Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ПРИМЕНИМО К: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Совет
Data Factory в Microsoft Fabric — это следующее поколение Azure Data Factory с более простой архитектурой, встроенным ИИ и новыми функциями. Если вы не знакомы с интеграцией данных, начните с Fabric Data Factory. Существующие рабочие нагрузки ADF могут обновляться до Fabric для доступа к новым возможностям в области обработки и анализа данных, аналитики в режиме реального времени и отчетов.
Обзор
Режим отладки потоков данных в Azure Data Factory и Synapse Analytics позволяет интерактивно отслеживать преобразование схемы данных во время конструирования и отладки этих потоков. Сеанс отладки можно использовать как при проектировании потоков данных, так и при выполнении отладки конвейера потоков данных. Чтобы включить режим отладки, нажмите кнопку Data Flow Debug в верхней строке холста потока данных или холста пайплайна при наличии действий потока данных.
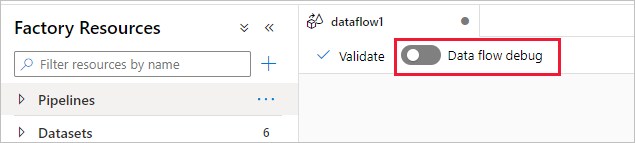

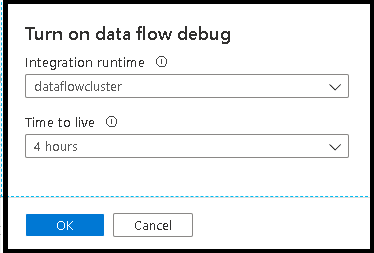
После включения ползунка вам будет предложено выбрать конфигурацию среды выполнения интеграции, которую вы хотите использовать. Если выбран параметр AutoResolveIntegrationRuntime, то появится кластер с восемью ядрами общих вычислений с 60-минутным временем существования (TTL) по умолчанию. Чтобы разрешить более продолжительное время простоя группы до окончания сеанса, можете выбрать более высокое значение параметра TTL. Дополнительные сведения о средах выполнения интеграции потока данных см. в разделе производительности средств выполнения интеграции.
Когда включен режим отладки, поток данных формируется в интерактивном режиме с помощью активного кластера Spark. Сеанс закрывается после отключения отладки. Следует помнить о почасовой оплате, которая взимается в Фабрике данных за время, когда сеанс отладки был включен.
