые обеспечивают больше памяти на виртуальный ЦП и быстрее хранилища на твердотельных дисках (SSD).
- Чтобы избежать сбоев в работе служб, перенесите рабочие нагрузки с виртуальных машин серии "Базовый" и "Стандартный" на виртуальные машины серии Av2 до 31 августа 2024 г.
Если у вас есть дополнительные вопросы, обратитесь в службу поддержки Azure.
Вы всегда можете попросить нас о HDInsight в Azure HDInsight — Microsoft Q&A.
Мы слушаем: вы можете добавить дополнительные идеи и другие темы здесь и проголосовать за них - HDInsight Ideas и следовать нам за дополнительными обновлениями в сообществе AzureHDInsight.
Примечание.
Мы советуем клиентам использовать последние версии образов HDInsight, так как они включают лучшие обновления с открытым исходным кодом, обновления Azure и исправления безопасности. Дополнительные сведения см. в статье " Рекомендации".
Дата выпуска: 23 января 2025 г.
Azure HDInsight периодически выпускает обновления обслуживания, включая исправления ошибок, улучшения производительности и обновления безопасности, чтобы вы всегда были в курсе последних изменений. Обеспечение актуальности этих обновлений гарантирует оптимальную производительность и надежность.
Это примечание о выпуске относится к
![]() версия HDInsight 5.1.
версия HDInsight 5.1.
![]() Версия HDInsight 5.0.
Версия HDInsight 5.0.
![]() Версия HDInsight 4.0.
Версия HDInsight 4.0.
Выпуск HDInsight будет доступен всем регионам в течение нескольких дней. Примечание о выпуске применимо к идентификатору образа 2501080039. Как проверить номер образа?
HDInsight использует методы безопасного развертывания, которые предполагают постепенное развертывание по регионам. Для нового выпуска или новой версии в всех регионах может потребоваться до 10 рабочих дней.
Версии ОС
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Примечание.
Ubuntu 18.04 поддерживается в рамках расширенного обслуживания безопасности (ESM) командой Azure Linux начиная с выпуска Azure HDInsight от июля 2023.
Для версий, специфичных для рабочих нагрузок, см. версии компонентов HDInsight 5.x.
Новая функция
Проверка подлинности с использованием MSI для баз данных SQL.
HDInsight теперь предоставляет управляемую идентификацию для безопасной проверки подлинности с базами данных SQL в своих кластерах. Это улучшение обеспечивает более безопасный механизм проверки подлинности. Дополнительные сведения см. в статье Об использовании управляемого удостоверения для проверки подлинности базы данных SQL в Azure HDInsight.
Чтобы использовать управляемое удостоверение с базами данных SQL, выполните следующие действия.
Эта функция по умолчанию не включена. Чтобы включить его, отправьте запрос в службу поддержки со сведениями о подписке и регионе.
После включения возможности перейдите к повторному воссоздаю кластера.
Примечание.
Управляемое удостоверение в настоящее время доступно только в общедоступных регионах. Он будет развернут в других регионах (федеральных и китайских регионах) в будущих выпусках.
Новые регионы
- Северная Зеландия.
Напоминание
Служба HDInsight была переведена на использование стандартных балансировщиков нагрузки для всех конфигураций кластера из-за объявления о прекращении поддержки базового балансировщика нагрузки Azure.
Примечание.
Это изменение доступно во всех регионах. Пересоздайте ваш кластер, чтобы внести это изменение. Для любой помощи обратитесь в службу поддержки.
Внимание
При использовании собственного виртуального сетевого пространства (кастомного VNet) во время создания кластера следует учитывать, что создание кластера не будет выполнено, как только это изменение будет применено. Мы рекомендуем ссылаться на руководство по миграции для повторного создания кластера. Для любой помощи обратитесь в службу поддержки.
Вывод из эксплуатации базовых и стандартных виртуальных машин серии A.
- 31 августа 2024 г. мы прекратим использование виртуальных машин A-серии типов 'Базовый' и 'Стандартный'. До этой даты необходимо перенести рабочие нагрузки на виртуальные машины серии Av2, которые обеспечивают больше памяти на виртуальный ЦП и быстрее хранилища на твердотельных дисках (SSD).
- Чтобы избежать сбоев в работе служб, перенесите рабочие нагрузки с виртуальных машин серии "Базовый" и "Стандартный" на виртуальные машины серии Av2 до 31 августа 2024 г.
 Скоро
Скоро
- Уведомления о выходе на пенсию для HDInsight 4.0 и HDInsight 5.0.
Если у вас есть дополнительные вопросы, обратитесь в службу поддержки Azure.
Вы всегда можете попросить нас о HDInsight в Azure HDInsight — Microsoft Q&A.
Мы слушаем: вы можете добавить дополнительные идеи и другие темы здесь и проголосовать за них - HDInsight Ideas и следовать нам за дополнительными обновлениями в сообществе AzureHDInsight.
Примечание.
Мы советуем клиентам использовать последние версии образов HDInsight, так как они включают лучшие обновления с открытым исходным кодом, обновления Azure и исправления безопасности. Дополнительные сведения см. в статье " Рекомендации".
Дата выпуска: 22 октября 2024 г.
Примечание.
Это выпуск исправлений и технического обслуживания для поставщика ресурсов. Дополнительные сведения см. в разделе "Поставщик ресурсов".
Azure HDInsight периодически выпускает обновления обслуживания, включая исправления ошибок, улучшения производительности и обновления безопасности, чтобы вы всегда были в курсе последних изменений. Обеспечение актуальности этих обновлений гарантирует оптимальную производительность и надежность.
Это примечание о выпуске относится к
![]() версия HDInsight 5.1.
версия HDInsight 5.1.
![]() Версия HDInsight 5.0.
Версия HDInsight 5.0.
![]() Версия HDInsight 4.0.
Версия HDInsight 4.0.
Выпуск HDInsight будет доступен всем регионам в течение нескольких дней. Это примечание к выпуску применимо к номеру образа 2409240625. Как проверить номер образа?
HDInsight использует методы безопасного развертывания, которые предполагают постепенное развертывание по регионам. Для нового выпуска или новой версии в всех регионах может потребоваться до 10 рабочих дней.
Версии ОС
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Примечание.
Ubuntu 18.04 поддерживается в рамках расширенного обслуживания безопасности (ESM) командой Azure Linux начиная с выпуска Azure HDInsight от июля 2023.
Для версий, специфичных для рабочих нагрузок, см. версии компонентов HDInsight 5.x.
Обновлено
Поддержка проверки подлинности на основе MSI для хранилища BLOB-объектов Azure.
- Azure HDInsight теперь поддерживает проверку подлинности на основе OAuth для доступа к хранилищу BLOB-объектов Azure, используя Azure Active Directory (AAD) и управляемые удостоверения (MSI). Благодаря этому улучшению HDInsight использует назначаемые пользователем управляемые удостоверения для доступа к хранилищу объектов BLOB в Azure. Дополнительные сведения см. в статье об управляемых удостоверениях для ресурсов Azure.
Служба HDInsight была переведена на использование стандартных балансировщиков нагрузки для всех конфигураций кластера из-за объявления о прекращении поддержки базового балансировщика нагрузки Azure.
Примечание.
Это изменение доступно во всех регионах. Пересоздайте ваш кластер, чтобы внести это изменение. Для любой помощи обратитесь в службу поддержки.
Внимание
При использовании собственного виртуального сетевого пространства (кастомного VNet) во время создания кластера следует учитывать, что создание кластера не будет выполнено, как только это изменение будет применено. Мы рекомендуем ссылаться на руководство по миграции для повторного создания кластера. Для любой помощи обратитесь в службу поддержки.
Скоро
Вывод из эксплуатации базовых и стандартных виртуальных машин серии A.
- 31 августа 2024 г. мы прекратим использование виртуальных машин A-серии типов 'Базовый' и 'Стандартный'. До этой даты необходимо перенести рабочие нагрузки на виртуальные машины серии Av2, которые обеспечивают больше памяти на виртуальный ЦП и быстрее хранилища на твердотельных дисках (SSD).
- Чтобы избежать сбоев в работе служб, перенесите рабочие нагрузки с виртуальных машин серии "Базовый" и "Стандартный" на виртуальные машины серии Av2 до 31 августа 2024 г.
Уведомления о выходе на пенсию для HDInsight 4.0 и HDInsight 5.0.
Если у вас есть дополнительные вопросы, обратитесь в службу поддержки Azure.
Вы всегда можете попросить нас о HDInsight в Azure HDInsight — Microsoft Q&A.
Мы слушаем: вы можете добавить дополнительные идеи и другие темы здесь и проголосовать за них - HDInsight Ideas и следовать нам за дополнительными обновлениями в сообществе AzureHDInsight.
Примечание.
Мы советуем клиентам использовать последние версии образов HDInsight, так как они включают лучшие обновления с открытым исходным кодом, обновления Azure и исправления безопасности. Дополнительные сведения см. в статье " Рекомендации".
Дата выпуска: 30 августа 2024 г.
Примечание.
Это выпуск исправлений и технического обслуживания для поставщика ресурсов. Дополнительные сведения см. в разделе "Поставщик ресурсов".
Azure HDInsight периодически выпускает обновления обслуживания, включая исправления ошибок, улучшения производительности и обновления безопасности, чтобы вы всегда были в курсе последних изменений. Обеспечение актуальности этих обновлений гарантирует оптимальную производительность и надежность.
Это примечание о выпуске относится к
![]() версия HDInsight 5.1.
версия HDInsight 5.1.
![]() Версия HDInsight 5.0.
Версия HDInsight 5.0.
![]() Версия HDInsight 4.0.
Версия HDInsight 4.0.
Выпуск HDInsight будет доступен всем регионам в течение нескольких дней. Это примечание о выпуске применимо для номера образа 2407260448. Как проверить номер образа?
HDInsight использует методы безопасного развертывания, которые предполагают постепенное развертывание по регионам. Для нового выпуска или новой версии в всех регионах может потребоваться до 10 рабочих дней.
Версии ОС
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Примечание.
Ubuntu 18.04 поддерживается в рамках расширенного обслуживания безопасности (ESM) командой Azure Linux начиная с выпуска Azure HDInsight от июля 2023.
Для версий, специфичных для рабочих нагрузок, см. версии компонентов HDInsight 5.x.
Исправлена проблема
- Исправление ошибок базы данных по умолчанию.
Скоро
-
Вывод из эксплуатации базовых и стандартных виртуальных машин серии A.
- 31 августа 2024 г. мы прекратим использование виртуальных машин A-серии типов 'Базовый' и 'Стандартный'. До этой даты необходимо перенести рабочие нагрузки на виртуальные машины серии Av2, которые обеспечивают больше памяти на виртуальный ЦП и быстрее хранилища на твердотельных дисках (SSD).
- Чтобы избежать сбоев в работе служб, перенесите рабочие нагрузки с виртуальных машин серии "Базовый" и "Стандартный" на виртуальные машины серии Av2 до 31 августа 2024 г.
- Уведомления о выходе на пенсию для HDInsight 4.0 и HDInsight 5.0.
Если у вас есть дополнительные вопросы, обратитесь в службу поддержки Azure.
Вы всегда можете попросить нас о HDInsight в Azure HDInsight — Microsoft Q&A.
Мы слушаем: вы можете добавить дополнительные идеи и другие темы здесь и проголосовать за них - HDInsight Ideas и следовать нам за дополнительными обновлениями в сообществе AzureHDInsight.
Примечание.
Мы советуем клиентам использовать последние версии образов HDInsight, так как они включают лучшие обновления с открытым исходным кодом, обновления Azure и исправления безопасности. Дополнительные сведения см. в статье с рекомендациями.
Дата выпуска: 09 августа 2024 г.
Это примечание о выпуске относится к
![]() версия HDInsight 5.1.
версия HDInsight 5.1.
![]() Версия HDInsight 5.0.
Версия HDInsight 5.0.
![]() Версия HDInsight 4.0.
Версия HDInsight 4.0.
Выпуск HDInsight будет доступен всем регионам в течение нескольких дней. Это примечание о выпуске применимо для номера образа 2407260448. Как проверить номер образа?
HDInsight использует методы безопасного развертывания, которые предполагают постепенное развертывание по регионам. Для нового выпуска или новой версии в всех регионах может потребоваться до 10 рабочих дней.
Версии ОС
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Примечание.
Ubuntu 18.04 поддерживается в рамках расширенного обслуживания безопасности (ESM) командой Azure Linux начиная с выпуска Azure HDInsight от июля 2023.
Для версий, специфичных для рабочих нагрузок, см. версии компонентов HDInsight 5.x.
Обновления
Добавление агента Azure Monitor для Log Analytics в HDInsight
Добавление SystemMSI и автоматизация DCR для Log Analytics в связи с устареванием нового интерфейса Azure Monitor (предварительная версия).
Примечание.
Эффективное изображение номер 2407260448, клиенты, использующие портал для анализа журналов, будут иметь интерфейс агента Azure Monitor, используемый по умолчанию. Если вы хотите перейти на интерфейс Azure Monitor (предварительная версия), вы можете закрепить кластеры на старые образы, создав запрос на поддержку.
Дата выпуска: 05 июля 2024 г.
Примечание.
Это выпуск исправлений и технического обслуживания для поставщика ресурсов. Дополнительные сведения см. в разделе "Поставщик ресурсов"
Устраненные проблемы
Теги HOBO перезаписывают теги пользователей.
- Теги HOBO перезаписывают теги пользователей на подресурсах при создании кластера HDInsight.
Дата выпуска: 19 июня 2024 г.
Это примечание о выпуске относится к
![]() версия HDInsight 5.1.
версия HDInsight 5.1.
![]() Версия HDInsight 5.0.
Версия HDInsight 5.0.
![]() Версия HDInsight 4.0.
Версия HDInsight 4.0.
Выпуск HDInsight будет доступен всем регионам в течение нескольких дней. Примечание к выпуску применимо для образа с номером 2406180258. Как проверить номер образа?
HDInsight использует методы безопасного развертывания, которые предполагают постепенное развертывание по регионам. Для нового выпуска или новой версии в всех регионах может потребоваться до 10 рабочих дней.
Версии ОС
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Примечание.
Ubuntu 18.04 поддерживается в рамках расширенного обслуживания безопасности (ESM) командой Azure Linux начиная с выпуска Azure HDInsight от июля 2023.
Для версий, специфичных для рабочих нагрузок, см. версии компонентов HDInsight 5.x.
Устраненные проблемы
Улучшения в системе безопасности
- Улучшения использования тегов для кластеров в соответствии с требованиями SFI .
- Улучшения скриптов тестов в соответствии с требованиями SFI.
Улучшения в HDInsight Log Analytics с поддержкой управляемых системных удостоверений для поставщика ресурсов HDInsight.
Добавление новой активности для обновления версии агента
mdsdдля старых образов, созданных до 2024 г.Включение MISE в шлюзе как часть продолжающихся улучшений для миграции MSAL.
Включите сервер Thrift Spark
Httpheader hiveConfв Jetty HTTP ConnectionFactory.Вернуть RANGER-3753 и RANGER-3593.
Реализация, указанная в выпуске
setOwnerUserRanger 2.3.0, имеет критическую проблему регрессии, когда используется с Hive. В Ranger 2.3.0, когда HiveServer2 пытается оценить политики, клиент Ranger пытается получить владельца таблицы hive, вызвав хранилище метаданных в функции setOwnerUser, которая по сути вызывает хранилище для проверки доступа к этой таблице. Эта проблема приводит к медленному выполнению запросов при запуске Hive в Ranger версии 2.3.0.
Добавлены новые регионы
- Северная Италия
- Израиль, центральный регион
- Центральная Испания
- Центральная Мексика
- Jio, Центральная Индия
Добавить в архивные заметки за июнь 2024 г.
Скоро
-
Вывод из эксплуатации базовых и стандартных виртуальных машин серии A.
- 31 августа 2024 г. мы прекратим использование виртуальных машин A-серии типов 'Базовый' и 'Стандартный'. До этой даты необходимо перенести рабочие нагрузки на виртуальные машины серии Av2, которые обеспечивают больше памяти на виртуальный ЦП и быстрее хранилища на твердотельных дисках (SSD).
- Чтобы избежать сбоев в работе служб, перенесите рабочие нагрузки с виртуальных машин серии "Базовый" и "Стандартный" на виртуальные машины серии Av2 до 31 августа 2024 г.
- Уведомления о выходе на пенсию для HDInsight 4.0 и HDInsight 5.0.
Если у вас есть дополнительные вопросы, обратитесь в службу поддержки Azure.
Вы всегда можете попросить нас о HDInsight в Azure HDInsight — Microsoft Q&A.
Мы слушаем: вы можете добавить дополнительные идеи и другие темы здесь и проголосовать за них - HDInsight Ideas и следовать нам за дополнительными обновлениями в сообществе AzureHDInsight.
Примечание.
Мы советуем клиентам использовать последние версии образов HDInsight, так как они включают лучшие обновления с открытым исходным кодом, обновления Azure и исправления безопасности. Дополнительные сведения см. в статье с рекомендациями.
Дата выпуска: 16 мая 2024 г.
Это примечание о выпуске относится к
![]() Версия HDInsight 5.0.
Версия HDInsight 5.0.
![]() Версия HDInsight 4.0.
Версия HDInsight 4.0.
Выпуск HDInsight будет доступен всем регионам в течение нескольких дней. Данное примечание к выпуску относится к номеру изображения 2405081840. Как проверить номер образа?
HDInsight использует методы безопасного развертывания, которые предполагают постепенное развертывание по регионам. Для нового выпуска или новой версии в всех регионах может потребоваться до 10 рабочих дней.
Версии ОС
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Примечание.
Ubuntu 18.04 поддерживается в рамках расширенного обслуживания безопасности (ESM) командой Azure Linux начиная с выпуска Azure HDInsight от июля 2023.
Для версий, специфичных для рабочих нагрузок, см. версии компонентов HDInsight 5.x.
Исправленные проблемы
- Добавлен API на шлюз для получения токена для Keyvault в рамках инициативы SFI.
- В новой таблице монитора журнала
HDInsightSparkLogsдля типа журналаSparkDriverLogнекоторые поля отсутствуют. Например,LogLevel & Message. Этот выпуск добавляет отсутствующие поля в схемы и фиксированное форматирование дляSparkDriverLog. - Журналы Livy недоступны в таблице мониторинга
SparkDriverLogLog Analytics из-за проблем с путём к источнику данных Livy и регулярными выражениями для парсинга журналов в конфигурацияхSparkLivyLog. - Любой кластер HDInsight, использующий ADLS 2-го поколения в качестве основной учетной записи хранения, может использовать доступ на основе MSI к любому из ресурсов Azure (например, SQL, Keyvaults), который используется в коде приложения.
Скоро
-
Вывод из эксплуатации базовых и стандартных виртуальных машин серии A.
- 31 августа 2024 г. мы прекратим использование виртуальных машин A-серии типов 'Базовый' и 'Стандартный'. До этой даты необходимо перенести рабочие нагрузки на виртуальные машины серии Av2, которые обеспечивают больше памяти на виртуальный ЦП и быстрее хранилища на твердотельных дисках (SSD).
- Чтобы избежать сбоев в работе служб, перенесите рабочие нагрузки с виртуальных машин серии "Базовый" и "Стандартный" на виртуальные машины серии Av2 до 31 августа 2024 г.
- Уведомления о выходе на пенсию для HDInsight 4.0 и HDInsight 5.0.
Если у вас есть дополнительные вопросы, обратитесь в службу поддержки Azure.
Вы всегда можете попросить нас о HDInsight в Azure HDInsight — Microsoft Q&A.
Мы слушаем: вы можете добавить дополнительные идеи и другие темы здесь и проголосовать за них - HDInsight Ideas и следовать нам за дополнительными обновлениями в сообществе AzureHDInsight.
Примечание.
Мы советуем клиентам использовать последние версии образов HDInsight, так как они включают лучшие обновления с открытым исходным кодом, обновления Azure и исправления безопасности. Дополнительные сведения см. в статье с рекомендациями.
Дата выпуска: 15 апреля 2024 г.
Это примечание о выпуске относится к версии HDInsight 5.1 ![]() .
.
Выпуск HDInsight будет доступен всем регионам в течение нескольких дней. Это примечание о выпуске применимо к номеру образа 2403290825. Как проверить номер образа?
HDInsight использует методы безопасного развертывания, которые предполагают постепенное развертывание по регионам. Для нового выпуска или новой версии в всех регионах может потребоваться до 10 рабочих дней.
Версии ОС
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Примечание.
Ubuntu 18.04 поддерживается в рамках расширенного обслуживания безопасности (ESM) командой Azure Linux начиная с выпуска Azure HDInsight от июля 2023.
Для версий, специфичных для рабочих нагрузок, см. версии компонентов HDInsight 5.x.
Исправленные проблемы
- Исправления ошибок для Ambari DB, контроллера хранилища Hive (HWC), Spark, HDFS
- Исправления ошибок для модуля Log Analytics для HDInsightSparkLogs
- Исправления CVE для поставщика ресурсов HDInsight.
Скоро
-
Вывод из эксплуатации базовых и стандартных виртуальных машин серии A.
- 31 августа 2024 г. мы прекратим использование виртуальных машин A-серии типов 'Базовый' и 'Стандартный'. До этой даты необходимо перенести рабочие нагрузки на виртуальные машины серии Av2, которые обеспечивают больше памяти на виртуальный ЦП и быстрее хранилища на твердотельных дисках (SSD).
- Чтобы избежать сбоев в работе служб, перенесите рабочие нагрузки с виртуальных машин серии "Базовый" и "Стандартный" на виртуальные машины серии Av2 до 31 августа 2024 г.
- Уведомления о выходе на пенсию для HDInsight 4.0 и HDInsight 5.0.
Если у вас есть дополнительные вопросы, обратитесь в службу поддержки Azure.
Вы всегда можете попросить нас о HDInsight в Azure HDInsight — Microsoft Q&A.
Мы слушаем: вы можете добавить дополнительные идеи и другие темы здесь и проголосовать за них - HDInsight Ideas и следовать нам за дополнительными обновлениями в сообществе AzureHDInsight.
Примечание.
Мы советуем клиентам использовать последние версии образов HDInsight, так как они включают лучшие обновления с открытым исходным кодом, обновления Azure и исправления безопасности. Дополнительные сведения см. в статье с рекомендациями.
Дата выпуска: 15 февраля 2024 г.
Этот выпуск относится к версиям HDInsight 4.x и 5.x. Выпуск HDInsight будет доступен всем регионам в течение нескольких дней. Этот выпуск применим к образу номер 2401250802. Как проверить номер образа?
HDInsight использует методы безопасного развертывания, которые предполагают постепенное развертывание по регионам. Для нового выпуска или новой версии в всех регионах может потребоваться до 10 рабочих дней.
Версии ОС
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Примечание.
Ubuntu 18.04 поддерживается в рамках расширенного обслуживания безопасности (ESM) командой Azure Linux начиная с выпуска Azure HDInsight от июля 2023.
Для получения информации о специфичных версиях для различных рабочих нагрузок, смотрите раздел
Новые возможности
- Поддержка Apache Ranger для Spark SQL в Spark 3.3.0 (HDInsight версии 5.1) с корпоративным пакетом безопасности. Дополнительные сведения см. здесь.
Исправленные проблемы
- Исправления безопасности для компонентов Ambari и Oozie
Скоро
- Вывод из эксплуатации базовых и стандартных виртуальных машин серии A.
- 31 августа 2024 г. мы прекратим использование виртуальных машин A-серии типов 'Базовый' и 'Стандартный'. До этой даты необходимо перенести рабочие нагрузки на виртуальные машины серии Av2, которые обеспечивают больше памяти на виртуальный ЦП и быстрее хранилища на твердотельных дисках (SSD).
- Чтобы избежать сбоев в работе служб, перенесите рабочие нагрузки с виртуальных машин серии "Базовый" и "Стандартный" на виртуальные машины серии Av2 до 31 августа 2024 г.
Если у вас есть дополнительные вопросы, обратитесь в службу поддержки Azure.
Вы всегда можете спросить нас о HDInsight на Azure HDInsight — Microsoft Q&A
Мы слушаем: вы можете добавить дополнительные идеи и другие темы здесь и проголосовать за них - HDInsight Идеи и следовать нам за дополнительными обновлениями в сообществе AzureHDInsight
Примечание.
Мы советуем клиентам использовать последние версии образов HDInsight, так как они включают лучшие обновления с открытым исходным кодом, обновления Azure и исправления безопасности. Дополнительные сведения см. в статье с рекомендациями.
Следующие шаги
- Azure HDInsight. Часто задаваемые вопросы
- Настройка расписания применения исправлений ОС для кластеров HDInsight на основе Linux
- Примечание к предыдущему выпуску
Azure HDInsight является одной из самых популярных среди корпоративных клиентов служб для аналитики с открытым кодом в Azure. Если вы хотите подписаться на заметки о выпуске, отслеживайте релизы в этом репозитории GitHub.
Дата выпуска: 10 января 2024 г.
Этот выпуск исправлений относится к версиям HDInsight 4.x и 5.x. Выпуск HDInsight будет доступен всем регионам в течение нескольких дней. Этот релиз применим для номера образа 2401030422. Как проверить номер образа?
HDInsight использует методы безопасного развертывания, которые предполагают постепенное развертывание по регионам. Для нового выпуска или новой версии в всех регионах может потребоваться до 10 рабочих дней.
Версии ОС
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Примечание.
Ubuntu 18.04 поддерживается в рамках расширенного обслуживания безопасности (ESM) командой Azure Linux начиная с выпуска Azure HDInsight от июля 2023.
Для получения информации о специфичных версиях для различных рабочих нагрузок, смотрите раздел
Устраненные проблемы
- Исправления безопасности для компонентов Ambari и Oozie
Скоро
- Вывод из эксплуатации базовых и стандартных виртуальных машин серии A.
- 31 августа 2024 г. мы прекратим использование виртуальных машин A-серии типов 'Базовый' и 'Стандартный'. До этой даты необходимо перенести рабочие нагрузки на виртуальные машины серии Av2, которые обеспечивают больше памяти на виртуальный ЦП и быстрее хранилища на твердотельных дисках (SSD).
- Чтобы избежать сбоев в работе служб, перенесите рабочие нагрузки с виртуальных машин серии "Базовый" и "Стандартный" на виртуальные машины серии Av2 до 31 августа 2024 г.
Если у вас есть дополнительные вопросы, обратитесь в службу поддержки Azure.
Вы всегда можете спросить нас о HDInsight на Azure HDInsight — Microsoft Q&A
Мы слушаем: вы можете добавить дополнительные идеи и другие темы здесь и проголосовать за них - HDInsight Идеи и следовать нам за дополнительными обновлениями в сообществе AzureHDInsight
Примечание.
Мы советуем клиентам использовать последние версии образов HDInsight, так как они включают лучшие обновления с открытым исходным кодом, обновления Azure и исправления безопасности. Дополнительные сведения см. в статье с рекомендациями.
Дата выпуска: 26 октября 2023 г.
Этот выпуск применяется к версиям HDInsight 4.x и 5.x и будет доступен во всех регионах в течение нескольких дней. Этот выпуск применим к номеру образа 2310140056. Как проверить номер образа?
HDInsight использует методы безопасного развертывания, которые предполагают постепенное развертывание по регионам. Для нового выпуска или новой версии в всех регионах может потребоваться до 10 рабочих дней.
Версии ОС
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Для получения информации о специфичных версиях для различных рабочих нагрузок, смотрите раздел
Новые возможности
HDInsight объявляет о общедоступной доступности HDInsight 5.1, начиная с 1 ноября 2023 г. В этом выпуске выполняется полное обновление стека компонентов с открытым исходным кодом и интеграций от Microsoft.
- Последняя версия с открытым исходным кодом — HDInsight 5.1 поставляется с последней стабильной версией с открытым исходным кодом. Клиенты могут воспользоваться всеми новейшими функциями открытый код, улучшениями производительности Майкрософт и исправлениями ошибок.
- Безопасная — последние версии поставляются с последними исправлениями безопасности, исправлениями безопасности с открытым исходным кодом и улучшениями безопасности корпорации Майкрософт.
- Более низкий уровень производительности — благодаря улучшению производительности клиенты могут снизить операционные затраты, а также повысить автомасштабирование.
Права доступа кластера для безопасного хранения
- Клиенты могут указать (во время создания кластера), следует ли использовать безопасный канал для узлов кластера HDInsight для подключения учетной записи хранения.
Создание кластера HDInsight с помощью пользовательских виртуальных сетей.
- Чтобы повысить общую безопасность кластеров HDInsight, кластеры HDInsight при использовании пользовательских виртуальных сетей должны убедиться, что пользователю предоставлены разрешения на
Microsoft Network/virtualNetworks/subnets/join/actionвыполнение операций создания. Клиент может столкнуться с ошибками создания, если эта проверка не включена.
- Чтобы повысить общую безопасность кластеров HDInsight, кластеры HDInsight при использовании пользовательских виртуальных сетей должны убедиться, что пользователю предоставлены разрешения на
Отличные от ESP ABFS кластеры [разрешения кластера для Word Readable]
- Кластеры ABFS, не относящиеся к ESP, ограничивают пользователей, не входящих в группу Hadoop, от выполнения команд Hadoop, связанных с операциями хранения. Это изменение повышает уровень безопасности кластера.
Обновление встроенной квоты.
- Теперь вы можете запросить увеличение квоты непосредственно с страницы "Моя квота", при этом прямой вызов API гораздо быстрее. В случае сбоя вызова API можно создать новый запрос на поддержку для увеличения квоты.
Скоро
Максимальная длина имени кластера будет сокращена с 59 до 45 символов, чтобы повысить уровень безопасности. Это изменение будет развернуто во всех регионах, начиная с предстоящего выпуска.
Вывод из эксплуатации базовых и стандартных виртуальных машин серии A.
- 31 августа 2024 г. мы выведем из эксплуатации виртуальные машины серии A "Базовый" и "Стандартный". До этой даты необходимо перенести рабочие нагрузки на виртуальные машины серии Av2, которые обеспечивают больше памяти на виртуальный ЦП и быстрее хранилища на твердотельных дисках (SSD).
- Чтобы избежать сбоев в работе служб, перенесите рабочие нагрузки с виртуальных машин серии "Базовый" и "Стандартный" на виртуальные машины серии Av2 до 31 августа 2024 г.
Если у вас есть дополнительные вопросы, обратитесь в службу поддержки Azure.
Вы всегда можете спросить нас о HDInsight на Azure HDInsight — Microsoft Q&A
Мы слушаем: вы можете добавить дополнительные идеи и другие темы здесь и проголосовать за них - HDInsight Идеи и следовать нам за дополнительными обновлениями в сообществе AzureHDInsight
Примечание.
В этом выпуске рассматриваются следующие CVEs, выпущенные MSRC 12 сентября 2023 года. Действие заключается в обновлении до последней версии образа 2308221128 или 2310140056. Клиентам рекомендуется планировать соответствующим образом.
| CVE | Серьезность | Название CVE | Комментарий |
|---|---|---|---|
| CVE-2023-38156 | Внимание | Уязвимость, связанная с повышением привилегий Apache Ambari в Azure HDInsight | Включено в образе 2308221128 или 2310140056 |
| CVE-2023-36419 | Внимание | Уязвимость, связанная с повышением привилегий планировщика рабочих процессов Apache Oozie в Azure HDInsight | Примените действие скрипта в своих кластерах или обновите образ до версии 2310140056 |
Примечание.
Мы советуем клиентам использовать последние версии образов HDInsight, так как они включают лучшие обновления с открытым исходным кодом, обновления Azure и исправления безопасности. Дополнительные сведения см. в статье с рекомендациями.
Дата выпуска: 7 сентября 2023 г.
Этот выпуск применяется к версиям HDInsight 4.x и 5.x и будет доступен во всех регионах в течение нескольких дней. Этот выпуск применим к номеру изображения 2308221128. Как проверить номер образа?
HDInsight использует методы безопасного развертывания, которые предполагают постепенное развертывание по регионам. Для нового выпуска или новой версии в всех регионах может потребоваться до 10 рабочих дней.
Версии ОС
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Для получения информации о специфичных версиях для различных рабочих нагрузок, смотрите раздел
Внимание
В этом выпуске рассматриваются следующие CVEs, выпущенные MSRC 12 сентября 2023 года. Действие заключается в обновлении до последней версии образа 2308221128. Клиентам рекомендуется планировать соответствующим образом.
| CVE | Серьезность | Название CVE | Комментарий |
|---|---|---|---|
| CVE-2023-38156 | Внимание | Уязвимость, связанная с повышением привилегий Apache Ambari в Azure HDInsight | Включена на образ 2308221128 |
| CVE-2023-36419 | Внимание | Уязвимость, связанная с повышением привилегий планировщика рабочих процессов Apache Oozie в Azure HDInsight | Примените скриптовую команду к вашим кластерам |
Скоро
- Максимальная длина имени кластера будет сокращена с 59 до 45 символов, чтобы повысить уровень безопасности. Это изменение будет реализовано 30 сентября 2023 г.
