Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье описывается, как оптимизировать управление памятью кластера Apache Spark для повышения производительности в Azure HDInsight.
Обзор
Spark работает путем размещения данных в памяти. Таким образом, управление ресурсами памяти является ключевым аспектом оптимизации выполнения заданий Spark. Есть несколько методов, которые можно применить для эффективного использования памяти кластера.
- В рамках стратегии секционирования рекомендуется выбирать небольшие секции данных и учитывать размер данных, типы и распределение.
- Рассмотрим более новую, более эффективную
Kryo data serialization, а не сериализацию Java по умолчанию. - Предпочитайте использовать YARN, так как он разделяет
spark-submitпо пакетам. - Отслеживайте и настраивайте параметры конфигурации Spark.
Для справки структура памяти Spark и некоторые основные параметры памяти исполнителя показаны на рисунке ниже.
Рекомендации по использованию памяти Spark
Если вы используете Apache Hadoop YARN, yarN управляет памятью, используемой всеми контейнерами на каждом узле Spark. На схеме ниже показаны ключевые объекты и их связи.
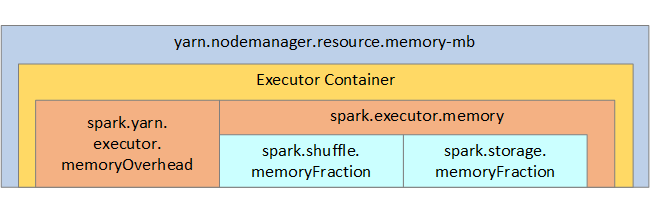
При получении сообщений о нехватке памяти сделайте следующее:
- Просмотрите изменения в управлении DAG. Уменьшите объем данных через оптимизацию на стороне сопоставления, выполните предварительное разбиение (или сегментацию) исходных данных, оптимизируйте перемешивание для минимизации количества операций и сократите передачу данных.
- Предпочитайте
ReduceByKeyс фиксированным ограничением памяти вместоGroupByKey, который предоставляет агрегирование, функции окон и другие функции, но имеет неограниченное ограничение на память. - Выберите
TreeReduce, который в основном обрабатывает исполнителей или секции, а неReduce, который в основном обрабатывает драйвер. - Используйте DataFrames, а не объекты RDD нижнего уровня.
- Создайте типы ComplexTypes, инкапсулирующие действия, такие как "Первые N", различные статистические функции или операции управления окнами.
Дополнительные инструкции по устранению неполадок см. в статье Об исключениях OutOfMemoryError для Apache Spark в Azure HDInsight.