В большинстве случаев рекомендуется создавать потоки данных в режиме отладки, чтобы можно было проверить бизнес-логику и просматривать преобразования данных перед публикацией результатов вашей работы. Используйте кнопку "Отладка" на панели конвейера для проверки потока данных в конвейере.
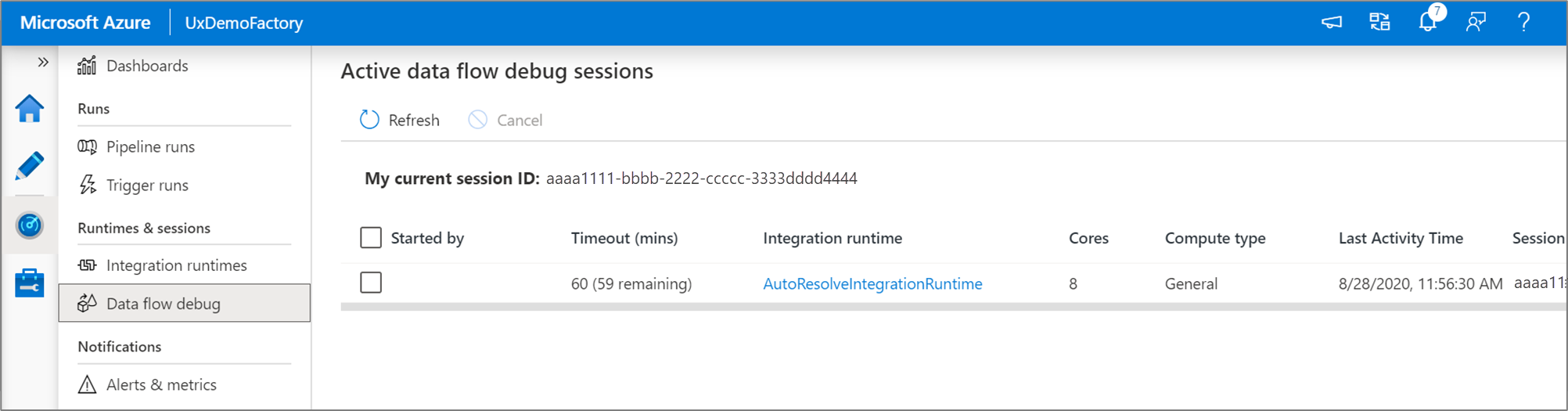
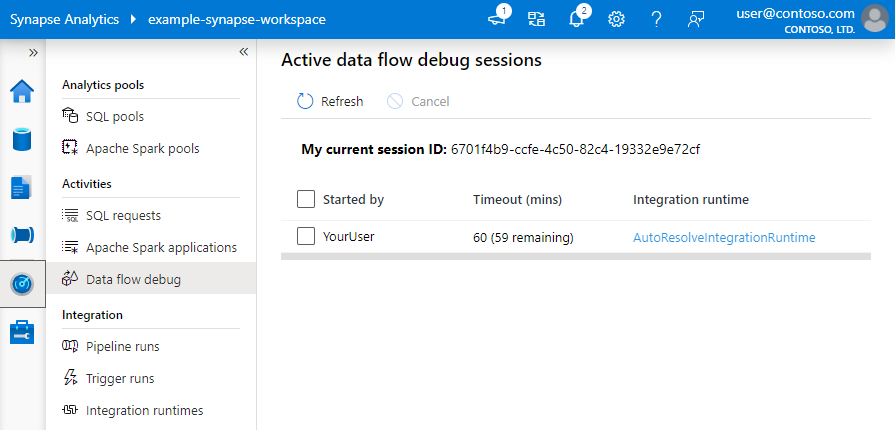
Примечание.
Каждый сеанс отладки, запускаемый пользователем из пользовательского интерфейса своего браузера, представляет собой новый сеанс с собственным кластером Spark. Вы можете использовать представление мониторинга для сеансов отладки, отображаемых на предыдущих изображениях, для просмотра сеансов отладки и управления ими. Плата взимается за каждый час выполнения каждого сеанса отладки, включая время TTL.
В этом видеоролике рассказывается о приемах, трюках и лучших методах работы в режиме отладки потока данных.
Состояние кластера
Индикатор состояния кластера в верхней части области конструктора становится зеленым, когда кластер готов к отладке. Если кластер уже теплый, зеленый индикатор отображается почти мгновенно. Если кластер еще не запущен при вводе режима отладки, кластер Spark выполняет холодную загрузку. Индикатор запускается до тех пор, пока среда не будет готова к интерактивной отладке.
Завершив отладку, отключите отладочный переключатель, чтобы кластер Spark смог завершить работу, и вы больше не будете выставлять счета за отладочное действие.
Параметры отладки
После включения режима отладки можно изменить способ предварительного просмотра данных в потоке данных. Параметры отладки можно изменить, щелкнув "Параметры отладки" на панели инструментов холста Data Flow. Вы можете выбрать предел строк или источник данных для каждого преобразования источника. Ограничения строк в этом параметре относятся только к текущему сеансу отладки. Вы также можете выбрать связанную службу подготовки данных, которая будет использоваться для источника Azure Synapse Analytics.