- Разрешения кластера для безопасного хранилища
- Клиенты могут указать (во время создания кластера), следует ли использовать безопасный канал для узлов кластера HDInsight для связи с учетной записью хранения.
- Обновление встроенной квоты.
- Увеличение квот для запросов осуществляется напрямую через страницу "Моя квота", это прямой вызов API, который работает быстрее. Если вызов APdI завершается сбоем, клиенты должны создать новый запрос на поддержку для увеличения квоты.
- Создание кластера HDInsight с помощью пользовательских виртуальных сетей.
- Чтобы повысить общую безопасность кластеров HDInsight, кластеры HDInsight при использовании пользовательских виртуальных сетей должны убедиться, что пользователю предоставлены разрешения на
Microsoft Network/virtualNetworks/subnets/join/actionвыполнение операций создания. Клиентам потребуется соответствующим образом планировать это изменение, чтобы избежать сбоев создания кластера до 30 сентября 2023 года.
- Чтобы повысить общую безопасность кластеров HDInsight, кластеры HDInsight при использовании пользовательских виртуальных сетей должны убедиться, что пользователю предоставлены разрешения на
- Вывод из эксплуатации базовых и стандартных виртуальных машин серии A.
- 31 августа 2024 г. мы прекратим использование виртуальных машин A-серии типов 'Базовый' и 'Стандартный'. До этой даты необходимо перенести рабочие нагрузки на виртуальные машины серии Av2, которые обеспечивают больше памяти на виртуальный ЦП и быстрее хранилища на твердотельных дисках (SSD). Чтобы избежать сбоев в работе служб, перенесите рабочие нагрузки с виртуальных машин серии "Базовый" и "Стандартный" на виртуальные машины серии Av2 до 31 августа 2024 г.
- Кластеры ABFS, не основанные на ESP [права доступа кластера для доступных по чтению]
- Запланируйте внедрение изменений в кластерах ABFS, не относящихся к ESP, которые ограничивают пользователей, не входящих в Hadoop, в выполнении команд Hadoop для операций хранения. Это изменение для улучшения состояния безопасности кластера. Клиентам необходимо планировать обновления до 30 сентября 2023 г.
Если у вас есть дополнительные вопросы, обратитесь в службу поддержки Azure.
Вы всегда можете спросить нас о HDInsight на Azure HDInsight — Microsoft Q&A
Вы можете добавить дополнительные предложения и идеи и другие темы здесь и проголосовать за них - HDInsight Community (azure.com).
Примечание.
Мы советуем клиентам использовать последние версии образов HDInsight, так как они включают лучшие обновления с открытым исходным кодом, обновления Azure и исправления безопасности. Дополнительные сведения см. в статье с рекомендациями.
Дата выпуска: 25 июля 2023 г.
Этот выпуск применяется к версиям HDInsight 4.x и 5.x и будет доступен во всех регионах в течение нескольких дней. Этот выпуск применим для номера образа 2307201242. Как проверить номер образа?
HDInsight использует методы безопасного развертывания, которые предполагают постепенное развертывание по регионам. Для нового выпуска или новой версии в всех регионах может потребоваться до 10 рабочих дней.
Версии ОС
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Для получения информации о специфичных версиях для различных рабочих нагрузок, смотрите раздел
 Новые возможности
Новые возможности
- HDInsight 5.1 теперь поддерживается в кластере ESP.
- Обновленная версия Ranger 2.3.0 и Oozie 5.2.1 теперь являются частью HDInsight 5.1
- Кластер Spark 3.3.1 (HDInsight 5.1) поставляется с Hive Warehouse Connector (HWC) 2.1, который работает совместно с кластером Interactive Query (HDInsight 5.1).
- Ubuntu 18.04 поддерживается в рамках ESM (расширенное обслуживание безопасности) командой Azure Linux для Azure HDInsight, начиная с выпуска июля 2023 г.
Внимание
В этом выпуске исправлены следующие CVE, опубликованные MSRC 8 августа 2023 года. Действие заключается в обновлении до последней версии образа 2307201242. Клиентам рекомендуется планировать соответствующим образом.
| CVE | Серьезность | Название CVE |
|---|---|---|
| CVE-2023-35393 | Внимание | Уязвимость подделки в Apache Hive Azure |
| CVE-2023-35394 | Внимание | Уязвимость спуфинга в записных книгах Jupyter Azure HDInsight |
| CVE-2023-36877 | Внимание | Уязвимость spoofing в Azure Apache Oozie |
| CVE-2023-36881 | Внимание | Уязвимость подделки Azure Apache Ambari |
| CVE-2023-38188 | Внимание | Уязвимость спуфинга в Azure Apache Hadoop |
Скоро
- Максимальная длина имени кластера будет сокращена с 59 до 45 символов, чтобы повысить уровень безопасности. Клиентам необходимо планировать обновления до 30 сентября 2023 г.
- Разрешения кластера для безопасного хранилища
- Клиенты могут указать (во время создания кластера), следует ли использовать безопасный канал для узлов кластера HDInsight для связи с учетной записью хранения.
- Обновление встроенной квоты.
- Увеличение квот для запросов осуществляется напрямую через страницу "Моя квота", это прямой вызов API, который работает быстрее. Если вызов API завершается сбоем, клиенты должны создать новый запрос на поддержку для увеличения квоты.
- Создание кластера HDInsight с помощью пользовательских виртуальных сетей.
- Чтобы повысить общую безопасность кластеров HDInsight, кластеры HDInsight при использовании пользовательских виртуальных сетей должны убедиться, что пользователю предоставлены разрешения на
Microsoft Network/virtualNetworks/subnets/join/actionвыполнение операций создания. Клиентам потребуется планировать соответствующее изменение, так как это изменение будет обязательной проверкой, чтобы избежать сбоев создания кластера до 30 сентября 2023 года.
- Чтобы повысить общую безопасность кластеров HDInsight, кластеры HDInsight при использовании пользовательских виртуальных сетей должны убедиться, что пользователю предоставлены разрешения на
- Вывод из эксплуатации базовых и стандартных виртуальных машин серии A.
- С 31 августа 2024 г. мы выводим из эксплуатации виртуальные машины серии A (Basic и Standard). До этой даты необходимо перенести рабочие нагрузки на виртуальные машины серии Av2, которые обеспечивают больше памяти на виртуальный ЦП и быстрее хранилища на твердотельных дисках (SSD). Чтобы избежать сбоев в работе служб, перенесите рабочие нагрузки с виртуальных машин серии "Базовый" и "Стандартный" на виртуальные машины серии Av2 до 31 августа 2024 г.
- Кластеры ABFS, не основанные на ESP [права доступа кластера для доступных по чтению]
- Запланируйте внедрение изменений в кластерах ABFS, не относящихся к ESP, которые ограничивают пользователей, не входящих в Hadoop, в выполнении команд Hadoop для операций хранения. Это изменение для улучшения состояния безопасности кластера. Клиентам необходимо планировать обновления до 30 сентября 2023 года.
Если у вас есть дополнительные вопросы, обратитесь в службу поддержки Azure.
Вы всегда можете спросить нас о HDInsight на Azure HDInsight — Microsoft Q&A
Вы можете добавить дополнительные предложения и идеи и другие темы здесь и проголосовать за них - HDInsight Community (azure.com) и следовать за нами для получения дополнительных обновлений на X
Примечание.
Мы советуем клиентам использовать последние версии образов HDInsight, так как они включают лучшие обновления с открытым исходным кодом, обновления Azure и исправления безопасности. Дополнительные сведения см. в статье с рекомендациями.
Дата выпуска: 08 мая 2023 г.
Этот выпуск относится к HDInsight 4.x и 5.x, которые становятся доступны во всех регионах в течение нескольких дней. Этот выпуск применим к образу с номером 2304280205. Как проверить номер образа?
HDInsight использует методы безопасного развертывания, которые предполагают постепенное развертывание по регионам. Для нового выпуска или новой версии в всех регионах может потребоваться до 10 рабочих дней.
Версии ОС
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Для получения информации о специфичных версиях для различных рабочих нагрузок, смотрите раздел
![]()
Azure HDInsight 5.1 обновлённая версия с
- Apache HBase 2.4.11
- Apache Phoenix 5.1.2
- Apache Hive 3.1.2
- Apache Spark 3.3.1
- Apache Tez 0.9.1
- Apache Zeppelin 0.10.1
- Apache Livy 0.5
- Apache Kafka 3.2.0
Примечание.
- Все компоненты интегрированы с Hadoop 3.3.4 и ZK 3.6.3
- Все перечисленные выше обновленные компоненты теперь доступны в кластерах, отличных от ESP, для общедоступной предварительной версии.
![]()
Расширенное автомасштабирование для HDInsight
Azure HDInsight сделал заметные улучшения стабильности и задержки в автомасштабировании. Основные изменения включают улучшенный цикл обратной связи для принятия решений по масштабированию, значительное снижение задержки при масштабировании, а также поддержку повторного ввода в эксплуатацию упразднённых узлов. Узнайте больше об улучшениях, о том, как настроить и перенести кластер на улучшенное автомасштабирование. Расширенная возможность автомасштабирования доступна с 17 мая 2023 г. во всех поддерживаемых регионах.
Azure HDInsight ESP для Apache Kafka 2.4.1 теперь общедоступен.
ESP Azure HDInsight для Apache Kafka 2.4.1 находится в стадии общедоступной предварительной версии с апреля 2022 года. После заметных улучшений в исправлениях и стабильности CVE Azure HDInsight ESP Kafka 2.4.1 теперь становится общедоступным и готовым для рабочих нагрузок, узнайте подробности о настройке и миграции.
Управление квотами для HDInsight
В настоящее время HDInsight выделяет квоту для подписок клиентов на региональном уровне. Ядра, выделенные клиентам, являются универсальными и не классифицируются на уровне семейства виртуальных машин (например,
Dv2, ,Ev3Eav4и т. д.).В HDInsight появилось улучшенное представление, которое предоставляет подробные сведения и классификацию квот для виртуальных машин уровня семьи, эта функция позволяет клиентам просматривать текущие и оставшиеся квоты для региона на уровне семейства виртуальных машин. Благодаря расширенному представлению клиенты имеют повышенную видимость для планирования квот и улучшенный пользовательский опыт. Эта функция в настоящее время доступна в HDInsight 4.x и 5.x для региона EUAP восточной части США. Другие регионы, которые будут следовать позже.
Дополнительные сведения см. в статье о планировании емкости кластера в Azure HDInsight | Microsoft Learn
![]()
- Центральная Польша
- Максимальная длина имени кластера изменяется на 45 символов с 59 символов, чтобы повысить уровень безопасности кластеров.
- Разрешения кластера для безопасного хранилища
- Клиенты могут указать (во время создания кластера), следует ли использовать безопасный канал для узлов кластера HDInsight для связи с учетной записью хранения.
- Обновление встроенной квоты.
- Запросите увеличение квоты непосредственно со страницы "Моя квота". Это инициирует прямой вызов API, что происходит быстрее. Если вызов API завершается сбоем, клиенты должны создать новый запрос на поддержку для увеличения квоты.
- Создание кластера HDInsight с помощью пользовательских виртуальных сетей.
- Чтобы повысить общую безопасность кластеров HDInsight, кластеры HDInsight при использовании пользовательских виртуальных сетей должны убедиться, что пользователю предоставлены разрешения на
Microsoft Network/virtualNetworks/subnets/join/actionвыполнение операций создания. Клиентам потребуется планировать соответствующим образом, так как это будет обязательной проверкой, чтобы избежать сбоев создания кластера.
- Чтобы повысить общую безопасность кластеров HDInsight, кластеры HDInsight при использовании пользовательских виртуальных сетей должны убедиться, что пользователю предоставлены разрешения на
- Вывод из эксплуатации базовых и стандартных виртуальных машин серии A.
- С 31 августа 2024 г. мы выводим из эксплуатации виртуальные машины серии A (Basic и Standard). До этой даты необходимо перенести рабочие нагрузки на виртуальные машины серии Av2, которые обеспечивают больше памяти на виртуальный ЦП и быстрее хранилища на твердотельных дисках (SSD). Чтобы избежать сбоев в работе служб, перенесите рабочие нагрузки с виртуальных машин серии "Базовый" и "Стандартный" на виртуальные машины серии Av2 до 31 августа 2024 года.
- Не-ESP отказоустойчивые кластеры ABFS [Разрешения кластера для доступности для всех]
- Запланируйте внедрение изменений в кластерах ABFS, не относящихся к ESP, которые ограничивают пользователей, не входящих в Hadoop, в выполнении команд Hadoop для операций хранения. Это изменение для улучшения состояния безопасности кластера. Клиентам необходимо планировать обновления.
Дата выпуска: 28 февраля 2023 г.
Этот выпуск применим к HDInsight версии 4.0. и 5.0, 5.1. Выпуск HDInsight доступен для всех регионов в течение нескольких дней. Этот выпуск применим к образу с номером 2302250400. Как проверить номер образа?
HDInsight использует методы безопасного развертывания, которые предполагают постепенное развертывание по регионам. Для нового выпуска или новой версии в всех регионах может потребоваться до 10 рабочих дней.
Версии ОС
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Для получения информации о специфичных версиях для различных рабочих нагрузок, смотрите раздел
Внимание
Корпорация Майкрософт опубликовала CVE-2023-23408, которая исправлена в последней версии, и клиентам рекомендуется обновить свои кластеры до последнего образа.
![]()
HDInsight 5.1
Мы начали развертывать новую версию HDInsight 5.1. Все новые выпуски с открытым кодом, добавленные как добавочные выпуски в HDInsight 5.1.
Дополнительные сведения см. в версии HDInsight 5.1.0
![]()
Обновление Kafka 3.2.0 (предварительная версия)
- Kafka 3.2.0 включает несколько важных новых функций и улучшений.
- Обновление Zookeeper до 3.6.3
- Поддержка Kafka Streams
- Усиленные гарантии доставки для Kafka Producer включены по умолчанию.
-
log4jзаменено на 1.xreload4j. - Отправьте сигнал лидеру раздела для восстановления раздела.
-
JoinGroupRequestиLeaveGroupRequestимеют прикреплённую причину. - Добавлены метрики количества брокеров8.
- Улучшения зеркального отображения
Maker2.
Обновление HBase 2.4.11 (предварительная версия)
- Эта версия имеет новые функции, такие как добавление новых типов механизмов кэширования для кэша блоков, возможность изменять и просматривать
hbase:meta tableтаблицуhbase:metaиз веб-интерфейса HBase.
Обновление Phoenix 5.1.2 (предварительная версия)
- Версия Phoenix обновлена до версии 5.1.2 в этом выпуске. Это обновление включает сервер запросов Phoenix. Сервер запросов Phoenix поддерживает стандартный драйвер Phoenix JDBC и предоставляет протокол проводной связи, совместимый с обратной совместимостью, для вызова этого драйвера JDBC.
Ambari CVEs
- Исправлены несколько уязвимостей Ambari.
Примечание.
ESP не поддерживается для Kafka и HBase в этом выпуске.
![]()
Дальнейшие действия
- Автомасштабирование
- Автомасштабирование с уменьшенной задержкой и рядом других улучшений
- Ограничение изменения имени кластера
- Максимальная длина имени кластера изменяется с 59 до 45 в общедоступной версии Azure, Azure China и Azure Government.
- Разрешения кластера для безопасного хранилища
- Клиенты могут указать (во время создания кластера), следует ли использовать безопасный канал для узлов кластера HDInsight для связи с учетной записью хранения.
- Не-ESP отказоустойчивые кластеры ABFS [Разрешения кластера для доступности для всех]
- Запланируйте внедрение изменений в кластерах ABFS, не относящихся к ESP, которые ограничивают пользователей, не входящих в Hadoop, в выполнении команд Hadoop для операций хранения. Это изменение для улучшения состояния безопасности кластера. Клиентам необходимо планировать обновления.
- Обновления с открытым кодом
- Apache Spark 3.3.0 и Hadoop 3.3.4 находятся в разработке в HDInsight 5.1 и включают несколько важных новых функций, производительности и других улучшений.
Примечание.
Мы советуем клиентам использовать последние версии образов HDInsight, так как они включают лучшие обновления с открытым исходным кодом, обновления Azure и исправления безопасности. Дополнительные сведения см. в статье с рекомендациями.
Дата выпуска: 12 декабря 2022 г.
Этот выпуск применим к HDInsight версии 4.0. и выпуск HDInsight версии 5.0 доступен для всех регионов в течение нескольких дней.
HDInsight использует методы безопасного развертывания, которые предполагают постепенное развертывание по регионам. Для нового выпуска или новой версии в всех регионах может потребоваться до 10 рабочих дней.
Версии ОС
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
![]()
- Log Analytics — клиенты могут включить классический мониторинг, чтобы получить последнюю версию OMS версии 14.19. Чтобы удалить старые версии, отключите и включите классический мониторинг.
- Автоматический выход пользователя в Ambari из-за неактивности. Дополнительные сведения см. здесь
- Spark — новая и оптимизированная версия Spark 3.1.3 включена в этот выпуск. Мы проверили Apache Spark 3.1.2 (предыдущая версия) и Apache Spark 3.1.3 (текущая версия) с помощью теста TPC-DS. Тест был выполнен с помощью SKU E8 версии 3 для Apache Spark на рабочей нагрузке 1 ТБ. Apache Spark 3.1.3 (текущая версия) превзошёл Apache Spark 3.1.2 (предыдущая версия) более чем на 40 % в общем времени выполнения запросов в TPC-DS с использованием тех же спецификаций оборудования. Команда Microsoft Spark добавила оптимизацию, доступную в Azure Synapse с помощью Azure HDInsight. Дополнительные сведения см. в статье "Ускорение рабочих нагрузок данных с помощью обновлений производительности в Apache Spark 3.1.2 в Azure Synapse"
![]()
- Центральный Катар
- Северная Германия
![]()
HDInsight отошел от Azul Zulu Java JDK 8 к
Adoptium Temurin JDK 8, который поддерживает сертифицированные среды выполнения TCK высокого качества и связанные с ними технологии для использования в экосистеме Java.HDInsight перенесен в
reload4j. Измененияlog4jприменимы к- Apache Hadoop
- Apache Zookeeper
- Apache Oozie
- Apache Ranger
- Apache Sqoop
- Apache Pig
- Apache Ambari
- Apache Kafka
- Apache Spark
- Apache Zeppelin
- Apache Livy
- Apache Rubix
- Apache Hive
- Apache Tez
- Apache HBase
- OMI
- Apache Phoenix
![]()
HDInsight будет внедрять TLS1.2 в будущем, а более ранние версии уже обновлены на платформе. Если вы работаете с приложениями на основе HDInsight, и они используют TLS 1.0 и 1.1, обновите до TLS 1.2, чтобы избежать каких-либо сбоев в службах.
Дополнительные сведения см. в разделе "Включение протокола TLS"
![]()
Прекращение поддержки кластеров Azure HDInsight в Ubuntu 16.04 LTS с 30 ноября 2022 г. HDInsight начинает выпуск образов кластеров на Ubuntu 18.04 с 27 июня 2021 г. Мы рекомендуем нашим клиентам, которые используют кластеры на базе Ubuntu 16.04, перестроить свои кластеры с последними образами HDInsight до 30 ноября 2022 года.
Дополнительные сведения о том, как проверить версию кластера Ubuntu, см . здесь
Выполните команду "lsb_release -a" в терминале.
Если значение свойства Description в выходных данных — Ubuntu 16.04 LTS, это обновление применимо к кластеру.
![]()
- Поддержка выбора зон доступности для кластеров Kafka и HBase (доступ на запись).
Исправления ошибок открытого исходного кода
Исправления ошибок Hive
| Исправления ошибок | Apache JIRA |
|---|---|
| HIVE-26127 | Ошибка INSERT OVERWRITE — файл не найден |
| HIVE-24957 | Неправильные результаты, когда подзапрос имеет COALESCE в предикате корреляции |
| HIVE-24999 | HiveSubQueryRemoveRule создает недопустимый план для вложенных запросов IN с несколькими корреляциями |
| HIVE-24322 | Если имеется прямая вставка, в случае ошибки при чтении манифеста необходимо проверить идентификатор попытки. |
| HIVE-23363 | Обновление зависимости DataNucleus до версии 5.2 |
| HIVE-26412 | Создать интерфейс для получения доступных слотов и добавления настроек по умолчанию |
| HIVE-26173 | Обновление Derby до версии 10.14.2.0 |
| HIVE-25920 | Обновите Xerce2 до 2.12.2. |
| HIVE-26300 | Обновление привязки данных Джексона до версии 2.12.6.1+ для предотвращения CVE-2020-36518 |
Дата выпуска: 10.08.2022
Этот выпуск применим к HDInsight версии 4.0. Выпуск HDInsight предоставляется для разных регионов на протяжении нескольких дней.
HDInsight использует методы безопасного развертывания, которые предполагают постепенное развертывание по регионам. Для нового выпуска или новой версии в всех регионах может потребоваться до 10 рабочих дней.
![]()
Новая возможность
1. Подключение внешних дисков в кластерах HDI Hadoop/Spark
Кластер HDInsight поставляется с предопределенным дисковым пространством на основе номера SKU. Это пространство может быть недостаточно в сценариях больших заданий.
Эта новая функция позволяет добавлять в кластер дополнительные диски, которые используются в качестве локального каталога диспетчера узлов. Добавьте количество дисков в рабочие узлы во время создания кластера HIVE и Spark, а выбранные диски являются частью локальных каталогов диспетчера узлов.
Примечание.
Добавленные диски настраиваются только для локальных каталогов диспетчера узлов.
Дополнительные сведения см. здесь
2. Выборочный анализ логирования
Анализ выборочного логирования теперь доступен во всех регионах для публик в предварительном просмотре. Кластер можно подключить к рабочей области анализа журналов. После включения можно просмотреть журналы и метрики, такие как журналы безопасности HDInsight, Yarn Resource Manager, системные метрики и т. д. Можно отслеживать рабочие нагрузки и видеть, как они влияют на стабильность кластера. Выборочное ведение журнала позволяет включить или отключить все таблицы или включить выборочные таблицы в рабочей области Log Analytics. Можно настроить тип источника для каждой таблицы, так как в новой версии Geneva Monitoring одна таблица имеет несколько источников.
- Система Geneva Monitoring использует mdsd (демон MDS), который является агентом мониторинга, и fluentd для сбора логов с использованием единого уровня логирования.
- Для выборочного ведения журнала используется действие скрипта для отключения и включения таблиц и их типов журналов. Оно не открывает новые порты и не изменяет существующий параметр безопасности, поэтому изменения безопасности отсутствуют.
- Действие скрипта выполняется параллельно на всех указанных узлах и изменяет файлы конфигурации для отключения или включения таблиц и их типов журналов.
Дополнительные сведения см. здесь
![]()
Исправлено
Анализ журналов
Для интеграции Анализа журналов с Azure HDInsight под управлением OMS версии 13 требуется обновление OMS до версии 14, чтобы применялись последние обновления для системы безопасности. Клиентам, использующим более раннюю версию кластера с OMS версии 13, необходимо установить OMS версии 14 в соответствии с требованиями безопасности. (Как проверить текущую версию и установить 14)
Проверка текущей версии OMS
- Войдите в кластер с помощью SSH.
- Выполните следующую команду в клиенте SSH.
sudo /opt/omi/bin/ominiserver/ --version

Обновление версии OMS с 13 до 14
- Войдите на портал Azure
- В группе ресурсов выберите ресурс кластера HDInsight
- Выберите действия скрипта
- На панели Отправка действия скрипта выберите Тип скрипта в качестве настраиваемого
- Вставьте следующую ссылку в поле URL-адреса скрипта Bash https://hdiconfigactions.blob.core.windows.net/log-analytics-patch/OMSUPGRADE14.1/omsagent-vulnerability-fix-1.14.12-0.sh
- Выберите Тип(ы) узлов
- Нажмите кнопку Создать
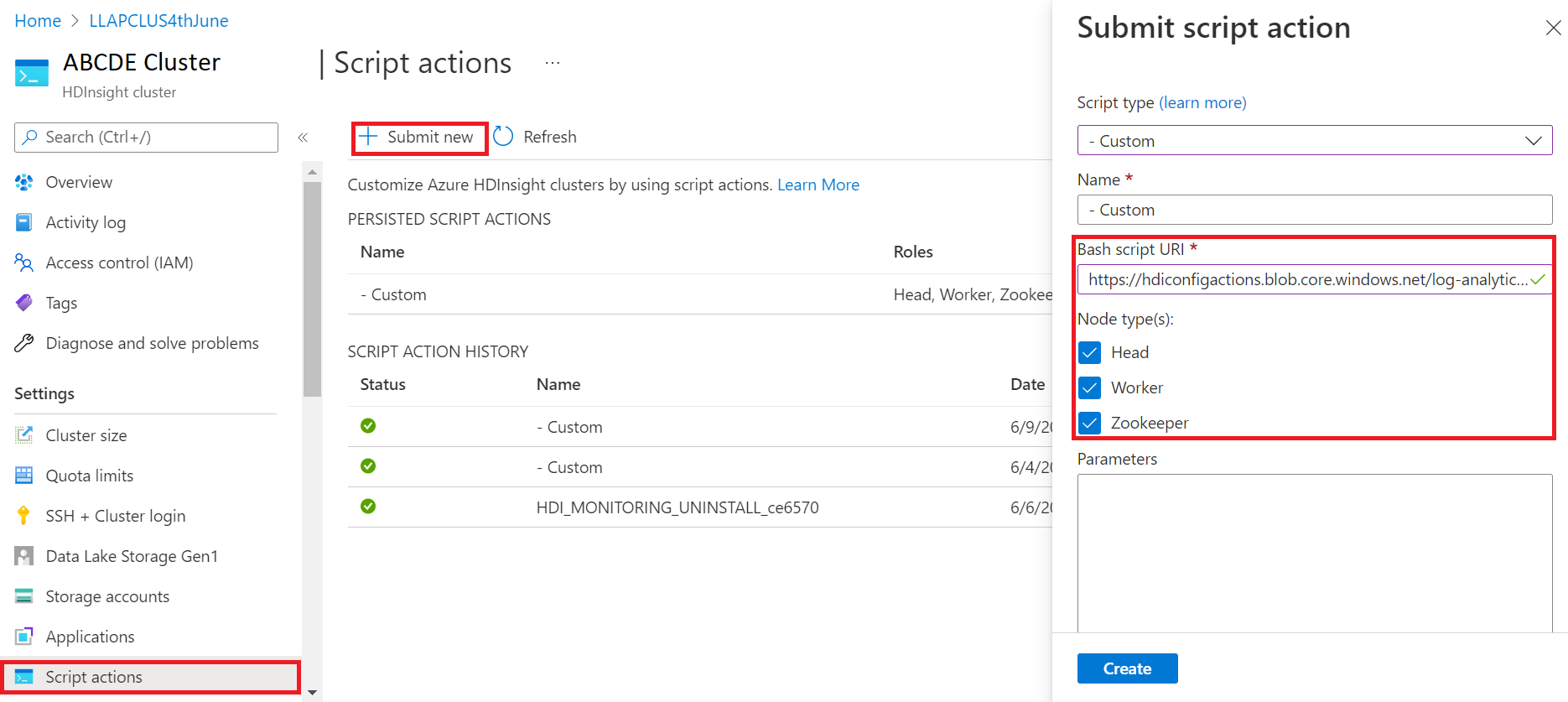
Проверьте успешную установку исправления, выполнив следующие действия:
Войдите в кластер с помощью SSH.
Выполните следующую команду в клиенте SSH.
sudo /opt/omi/bin/ominiserver/ --version
Исправления других ошибок
- Интерфейс командной строки журнала Yarn не смог получить журналы, если какой-либо
TFileповрежден или пуст. - Устранена ошибка с недопустимыми сведениями о субъекте-службе при получении маркера OAuth из Azure Active Directory.
- Повышена надежность создания кластера при настройке 100 и более рабочих узлов.
Исправления ошибок открытого исходного кода
Исправления ошибок TEZ
| Исправления ошибок | Apache JIRA |
|---|---|
| Сбой сборки Tez: FileSaver.js не найден | TEZ-4411 |
Неправильное исключение FS, если хранилище и scratchdir находятся на разных FS |
TEZ-4406 |
| TezUtils.createConfFromByteString при конфигурации размером более 32 MB выбрасывает исключение com.google.protobuf.CodedInputStream | TEZ-4142 |
| TezUtils::createByteStringFromConf должен использовать snappy вместо DeflaterOutputStream | TEZ-4113 |
| Обновление зависимости protobuf до версии 3.x | TEZ-4363 |
Исправления ошибок Hive
| Исправления ошибок | Apache JIRA |
|---|---|
| Оптимизация производительности при генерации сплитов ORC | HIVE-21457 |
| Избегайте интерпретации таблицы как ACID, если имя таблицы начинается с "DELTA", но таблица не является транзакционной, и используется стратегия разделения в бизнес-аналитике. | HIVE-22582 |
| Удалите вызов FS#exists из AcidUtils#getLogicalLength | HIVE-23533 |
| Векторный OrcAcidRowBatchReader.computeOffset и оптимизация контейнеров | HIVE-17917 |
Известные проблемы
HDInsight совместим с Apache HIVE версии 3.1.2. Вследствие ошибки в этом выпуске версия Hive отображается как 3.1.0 в интерфейсах Hive. Тем не менее, это не влияет на функциональность.
Дата выпуска: 10.08.2022
Этот выпуск применим к HDInsight версии 4.0. Выпуск HDInsight предоставляется для разных регионов на протяжении нескольких дней.
HDInsight использует методы безопасного развертывания, которые предполагают постепенное развертывание по регионам. Для нового выпуска или новой версии в всех регионах может потребоваться до 10 рабочих дней.
![]()
Новая возможность
1. Подключение внешних дисков в кластерах HDI Hadoop/Spark
Кластер HDInsight поставляется с предопределенным дисковым пространством на основе номера SKU. Это пространство может быть недостаточно в сценариях больших заданий.
Эта новая функция позволяет добавлять дополнительные диски в кластер, который будет использоваться в качестве локального каталога диспетчера узлов. Добавьте количество дисков в рабочие узлы во время создания кластера HIVE и Spark, а выбранные диски являются частью локальных каталогов диспетчера узлов.
Примечание.
Добавленные диски настраиваются только для локальных каталогов диспетчера узлов.
Дополнительные сведения см. здесь
2. Выборочный анализ логирования
Анализ выборочного логирования теперь доступен во всех регионах для публик в предварительном просмотре. Кластер можно подключить к рабочей области анализа журналов. После включения можно просмотреть журналы и метрики, такие как журналы безопасности HDInsight, Yarn Resource Manager, системные метрики и т. д. Можно отслеживать рабочие нагрузки и видеть, как они влияют на стабильность кластера. Выборочное ведение журнала позволяет включить или отключить все таблицы или включить выборочные таблицы в рабочей области Log Analytics. Можно настроить тип источника для каждой таблицы, так как в новой версии Geneva Monitoring одна таблица имеет несколько источников.
- Система Geneva Monitoring использует mdsd (демон MDS), который является агентом мониторинга, и fluentd для сбора логов с использованием единого уровня логирования.
- Для выборочного ведения журнала используется действие скрипта для отключения и включения таблиц и их типов журналов. Оно не открывает новые порты и не изменяет существующий параметр безопасности, поэтому изменения безопасности отсутствуют.
- Действие скрипта выполняется параллельно на всех указанных узлах и изменяет файлы конфигурации для отключения или включения таблиц и их типов журналов.
Дополнительные сведения см. здесь
![]()
Исправлено
Анализ журналов
Для интеграции Анализа журналов с Azure HDInsight под управлением OMS версии 13 требуется обновление OMS до версии 14, чтобы применялись последние обновления для системы безопасности. Клиентам, использующим более раннюю версию кластера с OMS версии 13, необходимо установить OMS версии 14 в соответствии с требованиями безопасности. (Как проверить текущую версию и установить 14)
Проверка текущей версии OMS
- Войдите в кластер с помощью SSH.
- Выполните следующую команду в клиенте SSH.
sudo /opt/omi/bin/ominiserver/ --version
Обновление версии OMS с 13 до 14
- Войдите на портал Azure
- В группе ресурсов выберите ресурс кластера HDInsight
- Выберите действия скрипта
- На панели Отправка действия скрипта выберите Тип скрипта в качестве настраиваемого
- Вставьте следующую ссылку в поле URL-адреса скрипта Bash https://hdiconfigactions.blob.core.windows.net/log-analytics-patch/OMSUPGRADE14.1/omsagent-vulnerability-fix-1.14.12-0.sh
- Выберите Тип(ы) узлов
- Нажмите кнопку Создать
Проверьте успешную установку исправления, выполнив следующие действия:
Войдите в кластер с помощью SSH.
Выполните следующую команду в клиенте SSH.
sudo /opt/omi/bin/ominiserver/ --version
Исправления других ошибок
- Интерфейс командной строки журнала Yarn не смог получить журналы, если какой-либо
TFileповрежден или пуст. - Устранена ошибка с недопустимыми сведениями о субъекте-службе при получении маркера OAuth из Azure Active Directory.
- Повышена надежность создания кластера при настройке 100 и более рабочих узлов.