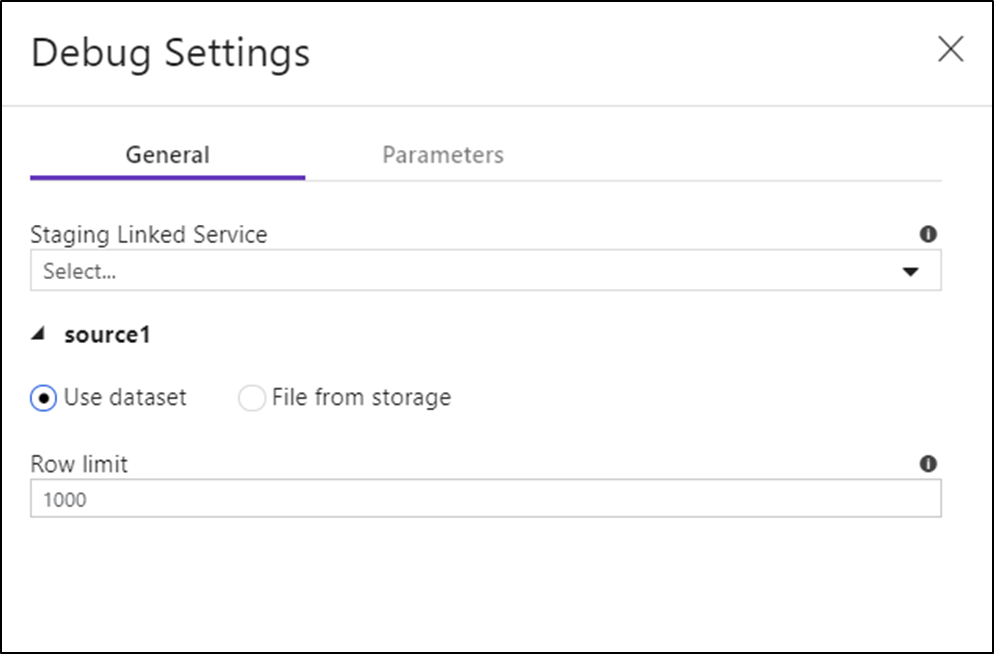
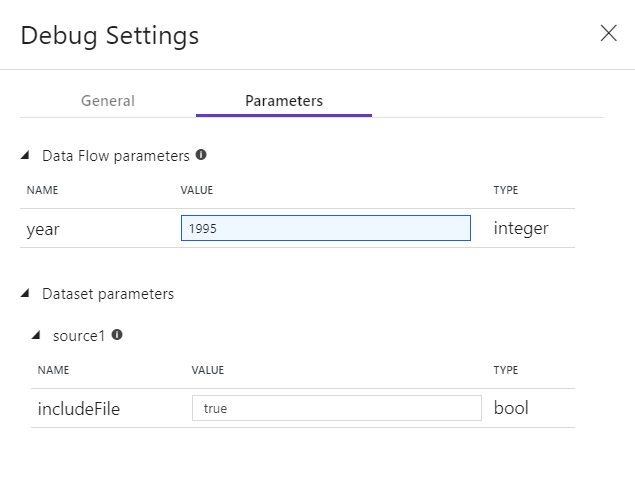
Если у вас есть параметры в Data Flow или любом из указанных наборов данных, можно указать, какие значения следует использовать во время отладки, выбрав вкладку Parameters.
Используйте параметры выборки здесь, чтобы указать на примеры файлов или примеры таблиц данных, чтобы не изменять исходные наборы данных. Используя образец файла или таблицы, можно сохранить в потоке данных те же параметры логики и свойств, что и при тестировании подмножества данных.
Среда выполнения интеграции по умолчанию, используемая для режима отладки в потоках данных, представляет собой небольшую конфигурацию с одним 4-ядерным рабочим узлом и одним 4-ядерным узлом драйвера. Она прекрасно подходит для небольших выборок данных при тестировании логики потока данных. Если вы расширяете ограничения строк в параметрах отладки во время предварительного просмотра данных или задаете большее количество примеров строк в источнике во время отладки конвейера, то вы можете рассмотреть возможность настройки более крупной вычислительной среды в новом Azure Integration Runtime. Затем можно перезапустить сеанс отладки с помощью более крупной среды вычислений.