Исправления ошибок открытого исходного кода
Исправления ошибок TEZ
| Исправления ошибок | Apache JIRA |
|---|---|
| Сбой сборки Tez: FileSaver.js не найден | TEZ-4411 |
Неправильное исключение FS, если хранилище и scratchdir находятся на разных FS |
TEZ-4406 |
| TezUtils.createConfFromByteString при конфигурации размером более 32 MB выбрасывает исключение com.google.protobuf.CodedInputStream | TEZ-4142 |
| TezUtils::createByteStringFromConf должен использовать snappy вместо DeflaterOutputStream | TEZ-4113 |
| Обновление зависимости protobuf до версии 3.x | TEZ-4363 |
Исправления ошибок Hive
| Исправления ошибок | Apache JIRA |
|---|---|
| Оптимизация производительности при генерации сплитов ORC | HIVE-21457 |
| Избегайте интерпретации таблицы как ACID, если имя таблицы начинается с "DELTA", но таблица не является транзакционной, и используется стратегия разделения в бизнес-аналитике. | HIVE-22582 |
| Удалите вызов FS#exists из AcidUtils#getLogicalLength | HIVE-23533 |
| Векторный OrcAcidRowBatchReader.computeOffset и оптимизация контейнеров | HIVE-17917 |
Известные проблемы
HDInsight совместим с Apache HIVE версии 3.1.2. Вследствие ошибки в этом выпуске версия Hive отображается как 3.1.0 в интерфейсах Hive. Тем не менее, это не влияет на функциональность.
Дата выпуска: 03.06.2022
Этот выпуск применим к HDInsight версии 4.0. Выпуск HDInsight предоставляется для разных регионов на протяжении нескольких дней. Указанная здесь дата выпуска обозначает дату выпуска для первого из регионов. Если вы не видите следующие изменения, дождитесь момента, когда выпуск станет доступным в вашем регионе в течение следующих нескольких дней.
Краткие сведения о выпуске
Hive Warehouse Connector (HWC) для Spark версии 3.1.2
Hive Warehouse Connector (HWC) позволяет использовать преимущества уникальных функций Hive и Spark для создания мощных приложений для работы с большими данными. Сейчас HWC поддерживается только для Spark версии 2.4. Эта функция обеспечивает поддержку транзакций ACID в таблицах Hive с помощью Spark. Эта функция полезна для клиентов, использующих Hive и Spark для работы с данными. Дополнительные сведения см. в статье Apache Spark и Hive — Соединитель хранилища Hive — Azure HDInsight | Документация Майкрософт
Ambari
- Изменения в масштабировании и подготовке
- HDI Hive теперь совместим с OSS версии 3.1.2
HDI Hive 3.1 обновлен до OSS Hive 3.1.2. Эта версия содержит все исправления и функции, доступные в версии Hive 3.1.2 с открытым кодом.
Примечание.
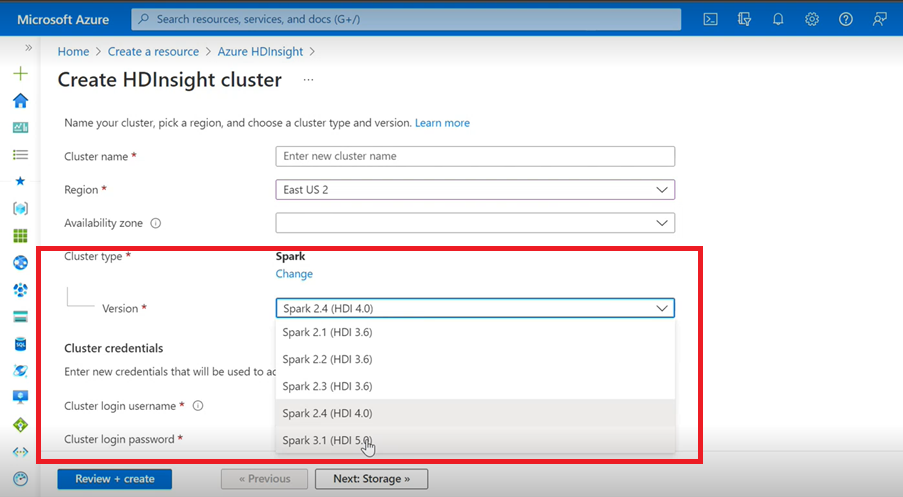
Искра
- Если вы создаете кластер Spark для HDInsight с помощью пользовательского интерфейса Azure, вы увидите в раскрывающемся списке еще одну версию Spark 3.1. (HDI 5.0) вместе с более старыми версиями. Это переименованная версия Spark 3.1. (HDI 4.0). Это изменение на уровне пользовательского интерфейса, которое не влияет на существующих пользователей и пользователей, которые уже используют шаблон ARM.
Примечание.
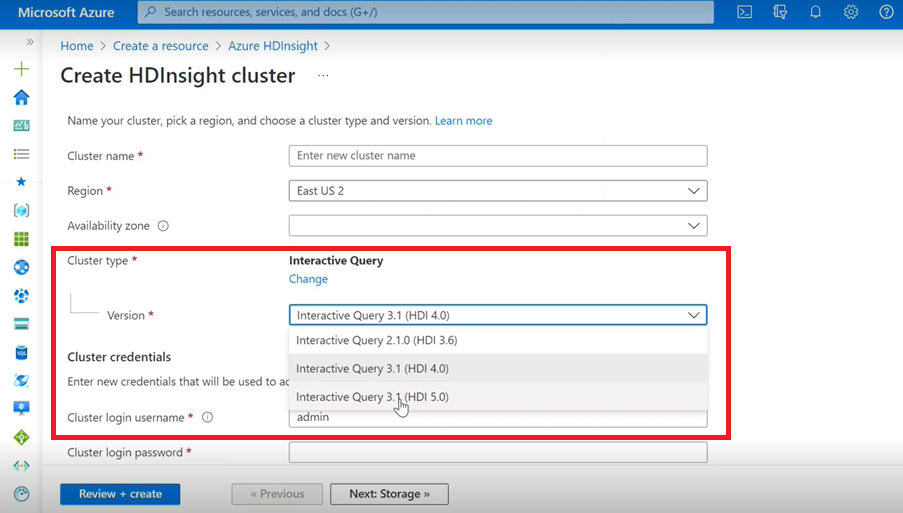
Интерактивный запрос
- При создании кластера Interactive Query вы увидите в раскрывающемся списке еще одну версию под названием Interactive Query 3.1 (HDI 5.0).
- Если вы собираетесь использовать Spark 3.1 вместе с Hive, для которого требуется поддержка ACID, необходимо выбрать эту версию Interactive Query 3.1 (HDI 5.0).
Исправления ошибок TEZ
| Исправления ошибок | Apache JIRA |
|---|---|
| TezUtils.createConfFromByteString при конфигурации размером более 32 MB выбрасывает исключение com.google.protobuf.CodedInputStream | TEZ-4142 |
| TezUtils createByteStringFromConf должен использовать snappy вместо DeflaterOutputStream | TEZ-4113 |
Исправление ошибок HBase
| Исправления ошибок | Apache JIRA |
|---|---|
TableSnapshotInputFormat должен использовать ReadType.STREAM для сканирования HFiles |
HBASE-26273 |
| Добавление параметра для отключения scanMetrics в TableSnapshotInputFormat | HBASE-26330 |
| Исправление для ArrayIndexOutOfBoundsException при выполнении балансировки | HBASE-22739 |
Исправления ошибок Hive
| Исправления ошибок | Apache JIRA |
|---|---|
| NPE при вставке данных с предложением "distribute by" с оптимизацией сортировки dynpart | HIVE-18284 |
| Команда MSCK REPAIR с фильтрацией разделов завершается сбоем в процессе удаления разделов. | HIVE-23851 |
| Неправильное исключение, если емкость <=0 | HIVE-25446 |
| Поддержка параллельной загрузки для HastTables — интерфейсы | HIVE-25583 |
| Включение MultiDelimitSerDe в HiveServer2 по умолчанию | HIVE-20619 |
| Удаление классов glassfish.jersey и mssql-jdbc из jdbc-standalone jar | HIVE-22134 |
| Исключение пустого указателя при выполнении сжатия по таблице MM. | HIVE-21280 |
Запрос Hive большого размера через knox терпит неудачу при записи из-за разрыва соединения. |
HIVE-22231 |
| Добавление возможности для пользователей задавать привязку пользователя | HIVE-21009 |
| Реализовать пользовательскую функцию (UDF) для интерпретации даты/временной метки с использованием внутреннего представления и гибридного григорианско-юлианского календаря. | HIVE-22241 |
| Опция Beeline для отображения или скрытия отчета о выполнении | HIVE-22204 |
| Tez: SplitGenerator пытается искать файлы плана, которые не существуют для Tez | HIVE-22169 |
Удалите дорогостоящее логирование из кэша LLAP hotpath |
HIVE-22168 |
| UDF: FunctionRegistry синхронизируется с классом org.apache.hadoop.hive.ql.udf.UDFType | HIVE-22161 |
| Запрет на создание аппендера маршрутизации запросов, если свойству присвоено значение false | HIVE-22115 |
| Удалить синхронизацию между запросами для оценки разделов | HIVE-22106 |
| Пропуск настройки hive scratch dir при планировании | HIVE-21182 |
| Пропуск создания scratch dir для tez, если включен RPC | HIVE-21171 |
Переключите пользовательские функции Hive на использование Re2J движка регулярных выражений |
HIVE-19661 |
| Перенесенные кластеризованные таблицы, использующие bucketing_version 1 на hive 3, используют bucketing_version 2 для вставок. | HIVE-22429 |
| Сегментирование. Сегментирование версии 1 неправильно секционирует данные | HIVE-21167 |
| Добавление заголовка лицензии ASF в только что добавленный файл | HIVE-22498 |
| Усовершенствования инструмента для работы с схемами для поддержки функции mergeCatalog | HIVE-22498 |
| Hive с TEZ, UNION ALL и UDTF вызывает потерю данных | HIVE-21915 |
| Разделение текстовых файлов даже в том случае, если существует верхний/нижний колонтитул | HIVE-21924 |
| MultiDelimitSerDe возвращает неправильные результаты в последнем столбце, если загруженный файл содержит больше столбцов, чем в схеме таблицы. | HIVE-22360 |
| Внешний клиент LLAP — необходимо уменьшить объем занимаемой памяти для LlapBaseInputFormat#getSplits() | HIVE-22221 |
| Имя столбца с зарезервированным ключевым словом раскодируется (unescape) при перезаписи запроса, включая операцию join в таблице со столбцом маски (Zoltan Matyus через Zoltan Haindrich) | HIVE-22208 |
Предотвратить завершение работы LLAP в связи с RuntimeException, связанной с AMReporter. |
HIVE-22113 |
| Драйвер службы состояния LLAP может застрять из-за неправильного идентификатора приложения Yarn | HIVE-21866 |
| OperationManager.queryIdOperation неправильно очищает несколько идентификаторов запросов | HIVE-22275 |
| Отключение диспетчера узлов блокирует перезапуск службы LLAP | HIVE-22219 |
| Stack OverflowError при удалении большого количества секций | HIVE-15956 |
| Проверка доступа завершается сбоем при удалении временного каталога | HIVE-22273 |
| Исправление неправильных результатов или исключения ArrayOutOfBound в левых внешних соединениях схемы в определенных условиях границ | HIVE-22120 |
| Удаление тега управления распространением из pom.xml | HIVE-19667 |
| Синтаксический анализ может занимать больше времени при наличии глубоко вложенных запросов | HIVE-21980 |
Для ALTER TABLE t SET TBLPROPERTIES ('EXTERNAL'='TRUE'); изменения атрибута TBL_TYPE не отражаются, если записано не прописными буквами |
HIVE-20057 |
JDBC: HiveConnection оттеняет интерфейсы log4j |
HIVE-18874 |
Обновление URL-адресов репозитория в poms ветви 3.1 версии |
HIVE-21786 |
DBInstall Неработающие тесты в ветках master и branch-3.1 |
HIVE-21758 |
| Загрузка данных в сегментированную таблицу игнорирует спецификации секций и загружает данные в секцию по умолчанию | HIVE-21564 |
| Запросы с условием объединения, содержащим метку времени или метку времени с указанием местного часового пояса, вызывают исключение SemanticException | HIVE-21613 |
| Анализ статистики вычислений для столбца не учитывает промежуточный dir в HDFS | HIVE-21342 |
| Несовместимое изменение в вычислениях контейнера Hive | HIVE-21376 |
| Предоставьте резервное средство авторизации, если не используется другое средство авторизации | HIVE-20420 |
| Некоторые вызовы alterPartitions вызывают исключение NumberFormatException: null | HIVE-18767 |
| HiveServer2: в некоторых случаях предварительно аутентифицированный субъект для HTTP-транспорта не удерживается на всё время HTTP-соединения | HIVE-20555 |
Дата выпуска: 10.03.2022
Этот выпуск применим к HDInsight версии 4.0. Выпуск HDInsight предоставляется для разных регионов на протяжении нескольких дней. Указанная здесь дата выпуска обозначает дату выпуска для первого из регионов. Если вы не видите следующие изменения, дождитесь момента, когда выпуск станет доступным в вашем регионе в течение следующих нескольких дней.
Версии ОС для этого выпуска:
- HDInsight 4.0: Ubuntu 18.04.5
Выпущена общедоступная версия Spark 3.1
Версия Spark 3.1 теперь общедоступна в HDInsight 4.0. В этот выпуск входят:
- адаптивное выполнение запросов;
- Преобразовать соединение сортировки слиянием в широковещательное хэш-соединение.
- оптимизатор Spark Catalyst;
- динамическая обрезка партиций
- клиенты смогут создавать новые кластеры Spark 3.1, а не кластеры Spark 3.0 (предварительная версия).
Подробнее см. в статье "Версия Apache Spark 3.1 теперь общедоступна в HDInsight" от сообщества Microsoft Tech Community.
Полный список улучшений см. в заметках о выпуске Apache Spark 3.1.
Подробнее о миграции см. в руководстве по миграции.
Выпущена общедоступная версия Kafka 2.4
Выпущена общедоступная версия Kafka 2.4.1. Дополнительные сведения см. в заметках о выпуске Kafka 2.4.1. Другие функции включают доступность MirrorMaker 2, новую категорию метрик AtMinIsr для разделов тем, улучшенное время запуска брокера за счет отложенной загрузки файлов индекса по запросу mmap, дополнительные метрики потребителей для наблюдения за поведением потребителя при опросе.
Тип данных Map в HWC теперь поддерживается в HDInsight 4.0
Этот релиз включает поддержку типа данных Map для HWC 1.0 (Spark 2.4) через приложение spark-shell, а также поддерживается всеми другими клиентами Spark, поддерживаемыми HWC. Следующие усовершенствования включены так же, как и для других типов данных:
Пользователь может выполнять следующие действия:
- Создать таблицу Hive с любыми столбцами, содержащими тип данных Map, вставлять в него данные и считывать из него результаты.
- Создать кадр данных Apache Spark с типом Map и выполнять пакетные/потоковые операции чтения и записи.
Новые регионы
Теперь HDInsight расширил свое географическое присутствие на два новых региона: "Восточный Китай 3" и "Северный Китай 3".
Изменения в бэкпорте OSS
Бэкпорты OSS, входящие в состав Hive, включая HWC 1.0 (Spark 2.4), который поддерживает тип данных Map.
Представлены обратно портированные OSS задачи Apache JIRA для данного выпуска:
| Затронутая функция | Apache JIRA |
|---|---|
| Прямые SQL-запросы к метахранилищу с IN/NOT IN должны быть разделены на основе максимального числа параметров, разрешенного базой данных SQL. | HIVE-25659 |
Обновление log4j 2.16.0 до версии 2.17.0 |
HIVE-25825 |
Обновление версии Flatbuffer |
HIVE-22827 |
| Встроенная поддержка типа данных Map в формате Arrow. | HIVE-25553 |
| Внешний клиент LLAP — обработка вложенных значений, если родительская структура имеет значение NULL. | HIVE-25243 |
| Обновление версии arrow до 0.11.0. | HIVE-23987 |
Примечания об устаревании
Масштабируемые наборы виртуальных машин Azure в HDInsight
HDInsight больше не будет использовать масштабируемые наборы виртуальных машин Azure для развертывания кластеров. Существенные изменения не ожидаются. Существующие кластеры HDInsight в масштабируемых наборах виртуальных машин не подвержены изменениям, но новые кластеры на последних версиях образов больше не будут использовать масштабируемые наборы виртуальных машин.
Масштабирование рабочих нагрузок Azure HDInsight HBase теперь будет поддерживаться только вручную.
Начиная с 1 марта 2022 г. HDInsight поддерживает для HBase только масштабирование вручную, но не оказывает влияния на работу кластеров. Новые кластеры HBase не смогут включить автомасштабирование на основе расписания. Дополнительные сведения о том, как вручную масштабировать кластер HBase, см. в документации по масштабированию кластеров Azure HDInsight вручную.
Дата выпуска: 27.12.2021
Этот выпуск применим к HDInsight версии 4.0. Выпуск HDInsight предоставляется для разных регионов на протяжении нескольких дней. Указанная здесь дата выпуска обозначает дату выпуска для первого из регионов. Если вы не видите следующие изменения, дождитесь момента, когда выпуск станет доступным в вашем регионе в течение следующих нескольких дней.
Версии ОС для этого выпуска:
- HDInsight 4.0: Ubuntu 18.04.5 LTS
Образ HDInsight 4.0 обновлен для устранения уязвимости Log4j, как указано в ответе Майкрософт на CVE-2021-44228 Apache Log4j 2.
Примечание.
- Все кластеры HDI 4.0, созданные после 27 декабря 2021 г. 00:00 UTC, создаются с обновленной версией образа, который устраняет
log4jуязвимости. Следовательно, клиентам не требуется исправление или перезагрузка этих кластеров. - Для новых кластеров HDInsight 4.0, созданных между 01:15 UTC 16 декабря 2021 г. и 00:00 UTC 27 декабря 2021 г., HDInsight 3.6 или в закрепленных подписках после 16 декабря 2021 г., исправление будет применено в течение часа, в течение которого создается кластер, однако клиенты должны перезагрузить свои узлы для завершения установки исправлений (за исключением узлов управления Kafka, которые перезагружаются автоматически).
Дата выпуска: 27.07.2021
Этот выпуск применим к версиям HDInsight 3.6 и HDInsight 4.0. Выпуск HDInsight предоставляется для разных регионов на протяжении нескольких дней. Указанная здесь дата выпуска обозначает дату выпуска для первого из регионов. Если вы не видите следующие изменения, подождите, пока обновление станет доступным в вашем регионе через несколько дней.
Версии ОС для этого выпуска:
- HDInsight 3.6: Ubuntu 16.04.7 LTS
- HDInsight 4.0: Ubuntu 18.04.5 LTS
Новые возможности
Поддержка Azure HDInsight для ограниченного общедоступного подключения доступна всем с 15 октября 2021 г.
Azure HDInsight теперь поддерживает ограниченное общедоступное подключение во всех регионах. Ниже приведены некоторые ключевые особенности этой возможности.
- Возможность изменить направление связи от кластера к поставщику ресурсов, так чтобы коммуникация исходила от кластера к поставщику ресурсов.
- Поддержка использования ваших собственных ресурсов с поддержкой Private Link (например, хранилища, SQL, хранилища ключей) для кластера HDInsight для доступа к ресурсам только через частную сеть
- Общедоступные IP-адреса не выделены как ресурсы
Используя эту новую функцию, вы также можете обойти правила служебных тегов входящей группы безопасности сети (NSG) для IP-адресов управления HDInsight. Узнайте больше об ограничении общедоступного подключения
Общедоступная версия службы поддержки Azure HDInsight для Azure Private Link доступна с15 октября 2021 г.
Теперь частные конечные точки можно использовать для подключения к кластерам HDInsight по частной ссылке. Приватный канал можно использовать в сценариях с несколькими виртуальными сетями, когда пиринг виртуальных сетей недоступен или не включен.
Приватный канал Azure обеспечивает доступ к службам Azure PaaS (например, к службе хранилища Azure и Базе данных SQL), а также размещенным в Azure службам, которые принадлежат клиенту или партнеру, через частную конечную точку виртуальной сети.
Трафик между виртуальной сетью и службой проходит через магистральную сеть Майкрософт. Предоставлять доступ к вашей службе через общедоступный Интернет больше не требуется.
Узнайте больше о включении приватной связи.
Новые интерфейсы интеграции Azure Monitor (предварительная версия)
В этом выпуске новый опыт интеграции Azure Monitor будет представлен в предварительной версии в Восточных регионах США и Западной Европе. Дополнительные сведения о новом интерфейсе Azure Monitor см. здесь.
Депрекация
Версия HDInsight 3.6 снята с поддержки с 1 октября 2022 г.
Изменения в поведении
Интерактивный запрос HDInsight поддерживает только автомасштабирование по расписанию
По мере того, как сценарии клиентов становятся более зрелыми и разнообразными, мы выявили некоторые ограничения автомасштабирования на основе интерактивных запросов (LLAP). Эти ограничения обусловлены характером динамики запросов LLAP, проблемами с точностью прогнозирования нагрузки в будущем и проблемами при перераспределении задач планировщика LLAP. Из-за этих ограничений пользователи могут видеть, что запросы выполняются медленнее в кластерах LLAP при включении автомасштабирования. Влияние на производительность может перевесить преимущества автомасштабирования по затратам.
Начиная с июля 2021 года рабочая нагрузка Interactive Query в HDInsight поддерживает только автомасштабирование по расписанию. Невозможно более включить автомасштабирование на основе нагрузки для новых кластеров Interactive Query. Существующие работающие кластеры по-прежнему могут работать с известными ограничениями, описанными выше.
Корпорация Майкрософт рекомендует выбрать функцию автомасштабирования по расписанию для LLAP. Вы можете проанализировать текущую модель использования кластера на панели мониторинга Grafana Hive. Дополнительные сведения см. в разделе Автоматическое масштабирование кластеров Azure HDInsight.
Предстоящие изменения
В предстоящих выпусках произойдут следующие изменения.
Встроенный компонент LLAP в кластере ESP Spark будет удален
Кластер HDInsight 4.0 ESP Spark содержит встроенные компоненты LLAP, работающие на обоих головных узлах. Компоненты LLAP в кластере ESP Spark изначально были добавлены для HDInsight 3.6 ESP Spark, но не имеют реальных вариантов использования для HDInsight 4.0 ESP Spark. В следующем выпуске, запланированном на сентябрь 2021 г., HDInsight удалит встроенный компонент LLAP из кластера HDInsight 4.0 ESP Spark. Это изменение помогает выгрузить рабочую нагрузку головного узла и избежать путаницы между типом кластера ESP Spark и ESP Interactive Hive.
Новый регион
- Запад США 3
-
JioЗападная Индия - Центральная Австралия
Изменение версий компонентов
В этом выпуске изменена следующая версия компонента:
- ORC с версии 1.5.1 по версию 1.5.9.
Текущие версии компонентов для HDInsight 4.0 и HDInsight 3.6 см. в этом документе.
Обратно портированные JIRA
Приведенные ниже Apache JIRA обратно портированы для этого выпуска:
| Затронутая функция | Apache JIRA |
|---|---|
| Дата / метка времени | HIVE-25104 |
| HIVE-24074 | |
| HIVE-22840 | |
| HIVE-22589 | |
| HIVE-22405 | |
| HIVE-21729 | |
| HIVE-21291 | |
| HIVE-21290 | |
| Пользовательская функция (UDF) | HIVE-25268 |
| HIVE-25093 | |
| HIVE-22099 | |
| HIVE-24113 | |
| HIVE-22170 | |
| HIVE-22331 | |
| ОРК (Оптическое Распознавание Символов) | HIVE-21991 |
| HIVE-21815 | |
| HIVE-21862 | |
| Схема таблицы | HIVE-20437 |
| HIVE-22941 | |
| HIVE-21784 | |
| HIVE-21714 | |
| HIVE-18702 | |
| HIVE-21799 | |
| HIVE-21296 | |
| Управление рабочей нагрузкой | HIVE-24201 |
| Сжатие | HIVE-24882 |
| HIVE-23058 | |
| HIVE-23046 | |
| Материализованное представление | HIVE-22566 |
Исправление цен для HDInsight Dv2 Виртуальные машины
Ошибка ценообразования была исправлена 25 апреля 2021 г. для Dv2 серии виртуальных машин в HDInsight. Ошибка ценообразования привела к снижению платы за некоторые счета клиента до 25 апреля, и с исправлением цены теперь соответствуют тому, что было объявлено на странице ценообразования HDInsight и калькуляторе цен HDInsight. Ошибка ценообразования повлияла на клиентов в следующих регионах, которые использовали Dv2 виртуальные машины:
- Центральная Канада
- Восточная Канада
- Восточная Азия
- Северная часть ЮАР;
- Юго-Восточная Азия
- Центральная часть ОАЭ
Начиная с 25 апреля 2021 г. исправленная сумма для Dv2 виртуальных машин будет находиться в вашей учетной записи. Перед изменением владельцам подписок было направлено соответствующее уведомление. Вы можете использовать калькулятор цен, страницу цен HDInsight или вкладку "Создание кластера HDInsight" на портале Azure, чтобы просмотреть исправленные затраты на Dv2 виртуальные машины в вашем регионе.
От вас никаких дополнительных действий не требуется. Корректировка цены будет применена для использования только 25 апреля 2021 г. или после этой даты в указанных регионах, но не в отношении использования в период до этой даты. Чтобы обеспечить наиболее эффективное и экономичное решение, мы рекомендуем просмотреть цены, VCPU и ОЗУ для Dv2 кластеров и сравнить Dv2 спецификации с Ev3 виртуальными машинами, чтобы оценить, выиграет ли ваше решение от использования одной из новых серий виртуальных машин.
Дата выпуска: 02.06.2021
Этот выпуск применим к версиям HDInsight 3.6 и HDInsight 4.0. Выпуск HDInsight предоставляется для разных регионов на протяжении нескольких дней. Указанная здесь дата выпуска обозначает дату выпуска для первого из регионов. Если вы не видите следующие изменения, подождите, пока обновление станет доступным в вашем регионе через несколько дней.
Версии ОС для этого выпуска:
- HDInsight 3.6: Ubuntu 16.04.7 LTS
- HDInsight 4.0: Ubuntu 18.04.5 LTS
Новые возможности
Обновление версии ОС
Как указано в цикле выпуска Ubuntu, ядро Ubuntu 16.04 достигает конца жизни (EOL) в апреле 2021 года. Мы начали развертывание нового образа кластера HDInsight 4.0, работающего под управлением Ubuntu 18.04, одновременно с этим выпуском. Вновь созданные кластеры HDInsight 4.0 работают в Ubuntu 18.04 по умолчанию, как только они становятся доступны. Существующие кластеры на Ubuntu 16.04 работают в неизменном виде с полной поддержкой.
Служба HDInsight 3.6 продолжит работать на платформе Ubuntu 16.04. С 1 июля 2021 года поддержка изменится с "Стандартной" на "Базовую". Дополнительные сведения о датах и вариантах поддержки см. в статье Версии Azure HDInsight. Платформа Ubuntu 18.04 не будет поддерживаться для HDInsight 3.6. Если вы хотите использовать Ubuntu 18.04, необходимо перенести кластеры в HDInsight 4.0.
Если вы хотите переместить существующие кластеры HDInsight 4.0 в Ubuntu 18.04, удалите и повторно создайте их. Запланируйте создание или повторное создание кластеров после того, как станет доступна поддержка Ubuntu 18.04.
После создания нового кластера вы сможете использовать SSH-подключение к кластеру и выполнить sudo lsb_release -a, чтобы убедиться, что на нем выполняется Ubuntu 18.04. Рекомендуем сначала протестировать ваши приложения в тестовых подписках, прежде чем перемещать их в рабочую среду.
Оптимизация масштабирования в кластерах HBase с ускоренной записью
В HDInsight внесены улучшения и оптимизации масштабирования в кластерах с поддержкой ускоренной записи на базе HBase. Узнайте больше об ускоренной записи HBase.
Депрекация
В этом выпуске нет устаревших элементов.
Изменения в поведении
Отключение размера виртуальной машины Standard_A5 в качестве головного узла для HDInsight 4.0
Головной узел кластера HDInsight отвечает за инициализацию и управление кластером. Виртуальные машины размера Standard_A5 недостаточно надежны в качестве головного узла HDInsight 4.0. Начиная с этого выпуска, клиенты не смогут создавать новые кластеры с конфигурацией виртуальной машины Standard_A5 в роли головного узла. Вы можете использовать другие 2-ядерные виртуальные машины, такие как E2_v3 или E2s_v3. Существующие кластеры будут работать как обычно. Для головного узла настоятельно рекомендуется виртуальная машина с 4 ядрами, чтобы обеспечивать высокий уровень доступности и надежности для кластеров HDInsight в рабочей среде.
Ресурс сетевого интерфейса не отображается для кластеров, которые работают в масштабируемых наборах виртуальных машин Azure
HDInsight постепенно переходит на масштабируемые наборы виртуальных машин Azure. Сетевые интерфейсы для виртуальных машин больше не видны клиентам кластеров, использующих масштабируемые наборы виртуальных машин Azure.
Предстоящие изменения
В предстоящих выпусках будут внесены описанные ниже изменения.
Интерактивный запрос HDInsight поддерживает только автомасштабирование по расписанию
По мере того, как сценарии клиентов становятся более зрелыми и разнообразными, мы выявили некоторые ограничения автомасштабирования на основе интерактивных запросов (LLAP). Эти ограничения обусловлены характером динамики запросов LLAP, проблемами с точностью прогнозирования нагрузки в будущем и проблемами при перераспределении задач планировщика LLAP. Из-за этих ограничений пользователи могут видеть, что запросы выполняются медленнее в кластерах LLAP при включении автомасштабирования. Влияние на производительность может перевесить преимущества автомасштабирования по затратам.
Начиная с июля 2021 года рабочая нагрузка Interactive Query в HDInsight поддерживает только автомасштабирование по расписанию. Включение автомасштабирования для новых кластеров интерактивных запросов будет недоступно. Существующие работающие кластеры по-прежнему могут работать с известными ограничениями, описанными выше.
Корпорация Майкрософт рекомендует выбрать функцию автомасштабирования по расписанию для LLAP. Вы можете проанализировать текущую модель использования кластера на панели мониторинга Grafana Hive. Дополнительные сведения см. в разделе Автоматическое масштабирование кластеров Azure HDInsight.
Именование узлов виртуальных машин изменено с 1 июля 2021 г.
Сейчас HDInsight использует для подготовки кластера виртуальные машины Azure. Служба постепенно переходит на масштабируемые наборы виртуальных машин Azure. Эта миграция изменит формат полного доменного имени (FQDN) узла кластера, а числа в именах узлов не обязательно будут идти по порядку. Если вы хотите получить полные доменные имена для каждого узла, обратитесь к разделу Поиск имен узлов кластера.
Перейдите на масштабируемые наборы виртуальных машин Azure
Сейчас HDInsight использует для подготовки кластера виртуальные машины Azure. Служба постепенно перейдет на масштабируемые наборы виртуальных машин Azure. Весь процесс может занять несколько месяцев. После переноса регионов и подписок все созданные кластеры HDInsight будут выполняться в масштабируемых наборах виртуальных машин, и для этого не требуются действия со стороны клиента. Критических изменений не ожидается.
Дата выпуска: 24.03.2021
Новые возможности
Предварительная версия Spark 3.0
Поддержка Spark 3.0.0 была добавлена в HDInsight 4.0 в качестве предварительной версии.
Предварительная версия Kafka 2.4
HDInsight добавил поддержку Kafka 2.4.1 к HDInsight 4.0 в качестве предварительной версии.
Eav4Поддержка серии
В этом выпуске добавлена поддержка серии Eav4 HDInsight.
Переход на масштабируемые наборы виртуальных машин Azure
Сейчас HDInsight использует для подготовки кластера виртуальные машины Azure. Служба постепенно переходит на масштабируемые наборы виртуальных машин Azure. Весь процесс может занять несколько месяцев. После переноса регионов и подписок все созданные кластеры HDInsight будут выполняться в масштабируемых наборах виртуальных машин, и для этого не требуются действия со стороны клиента. Критических изменений не ожидается.
Депрекация
В этом выпуске нет устаревших элементов.
Изменения в поведении
Версия кластера по умолчанию изменена на 4.0.
Версия кластера HDInsight по умолчанию изменена с 3.6 на 4.0. Дополнительные сведения о доступных версиях см. здесь. Изучите подробнее новые возможности HDInsight 4.0.
Размеры виртуальных машин кластера по умолчанию изменены на Ev3-series.
Размеры виртуальных машин кластера по умолчанию изменяются с серии D на Ev3-series. Это изменение применимо к головным узлам и рабочим узлам. Чтобы это изменение не затронуло проверенные рабочие процессы, укажите в шаблоне ARM правильные размеры виртуальных машин, которые вы хотите использовать.
Ресурс сетевого интерфейса не отображается для кластеров, которые работают в масштабируемых наборах виртуальных машин Azure
HDInsight постепенно переходит на масштабируемые наборы виртуальных машин Azure. Сетевые интерфейсы для виртуальных машин больше не видны клиентам кластеров, использующих масштабируемые наборы виртуальных машин Azure.
Предстоящие изменения
В предстоящих выпусках будут внесены описанные ниже изменения.
Интерактивный запрос HDInsight поддерживает только автомасштабирование по расписанию
По мере того, как сценарии клиентов становятся более зрелыми и разнообразными, мы выявили некоторые ограничения автомасштабирования на основе интерактивных запросов (LLAP). Эти ограничения обусловлены характером динамики запросов LLAP, проблемами с точностью прогнозирования нагрузки в будущем и проблемами при перераспределении задач планировщика LLAP. Из-за этих ограничений пользователи могут видеть, что запросы выполняются медленнее в кластерах LLAP при включении автомасштабирования. Влияние на производительность может перевесить стоимость преимуществ автомасштабирования.
Начиная с июля 2021 года рабочая нагрузка Interactive Query в HDInsight поддерживает только автомасштабирование по расписанию. Включение автомасштабирования для новых кластеров интерактивных запросов будет недоступно. Существующие работающие кластеры по-прежнему могут работать с известными ограничениями, описанными выше.
Корпорация Майкрософт рекомендует выбрать функцию автомасштабирования по расписанию для LLAP. Вы можете проанализировать текущую модель использования кластера на панели мониторинга Grafana Hive. Дополнительные сведения см. в разделе Автоматическое масштабирование кластеров Azure HDInsight.
Обновление версии ОС
Кластеры HDInsight в настоящее время работают под управлением Ubuntu 16.04 LTS. Как сказано в примечаниях к циклу выпуска Ubuntu, ядро Ubuntu 16.04 будет выведено из обращения в апреле 2021. Мы начали развертывание нового образа кластера HDInsight 4.0, работающего под управлением Ubuntu 18.04, в мае 2021 года. Недавно созданные кластеры HDInsight 4.0 будут работать под управлением Ubuntu 18.04 по умолчанию. Существующие кластеры Ubuntu 16.04 будут работать "как есть" и обеспечиваться полной поддержкой.
Служба HDInsight 3.6 продолжит работать на платформе Ubuntu 16.04. Поддержка стандартной версии завершится 30 июня 2021 года и перейдет на базовую поддержку начиная с 1 июля 2021 года. Дополнительные сведения о датах и вариантах поддержки см. в статье Версии Azure HDInsight. Платформа Ubuntu 18.04 не будет поддерживаться для HDInsight 3.6. Если вы хотите использовать Ubuntu 18.04, необходимо перенести кластеры в HDInsight 4.0.
Если вы хотите переместить существующие кластеры в Ubuntu 18.04, удалите и повторно создайте их. Запланируйте создание или повторное создание кластера после того, как станет доступна поддержка Ubuntu 18.04. После того как новый образ станет доступен во всех регионах, мы отправим вам другое уведомление.
Настоятельно рекомендуется заранее протестировать действия сценария и пользовательские приложения, развернутые на граничных узлах на виртуальной машине Ubuntu 18.04. Виртуальную машину Ubuntu Linux можно создать на виртуальной машине 18.04-LTS, а затем создать и использовать пару ключей безопасной оболочки (SSH) на виртуальной машине для запуска и тестирования действий скрипта и пользовательских приложений, развернутых на пограничных узлах.
Отключение размера виртуальной машины Standard_A5 в качестве головного узла для HDInsight 4.0
Головной узел кластера HDInsight отвечает за инициализацию и управление кластером. Виртуальные машины размера Standard_A5 недостаточно надежны в качестве головного узла HDInsight 4.0. Начиная с следующего выпуска в мае 2021 года клиенты не смогут создавать новые кластеры с размером виртуальной машины Standard_A5 в качестве головного узла. Вы можете использовать другие 2-ядерные виртуальные машины, такие как E2_v3 или E2s_v3. Существующие кластеры будут работать как обычно. Для головного узла требуется виртуальная машина с не менее чем 4 ядрами, чтобы обеспечивать высокий уровень доступности и надежности для кластеров HDInsight в рабочей среде.
Исправления ошибок
HDInsight постоянно повышает надежность и производительность кластеров.
Изменение версий компонентов
Добавлена поддержка Spark 3.0.0 и Kafka 2.4.1 в предварительной версии. Текущие версии компонентов для HDInsight 4.0 и HDInsight 3.6 см. в этом документе.
Дата выпуска: 05.02.2021
Этот выпуск применим к версиям HDInsight 3.6 и HDInsight 4.0. Выпуск HDInsight предоставляется для разных регионов на протяжении нескольких дней. Указанная здесь дата выпуска обозначает дату выпуска для первого из регионов. Если вы не видите следующие изменения, подождите, пока обновление станет доступным в вашем регионе через несколько дней.
Новые возможности
Поддержка серии Dav4
В HDInsight добавлена поддержка серии Dav4, начиная с этого выпуска. Подробную информацию о серии Dav4 см. здесь.
Общее применение REST-прокси Kafka
Прокси-сервер REST для Kafka позволяет взаимодействовать с кластером Kafka через REST API по протоколу HTTPS. Прокси-сервер REST для Kafka является общедоступным, начиная с этого выпуска. Дополнительные сведения о прокси-сервере REST для Kafka см. здесь.
Переход на масштабируемые наборы виртуальных машин Azure
Сейчас HDInsight использует для подготовки кластера виртуальные машины Azure. Служба постепенно переходит на масштабируемые наборы виртуальных машин Azure. Весь процесс может занять несколько месяцев. После переноса регионов и подписок все созданные кластеры HDInsight будут выполняться в масштабируемых наборах виртуальных машин, и для этого не требуются действия со стороны клиента. Критических изменений не ожидается.
Депрекация
Размеры отключенных виртуальных машин
Начиная с 9 января 2021 г., HDInsight блокирует всех клиентов, создающих кластеры с использованием размеров виртуальных машин стандартов A8, A9, A10 и A11. Существующие кластеры будут работать как обычно. Постарайтесь перейти на версию HDInsight 4.0, чтобы избежать потенциальных перерывов в работе или обслуживании.
Изменения в поведении
Размер виртуальной машины по умолчанию в кластере изменяется на серию Ev3
Размеры виртуальных машин кластера по умолчанию будут изменены с серии D на Ev3-series. Это изменение применимо к головным узлам и рабочим узлам. Чтобы это изменение не затронуло проверенные рабочие процессы, укажите в шаблоне ARM правильные размеры виртуальных машин, которые вы хотите использовать.
Ресурс сетевого интерфейса не отображается для кластеров, которые работают в масштабируемых наборах виртуальных машин Azure
HDInsight постепенно переходит на масштабируемые наборы виртуальных машин Azure. Сетевые интерфейсы для виртуальных машин больше не видны клиентам кластеров, использующих масштабируемые наборы виртуальных машин Azure.
Предстоящие изменения
В предстоящих выпусках будут внесены описанные ниже изменения.
Версия кластера по умолчанию будет изменена на 4.0
Начиная с февраля 2021 г., версия кластера HDInsight по умолчанию будет изменена с 3.6 на 4.0. Дополнительные сведения о доступных версиях см. здесь. Изучите подробнее новые возможности HDInsight 4.0.
Обновление версии ОС
В HDInsight будет обновлена версия операционной системы с Ubuntu 16.04 до 18.04. Это обновление будет завершено до апреля 2021 года.
Окончание поддержки HDInsight 3.6 30 июня 2021 г.
Поддержка HDInsight 3.6 будет прекращена. Начиная с 30 июня 2021 г., клиенты не смогут создавать новые кластеры HDInsight 3.6. Существующие кластеры будут продолжать работу без изменений, но без поддержки со стороны корпорации Майкрософт. Постарайтесь перейти на версию HDInsight 4.0, чтобы избежать потенциальных перерывов в работе или обслуживании.
Изменение версий компонентов
В этом выпуска не вносилось изменений в версии компонентов. Текущие версии компонентов для HDInsight 4.0 и HDInsight 3.6 см. в этом документе.
Дата выпуска: 18.11.2020
Этот выпуск применим к версиям HDInsight 3.6 и HDInsight 4.0. Выпуск HDInsight предоставляется для разных регионов на протяжении нескольких дней. Указанная здесь дата выпуска обозначает дату выпуска для первого из регионов. Если вы не видите следующие изменения, подождите, пока обновление станет доступным в вашем регионе через несколько дней.
Новые возможности
Автоматическое обновление ключей для шифрования данных в состоянии покоя с использованием ключа, управляемого клиентом
Начиная с этого релиза, клиенты могут использовать URL-адреса ключей шифрования без версионности Azure KeyVault для шифрования управляемых клиентом ключей шифрования данных в состоянии покоя. HDInsight будет выполнять автоматическую ротацию ключей по мере истечения срока их действия или заменять их новыми версиями. Дополнительные сведения см. здесь.
Возможность выбора различных размеров виртуальных машин Zookeeper для Spark, Hadoop и Служб машинного обучения
Ранее HDInsight не поддерживала настройку размера узла Zookeeper для типов кластера Spark, Hadoop и Служб машинного обучения. По умолчанию используются размеры виртуальных машин A2_v2/A2, которые предоставляются бесплатно. Начиная с этого выпуска, можно выбрать размер виртуальной машины Zookeeper, наиболее подходящий для вашего сценария. За узлы Zookeeper с размером виртуальной машины, отличным от A2_v2/A2, будет взиматься плата. Виртуальные машины A2_v2 и a2 по-прежнему предоставляются бесплатно.
Переход на масштабируемые наборы виртуальных машин Azure
Сейчас HDInsight использует для подготовки кластера виртуальные машины Azure. Начиная с этого выпуска, служба будет постепенно переноситься в масштабируемые наборы виртуальных машин Azure. Весь процесс может занять несколько месяцев. После переноса регионов и подписок все созданные кластеры HDInsight будут выполняться в масштабируемых наборах виртуальных машин, и для этого не требуются действия со стороны клиента. Критических изменений не ожидается.
Депрекация
Устаревание кластера служб машинного обучения (ML) в HDInsight 3.6
Поддержка типа кластера Служб машинного обучения HDInsight 3.6 будет прекращена 31 декабря 2020 г. Клиенты не смогут создавать новые кластеры Служб машинного обучения версии 3.6 после 31 декабря 2020 г. Существующие кластеры будут продолжать работу без изменений, но без поддержки со стороны корпорации Майкрософт. Проверьте срок действия поддержки для версий HDInsight и типов кластеров здесь.
Размеры отключенных виртуальных машин
Начиная с 16 ноября 2020 г., HDInsight будет блокировать новых клиентов от создания кластеров, используя размеры виртуальных машин standard_A8, standard_A9, standard_A10 и standard_A11. Существующие клиенты, которые использовали эти размеры виртуальных машин в течение последних трех месяцев, не будут затронуты. Начиная с 9 января 2021 г., HDInsight блокирует всех клиентов, создающих кластеры с использованием размеров виртуальных машин стандартов A8, A9, A10 и A11. Существующие кластеры будут работать как обычно. Постарайтесь перейти на версию HDInsight 4.0, чтобы избежать потенциальных перерывов в работе или обслуживании.
Изменения в поведении
Добавьте проверку правил NSG перед операцией масштабирования
В HDInsight добавлена проверка групп безопасности сети (NSG) и определяемых пользователем маршрутов (UDR) при операции масштабирования. Такая же проверка выполняется для масштабирования кластера, помимо создания кластера. Эта проверка помогает предотвратить непредсказуемые ошибки. Если проверка не пройдена, масштабирование завершается сбоем. Дополнительные сведения о том, как правильно настроить группы безопасности сети и определяемую пользователем маршрутизацию, см. в разделе IP-адреса управления HDInsight.
Изменение версий компонентов
В этом выпуска не вносилось изменений в версии компонентов. Текущие версии компонентов для HDInsight 4.0 и HDInsight 3.6 см. в этом документе.
Дата выпуска: 09.11.2020
Этот выпуск применим к версиям HDInsight 3.6 и HDInsight 4.0. Выпуск HDInsight предоставляется для разных регионов на протяжении нескольких дней. Указанная здесь дата выпуска обозначает дату выпуска для первого из регионов. Если вы не видите следующие изменения, подождите, пока обновление станет доступным в вашем регионе через несколько дней.
Новые возможности
Брокер удостоверений HDInsight (HIB) теперь общедоступен
Брокер удостоверений HDInsight (HIB), обеспечивающий аутентификацию OAuth для кластеров ESP, теперь общедоступен в этом выпуске. Кластеры HIB, созданные после этого выпуска, будут содержать новейшие функции HIB:
- Высокий уровень доступности (HA)
- Поддержка многофакторной проверки подлинности (MFA)
- Федеративные пользователи входят в систему без синхронизации хэшей паролей с AAD-DS. Дополнительные сведения см. в документации по HIB.
Переход на масштабируемые наборы виртуальных машин Azure
Сейчас HDInsight использует для подготовки кластера виртуальные машины Azure. Начиная с этого выпуска, служба будет постепенно переноситься в масштабируемые наборы виртуальных машин Azure. Весь процесс может занять несколько месяцев. После переноса регионов и подписок все созданные кластеры HDInsight будут выполняться в масштабируемых наборах виртуальных машин, и для этого не требуются действия со стороны клиента. Критических изменений не ожидается.
Депрекация
Устаревание кластера служб машинного обучения (ML) в HDInsight 3.6
Поддержка типа кластера Служб машинного обучения HDInsight 3.6 будет прекращена 31 декабря 2020 г. Клиенты не смогут создавать новые кластеры Служб машинного обучения версии 3.6 после 31 декабря 2020 г. Существующие кластеры будут продолжать работу без изменений, но без поддержки со стороны корпорации Майкрософт. Проверьте срок действия поддержки для версий HDInsight и типов кластеров здесь.
Размеры отключенных виртуальных машин
Начиная с 16 ноября 2020 г., HDInsight будет блокировать новых клиентов от создания кластеров, используя размеры виртуальных машин standard_A8, standard_A9, standard_A10 и standard_A11. Существующие клиенты, которые использовали эти размеры виртуальных машин в течение последних трех месяцев, не будут затронуты. Начиная с 9 января 2021 г., HDInsight блокирует всех клиентов, создающих кластеры с использованием размеров виртуальных машин стандартов A8, A9, A10 и A11. Существующие кластеры будут работать как обычно. Постарайтесь перейти на версию HDInsight 4.0, чтобы избежать потенциальных перерывов в работе или обслуживании.
Изменения в поведении
В этом выпуске не вносятся изменения в поведении.
Предстоящие изменения
В предстоящих выпусках будут внесены описанные ниже изменения.
Возможность выбора различных размеров виртуальных машин Zookeeper для Spark, Hadoop и Служб машинного обучения
На сегодня HDInsight не поддерживает настройку размера узла Zookeeper для типов кластера Spark, Hadoop и Служб машинного обучения. По умолчанию используются размеры виртуальных машин A2_v2/A2, которые предоставляются бесплатно. В предстоящем выпуске можно будет выбрать размер виртуальной машины Zookeeper, наиболее подходящий для вашего сценария. За узлы Zookeeper с размером виртуальной машины, отличным от A2_v2/A2, будет взиматься плата. Виртуальные машины A2_v2 и a2 по-прежнему предоставляются бесплатно.
Версия кластера по умолчанию будет изменена на 4.0
Начиная с февраля 2021 г., версия кластера HDInsight по умолчанию будет изменена с 3.6 на 4.0. Дополнительные сведения о доступных версиях см. в списке поддерживаемых версий. Изучите подробнее новые возможности HDInsight 4.0
Окончание поддержки HDInsight 3.6 30 июня 2021 г.
Поддержка HDInsight 3.6 будет прекращена. Начиная с 30 июня 2021 г., клиенты не смогут создавать новые кластеры HDInsight 3.6. Существующие кластеры будут продолжать работу без изменений, но без поддержки со стороны корпорации Майкрософт. Постарайтесь перейти на версию HDInsight 4.0, чтобы избежать потенциальных перерывов в работе или обслуживании.
Исправления ошибок
HDInsight постоянно повышает надежность и производительность кластеров.
Устранение проблемы при перезапуске виртуальных машин в кластере
Исправлена проблема с перезапуском виртуальных машин в кластере. Теперь снова можно использовать PowerShell или REST API для перезагрузки узлов в кластере.
Изменение версий компонентов
В этом выпуска не вносилось изменений в версии компонентов. Текущие версии компонентов для HDInsight 4.0 и HDInsight 3.6 см. в этом документе.
Дата выпуска: 08.10.2020
Этот выпуск применим к версиям HDInsight 3.6 и HDInsight 4.0. Выпуск HDInsight предоставляется для разных регионов на протяжении нескольких дней. Указанная здесь дата выпуска обозначает дату выпуска для первого из регионов. Если вы не видите следующие изменения, подождите, пока обновление станет доступным в вашем регионе через несколько дней.
Новые возможности
Частные кластеры HDInsight без публичного IP-адреса и Приватного подключения (режим предварительного просмотра)
HDInsight теперь поддерживает создание кластеров без общедоступного IP-адреса и доступа к кластерам по приватному каналу в предварительной версии. Клиенты могут использовать новые дополнительные сетевые параметры, чтобы создать полностью изолированный кластер без общедоступного IP-адреса и использовать собственные частные конечные точки для доступа к кластеру.
Переход на масштабируемые наборы виртуальных машин Azure
Сейчас HDInsight использует для подготовки кластера виртуальные машины Azure. Начиная с этого выпуска, служба будет постепенно переноситься в масштабируемые наборы виртуальных машин Azure. Весь процесс может занять несколько месяцев. После переноса регионов и подписок все созданные кластеры HDInsight будут выполняться в масштабируемых наборах виртуальных машин, и для этого не требуются действия со стороны клиента. Критических изменений не ожидается.
Депрекация
Устаревание кластера служб машинного обучения (ML) в HDInsight 3.6
Поддержка типа кластера Служб машинного обучения HDInsight 3.6 будет прекращена 31 декабря 2020 г. После этого клиенты не смогут создавать новые кластеры Служб машинного обучения версии 3.6. Существующие кластеры будут продолжать работу без изменений, но без поддержки со стороны корпорации Майкрософт. Проверьте срок действия поддержки для версий HDInsight и типов кластеров здесь.
Изменения в поведении
В этом выпуске не вносятся изменения в поведении.
Предстоящие изменения
В предстоящих выпусках будут внесены описанные ниже изменения.
Возможность выбора различных размеров виртуальных машин Zookeeper для Spark, Hadoop и Служб машинного обучения
На сегодня HDInsight не поддерживает настройку размера узла Zookeeper для типов кластера Spark, Hadoop и Служб машинного обучения. По умолчанию используются размеры виртуальных машин A2_v2/A2, которые предоставляются бесплатно. В предстоящем выпуске можно будет выбрать размер виртуальной машины Zookeeper, наиболее подходящий для вашего сценария. За узлы Zookeeper с размером виртуальной машины, отличным от A2_v2/A2, будет взиматься плата. Виртуальные машины A2_v2 и a2 по-прежнему предоставляются бесплатно.
Исправления ошибок
HDInsight постоянно повышает надежность и производительность кластеров.
Изменение версий компонентов
В этом выпуска не вносилось изменений в версии компонентов. Текущие версии компонентов для HDInsight 4.0 и HDInsight 3.6 см. в этом документе.
Дата выпуска: 28.09.2020
Этот выпуск применим к версиям HDInsight 3.6 и HDInsight 4.0. Выпуск HDInsight предоставляется для разных регионов на протяжении нескольких дней. Указанная здесь дата выпуска обозначает дату выпуска для первого из регионов. Если вы не видите следующие изменения, подождите, пока обновление станет доступным в вашем регионе через несколько дней.
Новые возможности
Автомасштабирование для Interactive Query с помощью HDInsight 4.0 теперь общедоступно
Автоматическое масштабирование для типа кластера Interactive Query теперь общедоступно (GA) для HDInsight 4.0. Все кластеры Interactive Query 4.0, созданные после 27 августа 2020 года, будут поддерживать функцию общего доступа для автоматического масштабирования.
Кластер HBase поддерживает ADLS 2-го поколения Premium
HDInsight теперь поддерживает Premium ADLS 2-го поколения в качестве основной учетной записи для хранения для кластеров HDInsight HBase 3.6 и 4.0. Вместе с ускоренными операциями записи можно повысить производительность кластеров HBase.
Распределение секций Kafka в доменах сбоя Azure
Домен сбоя — это логическое объединение базового оборудования в центре обработки данных Azure. Все домены сбоя используют общий источник питания и сетевой коммутатор. Ранее HDInsight Kafka мог хранить все реплики разделов в одном домене сбоя. Начиная с этого выпуска, HDInsight теперь поддерживает автоматическое распределение разделов Kafka на основе областей отказа Azure.
Шифрование при передаче
Клиенты могут включить шифрование между узлами кластера с помощью шифрования IPsec с ключами, управляемыми платформой. Этот параметр можно включить во время создания кластера. См. дополнительные сведения о том, как включить шифрование при передаче.
Шифрование на узле
При включении шифрования на узле данные, хранящиеся на узле виртуальной машины, шифруются при хранении и передаются в зашифрованном виде в службу хранилища. Начиная с этого выпуска, можно включить шифрование на узле на диске с временными данными при создании кластера. Шифрование на узле поддерживается только для определенных номеров SKU виртуальных машин в ограниченном числе регионов. HDInsight поддерживает следующие конфигурации узлов и SKU. См. дополнительные сведения о том, как включить шифрование на узле.
Переход на масштабируемые наборы виртуальных машин Azure
Сейчас HDInsight использует для подготовки кластера виртуальные машины Azure. Начиная с этого выпуска, служба будет постепенно переноситься в масштабируемые наборы виртуальных машин Azure. Весь процесс может занять несколько месяцев. После переноса регионов и подписок все созданные кластеры HDInsight будут выполняться в масштабируемых наборах виртуальных машин, и для этого не требуются действия со стороны клиента. Критических изменений не ожидается.
Депрекация
В этом выпуске нет устаревших компонентов.
Изменения в поведении
В этом выпуске не вносятся изменения в поведении.
Предстоящие изменения
В предстоящих выпусках будут внесены описанные ниже изменения.
Возможность выбора различных номеров SKU Zookeeper для Spark, Hadoop и Служб машинного обучения
На сегодня HDInsight не поддерживает изменение SKU Zookeeper для типов кластера Spark, Hadoop и Служб машинного обучения. Для узлов Zookeeper используется SKU A2_v2/A2, и клиенты за это не платят. В следующем выпуске клиенты могут изменить SKU Zookeeper для служб Spark, Hadoop и ML по мере необходимости. За узлы Zookeeper с SKU, отличающимися от A2_v2/A2, будет взиматься плата. Номером SKU по умолчанию по-прежнему будет A2_V2/A2, без оплаты.
Исправления ошибок
HDInsight постоянно повышает надежность и производительность кластеров.
Изменение версий компонентов
В этом выпуска не вносилось изменений в версии компонентов. Текущие версии компонентов для HDInsight 4.0 и HDInsight 3.6 см. в этом документе.
Дата выпуска: 09.08.2020
Этот выпуск применим только к HDInsight версии 4.0. Выпуск HDInsight предоставляется для разных регионов на протяжении нескольких дней. Указанная здесь дата выпуска обозначает дату выпуска для первого из регионов. Если вы не видите следующие изменения, подождите, пока обновление станет доступным в вашем регионе через несколько дней.
Новые возможности
Поддержка SparkCruise
SparkCruise — система автоматического повторного использования вычислений для Spark. Он выбирает общие подвыражения для материализации на основе рабочей нагрузки предыдущих запросов. SparkCruise обрабатывает эти части выражения в процессе обработки запросов, и повторное использование вычислений применяется автоматически в фоновом режиме. Вы можете воспользоваться преимуществами SparkCruise, не внося никаких изменений в код Spark.
Поддержка представления Hive для HDInsight 4.0
Модуль Apache Ambari Hive View разработан для помощи в создании, оптимизации и выполнении запросов Hive из вашего веб-браузера. Поддержка Hive нативно доступна для кластеров HDInsight 4.0, начиная с этого выпуска. Оно не применяется к существующим кластерам. Чтобы получить встроенное представление Hive, нужно удалить кластер и создать его заново.
Поддержка представления Tez для HDInsight 4.0
Представление Apache Tez используется для отслеживания и отладки выполнения задания Hive Tez. Нативная поддержка Tez View для HDInsight 4.0 начинается с этого выпуска. Оно не применяется к существующим кластерам. Чтобы получить встроенное представление Tez, необходимо удалить и повторно создать кластер.
Депрекация
Отказ от поддержки Spark 2.1 и 2.2 в кластере Spark для HDInsight 3.6
Начиная с 1 июля 2020 г. клиенты не могут создавать новые кластеры Spark с Spark 2.1 и 2.2 в HDInsight 3.6. Существующие кластеры будут продолжать работу без изменений, но без поддержки со стороны корпорации Майкрософт. Постарайтесь перейти к версии Spark 2.3 в HDInsight 3.6 не позднее 30 июня 2020 г., чтобы избежать потенциальных проблем или перерывов в работе.
Отказ от поддержки Spark 2.3 в HDInsight 4.0 для кластера Spark
Начиная с 1 июля 2020 г. клиенты не могут создавать новые кластеры Spark с Spark 2.3 в HDInsight 4.0. Существующие кластеры будут продолжать работу без изменений, но без поддержки со стороны корпорации Майкрософт. Постарайтесь перейти на версию Spark 2.4 в HDInsight 4.0 не позднее 30 июня 2020 г., чтобы избежать возможных проблем или перерывов в работе.
Снятие с поддержки Kafka 1.1 в кластере Kafka на HDInsight 4.0
Начиная с 1 июля 2020 г. клиенты не смогут создавать новые кластеры Kafka с Kafka 1.1 в HDInsight 4.0. Существующие кластеры будут продолжать работу без изменений, но без поддержки со стороны корпорации Майкрософт. Постарайтесь перейти на версию Kafka 2.1 в HDInsight 4.0 не позднее 30 июня 2020 г., чтобы избежать возможных проблем или перерывов в работе.
Изменения в поведении
Изменение версии стека Ambari
В этом выпуске версия Ambari изменяется с 2.x.x.x на 4.1. Версию стека (HDInsight 4.1) можно проверить в Ambari: Ambari > Пользователь > Версии.
Предстоящие изменения
Нет предстоящих критических изменений, на которые нужно обратить внимание.
Исправления ошибок
HDInsight постоянно повышает надежность и производительность кластеров.
Приведенные ниже JIRA обратно портированы для Hive:
Приведенные ниже JIRA обратно портированы для HBase:
Изменение версий компонентов
В этом выпуска не вносилось изменений в версии компонентов. Текущие версии компонентов для HDInsight 4.0 и HDInsight 3.6 см. в этом документе.
Известные проблемы
Исправлена проблема на портале Azure, где у пользователей возникала ошибка при создании кластера Azure HDInsight с помощью типа проверки подлинности SSH с открытым ключом. Когда пользователи нажимали кнопку "Проверка и создание", они получат сообщение об ошибке "Не должно содержать трех последовательных символов из имени пользователя SSH". Эта проблема устранена, но может потребоваться обновить кэш браузера, нажав клавиши CTRL+F5, чтобы загрузить исправленное представление. Обходное решение для этой проблемы заключалось в создании кластера с ARM-шаблоном.
Дата выпуска: 13.07.2020
Этот выпуск применим к HDInsight версий 3.6 и 4.0. Выпуск HDInsight предоставляется для разных регионов на протяжении нескольких дней. Указанная здесь дата выпуска обозначает дату выпуска для первого из регионов. Если вы не видите следующие изменения, подождите, пока обновление станет доступным в вашем регионе через несколько дней.
Новые возможности
Поддержка Customer Lockbox для клиентов Microsoft Azure
Azure HDInsight теперь поддерживает Azure Customer Lockbox. Клиенты получают интерфейс для просмотра и утверждения или отклонения запросов на доступ к данным клиента. Он используется, когда инженер Майкрософт должен получить доступ к данным клиента во время запроса на поддержку. Для получения дополнительной информации см. Customer Lockbox для Microsoft Azure.
Политики конечной точки сервиса для хранилища
Теперь клиенты могут использовать политики конечной точки службы (SEP) в подсети кластера HDInsight. Дополнительные сведения о политике конечной точки службы Azure.
Депрекация
Отказ от поддержки Spark 2.1 и 2.2 в кластере Spark для HDInsight 3.6
Начиная с 1 июля 2020 г. клиенты не могут создавать новые кластеры Spark с Spark 2.1 и 2.2 в HDInsight 3.6. Существующие кластеры будут продолжать работу без изменений, но без поддержки со стороны корпорации Майкрософт. Постарайтесь перейти к версии Spark 2.3 в HDInsight 3.6 не позднее 30 июня 2020 г., чтобы избежать потенциальных проблем или перерывов в работе.
Отказ от поддержки Spark 2.3 в HDInsight 4.0 для кластера Spark
Начиная с 1 июля 2020 г. клиенты не могут создавать новые кластеры Spark с Spark 2.3 в HDInsight 4.0. Существующие кластеры будут продолжать работу без изменений, но без поддержки со стороны корпорации Майкрософт. Постарайтесь перейти на версию Spark 2.4 в HDInsight 4.0 не позднее 30 июня 2020 г., чтобы избежать возможных проблем или перерывов в работе.
Снятие с поддержки Kafka 1.1 в кластере Kafka на HDInsight 4.0
Начиная с 1 июля 2020 г. клиенты не смогут создавать новые кластеры Kafka с Kafka 1.1 в HDInsight 4.0. Существующие кластеры будут продолжать работу без изменений, но без поддержки со стороны корпорации Майкрософт. Постарайтесь перейти на версию Kafka 2.1 в HDInsight 4.0 не позднее 30 июня 2020 г., чтобы избежать возможных проблем или перерывов в работе.
Изменения в поведении
Нет изменений в поведении, на которые нужно обратить внимание.
Предстоящие изменения
В предстоящих выпусках будут внесены описанные ниже изменения.
Возможность выбора различных номеров SKU Zookeeper для Spark, Hadoop и Служб машинного обучения
На сегодня HDInsight не поддерживает изменение SKU Zookeeper для типов кластера Spark, Hadoop и Служб машинного обучения. Для узлов Zookeeper используется SKU A2_v2/A2, и клиенты за это не платят. В следующем выпуске клиенты смогут при необходимости изменить SKU Zookeeper для услуг Spark, Hadoop и ML. За узлы Zookeeper с SKU, отличающимися от A2_v2/A2, будет взиматься плата. Номером SKU по умолчанию по-прежнему будет A2_V2/A2, без оплаты.
Исправления ошибок
HDInsight постоянно повышает надежность и производительность кластеров.
Исправлена проблема с Hive Warehouse Connector
В предыдущем выпуске возникла проблема с удобством использования Hive Warehouse Connector. Теперь эта проблема устранена.
Исправлена проблема с обрезанием начальных нулей в записной книжке Zeppelin
В Zeppelin неправильно усекались начальные нули в выводе таблицы для строкового формата. Мы устранили эту ошибку в данном выпуске.
Изменение версий компонентов
В этом выпуска не вносилось изменений в версии компонентов. Текущие версии компонентов для HDInsight 4.0 и HDInsight 3.6 см. в этом документе.
Дата выпуска: 11.06.2020
Этот выпуск применим к HDInsight версий 3.6 и 4.0. Выпуск HDInsight предоставляется для разных регионов на протяжении нескольких дней. Указанная здесь дата выпуска обозначает дату выпуска для первого из регионов. Если вы не видите следующие изменения, подождите, пока обновление станет доступным в вашем регионе через несколько дней.
Новые возможности
Переход на масштабируемые наборы виртуальных машин Azure
Сейчас HDInsight использует для подготовки кластера виртуальные машины Azure. Начиная с этого выпуска, в новых кластерах HDInsight будет использоваться масштабируемый набор виртуальных машин Azure. Изменение внедряется постепенно. Резкого изменения не предполагается. Изучите информацию о масштабируемых наборах виртуальных машин Azure.
Перезагрузка виртуальных машин в кластере HDInsight
В этом выпуске мы поддерживаем перезагрузку виртуальных машин в кластере HDInsight для перезагрузки нереагирующих узлов. В настоящее время это можно сделать только через API, поддержка PowerShell и CLI ожидается. Дополнительные сведения об интерфейсе API см. в этом документе.
Депрекация
Отказ от поддержки Spark 2.1 и 2.2 в кластере Spark для HDInsight 3.6
Начиная с 1 июля 2020 г. клиенты не могут создавать новые кластеры Spark с Spark 2.1 и 2.2 в HDInsight 3.6. Существующие кластеры будут продолжать работу без изменений, но без поддержки со стороны корпорации Майкрософт. Постарайтесь перейти к версии Spark 2.3 в HDInsight 3.6 не позднее 30 июня 2020 г., чтобы избежать потенциальных проблем или перерывов в работе.