Предварительный просмотр данных
При отладке вкладка "Предварительный просмотр данных" загорается на нижней панели. Без режима отладки Data Flow отображает только текущие метаданные в каждом из преобразований на вкладке "Проверка". Предварительный просмотр данных запрашивает только количество строк, заданных в качестве ограничения в параметрах отладки. Выберите "Обновить" , чтобы обновить предварительный просмотр данных на основе текущих преобразований. Если исходные данные изменились, выберите "Обновить > Refetch" из источника.
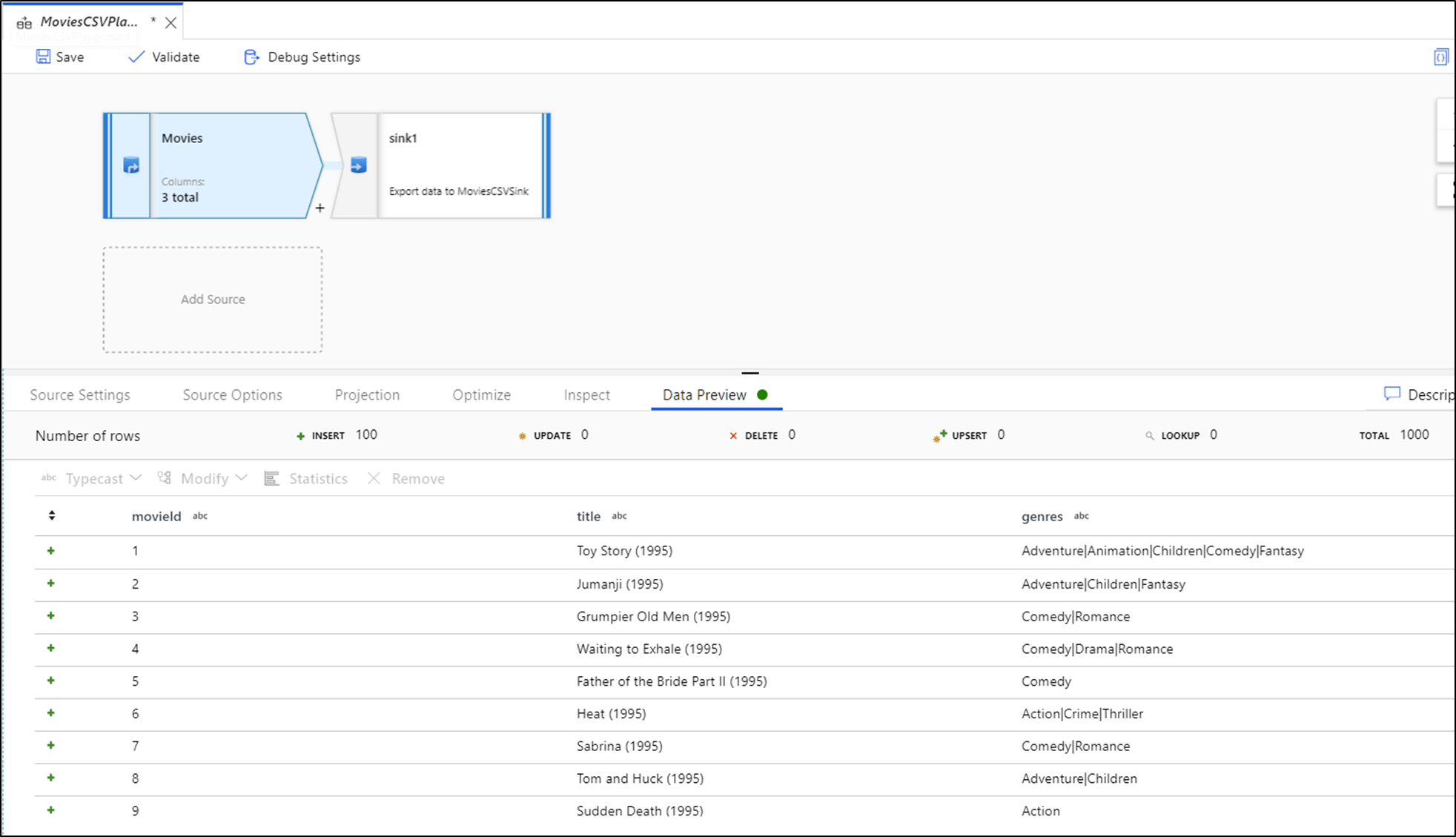
Столбцы можно сортировать в предварительном просмотре, а также переупорядочивать с помощью перетаскивания. Кроме того, в верхней части панели предварительного просмотра данных есть кнопка экспорта, которую можно использовать для экспорта данных предварительного просмотра в CSV-файл для автономного просмотра данных. Эту функцию можно использовать для экспорта до 1000 строк предварительных данных.