Отказ от поддержки Spark 2.3 в HDInsight 4.0 для кластера Spark
Начиная с 1 июля 2020 г. клиенты не могут создавать новые кластеры Spark с Spark 2.3 в HDInsight 4.0. Существующие кластеры будут продолжать работу без изменений, но без поддержки со стороны корпорации Майкрософт. Постарайтесь перейти на версию Spark 2.4 в HDInsight 4.0 не позднее 30 июня 2020 г., чтобы избежать возможных проблем или перерывов в работе.
Снятие с поддержки Kafka 1.1 в кластере Kafka на HDInsight 4.0
Начиная с 1 июля 2020 г. клиенты не смогут создавать новые кластеры Kafka с Kafka 1.1 в HDInsight 4.0. Существующие кластеры будут продолжать работу без изменений, но без поддержки со стороны корпорации Майкрософт. Постарайтесь перейти на версию Kafka 2.1 в HDInsight 4.0 не позднее 30 июня 2020 г., чтобы избежать возможных проблем или перерывов в работе.
Изменения в поведении
Изменение размера головного узла для кластера ESP Spark
Минимальный разрешенный размер головного узла для кластера ESP Spark изменен на Standard_D13_V2. Виртуальные машины с небольшим количеством ядер и объемом памяти в качестве головного узла могут вызвать проблемы с кластером ESP из-за относительной нехватки ресурсов ЦП и памяти. Начиная с этого релиза, используйте SKU выше чем Standard_D13_V2 и Standard_E16_V3 в качестве головных узлов для кластеров ESP Spark.
Для головного узла требуется виртуальная машина с не менее чем 4-мя ядрами
Для головного узла требуется виртуальная машина с не менее чем 4-мя ядрами, чтобы обеспечивать высокий уровень доступности и надежности для кластеров HDInsight. Начиная с 6 апреля 2020 г. клиенты смогут выбрать в качестве головного узла для новых кластеров HDInsight только виртуальные машины с 4-мя и более ядрами. Существующие кластеры продолжат работать ожидаемым образом.
Изменение подготовки рабочих узлов кластера
Когда 80% рабочих узлов готовы, кластер переходит на операционный этап. На этом этапе клиенты могут выполнять все операции в плоскости данных, такие как выполнение скриптов и заданий. Но клиенты не могут выполнять операции управления, такие как увеличение или уменьшение масштаба. Поддерживается только удаление.
После операционного этапа кластер ожидает еще 60 минут для оставшихся 20% рабочих узлов. В конце этого 60-минутного периода кластер переходит на этап запуска, даже если все рабочие узлы по-прежнему недоступны. После того как кластер перейдет на этап выполнения, его можно использовать как обычно. Принимаются как операции уровня управления, такие как увеличение или уменьшение масштаба, так и операции в плоскости данных, такие как выполнение скриптов и заданий. Если некоторые из запрошенных рабочих узлов недоступны, кластер будет помечен как частичный успех. Вы платите за узлы, которые были успешно развернуты.
Создайте новую учетную запись службы через HDInsight
Ранее при создании кластера клиенты могли создать новый субъект-службу для доступа к подключенной учетной записи ADLS 1-го поколения на портале Azure. Начиная с 15 июня 2020 г. создание нового субъекта-службы невозможно в рабочем процессе создания HDInsight, поддерживается только существующий субъект-служба. Смотрите Создание сервис-принципала и сертификатов с помощью Azure Active Directory.
Время ожидания для действий скриптов при создании кластера
HDInsight поддерживает выполнение скриптов при создании кластера. В этом выпуске все действия скрипта с созданием кластера должны завершиться в течение 60 минут или истекает время ожидания. Действия скрипта, отправленные в запущенные кластеры, не влияют. Дополнительные сведения см. здесь.
Предстоящие изменения
Нет предстоящих критических изменений, на которые нужно обратить внимание.
Исправления ошибок
HDInsight постоянно повышает надежность и производительность кластеров.
Изменение версий компонентов
HBase версии 2.0 - 2.1.6
Версия HBase обновлена с 2.0 до 2.1.6.
Обновление Spark 2.4.0 до 2.4.4
Версия Spark обновлена с 2.4.0 до 2.4.4.
Обновление Kafka 2.1.0 до 2.1.1
Версия Kafka обновлена с 2.1.0 до 2.1.1.
Текущие версии компонентов для HDInsight 4.0 и HDInsight 3.6 см. в этом документе.
Известные проблемы
Проблема с Hive Warehouse Connector
В этом выпуске возникла проблема с коннектором хранилища Hive. Исправление войдет в следующий выпуск. Существующие кластеры, созданные до этого выпуска, не затрагиваются. По возможности избегайте удаления и повторного создания кластера. Если вам нужна дополнительная помощь, откройте запрос в службу поддержки.
Дата выпуска: 01.09.2020
Этот выпуск применим к HDInsight версий 3.6 и 4.0. Выпуск HDInsight предоставляется для разных регионов на протяжении нескольких дней. Указанная здесь дата выпуска обозначает дату выпуска для первого из регионов. Если вы не видите следующие изменения, подождите, пока обновление станет доступным в вашем регионе через несколько дней.
Новые возможности
Обязательное использование TLS 1.2
TLS и SSL являются протоколами шифрования, которые обеспечивает безопасность передачи данных по сети. Дополнительные сведения о TLS. В HDInsight используется TLS 1.2 на общедоступных конечных точках HTTPS, но TLS 1.1 пока поддерживается для обеспечения обратной совместимости.
Начиная с этого выпуска клиенты могут потребовать использовать только TLS 1.2 для всех подключений через конечную точку общедоступного кластера. Для этого введено новое свойство minSupportedTlsVersion, которое можно указать во время создания кластера. Если значение для этого свойства не задано, кластер сохраняет поддержку TLS 1.0, 1.1 и 1.2, что соответствует текущему поведению. Клиенты могут задать для этого свойства значение "1.2", и тогда кластер будет поддерживать только TLS 1.2 и более поздних версий. Дополнительные сведения см. в статье Transport Layer Security (TLS).
Использование собственных ключей для шифрования дисков
Все управляемые диски в HDInsight защищены с помощью шифрования службы хранилища Azure (SSE). Данные на этих дисках по умолчанию шифруются с помощью ключей, управляемых корпорацией Майкрософт. Начиная с этого выпуска вы можете создавать собственные ключи (технология BYOK) для шифрования дисков и управлять ими в Azure Key Vault. Шифрование с поддержкой BYOK настраивается для кластера одним действием во время его создания и не предполагает других затрат. Просто зарегистрируйте HDInsight в качестве управляемого удостоверения в Azure Key Vault и добавьте ключ шифрования при создании кластера. Подробнее см. статью о шифровании диска с управляемыми клиентом ключами.
Депрекация
Устаревших компонентов в этом выпуске нет. Чтобы подготовиться к предстоящим прекращениям поддержки, изучите Предстоящие изменения.
Изменения в поведении
В этом выпуске не вносятся изменения в поведении. Чтобы подготовиться к планам по изменениям, изучите список Предстоящие изменения.
Предстоящие изменения
В предстоящих выпусках будут внесены описанные ниже изменения.
Отказ от поддержки Spark 2.1 и 2.2 в кластере Spark для HDInsight 3.6
Начиная с 1 июля 2020 г. клиенты не смогут создавать новые кластеры Spark с Spark 2.1 и 2.2 в HDInsight 3.6. Существующие кластеры будут продолжать работу без изменений, но без поддержки со стороны корпорации Майкрософт. Постарайтесь перейти на версию Spark 2.3 в HDInsight 3.6 не позднее 30 июня 2020 г., чтобы избежать возможных проблем или перерывов в работе.
Отказ от поддержки Spark 2.3 в HDInsight 4.0 для кластера Spark
Начиная с 1 июля 2020 г. клиенты не смогут создавать новые кластеры Spark с Spark 2.3 в HDInsight 4.0. Существующие кластеры будут продолжать работу без изменений, но без поддержки со стороны корпорации Майкрософт. Постарайтесь перейти на версию Spark 2.4 в HDInsight 4.0 не позднее 30 июня 2020 г., чтобы избежать возможных проблем или перерывов в работе.
Снятие с поддержки Kafka 1.1 в кластере Kafka на HDInsight 4.0
Начиная с 1 июля 2020 г. клиенты не смогут создавать новые кластеры Kafka с Kafka 1.1 в HDInsight 4.0. Существующие кластеры будут продолжать работу без изменений, но без поддержки со стороны корпорации Майкрософт. Постарайтесь перейти на версию Kafka 2.1 в HDInsight 4.0 не позднее 30 июня 2020 г., чтобы избежать возможных проблем или перерывов в работе. Дополнительные сведения см. в статье Перенос рабочих нагрузок Apache Kafka в Azure HDInsight 4.0.
HBase версии 2.0 - 2.1.6
В предстоящем выпуске HDInsight 4.0 версия HBase будет обновлена с 2.0 до 2.1.6
Обновление Spark 2.4.0 до 2.4.4
В предстоящем выпуске HDInsight 4.0 версия Spark будет обновлена с 2.4.0 до 2.4.4
Обновление Kafka 2.1.0 до 2.1.1
В предстоящем выпуске HDInsight 4.0 версия Kafka будет обновлена с 2.1.0 до 2.1.1
Для головного узла требуется виртуальная машина с не менее чем 4-мя ядрами
Для головного узла требуется виртуальная машина с не менее чем 4-мя ядрами, чтобы обеспечивать высокий уровень доступности и надежности для кластеров HDInsight. Начиная с 6 апреля 2020 г. клиенты смогут выбрать в качестве головного узла для новых кластеров HDInsight только виртуальные машины с 4-мя и более ядрами. Существующие кластеры продолжат работать ожидаемым образом.
Изменение размера узла для кластера ESP Spark
В предстоящем выпуске минимальный разрешенный размер узла для кластера ESP Spark изменится на Standard_D13_V2. Виртуальные машины серии A могут приводить к проблемам с кластером ESP из-за сравнительно малого объема ресурсов ЦП и памяти. Виртуальные машины серии A не рекомендуются для создания новых кластеров ESP.
Переход на масштабируемые наборы виртуальных машин Azure
Сейчас HDInsight использует для подготовки кластера виртуальные машины Azure. В предстоящем выпуске HDInsight переключится на использование масштабируемых наборов виртуальных машин Azure. Изучите информацию о масштабируемых наборах виртуальных машин Azure.
Исправления ошибок
HDInsight постоянно повышает надежность и производительность кластеров.
Изменение версий компонентов
В этом выпуска не вносилось изменений в версии компонентов. Текущие версии компонентов для HDInsight 4.0 и HDInsight 3.6 вы можете найти здесь.
Дата выпуска: 17.12.2019
Этот выпуск применим к HDInsight версий 3.6 и 4.0.
Новые возможности
Теги служб
Теги служб упрощают безопасность виртуальных машин Azure и виртуальных сетей Azure, позволяя легко ограничить сетевой доступ к службам Azure. Теги служб можно использовать в правилах группы безопасности сети (NSG), чтобы разрешать или запрещать трафик к определенной службе Azure глобально или по определенным регионам Azure. За обслуживание IP-адресов для этих тегов отвечает Azure. Теги службы HDInsight для групп безопасности сети (NSG) — это группы IP-адресов для служб мониторинга состояния и управления. Эти группы упрощают создание правил безопасности. Клиенты HDInsight могут включить тег службы с помощью портала Azure, PowerShell и REST API. Дополнительные сведения см. в статье Теги службы Azure HDInsight для групп безопасности сети.
Пользовательская база данных Ambari
HDInsight теперь позволяет использовать собственную базу данных SQL для Apache Ambari. Эту пользовательскую базу данных Ambari можно настроить на портале Azure или с помощью шаблона Resource Manager. Эта функция позволяет выбрать подходящую базу данных SQL для ваших потребностей в обработке и емкости. Также можно легко выполнить обновление в соответствии с требованиями растущего бизнеса. Дополнительные сведения см. в статье Настройка кластеров HDInsight с помощью пользовательской базы данных Ambari DB.

Депрекация
Устаревших компонентов в этом выпуске нет. Чтобы подготовиться к предстоящим прекращениям поддержки, изучите Предстоящие изменения.
Изменения в поведении
В этом выпуске не вносятся изменения в поведении. Чтобы подготовиться к предстоящим изменениям в поведении, изучите список Предстоящие изменения.
Предстоящие изменения
В предстоящих выпусках будут внесены описанные ниже изменения.
Принудительное применение протокола TLS версии 1.2
TLS и SSL являются протоколами шифрования, которые обеспечивает безопасность передачи данных по сети. Дополнительные сведения см. в статье Transport Layer Security (TLS). Хотя кластеры Azure HDInsight принимают подключения TLS 1.2 в общедоступных конечных точках HTTPS, TLS 1.1 по-прежнему поддерживается для обратной совместимости со старыми клиентами.
Начиная со следующего выпуска, вы сможете выбрать и настроить новые кластеры HDInsight на прием только подключений TLS 1.2.
Позднее в этом году, начиная с 30.06.2020, Azure HDInsight будет принудительно применять TLS 1.2 или более поздних версий для всех подключений HTTPS. Рекомендуем убедиться, что все клиенты готовы к работе с TLS 1.2 или более поздней версии.
Переход на масштабируемые наборы виртуальных машин Azure
Сейчас HDInsight использует для подготовки кластера виртуальные машины Azure. Начиная с февраля 2020 (точная дата будет сообщена позже), HDInsight будет использовать вместо этого масштабируемые наборы виртуальных машин Azure. Изучите информацию о масштабируемых наборах виртуальных машин Azure.
Изменение размера узла для кластера ESP Spark
В следующем выпуске:
- Минимальный разрешенный размер узла для кластера ESP Spark будет изменен на Standard_D13_V2.
- Виртуальные машины серии A будут объявлены нерекомендуемыми для создания новых кластеров ESP, так как виртуальные машины серии A могут вызвать проблемы с кластером ESP из-за относительной нехватки ресурсов ЦП и памяти.
Обновление HBase 2.0 до 2.1
В предстоящем выпуске HDInsight 4.0 версия HBase будет обновлена с 2.0 до 2.1.
Исправления ошибок
HDInsight постоянно повышает надежность и производительность кластеров.
Изменение версий компонентов
Поддержка HDInsight 3.6 была продлена до 31 декабря 2020 г. Дополнительные сведения см. в статье Поддерживаемые версии HDInsight.
Для HDInsight 4.0 нет изменений в версии компонентов.
Apache Zeppelin в HDInsight 3.6: 0.7.0-->0.7.3.
Последние версии компонентов можно найти в этом документе.
Новые регионы
Северная часть ОАЭ;
IP-адреса управления для северной части ОАЭ: 65.52.252.96 и 65.52.252.97.
Дата выпуска: 07.11.2019
Этот выпуск применим к HDInsight версий 3.6 и 4.0.
Новые возможности
Брокер идентичности HDInsight (HIB) (предварительный просмотр)
HDInsight Identity Broker (HIB) позволяет пользователям выполнять вход в Apache Ambari с помощью многофакторной аутентификации (MFA) и получать необходимые билеты Kerberos без хэшей паролей в службах доменных служб Azure Active Directory (AAD-DS). Сейчас HIB доступен только для кластеров, развернутых с помощью шаблона Azure Resource Manager (ARM).
Прокси-сервер API Rest для Kafka (предварительная версия)
Прокси-сервер API Rest для Kafka обеспечивает развертывание одним щелчком прокси-сервера REST высокой надежности с кластером Kafka посредством защищенной авторизации Azure AD и протокола OAuth.
Автомасштабирование
Автоматическое масштабирование Azure HDInsight теперь общедоступно во всех регионах для типов кластеров Apache Spark и Hadoop. Эта функция позволяет управлять рабочими нагрузками аналитики больших данных более экономичным и эффективным способом. Теперь можно оптимизировать использование кластеров HDInsight и платить только за то, что вам нужно.
В зависимости от ваших требований вы можете выбирать между автомасштабированием с учетом загрузки и автомасштабированием с учетом расписания. Автомасштабирование на основе нагрузки позволяет масштабировать размер кластера в соответствии с текущими потребностями в ресурсах, а автомасштабирование на основе расписания — изменять размер кластера на основе предопределенного расписания.
Поддержка автомасштабирования для рабочей нагрузки HBase и LLAP также находится в общедоступном предварительном просмотре. Дополнительные сведения см. в разделе Автоматическое масштабирование кластеров Azure HDInsight.
Ускорение операций записи Azure HDInsight для Apache HBase
Ускоренная запись с использованием управляемых дисков Azure Premium SSD улучшает производительность журнала предзаписи (Write Ahead Log, WAL) Apache HBase. Дополнительные сведения см. в статье Azure HDInsight Accelerated Writes for Apache HBase (Ускоренные операции записи Azure HDInsight для Apache HBase).
Пользовательская база данных Ambari
Теперь HDInsight предлагает новую емкость, которая позволит клиентам использовать собственную базу данных SQL для Ambari. Клиенты теперь могут выбрать подходящую базу данных SQL для Ambari и легко обновлять ее в соответствии с требованиями к росту бизнеса. Развертывание осуществляется с помощью шаблона Azure Resource Manager. Дополнительные сведения см. в статье Настройка кластеров HDInsight с помощью пользовательской базы данных Ambari DB.
Виртуальные машины серии F теперь доступны в HDInsight
Виртуальные машины серии F — хороший выбор для начала работы с HDInsight при незначительных требованиях к обработке. При более низкой пер-часовой стоимости, серия F обеспечивает наилучшее соотношение цены и производительности в портфеле Azure на основе единицы вычисления Azure (ACU) на виртуальный ЦП. Дополнительные сведения см. в статье Выбор правильного размера виртуальной машины для кластера Azure HDInsight.
Депрекация
Устаревание виртуальных машин серии G
Начиная с этого выпуска, виртуальные машины серии G больше не предлагаются в HDInsight.
Dv1 устаревающая виртуальная машина
В этом выпуске использование виртуальных Dv1 машин с HDInsight не рекомендуется. Любой клиентский запрос на Dv1 будет автоматически выполнен с помощью Dv2. Нет разницы в цене между виртуальными машинами Dv1 и Dv2.
Изменения в поведении
Изменение размера управляемого диска кластера
HDInsight предоставляет с кластером управляемое дисковое пространство. Начиная с этого выпуска, размер управляемого диска каждого узла в новом созданном кластере изменен на 128 ГБ.
Предстоящие изменения
В предстоящих выпусках будут внесены описанные ниже изменения.
Переход на масштабируемые наборы виртуальных машин Azure
Сейчас HDInsight использует для подготовки кластера виртуальные машины Azure. Начиная с декабря, HDInsight переключится на использование масштабируемых наборов виртуальных машин Azure. Изучите информацию о масштабируемых наборах виртуальных машин Azure.
Обновление HBase 2.0 до 2.1
В предстоящем выпуске HDInsight 4.0 версия HBase будет обновлена с 2.0 до 2.1.
Устаревание виртуальных машин серии A для кластера ESP
Виртуальные машины серии A могут приводить к проблемам с кластером ESP из-за сравнительно малого объема ресурсов ЦП и памяти. В предстоящем выпуске виртуальные машины серии A не будут рекомендоваться для создания новых кластеров ESP.
Исправления ошибок
HDInsight постоянно повышает надежность и производительность кластеров.
Изменение версий компонентов
Для этого выпуска не изменяется версия компонента. Текущие версии компонентов для HDInsight 4.0 и HDInsight 3.6 можно найти здесь.
Дата выпуска: 07.08.2019
Версии компонентов
Официальные версии Apache всех компонентов HDInsight 4.0 перечислены ниже. Перечисленные компоненты являются выпусками самых последних доступных стабильных версий.
- Apache Ambari 2.7.1
- Apache Hadoop 3.1.1
- Apache HBase 2.0.0
- Apache Hive 3.1.0
- Apache Kafka 1.1.1, 2.1.0
- Apache Mahout 0.9.0+
- Apache Oozie 4.2.0
- Apache Phoenix 4.7.0
- Apache Pig 0.16.0
- Apache Ranger 0.7.0
- Apache Slider 0.92.0
- Apache Spark 2.3.1, 2.4.0
- Apache Sqoop 1.4.7
- Apache TEZ 0.9.1
- Apache Zeppelin 0.8.0
- Apache ZooKeeper 3.4.6
В дополнение к версиям, перечисленным выше, более поздние версии компонентов Apache иногда включаются в пакет в платформе HDP. В этом случае эти более поздние версии приводятся в таблице технических предварительных версий и не должны заменять версии компонента Apache указанного выше списка в рабочей среде.
Сведения об исправлениях Apache
Дополнительные сведения об исправлениях, доступных в HDInsight 4.0, см. в списке исправлений для каждого продукта в таблице ниже.
| Название продукта | Сведения об исправлениях |
|---|---|
| Ambari | Сведения об исправлениях Ambari |
| Hadoop | Сведения об исправлениях Hadoop |
| HBase | Сведения об исправлениях HBase |
| Куст | В этом выпуске предоставляется Hive 3.1.0 без дополнительных исправлений Apache. |
| Кафка | В этом выпуске предоставляется Kafka 1.1.1 без дополнительных исправлений Apache. |
| Oozie, | Сведения об исправлениях Oozie |
| Феникс | Сведения об исправлениях Phoenix |
| Свинья | Информация о патчах Pig |
| Рейнджер | Сведения об исправлениях Ranger |
| Спарк | Сведения об исправлениях Spark |
| Sqoop | В этом выпуске предоставляется Sqoop 1.4.7 без дополнительных исправлений Apache. |
| Тез | В этом выпуске предоставляется Tez 0.9.1 без дополнительных исправлений Apache. |
| Цеппелин | В этом выпуске предоставляется Zeppelin 0.8.0 без дополнительных исправлений Apache. |
| Zookeeper | Сведения об исправлениях Zookeeper |
Исправлены проблемы, связанные с распространенными уязвимостями и рисками
Дополнительные сведения о проблемах безопасности, устраненных в этом выпуске, см. в статье Hortonworks Fixed Common Vulnerabilities and Exposures for HDP 3.0.1 (Устраненные распространенные уязвимости и риски для HDP 3.0.1).
Известные проблемы
Репликация не работает для Secure HBase с установкой по умолчанию
Для HDInsight 4.0 выполните следующие действия.
Включите обмен данными между кластерами.
Войдите на активный головной узел.
Загрузите скрипт для включения репликации с помощью следующей команды:
sudo wget https://raw.githubusercontent.com/Azure/hbase-utils/master/replication/hdi_enable_replication.shВведите команду
sudo kinit <domainuser>.Введите следующую команду, чтобы запустить скрипт:
sudo bash hdi_enable_replication.sh -m <hn*> -s <srclusterdns> -d <dstclusterdns> -sp <srcclusterpasswd> -dp <dstclusterpasswd> -copydata
Для HDInsight 3.6
Войдите в активный HMaster ZK.
Загрузите скрипт для включения репликации с помощью следующей команды:
sudo wget https://raw.githubusercontent.com/Azure/hbase-utils/master/replication/hdi_enable_replication.shВведите команду
sudo kinit -k -t /etc/security/keytabs/hbase.service.keytab hbase/<FQDN>@<DOMAIN>.Введите следующую команду:
sudo bash hdi_enable_replication.sh -s <srclusterdns> -d <dstclusterdns> -sp <srcclusterpasswd> -dp <dstclusterpasswd> -copydata
Phoenix Sqlline перестает работать после переноса кластера HBase в HDInsight 4.0
Выполните следующие действия:
- Удалите следующие таблицы Phoenix:
SYSTEM.FUNCTIONSYSTEM.SEQUENCESYSTEM.STATSSYSTEM.MUTEXSYSTEM.CATALOG
- Если не удается удалить ни одну из таблиц, перезапустите HBase, чтобы очистить все соединения с таблицами.
- Еще раз запустите
sqlline.py. Phoenix повторно создаст все таблицы, которые были удалены на шаге 1. - Повторно создайте таблицы и представления Phoenix для данных HBase.
Phoenix Sqlline прекращает работу после репликации метаданных HBase Phoenix из HDInsight 3.6 в 4.0
Выполните следующие действия:
- Перед выполнением репликации перейдите в целевой кластер 4.0 и выполните
sqlline.py. Эта команда создаст таблицы Phoenix, такие какSYSTEM.MUTEXиSYSTEM.LOG, которые существуют только в 4.0. - Удалите следующие таблицы:
SYSTEM.FUNCTIONSYSTEM.SEQUENCESYSTEM.STATSSYSTEM.CATALOG
- Запуск репликации HBase
Депрекация
Apache Storm и Службы машинного обучения недоступны в HDInsight 4.0.
Дата выпуска: 14.04.2019
Новые возможности
Новые обновления и возможности относятся к следующим категориям.
Обновление Hadoop и других проектов с открытым кодом. Помимо исправления более чем 1000 ошибок в более чем 20 проектах с открытым кодом, это обновление также содержит новые версии Spark (2.3) и Kafka (1.0).
Обновление R Server 9.1 до Служб машинного обучения 9.3. В этом выпуске мы предоставили специалистам по анализу данных и инженерам лучшие проекты с открытым кодом, дополненные инновационными алгоритмами и возможностью легко вводить их в эксплуатацию, причем на любом удобном языке с сохранением скорости Apache Spark. Этот выпуск расширяет возможности, предлагаемые R Server, реализуя поддержку Python. Из-за этого имя кластера изменено с R Server на Службы машинного обучения.
Поддержка Azure Data Lake Storage поколения 2. HDInsight теперь будет поддерживать предварительный выпуск Azure Data Lake Storage поколения 2. Во всех регионах доступности клиентам будет предоставлена возможность выбрать учетную запись ADSL поколения 2, как основное или дополнительное хранилище для кластеров HDInsight.
Обновления пакета безопасности HDInsight Enterprise (предварительная версия) — поддержка конечных точек виртуальной сети для Azure Blob Storage, ADLS 1-го поколения, Azure Cosmos DB и Azure DB.
Версии компонентов
Официальные версии Apache всех компонентов HDInsight 3.6 перечислены ниже. Все компоненты, перечисленные здесь, являются официальными выпусками Apache самых последних из доступных стабильных версий.
Apache Hadoop 2.7.3
Apache HBase 1.1.2
Apache Hive 1.2.1
Apache Hive 2.1.0
Apache Kafka 1.0.0
Apache Mahout 0.9.0+
Apache Oozie 4.2.0
Apache Phoenix 4.7.0
Apache Pig 0.16.0
Apache Ranger 0.7.0
Apache Slider 0.92.0
Apache Spark 2.2.0/2.3.0
Apache Sqoop 1.4.6
Apache Storm 1.1.0
Apache TEZ 0.7.0
Apache Zeppelin 0.7.3
Apache ZooKeeper 3.4.6
В дополнение к версиям, перечисленным выше, более поздние версии нескольких компонентов Apache иногда включаются в пакет в платформе HDP. В этом случае эти более поздние версии приводятся в таблице технических предварительных версий и не должны заменять версии компонента Apache указанного выше списка в рабочей среде.
Сведения об исправлениях Apache
Hadoop
В этом выпуске содержится Hadoop Common 2.7.3 и следующие исправления Apache.
HADOOP-13190: упомянуть LoadBalancingKMSClientProvider в документации высокой доступности KMS.
HADOOP-13227: обработчик AsyncCallHandler должен использовать архитектуру, управляемую событиями, для обработки асинхронных вызовов.
HADOOP-14104: клиент должен всегда запрашивать namenode для пути поставщика KMS.
HADOOP-14799: обновите nimbus-jose-jwt до версии 4.41.1.
HADOOP-14814: Исправление изменения несовместимого API в FsServerDefaults, связанного с HADOOP-14104.
HADOOP-14903: добавьте явным образом json-smart в файл pom.xml.
HADOOP-15042: Azure PageBlobInputStream.skip() может возвращать отрицательное значение, когда значение numberOfPagesRemaining равно 0.
HADOOP-15255: поддержка преобразования верхнего и нижнего регистров для имен групп в LdapGroupsMapping.
HADOOP-15265: исключите явным образом json-smart из файла pom.xml hadoop-auth.
HDFS-7922: ShortCircuitCache#close не выпускает ScheduledThreadPoolExecutors.
HDFS-8496: вызов stopWriter() с блокировкой FSDatasetImpl может блокировать другие потоки (cmccabe).
HDFS-10267: дополнительно синхронизированный в FsDatasetImpl#recoverAppend и FsDatasetImpl#recoverClose.
HDFS-10489: объявите устаревшим URI dfs.encryption.key.provider.uri для зон шифрования HDFS.
HDFS-11384: добавьте параметр для балансировщика для разгона вызовов getBlocks, чтобы избежать всплеска rpc.CallQueueLength узла NameNode.
HDFS-11689: новое исключение, вызванное
DFSClient%isHDFSEncryptionEnabled, сломало кодhackyHive.HDFS-11711: DN не должен удалять блок при исключении "Слишком много открытых файлов".
HDFS-12347: TestBalancerRPCDelay#testBalancerRPCDelay часто дает сбой.
HDFS-12781: после
Datanodeпадения во вкладкеNamenodeвDatanodeUI появляется предупреждающее сообщение.HDFS-13054: обработка PathIsNotEmptyDirectoryException при
DFSClientвызове удаления.HDFS-13120: Разница моментальных снимков могла быть повреждена после объединения.
YARN-3742: YARN RM завершит работу, если
ZKClientвремя создания истекло.YARN-6061: добавьте обработчик UncaughtExceptionHandler для критических потоков в RM.
YARN-7558: команда yarn logs не может получить журналы для выполняющихся контейнеров, если проверка подлинности пользовательского интерфейса активирована.
YARN-7697: извлечение журналов для готового приложения завершается сбоем, даже если выполнена агрегация журнала.
В HDP версии 2.6.4 содержится Hadoop Common 2.7.3 и следующие исправления Apache.
HADOOP-13700: Удалите необработанные
IOExceptionиз TrashPolicy#initialize и #getInstance сигнатур.HADOOP-13709: возможность убирать подпроцессы, порожденные Shell, при завершении процесса.
HADOOP-14059: опечатка в
s3aсообщении об ошибке переименования (self, subdir).HADOOP-14542: добавьте средство ведения журнала IOUtils.cleanupWithLogger, которое принимает API средства ведения журнала slf4j.
HDFS-9887: время ожидания сокета WebHDFS должно быть настраиваемое.
HDFS-9914: исправьте настраиваемое время ожидания на чтение и подключение WebHDFS.
MAPREDUCE-6698: увеличьте время ожидания в TestUnnecessaryBlockingOnHist oryFileInfo.testTwoThreadsQueryingDifferentJobOfSameUser.
YARN-4550: некоторые тесты в TestContainerLaunch не проходят в средах с неанглийскими локалями.
YARN-4717: работа каталога TestResourceLocalizationService.testPublicResourceInitializesLocalDir периодически прерывается из-за исключения IllegalArgumentException в процессе очистки.
YARN-5042: смонтируйте /sys/fs/cgroup в контейнеры Docker в режиме только для чтения.
YARN-5318: Устранение проблемы с периодическим сбоем теста TestRMAdminService#testRefreshNodesResourceWithFileSystemBasedConfigurationProvider.
YARN-5641: средство локализации оставляет TAR-архивы после завершения работы контейнера.
YARN-6004: Refactor TestResourceLocalizationService#testDownloadingResourcesOnContainer, чтобы оно было меньше 150 строк.
YARN-6078: контейнеры зависли в состоянии локализации.
YARN-6805: NPE в исполнителе LinuxContainerExecutor из-за кода завершения исключения PrivilegedOperationException со значением NULL.
HBase
В этом выпуске содержится HBase 1.1.2 и следующие исправления Apache.
HBASE-13376: улучшения стохастической подсистемы балансировки нагрузки.
HBASE-13716: прекратите использовать константы FSConstants Hadoop.
HBASE-13848: получите доступ к паролям SSL InfoServer с помощью API поставщика учетных данных.
HBASE-13947: используйте службы MasterServices вместо сервера в AssignmentManager.
HBASE-14135: этап 3 резервного копирования и восстановления HBase — объедините образы резервных копий.
HBASE-14473: вычислите местоположение региона в параллельном режиме.
HBASE-14517: отображение
regionserver'sверсии на главной странице состояния.HBASE-14606: Время ожидания тестов TestSecureLoadIncrementalHFiles истекло в основной ветке сборки на Apache.
HBASE-15210: отмените интенсивное ведение журналов для десятков строк за миллисекунду в подсистеме балансировки нагрузки.
HBASE-15515: оптимизируйте в балансировщике LocalityBasedCandidateGenerator.
HBASE-15615: неправильное время сна, когда
RegionServerCallableтребуется повторить попытку.HBASE-16135: PeerClusterZnode, находящийся под rs, удаленного однорангового узла может никогда не быть удален.
HBASE-16570: при запуске вычислите местоположение региона в параллельном режиме.
HBASE-16810: HBase Balancer вызывает исключение ArrayIndexOutOfBoundsException, когда
regionserversнаходятся в /hbase/draining znode и не загружены.HBASE-16852: тест TestDefaultCompactSelection не прошёл на ветви branch-1.3.
HBASE-17387: Снижение издержек, связанных с отчетом об исключениях в RegionActionResult для multi().
HBASE-17850: служебная программа восстановления резервной копии.
HBASE-17931: назначьте системные таблицы серверам с наивысшей версией.
HBASE-18083: обеспечьте возможность настройки числа потоков очистки файлов небольших и больших размеров в HFileCleaner.
HBASE-18084: оптимизируйте CleanerChore для очистки каталога, который потребляет больше дискового пространства.
HBASE-18164: более быстрая функция стоимости местоположения и генератор-кандидат.
HBASE-18212: В автономном режиме с локальной файловой системой журналы HBase показывают предупреждающее сообщение: Не удалось вызвать метод 'unbuffer' в классе org.apache.hadoop.fs.FSDataInputStream.
HBASE-18808: неэффективная проверка конфигурации в BackupLogCleaner#getDeletableFiles().
HBASE-19052: FixedFileTrailer должен распознавать класс CellComparatorImpl в ветви branch-1.x.
HBASE-19065: метод HRegion#bulkLoadHFiles() должен ожидать завершения параллельного метода Region#flush().
HBASE-19285: добавьте гистограммы задержки для каждой таблицы.
HBASE-19393: ошибка HTTP 413 FULL head (полный заголовок) во время доступа к пользовательскому интерфейсу HBase с помощью SSL.
HBASE-19395: [branch-1] TestEndToEndSplitTransaction.testMasterOpsWhileSplitting завершается сбоем из-за ошибки NPE.
HBASE-19421: ветвь branch-1 не компилируется с Hadoop версии 3.0.0.
HBASE-19934: исключение HBaseSnapshotException, когда включены реплики для чтения, и создаётся моментальный снимок в реальном времени после разделения региона.
HBASE-20008: [backport] ошибка NullPointerException при восстановлении моментального снимка после разделения региона.
Куст
В этом выпуске содержатся Hive 1.2.1 и Hive 2.1.0, а также следующие исправления.
Исправления Apache Hive 1.2.1:
HIVE-10697: ObjectInspectorConvertors#UnionConvertor выполняет ошибочное преобразование.
HIVE-11266: неправильный результат count(*), основанный на статистике таблицы для внешних таблиц.
HIVE-12245: поддержка комментариев в столбцах для таблицы на основе HBase.
HIVE-12315: исправьте деление на ноль двойного значения в векторной форме.
HIVE-12360: некорректный поиск в ORC без сжатия с включением предиката.
HIVE-12378: исключение в бинарном поле HBaseSerDe.serialize.
HIVE-12785: Просмотр с объединённым типом и пользовательской функцией (UDF) для структуры не работает.
HIVE-14013: в таблице с описанием неправильно отображается Юникод.
HIVE-14205: Hive не поддерживает тип объединения с файлом формата AVRO.
HIVE-14421: FS.deleteOnExit содержит ссылки на файлы _tmp_space.db.
HIVE-15563: проигнорируйте исключение перехода состояния недопустимой операции в запросе SQLOperation.runQuery, чтобы предоставить реальное исключение.
HIVE-15680: неправильные результаты в режиме MR, когда hive.optimize.index.filter=true и в запросе дважды содержится ссылка на одну таблицу ORC.
HIVE-15883: сопоставленная таблица HBase в Hive INSERT не подходит для десятичного числа.
HIVE-16232: Поддержка вычисления статистики для столбцов в QuotedIdentifier.
HIVE-16828: При включенной оптимизации на основе затрат, запрос в секционированных представлениях вызывает исключение IndexOutOfBoundsException.
HIVE-17013: Удалить запрос с подзапросом, основанным на выборе вида.
HIVE-17063: вставка с перезаписью раздела во внешнюю таблицу завершается сбоем, если сначала выполняется удаление раздела.
HIVE-17259: Hive JDBC не распознает столбцы UNIONTYPE.
HIVE-17419: при выполнении команды ANALYZE TABLE...COMPUTE STATISTICS FOR COLUMNS отображается вычисленная статистика для маскированных таблиц.
HIVE-17530: ClassCastException при преобразовании
uniontype.HIVE-17621: настройки Hive-site игнорируются во время вычисления сплитов HCatInputFormat.
HIVE-17636: добавлен тест multiple_agg.q для
blobstores.HIVE-17729: добавьте базу данных и объясните связанные проверки в хранилище BLOB-объектов.
HIVE-17731: добавьте обратный
compatвариант для внешних пользователей в HIVE-11985.HIVE-17803: при использовании множественного запроса Pig записи двух HCatStorers в одну таблицу будут перезаписывать выходные данные друг друга.
HIVE-17829: ArrayIndexOutOfBoundsException — таблицы на основе HBASE со схемой Avro в
Hive2.HIVE-17845: вставка неудачна, если столбцы целевой таблицы не в нижнем регистре.
HIVE-17900: анализ статистики по столбцам, вызванный Компактором, приводит к созданию некорректного SQL с 1 столбцом раздела.
HIVE-18026: оптимизация основной конфигурации Hive WebHCat.
HIVE-18031: Поддержка репликации для операции ALTER DATABASE.
HIVE-18090: сбой пульса ACID при подключении хранилища метаданных через учетные данные Hadoop.
HIVE-18189: запрос Hive возвращает неправильные результаты, если для псевдонима hive.groupby.orderby.position.alias установлено значение true.
HIVE-18258: векторизация — Reduce-Side GROUP BY MERGEPARTIAL с двойными столбцами неработоспособна.
HIVE-18293: Hive не может сжимать таблицы, содержащиеся в папке, которая не принадлежит пользователю, запускающему HiveMetaStore.
HIVE-18327: удалите ненужную зависимость HiveConf для MiniHiveKdc.
HIVE-18341: добавьте поддержку загрузки REPL для добавления «необработанного» пространства имен для TDE с одинаковыми ключами шифрования.
HIVE-18352: введите параметр METADATAONLY при выполнении REPL DUMP, чтобы разрешить процессы интеграции других инструментов.
HIVE-18353: CompactorMR должен вызвать метод jobclient.close() для активации очистки.
HIVE-18390: IndexOutOfBoundsException при запросе секционированного представления в ColumnPruner.
HIVE-18429: сжатие должно обработать случай при отсутствии выходных данных.
HIVE-18447: JDBC — предоставьте пользователям JDBC возможность передавать сведения о файлах cookie через строку подключения.
HIVE-18460: компактор не передает свойства таблицы пишущему модулю ORC.
HIVE-18467: поддержка целого дампа хранилища и загрузки, а также создание и удаление событий в базе данных (Анишек Агарвал (Anishek Agarwal), редакция Санкар Харипапан (Sankar Hariappan)).
HIVE-18551: векторизация — VectorMapOperator пытается написать слишком много векторных столбцов для Hybrid Grace.
HIVE-18587: вставить событие DML может попытаться вычислить контрольную сумму по каталогам.
HIVE-18613: продлите JsonSerDe для поддержки типа BINARY.
HIVE-18626: инструкция REPL load "with" не передает конфигурацию задачам.
HIVE-18660: PCR не различает разделы и виртуальные столбцы.
HIVE-18754: Конструкция состояния REPL должна поддерживать оператор WITH.
HIVE-18754: Конструкция состояния REPL должна поддерживать оператор WITH.
HIVE-18788: Очистка входных данных в JDBC PreparedStatement.
HIVE-18794: Клауза "with" в команде загрузки REPL не передает конфигурацию задачам для непространственных таблиц.
HIVE-18808: обеспечьте более надежное сжатие при сбое обновления статистических данных.
HIVE-18817: исключение ArrayIndexOutOfBounds во время чтения таблицы ACID.
HIVE-18833: автоматическое объединение сбой при выполнении команды "insert into directory as orcfile".
HIVE-18879: запретите работу внедренного элемента в UDFXPathUtil при наличии в пути класса файла xercesImpl.jar.
HIVE-18907: создайте утилиту, чтобы исправить проблему индекса ключа ACID в HIVE-18817.
Исправления Apache Hive 2.1.0:
HIVE-14013: в таблице с описанием неправильно отображается Юникод.
HIVE-14205: Hive не поддерживает тип объединения с файлом формата AVRO.
HIVE-15563: проигнорируйте исключение перехода состояния недопустимой операции в запросе SQLOperation.runQuery, чтобы предоставить реальное исключение.
HIVE-15680: неправильные результаты в режиме MR, когда hive.optimize.index.filter=true и в запросе дважды содержится ссылка на одну таблицу ORC.
HIVE-15883: сопоставленная таблица HBase в Hive INSERT не подходит для десятичного числа.
HIVE-16757: удалить вызовы устаревшего метода AbstractRelNode.getRows.
HIVE-16828: При включенной оптимизации на основе затрат, запрос в секционированных представлениях вызывает исключение IndexOutOfBoundsException.
HIVE-17063: вставка с перезаписью раздела во внешнюю таблицу завершается сбоем, если сначала выполняется удаление раздела.
HIVE-17259: Hive JDBC не распознает столбцы UNIONTYPE.
HIVE-17530: ClassCastException при преобразовании
uniontype.HIVE-17600: обеспечьте пользователям возможность настроить размер enforceBufferSize ORC-файла.
HIVE-17601: оптимизируйте обработку ошибок в LlapServiceDriver.
HIVE-17613: удалить пулы объектов для коротких распределений в контексте одного потока.
HIVE-17617: Свертывание пустого набора результатов должно включать группировку пустой совокупности.
HIVE-17621: настройки Hive-site игнорируются во время вычисления сплитов HCatInputFormat.
HIVE-17629: CachedStore: имеет утвержденную или не утвержденную конфигурацию, чтобы разрешить выборочное кэширование таблиц и секций и разрешить чтение во время предварительного потепления.
HIVE-17636: добавлен тест multiple_agg.q для
blobstores.HIVE-17702: неправильная обработка isRepeating в десимальном считывателе в ORC.
HIVE-17729: добавьте базу данных и объясните связанные проверки в хранилище BLOB-объектов.
HIVE-17731: добавьте обратный
compatвариант для внешних пользователей в HIVE-11985.HIVE-17803: при использовании множественного запроса Pig записи двух HCatStorers в одну таблицу будут перезаписывать выходные данные друг друга.
HIVE-17845: вставка неудачна, если столбцы целевой таблицы не в нижнем регистре.
HIVE-17900: анализ статистики по столбцам, вызванный Компактором, приводит к созданию некорректного SQL с 1 столбцом раздела.
HIVE-18006: оптимизируйте объем памяти HLLDenseRegister.
HIVE-18026: оптимизация основной конфигурации Hive WebHCat.
HIVE-18031: Поддержка репликации для операции ALTER DATABASE.
HIVE-18090: сбой пульса ACID при подключении хранилища метаданных через учетные данные Hadoop.
HIVE-18189: порядок по позиции не работает при
cboотключении.HIVE-18258: векторизация — Reduce-Side GROUP BY MERGEPARTIAL с двойными столбцами неработоспособна.
HIVE-18269: LLAP: быстрое
llapвыполнение операций ввода-вывода с конвейером медленной обработки может привести к OOM.HIVE-18293: Hive не может сжимать таблицы, содержащиеся в папке, которая не принадлежит пользователю, запускающему HiveMetaStore.
HIVE-18318: устройство чтения записей LLAP должно проверять прерывания, даже при отсутствии блокировки.
HIVE-18326: планировщик LLAP Tez должен прекращать выполнение заданий только при наличии между ними зависимости.
HIVE-18327: удалите ненужную зависимость HiveConf для MiniHiveKdc.
HIVE-18331: Добавить повторный вход при истечении TGT и логирование/лямбда.
HIVE-18341: добавьте поддержку загрузки REPL для добавления «необработанного» пространства имен для TDE с одинаковыми ключами шифрования.
HIVE-18352: введите параметр METADATAONLY при выполнении REPL DUMP, чтобы разрешить процессы интеграции других инструментов.
HIVE-18353: CompactorMR должен вызвать метод jobclient.close() для активации очистки.
HIVE-18384: ConcurrentModificationException в
log4j2.xбиблиотеке.HIVE-18390: IndexOutOfBoundsException при запросе секционированного представления в ColumnPruner.
HIVE-18447: JDBC — предоставьте пользователям JDBC возможность передавать сведения о файлах cookie через строку подключения.
HIVE-18460: компактор не передает свойства таблицы пишущему модулю ORC.
HIVE-18462: (пояснение форматирования для запросов с map join и columnExprMap, с неформатированным именем столбца).
HIVE-18467: поддержка целого дампирования/загрузки хранилища и событий создания/удаления базы данных.
HIVE-18488: в считывателях LLAP ORC отсутствуют некоторые проверки значений NULL.
HIVE-18490: запрос с инструкциями EXISTS и NOT EXISTS с неэквивалентным предикатом может привести к неправильному результату.
HIVE-18506: формат LlapBaseInputFormat — отрицательный индекс массива.
HIVE-18517: векторизация — исправьте VectorMapOperator для приема VRB и проверьте правильное расположение векторизованного флага для поддержки кэширования LLAP.
HIVE-18523: исправьте строку сводки в случае отсутствия входных данных.
HIVE-18528: объединенные статистические данные в ObjectStore получили неправильный результат.
HIVE-18530: репликация должна пропустить таблицу MM (на данном этапе).
HIVE-18548: исправьте
log4jимпорт.HIVE-18551: векторизация — VectorMapOperator пытается написать слишком много векторных столбцов для Hybrid Grace.
HIVE-18577: у SemanticAnalyzer.validate есть некоторые нецелесообразные вызовы хранилища метаданных.
HIVE-18587: вставить событие DML может попытаться вычислить контрольную сумму по каталогам.
HIVE-18597: LLAP: всегда упаковывал
log4j2JAR-файл API дляorg.apache.log4j.HIVE-18613: продлите JsonSerDe для поддержки типа BINARY.
HIVE-18626: инструкция REPL load "with" не передает конфигурацию задачам.
HIVE-18643: не выполняйте проверку архивных разделов для операций ACID.
HIVE-18660: PCR не различает разделы и виртуальные столбцы.
HIVE-18754: Конструкция состояния REPL должна поддерживать оператор WITH.
HIVE-18788: Очистка входных данных в JDBC PreparedStatement.
HIVE-18794: Клауза "with" в команде загрузки REPL не передает конфигурацию задачам для непространственных таблиц.
HIVE-18808: обеспечьте более надежное сжатие при сбое обновления статистических данных.
HIVE-18815: удалите неиспользуемую функцию в HPL и SQL.
HIVE-18817: исключение ArrayIndexOutOfBounds во время чтения таблицы ACID.
HIVE-18833: автоматическое объединение сбой при выполнении команды "insert into directory as orcfile".
HIVE-18879: запретите работу внедренного элемента в UDFXPathUtil при наличии в пути класса файла xercesImpl.jar.
HIVE-18944: во время DPP неправильно задана позиция наборов группирования.
Кафка
В этом выпуске содержится Kafka 1.0.0 и следующие исправления Apache.
KAFKA-4827: Kafka connect: ошибка со специальными знаками в имени коннектора.
KAFKA-6118: Временный сбой в тесте kafka.api.SaslScramSslEndToEndAuthorizationTest.testTwoConsumersWithDifferentSaslCredentials.
KAFKA-6156: JmxReporter не может обрабатывать пути каталога в стиле Windows.
KAFKA-6164: потоки ClientQuotaManager предотвращают выключение при возникновении ошибки при загрузке журналов.
KAFKA-6167: метка времени в каталоге потоков содержит двоеточие, которое является недопустимым символом.
KAFKA-6179: метод RecordQueue.clear() не очищает поддерживаемый список MinTimestampTracker.
KAFKA-6185: утечка памяти селектора с высокой вероятностью OOM при уменьшении преобразования.
KAFKA-6190: GlobalKTable никогда не завершает восстановление при потреблении транзактных сообщений.
KAFKA-6210: исключение IllegalArgumentException, если версия 1.0.0 используется для inter.broker.protocol.version или log.message.format.version.
KAFKA-6214: использование резервных реплик с хранилищем состояний в оперативной памяти приводит к сбою потоков.
KAFKA-6215: KafkaStreamsTest сбой в основной ветке.
KAFKA-6238: проблемы с версией протокола при применении последовательного обновления до версии 1.0.0.
KAFKA-6260: AbstractCoordinator нечетко обрабатывает исключение NULL.
KAFKA-6261: логирование запросов вызывает исключение, если acks = 0.
KAFKA-6274: улучшить
KTableавтоматически созданные имена хранилища источника состояния.
Махут
В HDP версий 2.3.x и 2.4.x вместо использования определенного релиза Apache Mahout, мы синхронизировались с конкретной точкой редакции в основной ветке Apache Mahout. Эта точка версии идет после выпуска 0.9.0, но до выпуска 0.10.0. Это обеспечивает большое количество исправлений ошибок и функциональных улучшений по сравнению с версией 0.9.0, но предлагает стабильный выпуск функций Mahout перед полным переходом на новую версию Mahout на основе Spark в версии 0.10.0.
Точка ревизии, выбранная для Mahout в HDP версий 2.3.x и 2.4.x, относится к ветви "mahout-0.10.x" Apache Mahout на 19 декабря 2014 года, ревизия 0f037cb03e77c096 в GitHub.
В HDP версий 2.5.x и 2.6.x мы удалили библиотеку "commons-httpclient" из Mahout, потому что рассматриваем ее как устаревшую с возможными проблемами безопасности. Мы обновили клиент Hadoop-Client в Mahout до версии 2.7.3, той же версии, используемой в HDP версии 2.5. В результате:
Ранее скомпилированные задания Mahout необходимо повторно компилировать в среде HDP-2.5 или 2.6.
Существует небольшая вероятность того, что некоторые задания Mahout могут столкнуться с ошибками ClassNotFoundException или "не удалось загрузить класс", связанных с префиксом "org.apache.commons.httpclient", "net.java.dev.jets3t" или соответствующими префиксами имени класса. Если эти ошибки возникают, вы можете рассмотреть, следует ли вручную устанавливать необходимые JAR-файлы в пути к заданию, если риск проблем безопасности в устаревшей библиотеке является приемлемым в вашей среде.
Существует еще меньшая вероятность того, что некоторые задания Mahout могут столкнуться со сбоями в вызовах hbase-client к библиотекам hadoop-common из-за проблем с бинарной совместимостью. К сожалению, нет способа устранить эту проблему, кроме возврата к версии HDP-2.4.2 Mahout, которая может иметь проблемы с безопасностью. Опять же, это случается редко и вряд ли произойдет в любом доступном наборе заданий Mahout.
Oozie,
В этом выпуске содержится Oozie 4.2.0 и следующие исправления Apache.
OOZIE-2571: добавьте свойство Maven spark.scala.binary.version, чтобы можно было использовать Scala 2.11.
OOZIE-2606: установите spark.yarn.jars, чтобы исправить Spark 2.0 с помощью Oozie.
OOZIE-2658: Параметр --driver-class-path может перезаписать путь класса в SparkMain.
OOZIE-2787: Oozie распространяет JAR-файл приложения дважды, что приводит к сбою задания Spark.
OOZIE-2792:
Hive2действие не анализирует идентификатор приложения Spark из файла журнала правильно, когда Hive находится в Spark.OOZIE-2799: настройка местоположения журнала для Spark SQL в Hive.
OOZIE-2802: сбой действия Spark в Spark 2.1.0 из-за дублирования
sharelibs.OOZIE-2923: оптимизируйте синтаксический анализ параметров Spark.
OOZIE-3109: SCA — отражённый межсайтовый скриптинг.
OOZIE-3139: Oozie неправильно проверяет рабочий процесс.
OOZIE-3167: обновление версии Tomcat в ветке Oozie 4.3.
Феникс
В этом выпуске содержится Phoenix 4.7.0 и следующие исправления Apache.
PHOENIX-1751: выполняйте агрегацию, сортировку и т. д. в preScannerNext, а не postScannerOpen.
PHOENIX-2714: исправьте оценку байтов в BaseResultIterators и предоставьте как интерфейс.
PHOENIX-2724: запрос с большим количеством ориентиров выполняется медленнее по сравнению с запросом без статистики.
PHOENIX-2855: Обходное решение для инкремента TimeRange, который не сериализуется в HBase 1.2.
PHOENIX-3023: низкая производительность при параллельном выполнении запросов ограничения по умолчанию.
PHOENIX-3040: не используйте направляющие для выполнения запросов поочередно.
PHOENIX-3112: частичное сканирование строки обрабатывается неправильно.
PHOENIX-3240: исключение ClassCastException из загрузчика Pig.
PHOENIX-3452: NULLS FIRST/NULL LAST не должно влиять на то, сохраняет ли GROUP BY порядок.
PHOENIX-3469: неверный порядок сортировки для первичного ключа DESC для NULLS LAST и NULLS FIRST.
PHOENIX-3789: выполните вызовы обслуживания межрегионального индекса в postBatchMutateIndispensably.
PHOENIX-3865: IS NULL не возвращает правильные результаты, если фильтрация не применяется к первому семейству столбцов.
PHOENIX-4290: полное сканирование таблицы, выполненное для DELETE с таблицей, содержащей неизменяемые индексы.
PHOENIX-4373: Ключ переменной длины локального индекса может содержать завершающие нули при операции вставки или обновления.
PHOENIX-4466: исключение java.lang.RuntimeException — код отклика 500 — выполнение задания Spark для подключения к серверу запросов Phoenix и загрузки данных.
PHOENIX-4489: утечка соединений HBase в заданиях Phoenix MR.
PHOENIX-4525: переполнение целого числа в выполнении GroupBy.
PHOENIX-4560: ORDER BY с GROUP BY не работает, если к
pkстолбцу применяется WHERE.PHOENIX-4586: UPSERT SELECT не принимает во внимание операторы сравнения для подзапросов.
PHOENIX-4588: клонировать выражение также, если его дочерние элементы включают Determinism.PER_INVOCATION.
Свинья
В этом выпуске содержится Pig 0.16.0 и следующие исправления Apache.
PIG-5159: Исправить, что Pig не сохраняет историю Grunt.
PIG-5175: обновление
jrubyдо версии 1.7.26.
Рейнджер
В этом выпуске содержится Ranger 0.7.0 и следующие исправления Apache.
RANGER-1805: улучшение кода для отслеживания лучших методик в JS.
RANGER-1960: Для операции удаления учтите название таблицы моментального снимка.
RANGER-1982: исправление ошибок для метрики аналитики администратора и сервера управления ключами Ranger.
RANGER-1984: записи журнала аудита HBase могут не отображать все теги, связанные с доступом к столбцу.
RANGER-1988: исправьте небезопасную случайность.
RANGER-1990: добавьте одностороннюю поддержку MySQL SSL для администратора Ranger.
RANGER-2006: устранение проблем, обнаруженных статическим анализом кода в ranger
usersyncдляldapисточника синхронизации.RANGER-2008: Происходит сбой при оценке политики для многолинейных условий политики.
Ползунок
В этом выпуске предоставляется Slider 0.92.0 без дополнительных исправлений Apache.
Спарк
В этом выпуске содержится Spark 2.3.0 и следующие исправления Apache.
SPARK-13587: включите поддержку virtualenv в PySpark.
SPARK-19964: избегайте чтения из удаленного репозитория в SparkSubmitSuite.
SPARK-22882: тест машинного обучения для структурированной потоковой передачи: ml.classification.
SPARK-22915: тесты потоковой передачи для spark.ml.feature, от N до Z.
SPARK-23020: Исправление очередного состояния гонки в внутрипроцессном тесте средства запуска.
SPARK-23040: возвращает прерываемый итератор для читателя шифрованных данных.
SPARK-23173: не создавайте поврежденные файлы Parquet при загрузке данных из JSON.
SPARK-23264: Исправление ошибки scala.MatchError в literals.sql.out.
SPARK-23288: исправьте выходные показатели с помощью приемника Parquet.
SPARK-23329: исправьте документацию о тригонометрических функциях.
SPARK-23406: включите самосоединение потоков для ветви branch-2.3.
SPARK-23434: Spark не должен выводить предупреждение о каталоге метаданных для пути к файлу HDFS.
SPARK-23436: Определять раздел как Дата только в том случае, если его можно привести к типу Дата.
SPARK-23457: сначала зарегистрируйте слушателей завершения задачи в ParquetFileFormat.
SPARK-23462: оптимизируйте сообщение об ошибке в отсутствующем поле "StructType".
SPARK-23490: проверьте storage.locationUri с помощью имеющейся таблицы в CreateTable.
SPARK-23524: большие локальные блоки перемешивания не должны проверяться на повреждение.
SPARK-23525: включите поддержку ALTER TABLE CHANGE COLUMN COMMENT для внешней таблицы Hive.
SPARK-23553: тесты не должны предполагать значение по умолчанию "spark.sql.sources.default".
SPARK-23569: Позволить pandas_udf работать с функциями с аннотациями типов в стиле python3.
SPARK-23570: добавьте Spark 2.3.0 в HiveExternalCatalogVersionsSuite.
SPARK-23598: сделайте методы в BufferedRowIterator общедоступными, чтобы избежать ошибки времени выполнения для большого запроса.
SPARK-23599: добавьте генератор UUID из псевдослучайных чисел.
SPARK-23599: используйте RandomUUIDGenerator в выражении Uuid.
SPARK-23601: удалить
.md5файлы из релиза.SPARK-23608: добавьте синхронизацию в SHS между функциями attachSparkUI и detachSparkUI, чтобы избежать проблемы параллельной модификации в обработчиках Jetty.
SPARK-23614: Исправлено неправильное повторное использование обмена при кэшировании.
SPARK-23623: следует избегать параллельного использования кэшированных консумеров в CachedKafkaConsumer (ветвь-2.3).
SPARK-23624: Пересмотр документации метода pushFilters в Datasource V2.
SPARK-23628: calculateParamLength не должен возвращать результат в виде 1 + количество выражений.
SPARK-23630: разрешите активацию настроек конфигурации Hadoop пользователя.
SPARK-23635: переменная среды исполнителя Spark перезаписывается переменной среды Application Master с тем же именем.
SPARK-23637: Yarn может выделять больше ресурсов, если один и тот же исполнитель выходит из строя несколько раз.
SPARK-23639: получите токен перед инициализацией клиента хранилища метаданных в CLI SparkSQL.
SPARK-23642: подкласс AccumulatorV2 isZero
scaladocисправление.SPARK-23644: используйте абсолютный путь для вызова REST в SHS.
SPARK-23645: Добавить документацию относительно "pandas_udf" с ключевыми аргументами.
SPARK-23649: пропуск символов, запрещенных в UTF-8.
SPARK-23658: InProcessAppHandle использует неправильный класс в getLogger.
SPARK-23660: Исправлено исключение в режиме кластера YARN, когда приложение быстро завершает работу.
SPARK-23670: исправьте проблему утечки памяти в SparkPlanGraphWrapper.
SPARK-23671: исправьте условие, чтобы включить пул потоков SHS.
SPARK-23691: используйте утилиту sql_conf в тестах PySpark, где это возможно.
SPARK-23695: исправьте сообщение об ошибке для тестов потоковой передачи Kinesis.
SPARK-23706: spark.conf.get(value, default=None) должно формировать значение None в PySpark.
SPARK-23728: Исправлены тесты машинного обучения с ожидаемыми исключениями для потоковых тестов.
SPARK-23729: учитывайте фрагмент унифицированного указателя ресурсов (URI) при обработке шаблонов glob.
SPARK-23759: не удалось связать пользовательский интерфейс Spark с конкретным именем узла или IP-адреса.
SPARK-23760: CodegenContext.withSubExprEliminationExprs должен правильно сохранять и восстанавливать состояние CSE.
SPARK-23769: Удалите комментарии, которые ненужно отключают
Scalastyleпроверку.SPARK-23788: исправьте ошибку состояния гонки в StreamingQuerySuite.
SPARK-23802: PropagateEmptyRelation может оставить план запроса в неразрешенном состоянии.
SPARK-23806: Broadcast.unpersist может вызвать фатальное исключение при использовании с динамическим распределением.
SPARK-23808: установите сеанс Spark по умолчанию в сеансах Spark только для тестирования.
SPARK-23809: активный SparkSession должен быть установлен с помощью getOrCreate.
SPARK-23816: завешенные задачи должны игнорировать FetchFailures.
SPARK-23822: оптимизируйте сообщение об ошибке для несоответствий схемы Parquet.
SPARK-23823: придерживайтесь исходной формы в transformExpression.
SPARK-23827: оператор StreamingJoinExec должен обеспечивать разбиение входных данных на заданное число разделов.
SPARK-23838: на вкладке SQL запуск SQL-запроса отображается как "завершен".
SPARK-23881: исправьте нестабильный тест JobCancellationSuite — прерываемый итератор средства чтения shuffle.
Sqoop
В этом выпуске предоставляется Sqoop 1.4.6 без дополнительных исправлений Apache.
Буря
В этом выпуске содержатся сведения о Storm 1.1.1 и следующие исправления Apache.
STORM-2652: исключение, вызванное в открытом методе JmsSpout.
STORM-2841: юнит-тест testNoAcksIfFlushFails завершился сбоем с исключением NullPointerException.
STORM-2854: Сделать интерфейс IEventLogger доступным для подключения модулей журнала событий.
STORM-2870: FileBasedEventLogger имеет утечку ExecutorService недемонического типа, что мешает завершению процесса.
STORM-2960: Лучше выделить важность создания правильной учетной записи ОС для процессов Storm.
Тез
В этом выпуске содержатся сведения о Tez 0.7.0 и следующие исправления Apache.
- TEZ-1526: LoadingCache для TezTaskID замедляется для больших заданий.
Цеппелин
В этом выпуске предоставляется Zeppelin 0.7.3 без дополнительных исправлений Apache.
ZEPPELIN-3072: пользовательский интерфейс Zeppelin медленно работает или не отвечает при большом количестве записных книжек.
ZEPPELIN-3129: пользовательский интерфейс Zeppelin не выходит из Internet Explorer.
ZEPPELIN-903: замените CXF на
Jersey2.
ZooKeeper
В этом выпуске представлены ZooKeeper 3.4.6 и следующие патчи Apache.
ZOOKEEPER-1256: ошибка ClientPortBindTest в macOS X.
ZOOKEEPER-1901: [JDK8] — сортируйте дочерние элементы для сравнения в тестах AsyncOps.
ZOOKEEPER-2423: обновите версию Netty из-за уязвимости безопасности (CVE-2014-3488).
ZOOKEEPER-2693: атака типа "отказ в обслуживании" на команды wchp/wchc, каждая из которых состоит из четырех символов (4lw).
ZOOKEEPER-2726: Патч вводит потенциальное условие гонки.
Исправлены проблемы, связанные с распространенными уязвимостями и рисками
В этом разделе описываются все общие уязвимости и риски (CVE), которые рассматриваются в этом выпуске.
CVE-2017-7676
| Сводка: оценка политики Apache Ranger игнорирует символы после подстановочного знака "*" |
|---|
| Уровень серьезности: критический |
| Поставщик: Hortonworks |
| Затронутые версии: версии HDInsight 3.6, включая Apache Ranger версий 0.5.x/0.6.x/0.7.0. |
| Пользователи, на которых это повлияло: среды, использующие правила Ranger с символами после подстановочного знака "*" — например, my*test, test*.txt |
| Влияние: сопоставитель ресурса политики игнорирует символы после подстановочного знака "*", что может привести к непреднамеренному поведению. |
| Сведения об исправлении: сопоставитель ресурса политики Ranger был обновлен для правильной обработки совпадений подстановочных знаков. |
| Рекомендуемое действие: обновите HDI до версии 3.6 (с Apache Ranger 0.7.1+). |
CVE-2017-7677
| Сводка: Авторизатор Apache Ranger Hive должен проверить наличие разрешений RWX, когда указана внешняя директория |
|---|
| Уровень серьезности: критический |
| Поставщик: Hortonworks |
| Затронутые версии: версии HDInsight 3.6, включая Apache Ranger версий 0.5.x/0.6.x/0.7.0. |
| Затронутые пользователи: среды, которые используют внешнее местоположение для таблиц Hive. |
| Влияние: в средах, которые используют внешнее местоположение для таблиц Hive, Apache Ranger Hive Authorizer должен проверить наличие разрешений RWX для внешнего местоположения, указанного при создании таблицы. |
| Сведения об исправлении: авторизатор Ranger Hive был обновлен для правильной обработки проверки полномочий для внешней локации. |
| Рекомендуемое действие: пользователи должны обновить HDI до версии 3.6 (с Apache Ranger 0.7.1+). |
CVE-2017-9799
| Сводка: потенциальное выполнение кода от имени неверного пользователя в Apache Storm |
|---|
| Уровень серьезности: важно |
| Поставщик: Hortonworks |
| Затронутые версии: HDP 2.4.0, HDP-2.5.0, HDP-2.6.0 |
| Затронутые пользователи: пользователи, которые используют Storm в безопасном режиме и хранилище BLOB-объектов для распространения артефактов на основе топологии, или используют хранилище BLOB-объектов для распространения любых ресурсов топологии. |
| Влияние: в некоторых ситуациях и конфигурациях storm владелец топологии может теоретически обмануть руководителя, чтобы запустить работник от имени другого, не корневого пользователя. В худшем случае это может привести к тому, что учетные данные другого пользователя будут скомпрометированы. Эта уязвимость касается только установок Apache Storm с включенной защитой. |
| Устранение рисков: обновите HDP до версии 2.6.2.1, так как в настоящее время обходных путей нет. |
CVE-2016-4970
| Сводка: обработчик/ssl/OpenSslEngine.java в Netty 4.0.x до 4.0.37. Финальный выпуск и версии 4.1.x до 4.1.1. Финал позволяет удаленным злоумышленникам вызвать отказ в обслуживании (бесконечный цикл) |
|---|
| Уровень серьезности: средний |
| Поставщик: Hortonworks |
| Затронутые версии: HDP 2.x.x с версии 2.3.x |
| Затронутые пользователи: все пользователи, использующие HDFS. |
| Влияние: влияние недостаточное, поскольку Hortonworks не использует OpenSslEngine.java непосредственно в базе кодов Hadoop. |
| Рекомендуемое действие: обновите HDP до версии 2.6.3. |
CVE-2016-8746
| Сводка: проблема соответствия пути Apache Ranger в оценке политики |
|---|
| Уровень серьезности: обычный |
| Поставщик: Hortonworks |
| Затронутые версии: все версии HDP 2.5, включая версии Apache Ranger 0.6.0/0.6.1/0.6.2 |
| Затронутые пользователи: все пользователи средства администрирования политики Ranger. |
| Влияние: политический движок Ranger неправильно сопоставляет маршруты в определенных условиях, когда политика содержит подстановочные символы и рекурсивные флаги. |
| Сведения об исправлении: исправленная логика оценки политики |
| Рекомендуемое действие: пользователи должны обновить HDI до версии 2.5.4+ (с Apache Ranger 0.6.3+) или 2.6+ (с Apache Ranger 0.7.0+) |
CVE-2016-8751
| Сводка: у Apache Ranger есть проблема межсайтового написания скриптов |
|---|
| Уровень серьезности: обычный |
| Поставщик: Hortonworks |
| Затронутые версии: все версии HDP 2.3/2.4/2.5, включая Apache Ranger версий 0.5.x/0.6.0/0.6.1/0.6.2. |
| Затронутые пользователи: все пользователи средства администрирования политики Ranger. |
| Влияние: Apache Ranger уязвим для хранимых межсайтовых скриптов при вводе пользовательских условий политики. Администраторы могут хранить произвольный код JavaScript, который будет выполняться при входе обычных пользователей и их доступе к политикам. |
| Сведения об исправлении: добавлена логика для очистки входных данных пользователя. |
| Рекомендуемое действие: пользователи должны обновить HDI до версии 2.5.4+ (с Apache Ranger 0.6.3+) или 2.6+ (с Apache Ranger 0.7.0+) |
Исправленные проблемы для поддержки
Исправленные ошибки представляют собой выбранные проблемы, которые ранее были зарегистрированы в Hortonworks Support, но теперь рассматриваются в текущем выпуске. Эти проблемы могут быть сообщены в предыдущих версиях в разделе "Известные проблемы"; означает, что они были сообщены клиентами или идентифицированы командой Hortonworks Quality Engineering.
Неверные результаты
| Идентификатор ошибки | Apache JIRA | Сводка |
|---|---|---|
| ОШИБКА-100019 | YARN-8145 | yarn rmadmin -getGroups не возвращает обновленные группы для пользователя |
| ОШИБКА-100058 | PHOENIX-2645 | Подстановочные знаки не соответствуют знакам новой строки |
| ОШИБКА-100266 | PHOENIX-3521, PHOENIX-4190 | Результаты не соответствуют локальным индексам |
| ОШИБКА-88774 | HIVE-17617, HIVE-18413, HIVE-18523 | Сбой query36, несоответствие числа строк |
| ОШИБКА-89765 | HIVE-17702 | Неправильная обработка isRepeating в читателе десятичных чисел в ORC |
| ОШИБКА-92293 | HADOOP-15042 | Azure PageBlobInputStream.skip() может возвращать отрицательное значение, когда число numberOfPagesRemaining равно 0. |
| ОШИБКА-92345 | ATLAS-2285 | Пользовательский интерфейс: сохраненный поиск переименован с указанием даты. |
| ОШИБКА-92563 | HIVE-17495, HIVE-18528 | Объединенные статистические данные в ObjectStore получили неправильный результат |
| ОШИБКА-92957 | HIVE-11266 | Неправильный результат count(*) на основе статистики внешних таблиц |
| ОШИБКА-93097 | RANGER-1944 | Не работает фильтр действий для аудита администратора |
| ОШИБКА-93335 | HIVE-12315 | vectorization_short_regress.q содержит неправильный результат для двойного вычисления |
| ОШИБКА-93415 | HIVE-18258, HIVE-18310 | Векторизация — Reduce-Side GROUP BY MERGEPARTIAL с дубликатами столбцов не работает |
| ОШИБКА-93939 | ATLAS-2294 | При создании типа добавлен дополнительный параметр "описание" |
| ОШИБКА-94007 | PHOENIX-1751, PHOENIX-3112 | Запросы Phoenix возвращают значения NULL из-за частичных строк HBase |
| ОШИБКА-94266 | HIVE-12505 | Вставка перезаписи в зашифрованной зоне незаметно не удаляет некоторые существующие файлы. |
| ОШИБКА-94414 | HIVE-15680 | Неправильные результаты, когда hive.optimize.index.filter=true и в запросе дважды содержится ссылка на одну таблицу ORC |
| ОШИБКА-95048 | HIVE-18490 | Запрос с EXISTS и NOT EXISTS с неравенственным предикатом может привести к неправильному результату. |
| ОШИБКА-95053 | PHOENIX-3865 | IS NULL не возвращает правильные результаты, когда первое семейство столбцов не подвергается фильтрации. |
| ОШИБКА-95476 | RANGER-1966 | В некоторых случаях инициализация механизма политики не создает контекстных обогатителей |
| ОШИБКА-95566 | SPARK-23281 | Запрос генерирует результаты в неправильном порядке, когда составной порядок по предложению ссылается на исходные столбцы и псевдонимы |
| ОШИБКА-95907 | PHOENIX-3451, PHOENIX-3452, PHOENIX-3469, PHOENIX-4560 | Исправление проблем с ORDER BY ASC, если запрос включает агрегирование |
| ОШИБКА-96389 | PHOENIX-4586 | UPSERT SELECT не учитывает операторы сравнения для подзапросов. |
| ОШИБКА-96602 | HIVE-18660 | PCR не различает разделы и виртуальные столбцы |
| ОШИБКА-97686 | ATLAS-2468 | [Basic Search] Проблема с примерами OR, когда NEQ используется с числовыми типами |
| ОШИБКА-97708 | HIVE-18817 | Исключение ArrayIndexOutOfBounds во время чтения таблицы ACID |
| ОШИБКА-97864 | HIVE-18833 | Сбой автоматического объединения при выполнении операции вставки в каталог как ORCfile. |
| ОШИБКА-97889 | RANGER-2008 | Проведение оценки политики не удается для многолинейных условий политики. |
| ОШИБКА-98655 | RANGER-2066 | Доступ к семейству столбцов Hbase разрешен с помощью помеченного столбца в семействе столбцов |
| ОШИБКА-99883 | HIVE-19073, HIVE-19145 | StatsOptimizer может исказить данные в постоянных столбцах |
Другое
| Идентификатор ошибки | Apache JIRA | Сводка |
|---|---|---|
| ОШИБКА-100267 | HBASE-17170 | HBase также повторно пытается обработать исключение типа DoNotRetryIOException из-за различий в загрузчиках классов. |
| ОШИБКА-92367 | YARN-7558 | Команда "yarn logs" не может получить журналы для работающих контейнеров, если включена проверка подлинности пользовательского интерфейса (UI). |
| ОШИБКА-93159 | OOZIE-3139 | Oozie неправильно проверяет рабочий процесс |
| ОШИБКА-93936 | ATLAS-2289 | Нужно удалить из реализации KafkaNotification встроенный код start/stop сервера kafka/zookeeper |
| ОШИБКА-93942 | ATLAS-2312 | Используйте объекты ThreadLocal DateFormat для избегания одновременного использования в нескольких потоках. |
| ОШИБКА-93946 | ATLAS-2319 | Пользовательский интерфейс: для удаления тега, который находится на 25-й или ниже позиции в списке тегов в как плоской, так и древовидной структуре, необходимо обновить список. |
| ОШИБКА-94618 | YARN-5037, YARN-7274 | Возможность отключить эластичность на уровне листовой очереди |
| ОШИБКА-94901 | HBASE-19285 | Добавьте гистограммы задержки для каждой таблицы |
| ОШИБКА-95259 | HADOOP-15185, HADOOP-15186 | Обновление adls соединителя для использования текущей версии пакета SDK ADLS |
| ОШИБКА-95619 | HIVE-18551 | Векторизация — VectorMapOperator пытается написать слишком много векторных столбцов для Hybrid Grace |
| ОШИБКА-97223 | SPARK-23434 | Spark не должен предупреждать `каталог метаданных` для пути к файлу HDFS |
Производительность
| Идентификатор ошибки | Apache JIRA | Сводка |
|---|---|---|
| ОШИБКА-83282 | HBASE-13376, HBASE-14473, HBASE-15210, HBASE-15515, HBASE-16570, HBASE-16810, HBASE-18164 | Быстрое вычисление местоположения в балансировщике |
| ОШИБКА-91300 | HBASE-17387 | Уменьшите издержки отчета об исключениях в RegionActionResult для multi. |
| ОШИБКА-91804 | TEZ-1526 | LoadingCache для TezTaskID замедляется для больших заданий |
| ОШИБКА-92760 | ACCUMULO-4578 | Отмена операции FATE для сжатия не приводит к снятию блокировки пространства имен |
| ОШИБКА-93577 | RANGER-1938 | Solr для настройки аудита неэффективно использует значения DocValues |
| ОШИБКА-93910 | HIVE-18293 | Hive не может сжимать таблицы, содержащиеся в папке, которая не принадлежит пользователю, запускающему HiveMetaStore. |
| ОШИБКА-94345 | HIVE-18429 | Сжатие должно обрабатывать случай, когда оно не производит выходных данных. |
| ОШИБКА-94381 | HADOOP-13227, HDFS-13054 | Обработка последовательности действий RequestHedgingProxyProvider: FAIL < RETRY < FAILOVER_AND_RETRY. |
| ОШИБКА-94432 | HIVE-18353 | CompactorMR должен вызвать метод jobclient.close() для активации очистки |
| ОШИБКА-94869 | PHOENIX-4290, PHOENIX-4373 | Запрошенная строка вне диапазона для команды HRegion на локальной индексированной засоленной таблице Phoenix. |
| ОШИБКА-94928 | HDFS-11078 | Исправьте NPE в LazyPersistFileScrubber |
| ОШИБКА-94964 | HIVE-18269, HIVE-18318, HIVE-18326 | Несколько исправлений для LLAP |
| ОШИБКА-95669 | HIVE-18577, HIVE-18643 | При выполнении запроса обновления или удаления в секционированной таблице ACID, HS2 считывает все разделы целиком. |
| ОШИБКА-96390 | HDFS-10453 | Поток ReplicationMonitor может зависнуть на продолжительное время из-за состязания между репликацией и удалением одного и того же файла в большом кластере. |
| ОШИБКА-96625 | HIVE-16110 | Отмена изменения "Векторизация: включение поддержки CASE WHEN с двумя значениями вместо возврата к VectorUDFAdaptor" |
| ОШИБКА-97109 | HIVE-16757 | Использование устаревшего метода getRows() вместо нового estimateRowCount(RelMetadataQuery...) оказывает серьезное влияние на производительность |
| ОШИБКА-97110 | PHOENIX-3789 | Осуществите вызовы обслуживания кросс-регионального индекса в postBatchMutateIndispensably |
| ОШИБКА-98833 | YARN-6797 | TimelineWriter не полностью использует ответ POST |
| ОШИБКА-98931 | ATLAS-2491 | Обновите обработчик Hive для использования уведомлений Atlas v2 |
Потенциальная потеря данных
| Идентификатор ошибки | Apache JIRA | Сводка |
|---|---|---|
| ОШИБКА-95613 | HBASE-18808 | Неэффективная проверка конфигурации в BackupLogCleaner#getDeletableFiles() |
| ОШИБКА-97051 | HIVE-17403 | Ошибка конкатенации для неуправляемых и транзакционных таблиц |
| ОШИБКА-97787 | HIVE-18460 | Компактор не передает свойства таблицы записывающему модулю ORC |
| ОШИБКА-97788 | HIVE-18613 | Расширьте JsonSerDe для поддержки типа BINARY |
Сбой запроса
| Идентификатор ошибки | Apache JIRA | Сводка |
|---|---|---|
| ОШИБКА-100180 | CALCITE-2232 | Ошибка утверждения в AggregatePullUpConstantsRule при настройке агрегированных индексов |
| ОШИБКА-100422 | HIVE-19085 | FastHiveDecimal abs(0) устанавливает знак +ve |
| ОШИБКА-100834 | PHOENIX-4658 | IllegalStateException: requestSeek не может вызываться в ReversedKeyValueHeap |
| ОШИБКА-102078 | HIVE-17978 | Запросы TPCDS 58 и 83 создают исключения в векторизации |
| ОШИБКА-92483 | HIVE-17900 | Анализ статистики по столбцам, сгенерированной уплотнителем, приводит к некорректному SQL с 1 столбцом раздела. |
| ОШИБКА-93135 | HIVE-15874, HIVE-18189 | Запрос Hive возвращает неправильные результаты, если для псевдонима hive.groupby.orderby.position.alias установлено значение true |
| ОШИБКА-93136 | HIVE-18189 | Порядок по позиции не работает при cbo отключении |
| ОШИБКА-93595 | HIVE-12378, HIVE-15883 | Сопоставленная таблица HBase в Hive INSERT не подходит для десятичных и двоичных столбцов |
| ОШИБКА-94007 | PHOENIX-1751, PHOENIX-3112 | Запросы Phoenix возвращают значения NULL из-за частичных строк HBase |
| ОШИБКА-94144 | HIVE-17063 | Операция вставки с перезаписью раздела в внешнюю таблицу завершается ошибкой, если сначала удалить раздел. |
| ОШИБКА-94280 | HIVE-12785 | Использование типа объединения и определяемой пользователем функции для `преобразования` структуры не работает |
| ОШИБКА-94505 | PHOENIX-4525 | Переполнение целочисленного значения в процессе выполнения GroupBy |
| ОШИБКА-95618 | HIVE-18506 | Формат LlapBaseInputFormat — отрицательный индекс массива |
| ОШИБКА-95644 | HIVE-9152 | Формат CombineHiveInputFormat: выполнение запроса Hive в Tez завершается с исключением java.lang.IllegalArgumentException |
| ОШИБКА-96762 | PHOENIX-45888 | Клонируйте выражение, если его дочерние элементы имеют Determinism.PER_INVOCATION |
| ОШИБКА-97145 | HIVE-12245, HIVE-17829 | Поддержка комментариев к столбцам для таблицы на основе HBase |
| ОШИБКА-97741 | HIVE-18944 | Позиция группирования наборов задана неправильно во время выполнения DPP |
| ОШИБКА-98082 | HIVE-18597 | LLAP: всегда упаковывал log4j2 JAR-файл API для org.apache.log4j |
| ОШИБКА-99849 | Н/П | При создании таблицы из файла мастер попытается использовать базу данных по умолчанию |
Безопасность
| Идентификатор ошибки | Apache JIRA | Сводка |
|---|---|---|
| ОШИБКА-100436 | RANGER-2060 |
Knox прокси-сервер knox-sso не работает для ranger |
| ОШИБКА-101038 | SPARK-24062 | Ошибка интерпретатора %Spark Zeppelin "В подключении отказано". Ошибка в HiveThriftServer "Необходимо указать секретный ключ..." |
| ОШИБКА-101359 | ACCUMULO-4056 | Обновите общедоступную коллекцию до версии 3.2.2 при выпуске |
| ОШИБКА-54240 | HIVE-18879 | Запретите использование элемента embedded в UDFXPathUtil, если xercesImpl.jar находится в classpath. |
| ОШИБКА-79059 | OOZIE-3109 | Избегайте HTML-специфичных символов при потоковой передаче логов |
| ОШИБКА-90041 | OOZIE-2723 | Лицензией JSON.org теперь является CatX |
| ОШИБКА-93754 | RANGER-1943 | Авторизация Ranger Solr пропускается, если коллекция пуста или содержит значение NULL |
| ОШИБКА-93804 | HIVE-17419 | При выполнении команды ANALYZE TABLE...COMPUTE STATISTICS FOR COLUMNS отображается вычисленная статистика для маскированных таблиц |
| ОШИБКА-94276 | ZEPPELIN-3129 | Пользовательский интерфейс Zeppelin не выходит из Internet Explorer |
| ОШИБКА-95349 | ZOOKEEPER-1256, ZOOKEEPER-1901 | Обновите netty |
| ОШИБКА-95483 | Н/П | Исправление для CVE-2017-15713 |
| ОШИБКА-95646 | OOZIE-3167 | Обновите версию Tomcat на ветке Oozie 4.3 |
| ОШИБКА-95823 | Н/П |
Knox:Модернизировать Beanutils |
| ОШИБКА-95908 | RANGER-1960 | Авторизация в HBase не принимает во внимание пространство имен таблицы при удалении снимка состояния. |
| ОШИБКА-96191 | FALCON-2322,FALCON-2323 | Обновите версии Jackson и Spring во избежание возникновения уязвимостей системы безопасности |
| ОШИБКА-96502 | RANGER-1990 | Добавьте поддержку MySQL с использованием односторонней SSL в Ranger Admin |
| ОШИБКА-96712 | FLUME-3194 | Обновите Derby до последней версии (1.14.1.0) |
| ОШИБКА-96713 | FLUME-2678 | Обновите Xalan до версии 2.7.2 во избежание возникновения уязвимостей CVE-2014-0107 |
| ОШИБКА-96714 | FLUME-2050 | Обновление до log4j2 (когда общедоступная версия) |
| ОШИБКА-96737 | Н/П | Используйте методы файловой системы ввода-вывода Java для доступа к локальным файлам |
| ОШИБКА-96925 | Н/П | Обновите в Hadoop Tomcat с версии 6.0.48 до 6.0.53 |
| ОШИБКА-96977 | FLUME-3132 | Обновление зависимостей библиотеки tomcat jasper |
| ОШИБКА-97022 | HADOOP-14799,HADOOP-14903, HADOOP-15265 | Обновление библиотеки Nimbus-JOSE-JWT с версией выше 4.39 |
| ОШИБКА-97101 | RANGER-19888 | Исправьте небезопасную генерацию случайных чисел |
| ОШИБКА-97178 | ATLAS-2467 | Обновление зависимости для Spring и Nimbus-JOSE-JWT |
| ОШИБКА-97180 | Н/П | Обновите Nimbus-JOSE-JWT |
| ОШИБКА-98038 | HIVE-187888 | Очистите входные данные в JDBC PreparedStatement. |
| ОШИБКА-98353 | HADOOP-13707 | Вернуться к параметру "Если kerberos включен, пока http SPNEGO не настроено, некоторые ссылки не могут быть доступны". |
| ОШИБКА-98372 | HBASE-13848 | Получите доступ к паролям SSL InfoServer с помощью API поставщика учетных данных |
| ОШИБКА-98385 | ATLAS-2500 | Добавьте больше заголовков в ответ Atlas. |
| ОШИБКА-98564 | HADOOP-14651 | Обновите OkHttp до версии 2.7.5 |
| ОШИБКА-99440 | RANGER-2045 | При выполнении команды 'desc table' будут перечислены столбцы таблицы Hive без явной политики разрешения доступа. |
| ОШИБКА-99803 | Н/П | Oozie должен отключить загрузку динамического класса HBase |
Стабильность
| Идентификатор ошибки | Apache JIRA | Сводка |
|---|---|---|
| ОШИБКА-100040 | ATLAS-2536 | NPE в хуке Atlas Hive |
| ОШИБКА-100057 | HIVE-19251 | ObjectStore.getNextNotification с использованием LIMIT должно использовать меньше памяти |
| ОШИБКА-100072 | HIVE-19130 | NPE вызывается при применении события удаления раздела REPL LOAD. |
| ОШИБКА-100073 | Н/П | слишком много подключений close_wait от hiveserver к узлу данных |
| ОШИБКА-100319 | HIVE-19248 | REPL LOAD не вызывает ошибку при сбое копирования файла |
| ОШИБКА-100352 | Н/П | CLONE — логика удаления RM слишком часто сканирует znode реестра |
| ОШИБКА-100427 | HIVE-19249 | Репликация: предложение WITH не во всех случаях корректно передает конфигурацию в Task. |
| ОШИБКА-100430 | HIVE-14483 | java.lang.ArrayIndexOutOfBoundsException org.apache.orc.impl.TreeReaderFactory$BytesColumnVectorUtil.commonReadByteArrays |
| ОШИБКА-100432 | HIVE-19219 | Инкрементный REPL DUMP должен возвращать ошибку, если запрашиваемые события были удалены. |
| ОШИБКА-100448 | SPARK-23637, SPARK-23802, SPARK-23809, SPARK-23816, SPARK-23822,SPARK-23823,SPARK-23838, SPARK-23881 | Обновление Spark2 до версии 2.3.0+ (4/11) |
| ОШИБКА-100740 | HIVE-16107 | JDBC: HttpClient должен повторить попытку при возникновении NoHttpResponseException |
| ОШИБКА-100810 | HIVE-19054 | Сбой репликации функций Hive |
| ОШИБКА-100937 | MAPREDUCE-6889 | Добавьте API-интерфейс Job#close, чтобы завершить работу клиентских служб MR. |
| ОШИБКА-101065 | ATLAS-2587 | Настройте ACL для чтения на znode /apache_atlas/active_server_info в системе высокой доступности (HA), чтобы прокси-сервер мог его читать. |
| ОШИБКА-101093 | STORM-2993 | В Storm компонент HDFS Bolt вызывает исключение ClosedChannelException при использовании политики ротации времени. |
| ОШИБКА-101181 | Н/П | Обработчик PhoenixStorageHandler неправильно обрабатывает оператор AND в предикате |
| ОШИБКА-101266 | PHOENIX-4635 | Утечка подключения HBase в формате org.apache.phoenix.hive.mapreduce.PhoenixInputFormat |
| ОШИБКА-101458 | HIVE-11464 | Информация о происхождении отсутствует, если есть несколько выходных данных. |
| ОШИБКА-101485 | Н/П | Thrift API хранилища метаданных Hive работает медленно и вызывает тайм-аут клиента |
| ОШИБКА-101628 | HIVE-19331 | Не удалось выполнить добавочную репликацию Hive в облако |
| ОШИБКА-102048 | HIVE-19381 | FunctionTask: сбой репликации функции Hive в облако |
| ОШИБКА-102064 | Н/П | Тесты репликации \[ onprem to onprem \] Hive завершились сбоем в ReplCopyTask. |
| ОШИБКА-102137 | HIVE-19423 | Тесты репликации \[ Onprem to Cloud \] Hive завершились сбоем в ReplCopyTask. |
| ОШИБКА-102305 | HIVE-19430 | Дампы нехватки памяти хранилища метаданных Hive и HS2 |
| ОШИБКА-102361 | Н/П | Результаты нескольких вставок объединяются в одну вставку, реплицируемую в целевой кластер Hive (onprem - s3) |
| ОШИБКА-87624 | Н/П | Включение ведения журнала событий Storm постоянно выводит из строя рабочие роли |
| ОШИБКА-88929 | HBASE-15615 | Неправильное время перехода в спящий режим при необходимости повторной попытки RegionServerCallable |
| ОШИБКА-89628 | HIVE-17613 | Удалите пулы объектов для краткосрочных выделений в одном потоке |
| ОШИБКА-89813 | Н/П | SCA: Правильность кода: несинхронизированный метод переопределяет синхронизированный метод |
| ОШИБКА-90437 | ZEPPELIN-3072 | Пользовательский интерфейс Zeppelin медленно работает или не отвечает при большом количестве записных книжек |
| ОШИБКА-90640 | HBASE-19065 | Метод HRegion#bulkLoadHFiles() должен ожидать завершения параллельного метода Region#flush() |
| ОШИБКА-91202 | HIVE-17013 | Удаление запроса с использованием подзапроса на основе команды SELECT в представлении |
| ОШИБКА-91350 | KNOX-1108 | Функция переключения отказа NiFiHaDispatch не срабатывает |
| ОШИБКА-92054 | HIVE-13120 | При генерации разделов ORC применяйте doAs |
| ОШИБКА-92373 | FALCON-2314 | Обновите TestNG до версии 6.13.1, чтобы вовсе избежать зависимости от BeanShell. |
| ОШИБКА-92381 | Н/П | Не проходят модульные тесты testContainerLogsWithNewAPI и testContainerLogsWithOldAPI |
| ОШИБКА-92389 | STORM-2841 | Сбой модульного теста testNoAcksIfFlushFails с исключением NullPointerException |
| ОШИБКА-92586 | SPARK-17920, SPARK-20694, SPARK-21642, SPARK-22162, SPARK-22289, SPARK-22373, SPARK-22495, SPARK-22574, SPARK-22591, SPARK-22595, SPARK-22601, SPARK-22603, SPARK-22607, SPARK-22635, SPARK-22637, SPARK-22653, SPARK-22654, SPARK-22686, SPARK-22688, SPARK-22817, SPARK-22862, SPARK-22889, SPARK-22972, SPARK-22975, SPARK-22982, SPARK-22983, SPARK-22984, SPARK-23001, SPARK-23038, SPARK-23095 | Обновление Spark2 до версии 2.2.1 (январь 16) |
| ОШИБКА-92680 | ATLAS-2288 | Исключение NoClassDefFoundError при выполнении скрипта импорта Hive при создании таблицы HBase через Hive |
| ОШИБКА-92760 | ACCUMULO-4578 | Отмена операции FATE для сжатия не приводит к снятию блокировки пространства имен |
| ОШИБКА-92797 | HDFS-10267, HDFS-8496 | Снижение конфликтов блокировки дата-узла в определенных сценариях использования. |
| ОШИБКА-92813 | FLUME-2973 | Взаимоблокировка в приемнике HDFS |
| ОШИБКА-92957 | HIVE-11266 | Неправильный результат count(*) на основе статистики внешних таблиц |
| ОШИБКА-93018 | ATLAS-2310 | В режиме HA пассивный узел перенаправляет запрос с неправильной кодировкой URL. |
| ОШИБКА-93116 | RANGER-1957 | Синхронизация пользователей Ranger не выполняет периодическую синхронизацию пользователей или групп при включенной инкрементальной синхронизации. |
| ОШИБКА-93361 | HIVE-12360 | Некорректный поиск в ORC без сжатия с включением предиката |
| ОШИБКА-93426 | CALCITE-2086 | HTTP/413 в некоторых случаях из-за больших заголовков авторизации |
| ОШИБКА-93429 | PHOENIX-3240 | Исключение ClassCastException из загрузчика Pig |
| ОШИБКА-93485 | Н/П | не удалось получить таблицу mytestorg.apache.hadoop.hive.ql.metadata.InvalidTableException: таблица не найдена при выполнении команды анализа таблицы по столбцам в LLAP |
| ОШИБКА-93512 | PHOENIX-4466 | Исключение java.lang.RuntimeException — код отклика 500 — выполнение задания Spark для подключения к серверу запросов Phoenix и загрузки данных |
| ОШИБКА-93550 | Н/П | Zeppelin %spark.r не работает со spark1 из-за несоответствия версии Scala |
| ОШИБКА-93910 | HIVE-18293 | Hive не может сжимать таблицы, содержащиеся в папке, которая не принадлежит пользователю, запускающему HiveMetaStore. |
| ОШИБКА-93926 | ZEPPELIN-3114 | Записные книжки и интерпретаторы не сохраняются в Zeppelin после нагрузочного теста, выполнявшегося более одного дня |
| ОШИБКА-93932 | ATLAS-2320 | Классификация "*" с запросом вызывает исключение внутреннего сервера 500 |
| ОШИБКА-93948 | YARN-7697 | NM выходит из строя с OOM из-за утечки в объединении журналов (часть №1) |
| ОШИБКА-93965 | ATLAS-2229 | Поиск DSL: нестроковой атрибут "orderby" вызывает исключение. |
| ОШИБКА-93986 | YARN-7697 | NM выходит из строя из-за переполнения памяти (OOM) из-за утечки в агрегации журналов (часть №2) |
| ОШИБКА-94030 | ATLAS-2332 | Сбой создания типа с атрибутами с вложенным типом данных коллекции |
| ОШИБКА-94080 | YARN-3742, YARN-6061 | Оба RM находятся в режиме ожидания в защищенном кластере |
| ОШИБКА-94081 | HIVE-18384 | ConcurrentModificationException в log4j2.x библиотеке |
| ОШИБКА-94168 | Н/П | Yarn RM выходит из строя, когда реестр службы находится в ошибочном состоянии: ОШИБКА |
| ОШИБКА-94330 | HADOOP-13190, HADOOP-14104, HADOOP-14814, HDFS-10489, HDFS-11689 | HDFS должен поддерживать несколько KMS Uris |
| ОШИБКА-94345 | HIVE-18429 | Сжатие должно обрабатывать случай, когда оно не производит выходных данных. |
| ОШИБКА-94372 | ATLAS-2229 | Запрос DSL: hive_table name = ["t1","t2"] вызывает исключение недействительного DSL-запроса |
| ОШИБКА-94381 | HADOOP-13227, HDFS-13054 | Обработка последовательности действий RequestHedgingProxyProvider: FAIL < RETRY < FAILOVER_AND_RETRY. |
| ОШИБКА-94432 | HIVE-18353 | CompactorMR должен вызвать метод jobclient.close() для активации очистки |
| ОШИБКА-94575 | SPARK-22587 | Задание Spark завершается сбоем, если URL-адреса fs.defaultFS и JAR-файла приложения не совпадают. |
| ОШИБКА-94791 | SPARK-22793 | Утечка памяти на сервере Thrift Spark |
| ОШИБКА-94928 | HDFS-11078 | Исправьте NPE в LazyPersistFileScrubber |
| ОШИБКА-95013 | HIVE-18488 | У считывателей LLAP ORC отсутствуют некоторые проверки на NULL значения. |
| ОШИБКА-95077 | HIVE-14205 | Hive не поддерживает тип объединения с файлом формата AVRO |
| ОШИБКА-95200 | HDFS-13061 | SaslDataTransferClient#checkTrustAndSend не должен доверять частично доверенному каналу |
| ОШИБКА-95201 | HDFS-13060 | Добавление BlacklistBasedTrustedChannelResolver для TrustedChannelResolver |
| ОШИБКА-95284 | HBASE-19395 | [branch-1] TestEndToEndSplitTransaction.testMasterOpsWhileSplitting завершается с ошибкой из-за NPE |
| ОШИБКА-95301 | HIVE-18517 | Векторизация — исправьте VectorMapOperator для приема VRB и проверьте правильное расположение векторизованного флага для поддержки кэширования LLAP |
| ОШИБКА-95542 | HBASE-16135 | PeerClusterZnode в структуре rs удаленного однорангового узла может никогда не удалиться. |
| ОШИБКА-95595 | HIVE-15563 | Игнорируйте исключение при переходе состояния незаконной операции в запросе SQLOperation.runQuery, чтобы выявить реальное исключение. |
| ОШИБКА-95596 | YARN-4126, YARN-5750 | Сбой TestClientRMService |
| ОШИБКА-96019 | HIVE-18548 | Исправление log4j импорта |
| ОШИБКА-96196 | HDFS-13120 | Инструмент сравнения моментального снимка мог быть поврежден после объединения |
| ОШИБКА-96289 | HDFS-11701 | NPE с неразрешенного узла вызывает постоянные сбои DFSInputStream |
| ОШИБКА-96291 | STORM-2652 | Исключение, возникшее в методе open JmsSpout |
| ОШИБКА-96363 | HIVE-18959 | Не следует создавать дополнительный пул потоков в LLAP |
| ОШИБКА-96390 | HDFS-10453 | Поток ReplicationMonitor мог зависнуть на длительное время из-за гонки между репликацией и удалением одного и того же файла в большом кластере |
| ОШИБКА-96454 | YARN-4593 | Взаимоблокировка в методе AbstractService.getConfig() |
| ОШИБКА-96704 | FALCON-2322 | Исключение ClassCastException при использовании submitAndSchedule для потока данных |
| ОШИБКА-96720 | SLIDER-1262 | Сбой функциональных тестов слайдера в Kerberized среде. |
| ОШИБКА-96931 | SPARK 23053, SPARK 23186, SPARK 23230, SPARK 23358, SPARK 23376, SPARK 23391 | Обновление Spark2 до текущей версии (19 февраля) |
| ОШИБКА-97067 | HIVE-10697 | ObjectInspectorConvertors#UnionConvertor выполняет ошибочное преобразование |
| ОШИБКА-97244 | KNOX-1083 | Время ожидания по умолчанию HttpClient должно представлять собой допустимое значение |
| ОШИБКА-97459 | ZEPPELIN-3271 | Опция отключения планировщика |
| ОШИБКА-97511 | KNOX-1197 | В службе фильтр AnonymousAuthFilter не добавляется, если authentication=Anonymous |
| ОШИБКА-97601 | HIVE-17479 | Промежуточные каталоги не очищаются после выполнения запросов на обновление или удаление. |
| ОШИБКА-97605 | HIVE-18858 | Свойства системы в конфигурации задания не разрешились при отправке задания MR (MapReduce) |
| ОШИБКА-97674 | OOZIE-3186 | Oozie не может использовать конфигурацию, связанную с помощью jceks://file/... |
| ОШИБКА-97743 | Н/П | Исключение java.lang.NoClassDefFoundError при развертывании топологии Storm |
| ОШИБКА-97756 | PHOENIX-4576 | Исправить сбои в тестах LocalIndexSplitMergeIT |
| ОШИБКА-97771 | HDFS-11711 | DN не должен удалять блок при исключении "Слишком много открытых файлов" |
| ОШИБКА-97869 | KNOX-1190 |
Knox Поддержка единого входа для Google OIDC не работает. |
| ОШИБКА-97879 | PHOENIX-4489 | Утечка соединений HBase в заданиях Phoenix MapReduce |
| ОШИБКА-98392 | RANGER-2007 | Сбой обновления билета Kerberos в ranger-tagsync. |
| ОШИБКА-98484 | Н/П | Инкрементная репликация Hive в облако не работает |
| ОШИБКА-98533 | HBASE-19934, HBASE-20008 | Сбой восстановления моментального снимка HBase из-за ошибки с пустым указателем |
| ОШИБКА-98555 | PHOENIX-4662 | Исключение NullPointerException в TableResultIterator.java при повторной отправке кэша |
| ОШИБКА-98579 | HBASE-13716 | Прекратите использовать константы FSConstants Hadoop |
| ОШИБКА-98705 | KNOX-1230 | Многочисленные одновременные запросы к Knox приводят к искажению URL-адреса. |
| ОШИБКА-98983 | KNOX-1108 | Функция переключения отказа NiFiHaDispatch не срабатывает |
| ОШИБКА-99107 | HIVE-19054 | Репликация функции будет использовать "hive.repl.replica.functions.root.dir" как корневой каталог. |
| ОШИБКА-99145 | RANGER-2035 | Ошибки доступа к servicedefs с пустым классом implClass с серверной частью Oracle |
| ОШИБКА-99160 | SLIDER-1259 | Слайдер не работает в многоадресных средах |
| ОШИБКА-99239 | ATLAS-2462 | Импорт Sqoop для всех таблиц вызывает NPE без таблицы, указанной в команде |
| ОШИБКА-99301 | ATLAS-2530 | Новая строка в начале атрибута имени для элементов hive_process и hive_column_lineage |
| ОШИБКА-99453 | HIVE-19065 | Проверка совместимости клиента хранилища метаданных должна включать функцию syncMetaStoreClient |
| ОШИБКА-99521 | Н/П | Кэш сервера для HashJoin не пересоздается при повторном создании экземпляров итераторов. |
| ОШИБКА-99590 | PHOENIX-3518 | Утечка памяти в RenewLeaseTask |
| ОШИБКА-99618 | SPARK-23599, SPARK-23806 | Обновление Spark2 до версии 2.3.0+ (3/28) |
| ОШИБКА-99672 | ATLAS-2524 | Обработчик Hive с уведомлениями V2 — неправильная обработка операции "ALTER VIEW AS" |
| ОШИБКА-99809 | HBASE-20375 | Не используйте getCurrentUserCredentials в модуле hbase-spark |
Возможности поддержки
| Идентификатор ошибки | Apache JIRA | Сводка |
|---|---|---|
| ОШИБКА-873433 | HIVE-18031 | Включите поддержку репликации для операции изменения базы данных |
| ОШИБКА-91293 | RANGER-2060 |
Knox прокси-сервер knox-sso не работает для ranger |
| ОШИБКА-93116 | RANGER-1957 | Синхронизация пользователей Ranger не выполняет периодическую синхронизацию пользователей или групп при включенной инкрементальной синхронизации. |
| ОШИБКА-93577 | RANGER-1938 | Solr для настройки аудита неэффективно использует значения DocValues |
| ОШИБКА-96082 | RANGER-1982 | Улучшение ошибок для метрики аналитики администратора Ranger и Ranger Kms |
| ОШИБКА-96479 | HDFS-12781 | После Datanode отключения, во вкладке UI NamenodeDatanode появляется предупреждающее сообщение. |
| ОШИБКА-97864 | HIVE-18833 | Сбой автоматического объединения при выполнении операции вставки в каталог как ORCfile. |
| ОШИБКА-98814 | HDFS-13314 | При обнаружении узлом NameNode повреждения FsImage нужно обязательно завершить его работу |
Обновить
| Идентификатор ошибки | Apache JIRA | Сводка |
|---|---|---|
| ОШИБКА-100134 | SPARK-22919 | Отмена обновления версий Apache httpclient |
| ОШИБКА-95823 | Н/П |
Knox:Модернизировать Beanutils |
| ОШИБКА-96751 | KNOX-1076 | Обновите nimbus-jose-jwt до версии 4.41.2 |
| ОШИБКА-97864 | HIVE-18833 | Сбой автоматического объединения при выполнении операции вставки в каталог как ORCfile. |
| ОШИБКА-99056 | HADOOP-13556 | Измените префикс Configuration.getPropsWithPrefix, чтобы вместо итератора использовать getProps |
| ОШИБКА-99378 | ATLAS-2461, ATLAS-2554 | Служебная программа переноса для экспорта данных Atlas в базе данных графа Titan |
Удобство использования
| Идентификатор ошибки | Apache JIRA | Сводка |
|---|---|---|
| ОШИБКА-100045 | HIVE-19056 | Исключение IllegalArgumentException в индексе FixAcidKeyIndex при отсутствии строк в ORC-файле |
| ОШИБКА-100139 | KNOX-1243 | Нормализация необходимых доменных имен, настроенных в KnoxToken службе |
| ОШИБКА-100570 | ATLAS-2557 | Исправление, позволяющее разрешить lookup группы hadoop ldap , если группы из UGI неправильно заданы или не пусты |
| ОШИБКА-100646 | ATLAS-2102 | Оптимизация пользовательского интерфейса Atlas: страница результатов поиска |
| ОШИБКА-100737 | HIVE-19049 | Добавьте поддержку для таблицы ALTER TABLE, чтобы добавить столбцы для Druid |
| ОШИБКА-100750 | KNOX-1246 | Обновите конфигурацию службы в Knox, чтобы поддерживать последние конфигурации для Ranger. |
| ОШИБКА-100965 | ATLAS-2581 | Регрессия с уведомлениями обработчика Hive V2: перемещение таблицы в другую базу данных |
| ОШИБКА-84413 | ATLAS-1964 | Пользовательский интерфейс: поддержка упорядочивания столбцов в таблице поиска |
| ОШИБКА-90570 | HDFS-11384, HDFS-12347 | Добавьте параметр для балансировщика для распределения вызовов getBlocks, чтобы избежать всплеска длины очереди вызовов rpc.CallQueueLength у NameNode. |
| ОШИБКА-90584 | HBASE-19052 | FixedFileTrailer должен распознавать класс CellComparatorImpl в ветви branch-1.x |
| ОШИБКА-90979 | KNOX-1224 |
Knox Прокси HADispatcher для поддержки Atlas в HA. |
| ОШИБКА-91293 | RANGER-2060 |
Knox прокси-сервер с Knox-SSO не работает для Ranger |
| ОШИБКА-92236 | ATLAS-2281 | Сохранение запросов фильтра атрибутов тегов и типов с фильтрами NULL и без поддержки NULL |
| ОШИБКА-92238 | ATLAS-2282 | Сохраненный избранный поиск появляется только при обновлении после создания, когда есть более 25 избранных поисков |
| ОШИБКА-923333 | ATLAS-2286 | Предварительно созданный тип kafka_topic не должен объявлять атрибут "тема" как уникальный |
| ОШИБКА-92678 | ATLAS-2276 | Значение пути для сущности типа hdfs_path задано в нижнем регистре в hive-bridge |
| ОШИБКА-93097 | RANGER-1944 | Не работает фильтр действий для аудита администратора |
| ОШИБКА-93135 | HIVE-15874, HIVE-18189 | Запрос Hive возвращает неправильные результаты, если для псевдонима hive.groupby.orderby.position.alias установлено значение true |
| ОШИБКА-93136 | HIVE-18189 | Порядок по позиции не работает при cbo отключении |
| ОШИБКА-93387 | HIVE-17600 | Сделайте параметр "enforceBufferSize" ORC-файла настраиваемым пользователем. |
| ОШИБКА-93495 | RANGER-1937 | Ranger tagsync должен обрабатывать уведомление ENTITY_CREATE для поддержки функционала импорта Atlas |
| ОШИБКА-93512 | PHOENIX-4466 | Исключение java.lang.RuntimeException — код отклика 500 — выполнение задания Spark для подключения к серверу запросов Phoenix и загрузки данных |
| ОШИБКА-93801 | HBASE-19393 | Головной узел HTTP 413 во время доступа к пользовательскому интерфейсу HBase с помощью SSL |
| ОШИБКА-93804 | HIVE-17419 | При выполнении команды ANALYZE TABLE...COMPUTE STATISTICS FOR COLUMNS отображается вычисленная статистика для маскированных таблиц |
| ОШИБКА-93932 | ATLAS-2320 | Классификация "*" с запросом вызывает исключение внутреннего сервера 500 |
| ОШИБКА-93933 | ATLAS-2286 | Предварительно созданный тип kafka_topic не должен объявлять атрибут "тема" как уникальный |
| ОШИБКА-93938 | ATLAS-2283, ATLAS-2295 | Обновления пользовательского интерфейса для классификаций |
| ОШИБКА-93941 | ATLAS-2296, ATLAS-2307 | Оптимизация базового поиска, позволяющая при необходимости исключить подтипы и типы дополнительных классификаций сущностей |
| ОШИБКА-93944 | ATLAS-2318 | Пользовательский интерфейс: При двойном щелчке на дочернем теге выбирается родительский тег |
| ОШИБКА-93946 | ATLAS-2319 | Пользовательский интерфейс: для удаления тега, который находится на 25-й или ниже позиции в списке тегов в как плоской, так и древовидной структуре, необходимо обновить список. |
| ОШИБКА-93977 | HIVE-16232 | Поддержите вычисление статистики для столбца в QuotedIdentifier |
| ОШИБКА-94030 | ATLAS-2332 | Сбой создания типа с атрибутами с вложенным типом данных коллекции |
| ОШИБКА-94099 | ATLAS-2352 | Сервер Atlas должен предоставить конфигурацию для указания срока действия маркера Kerberos DelegationToken. |
| ОШИБКА-94280 | HIVE-12785 | Использование типа объединения и определяемой пользователем функции для `преобразования` структуры не работает |
| ОШИБКА-94332 | SQOOP-2930 | Выполнение команды Sqoop не переопределяет общие свойства сохраненного задания |
| ОШИБКА-94428 | Н/П |
Dataplane Поддержка REST API для агента профилировки Knox |
| ОШИБКА-94514 | ATLAS-2339 | Пользовательский интерфейс: изменения в столбцах в представлении результатов базового поиска также влияют на DSL. |
| ОШИБКА-94515 | ATLAS-2169 | Запрос на удаление не выполняется, когда настроено необратимое удаление. |
| ОШИБКА-94518 | ATLAS-2329 | При нажатии пользователем на другой тег в Atlas UI, что является неправильно, одновременно отображаются несколько наведений. |
| ОШИБКА-94519 | ATLAS-2272 | Сохраните состояние перетаскиваемых столбцов с помощью API сохранения поиска. |
| ОШИБКА-94627 | HIVE-17731 | добавление обратного compat параметра для внешних пользователей в HIVE-11985 |
| ОШИБКА-94786 | HIVE-6091 | Пустые pipeout файлы создаются для создания и закрытия подключения |
| ОШИБКА-94793 | HIVE-14013 | В таблице "Describe" неправильно отображается юникод |
| ОШИБКА-94900 | OOZIE-2606, OOZIE-2658, OOZIE-2787, OOZIE-2802 | Установите spark.yarn.jars, чтобы исправить Spark 2.0 с помощью Oozie |
| ОШИБКА-94901 | HBASE-19285 | Добавьте гистограммы задержки для каждой таблицы |
| ОШИБКА-94908 | ATLAS-1921 | Пользовательский интерфейс. Поиск с помощью атрибутов признака и сущности: пользовательский интерфейс не выполняет проверку диапазона и позволяет предоставлять значения вне границ для целочисленных и плавающих типов данных. |
| ОШИБКА-95086 | RANGER-1953 | Улучшение на странице списка групп пользователей |
| ОШИБКА-95193 | SLIDER-1252 | Сбой агента Slider — ошибки проверки SSL с помощью Python версии 2.7.5-58 |
| ОШИБКА-95314 | YARN-7699 | queueUsagePercentage будет поступать как INF для вызова REST API getApp. |
| ОШИБКА-95315 | HBASE-13947, HBASE-14517, HBASE-17931 | Назначьте системные таблицы серверам с самой высокой версией |
| ОШИБКА-95392 | ATLAS-2421 | Обновления уведомлений для поддержки структур данных V2 |
| ОШИБКА-95476 | RANGER-1966 | В некоторых случаях инициализация механизма политики не создает контекстных обогатителей |
| ОШИБКА-95512 | HIVE-18467 | Поддержка полного дампа/загрузки хранилища данных, а также создание/удаление событий в базе данных. |
| ОШИБКА-95593 | Н/П | Расширение возможностей Oozie DB для поддержки Spark2sharelib создания |
| ОШИБКА-95595 | HIVE-15563 | Игнорируйте исключение при переходе состояния незаконной операции в запросе SQLOperation.runQuery, чтобы выявить реальное исключение. |
| ОШИБКА-95685 | ATLAS-2422 | Экспорт: включите поддержку экспорта на основе типа |
| ОШИБКА-95798 | PHOENIX-2714, PHOENIX-2724, PHOENIX-3023, PHOENIX-3040 | Не используйте направляющие для выполнения запросов поочередно |
| ОШИБКА-95969 | HIVE-16828, HIVE-17063, HIVE-18390 | Ошибка секционированного представления с ошибкой IndexOutOfBoundsException: Индекс: 1, Размер: 1. |
| ОШИБКА-96019 | HIVE-18548 | Исправление log4j импорта |
| ОШИБКА-96288 | HBASE-14123, HBASE-14135, HBASE-17850 | Реализуйте резервное копирование и восстановление HBase версии 2.0 |
| ОШИБКА-96313 | KNOX-1119 |
Pac4J Субъект OAuth/OpenID должен быть настраиваемым |
| ОШИБКА-96365 | ATLAS-2442 | Пользователь с правами только на чтение ресурса сущности не может выполнить базовый поиск. |
| ОШИБКА-96479 | HDFS-12781 | После Datanode отключения, во вкладке UI NamenodeDatanode появляется предупреждающее сообщение. |
| ОШИБКА-96502 | RANGER-1990 | Добавьте поддержку MySQL с использованием односторонней SSL в Ranger Admin |
| ОШИБКА-96718 | ATLAS-2439 | Обновите обработчик Sqoop, чтобы использовать уведомления V2 |
| ОШИБКА-96748 | HIVE-18587 | Вставить событие DML может попытаться вычислить контрольную сумму для каталогов |
| ОШИБКА-96821 | HBASE-18212 | В автономном режиме с локальной файловой системой HBase выводится предупреждающее сообщение: не удалось вызвать метод unbuffer в классе org.apache.hadoop.fs.FSDataInputStream. |
| ОШИБКА-96847 | HIVE-18754 | Состояние REPL должно поддерживать конструкцию "with" |
| ОШИБКА-96873 | ATLAS-2443 | Запишите требуемые атрибуты сущности в исходящих сообщениях DELETE |
| ОШИБКА-96880 | SPARK-23230 | Если hive.default.fileformat — это другие типы файлов, создание textfile таблицы приводит к ошибке serde . |
| ОШИБКА-96911 | OOZIE-2571, OOZIE-2792, OOZIE-2799, OOZIE-2923 | Оптимизируйте синтаксический анализ параметров Spark |
| ОШИБКА-97100 | RANGER-1984 | Записи журнала аудита HBase могут не отображать все теги, связанные с доступом к столбцу |
| ОШИБКА-97110 | PHOENIX-3789 | Осуществите вызовы обслуживания кросс-регионального индекса в postBatchMutateIndispensably |
| ОШИБКА-97145 | HIVE-12245, HIVE-17829 | Поддержка комментариев к столбцам для таблицы на основе HBase |
| ОШИБКА-97409 | HADOOP-15255 | Поддержка преобразования нижнего и верхнего регистров для имен групп в "LdapGroupsMapping" |
| ОШИБКА-97535 | HIVE-18710 | Расширьте inheritPerms для ACID в Hive 2.X |
| ОШИБКА-97742 | OOZIE-1624 | Шаблон исключения для sharelib JAR-файлов |
| ОШИБКА-97744 | PHOENIX-3994 | Приоритет RPC индекса по-прежнему зависит от свойства конфигурации контроллера в файле hbase-site.xml |
| ОШИБКА-97787 | HIVE-18460 | Компактор не передает свойства таблицы записывающему модулю ORC |
| ОШИБКА-97788 | HIVE-18613 | Расширьте JsonSerDe для поддержки типа BINARY |
| ОШИБКА-97899 | HIVE-18808 | Обеспечьте более надежное сжатие при сбое обновления статистических данных |
| ОШИБКА-98038 | HIVE-187888 | Очистите входные данные в JDBC PreparedStatement. |
| ОШИБКА-98383 | HIVE-18907 | Создайте служебную программу, чтобы исправить проблему индекса ключа ACID в HIVE-18817 |
| ОШИБКА-98388 | RANGER-1828 | Оптимальной процедурой кодирования является добавление дополнительных заголовков в Ranger |
| ОШИБКА-98392 | RANGER-2007 | Сбой обновления билета Kerberos в ranger-tagsync. |
| ОШИБКА-98533 | HBASE-19934, HBASE-20008 | Сбой восстановления моментального снимка HBase из-за ошибки с пустым указателем |
| ОШИБКА-98552 | HBASE-18083, HBASE-18084 | Обеспечьте настраиваемость количества потоков очистки маленьких и больших файлов в HFileCleaner. |
| ОШИБКА-98705 | KNOX-1230 | Многочисленные одновременные запросы к Knox приводят к искажению URL-адреса. |
| ОШИБКА-98711 | Н/П | Диспетчеризация NiFi не может использовать двухсторонний SSL без модификаций файла service.xml |
| ОШИБКА-98880 | OOZIE-3199 | Предоставьте возможность настраивать ограничение системного свойства |
| ОШИБКА-98931 | ATLAS-2491 | Обновите обработчик Hive для использования уведомлений Atlas v2 |
| ОШИБКА-98983 | KNOX-1108 | Функция переключения отказа NiFiHaDispatch не срабатывает |
| ОШИБКА-99088 | ATLAS-2511 | Предоставьте возможность выборочно импортировать базы данных и таблицы из Hive в Atlas |
| ОШИБКА-99154 | OOZIE-2844, OOZIE-2845, OOZIE-2858, OOZIE-2885 | Ошибка запроса Spark с исключением "java.io.FileNotFoundException: hive-site.xml (Permission denied)" |
| ОШИБКА-99239 | ATLAS-2462 | Импорт Sqoop для всех таблиц вызывает NPE без таблицы, указанной в команде |
| ОШИБКА-99636 | KNOX-1238 | Исправьте настройки пользовательского хранилища Truststore для шлюза |
| ОШИБКА-99650 | KNOX-1223 | Прокси-сервер Zeppelin Knox не перенаправляет /api/ticket, как ожидалось |
| ОШИБКА-99804 | OOZIE-2858 | HiveMain, ShellMain и SparkMain не должны локально перезаписывать свойства и файлы конфигурации |
| ОШИБКА-99805 | OOZIE-2885 | Запуск действий Spark не должен требовать наличия Hive в classpath |
| ОШИБКА-99806 | OOZIE-2845 | Замените код, основанный на отражении, который задает переменные в HiveConf |
| ОШИБКА-99807 | OOZIE-28444 | Повышение стабильности действий Oozie, когда log4j свойства отсутствуют или недоступны для чтения |
| RMP-9995 | AMBARI-222222 | Переключите Druid, чтобы использовать каталог /var/druid вместо каталога /apps/druid на локальном диске |
Изменение поведения
| Компонент Apache | Apache JIRA | Сводка | Сведения |
|---|---|---|---|
| Spark 2.3 | Н/Д | Изменения, описанные в заметках о выпуске Apache Spark | - Есть документ «Об устаревании» и руководство «О изменении поведения», https://spark.apache.org/releases/spark-release-2-3-0.html#deprecations — В части SQL, есть подробное руководство по миграции (переноса с версии 2.2 до 2.3), https://spark.apache.org/docs/latest/sql-programming-guide.html#upgrading-from-spark-sql-22-to-23| |
| Спарк | HIVE-12505 | Задание Spark успешно завершено, но возникла ошибка из-за заполненной квоты диска HDFS. |
Сценарий: выполнение команды insert overwrite, когда в папке "Корзина" пользователя, запустившего команду, задана квота. Прежнее поведение: задание выполняется успешно, даже если не удается переместить данные в корзину. Результат может ошибочно содержать некоторые данные, ранее представленные в таблице. Новое поведение: при сбое перемещения в папку "Корзина" файлы навсегда удаляются. |
| Kafka 1.0 | Н/Д | Изменения, описанные в заметках о выпуске Apache Spark | https://kafka.apache.org/10/documentation.html#upgrade_100_notable |
| Hive/Ranger | Другие политики Ranger Hive, необходимые для выполнения команды INSERT OVERWRITE |
Сценарий: другие политики Ranger Hive, необходимые для выполнения команды INSERT OVERWRITE Прежнее поведение: запросы INSERT OVERWRITE Hive выполнялись в обычном режиме. Новое поведение: запросы INSERT OVERWRITE Hive неожиданно завершаются сбоем после обновления до HDP-2.6.x. Появляется следующая ошибка: Произошла ошибка при компилировании инструкции: ошибка: HiveAccessControlException: отказано в разрешении; пользователь jdoe не имеет привилегии WRITE в каталоге /tmp/*(state=42000,code=40000) Начиная с HDP версии 2.6.0, запросам INSERT OVERWRITE Hive требуется, чтобы политика URI Ranger позволяла выполнять операции записи, даже если у пользователя есть привилегия на запись, предоставленная с помощью политики HDFS. Возможное решение или ожидаемое действие пользователя: 1. Создайте новую политику в репозитории Hive. 2. В раскрывающемся списке, где указана база данных, выберите URI. 3. Обновите путь (например: /tmp/*). 4. Добавьте пользователей и группу. Сохраните изменения. 5. Повторно выполните запрос вставки. |
|
| HDFS | Н/Д | HDFS должен поддерживать несколько KMS Uris |
Прежнее поведение: свойство dfs.encryption.key.provider.uri использовалось для настройки пути поставщика сервера управления ключами. Новое поведение: dfs.encryption.key.provider.uri теперь устарел. Для настройки пути поставщика сервера ключей (KMS) сейчас используется hadoop.security.key.provider.path. |
| Цеппелин | ZEPPELIN-3271 | Опция отключения планировщика |
Затронутый компонент: Zeppelin-Server Прежнее поведение: в предыдущих выпусках Zeppelin не было возможности отключить планировщик. Новое поведение. По умолчанию пользователи больше не увидят планировщика, так как он отключен по умолчанию. Возможное решение или ожидаемое действие пользователя: Чтобы включить планировщик, вам нужно будет добавить параметр azeppelin.notebook.cron.enable со значением true в разделе настройки пользовательского сайта Zeppelin в Ambari. |
Известные проблемы
Интеграция HDInsight с ADLS 2-го поколения. Существует две проблемы в кластерах ESP HDInsight, использующих Azure Data Lake Storage 2-го поколения с каталогами и разрешениями пользователей:
Домашние каталоги для пользователей не создаются на головном узле 1. В качестве обходного решения создайте каталоги вручную и измените владельца на имя участника-пользователя (UPN) соответствующего пользователя.
Сейчас в качестве разрешений для каталога /hdp не задано значение 751. Необходимо установить
chmod 751 /hdp chmod –R 755 /hdp/apps
Spark 2.3
[SPARK-23523][SQL] Неверный результат, вызванный правилом OptimizeMetadataOnlyQuery
[SPARK-23406] Ошибки в самосоединениях между потоками
Примеры записных книжек Spark недоступны, если Azure Data Lake Storage (поколение 2) является хранилищем кластера по умолчанию.
Пакет безопасности корпоративного уровня
- Сервер Thrift Spark не принимает подключения из клиентов ODBC.
Обходные действия:
- Когда кластер будет создан, подождите около 15 минут.
- Проверьте пользовательский интерфейс Ranger на наличие политики hivesampletable_policy.
- Перезапустите службу Spark. Теперь подключение STS должно работать.
- Сервер Thrift Spark не принимает подключения из клиентов ODBC.
Обходные действия:
Обходное решение для устранения ошибки проверки службы Ranger
RANGER-1607: обходное решение для устранения сбоя проверки службы Ranger при обновлении с предыдущих версий HDP до версии 2.6.2.
Примечание.
Только если для Ranger включен SSL.
Эта проблема возникает при попытке обновить через Ambari предыдущие версии HDP до версии 2.6.1. Ambari использует вызов curl для проверки службы Ranger в Ambari. Если Ambari использует JDK версии 1.7, вызов Curl завершится ошибкой ниже:
curl: (35) error:14077410:SSL routines:SSL23_GET_SERVER_HELLO:sslv3 alert handshake failureПричиной этой ошибки является версия Tomcat, используемая в Ranger, — Tomcat-7.0.7*. JDK-1.7 конфликтует с шифрами по умолчанию, которые содержатся в Tomcat-7.0.7*.
Вы можете устранить эту проблему двумя способами:
Обновите версию JDK в Ambari с 1.7 до 1.8 (ознакомьтесь с разделом об изменении версии JDK в справочном руководстве Ambari).
Если вы хотите продолжить работу с JDK версии 1.7:
Добавьте свойство ranger.tomcat.ciphers в раздел ranger-admin-site в конфигурации Ambari Ranger с указанным ниже значением:
SSL_RSA_WITH_RC4_128_MD5, SSL_RSA_WITH_RC4_128_SHA, TLS_RSA_WITH_AES_128_CBC_SHA, SSL_RSA_WITH_3DES_EDE_CBC_SHA
Если среда настроена для менеджера ключей Ranger, добавьте свойство ranger.tomcat.ciphers в секции ranger-kms-site в конфигурации Ambari Ranger с указанным ниже значением.
SSL_RSA_WITH_RC4_128_MD5, SSL_RSA_WITH_RC4_128_SHA, TLS_RSA_WITH_AES_128_CBC_SHA, SSL_RSA_WITH_3DES_EDE_CBC_SHA
Примечание.
Отмеченные значения являются рабочими примерами и могут не указывать на вашу среду. Проверьте, чтобы способ задания этих свойств соответствовал настройке вашей среды.
Пользовательский интерфейс Ranger: исключение текста условия политики, введенного в форму политики
Затронутый компонент: Ranger
Описание проблемы
Если пользователь хочет создать политику с настраиваемыми условиями, а выражение или текст содержит специальные знаки, тогда применение политики завершится сбоем. Перед сохранением политики в базу данных специальные знаки преобразуются в ASCII.
Специальные символы: & <> ' '
Например, после сохранения политики условие tags.attributes['type']='abc' будет преобразовано в следующее.
tags.attds[' dsds']=' cssdfs'
Чтобы увидеть условие политики с этими знаками, откройте политику в режиме редактирования.
Обходное решение
Вариант №1: создание-обновление политики через REST API Ranger
URL-адрес REST: http://<host>:6080/service/plugins/policies
Создание политики с условием:
В примере ниже будет создана политика с тегами, такими как "tags-test". Она будет назначена группе "public" с условием политики astags.attr['type']=='abc' путем выбора всех разрешений компонента Hive, например select, update, create, drop, alter, index, lock, all.
Пример:
curl -H "Content-Type: application/json" -X POST http://localhost:6080/service/plugins/policies -u admin:admin -d '{"policyType":"0","name":"P100","isEnabled":true,"isAuditEnabled":true,"description":"","resources":{"tag":{"values":["tags-test"],"isRecursive":"","isExcludes":false}},"policyItems":[{"groups":["public"],"conditions":[{"type":"accessed-after-expiry","values":[]},{"type":"tag-expression","values":["tags.attr['type']=='abc'"]}],"accesses":[{"type":"hive:select","isAllowed":true},{"type":"hive:update","isAllowed":true},{"type":"hive:create","isAllowed":true},{"type":"hive:drop","isAllowed":true},{"type":"hive:alter","isAllowed":true},{"type":"hive:index","isAllowed":true},{"type":"hive:lock","isAllowed":true},{"type":"hive:all","isAllowed":true}]}],"denyPolicyItems":[],"allowExceptions":[],"denyExceptions":[],"service":"tagdev"}'Обновите имеющуюся политику с условием:
В примере ниже политика с тегами, такими как "tag-test", будет обновлена. Она будет назначена группе "public" с условием политики astags.attr['type']=='abc' путем выбора всех разрешений компонента Hive, например select, update, create, drop, alter, index, lock, all.
URL-адрес REST: http://<host-name>:6080/service/plugins/policies/<policy-id>
Пример:
curl -H "Content-Type: application/json" -X PUT http://localhost:6080/service/plugins/policies/18 -u admin:admin -d '{"id":18,"guid":"ea78a5ed-07a5-447a-978d-e636b0490a54","isEnabled":true,"createdBy":"Admin","updatedBy":"Admin","createTime":1490802077000,"updateTime":1490802077000,"version":1,"service":"tagdev","name":"P0101","policyType":0,"description":"","resourceSignature":"e5fdb911a25aa7f77af5a9546938d9ed","isAuditEnabled":true,"resources":{"tag":{"values":["tags"],"isExcludes":false,"isRecursive":false}},"policyItems":[{"accesses":[{"type":"hive:select","isAllowed":true},{"type":"hive:update","isAllowed":true},{"type":"hive:create","isAllowed":true},{"type":"hive:drop","isAllowed":true},{"type":"hive:alter","isAllowed":true},{"type":"hive:index","isAllowed":true},{"type":"hive:lock","isAllowed":true},{"type":"hive:all","isAllowed":true}],"users":[],"groups":["public"],"conditions":[{"type":"ip-range","values":["tags.attributes['type']=abc"]}],"delegateAdmin":false}],"denyPolicyItems":[],"allowExceptions":[],"denyExceptions":[],"dataMaskPolicyItems":[],"rowFilterPolicyItems":[]}'Параметр №2: применение изменений Javascript
Чтобы обновить JS-файл, сделайте следующее:
В /usr/hdp/current/ranger-admin найдите файл PermissionList.js.
Определение функции renderPolicyCondtion (строка no: 404).
Удалите следующую строку из этой функции, т. е. под отображаемой функцией (строка no: 434)
val = _.escape(val);//Line No:460
После удаления вышеуказанной строки пользовательский интерфейс Ranger позволит вам создавать политики с условиями, которые могут содержать специальные символы, и оценка этой политики будет успешной.
Интеграция HDInsight с ADLS Gen 2: проблемы с каталогами пользователей и разрешениями в кластерах ESP 1. Домашние каталоги для пользователей не создаются на головном узле 1. Обходной путь — создать их вручную и изменить владение на соответствующий UPN пользователя. 2. Права доступа на /hdp в настоящее время не установлены на 751. Необходимо задать следующие права доступа: a. chmod 751 /hdp b. chmod –R 755 /hdp/apps
Депрекация
Портал OMS: мы удалили ссылку на страницу ресурсов HDInsight, которая указывала на портал OMS. Для журналов Azure Monitor изначально использовался собственный портал для управления конфигурацией и анализа собранных данных, известный как портал OMS. Теперь все функциональные возможности этого портала перемещены на портал Azure, где и будут совершенствоваться далее. HDInsight больше не поддерживает портал OMS. На портале Azure клиенты будут использовать интеграцию журналов Azure Monitor с HDInsight.
Spark 2.3.Устаревшие функции в выпуске Spark 2.3.0
Обновление
Все эти функции доступны в HDInsight версии 3.6. Чтобы получить последнюю версию Spark, Kafka и R Server (Службы машинного обучения), выберите версию Spark, Kafka, Службы машинного обучения при создании кластера HDInsight 3.6. Чтобы получить поддержку ADLS, как вариант можно выбрать тип хранилища ADLS. Автоматическое обновление имеющихся кластеров до этих версий не предусмотрено.
Все новые кластеры, созданные после июня 2018 года, автоматически получат больше 1000 исправлений ошибок для всех проектов с открытым кодом. Ознакомьтесь с этим руководством, чтобы узнать о передовых методах обновления до более новой версии HDInsight.