Примечание.
Источники файлов ограничивают только отображаемые строки, но не считываемые строки. Для очень больших наборов данных рекомендуется взять небольшую часть этого файла и использовать его для тестирования. Можно выбрать временный файл в параметрах отладки для каждого источника, который является типом файлового набора данных.
При запуске Data Flow в режиме отладки данные не будут записаны в трансформацию приемника. Сеанс отладки предназначен для использования в качестве тестовой оболочки для преобразований. Приемники не требуются во время отладки и игнорируются в потоке данных. Если вы хотите проверить запись данных в приемнике данных, выполните Data Flow из конвейера и запустите отладку из конвейера.
Предварительный просмотр данных — это моментальный снимок преобразованных данных, использующий ограничения строк и выборку данных из кадров данных в памяти Spark. Поэтому драйверы приемника не используются и не тестируются в этом сценарии.
Примечание.
Предварительный просмотр данных отображает время в соответствии с языковыми настройками браузера.
Тестирование условий соединения
При юнит-тестировании преобразований Join, Exist или Lookup убедитесь, что вы используете небольшой набор известных данных для теста. Параметр "Параметры отладки", описанный ранее, можно использовать для задания временного файла, используемого для тестирования. Это необходимо, так как при ограничении или выборке строк из большого набора данных невозможно предсказать, какие строки и какие ключи считываются в поток для тестирования. Результат недетерминирован, что означает, что условия соединения могут не выполниться.
Быстрые действия
После предпросмотра данных можно создать быструю трансформацию для типизации, удаления или внесения изменений в столбец. Выберите заголовок столбца и выберите один из вариантов на панели инструментов предварительного просмотра данных.
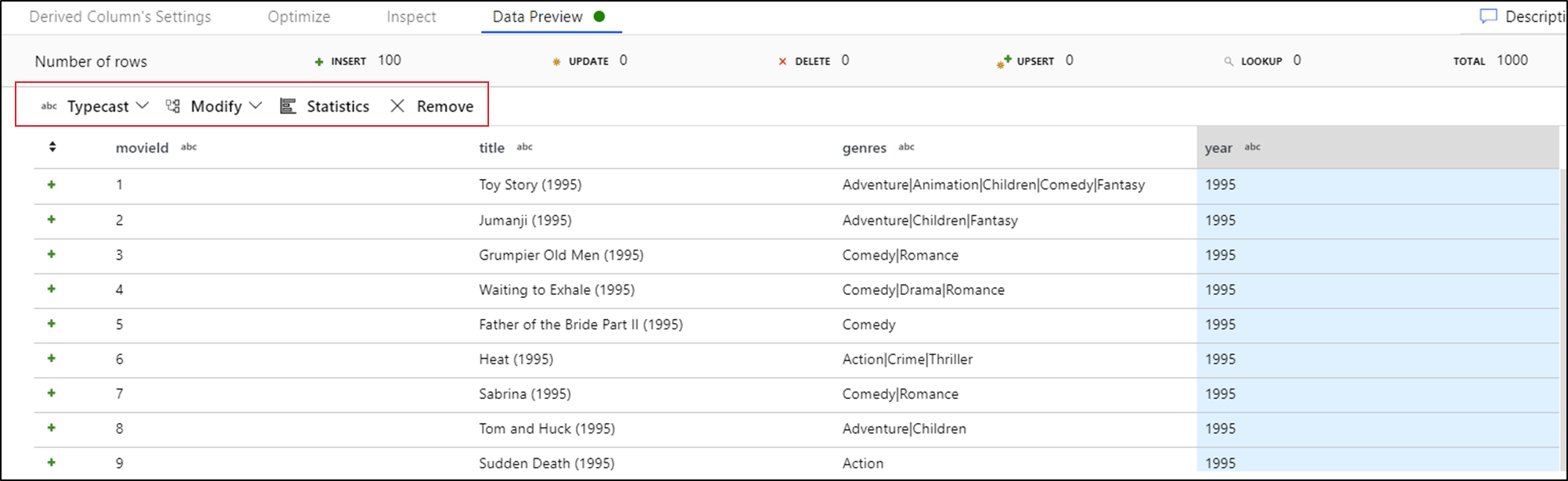
После выбора изменения предварительный просмотр данных будет немедленно обновлен. Нажмите кнопку "Подтвердить" в правом верхнем углу, чтобы создать новое преобразование.
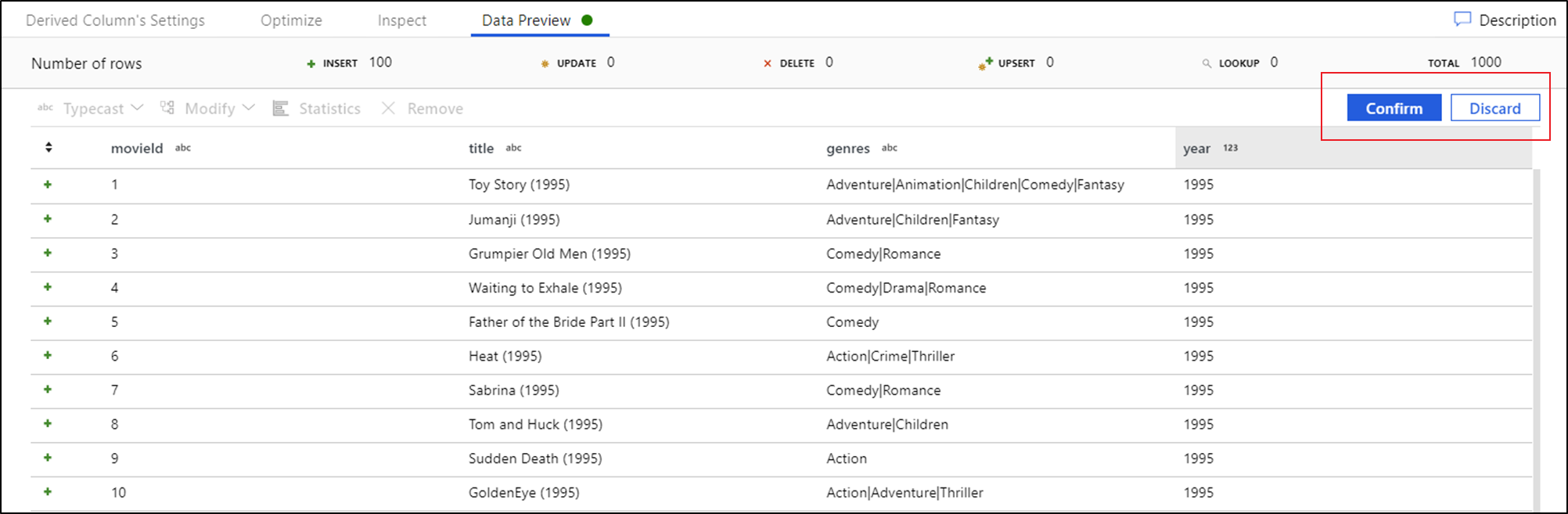
Typecast и Modify создают преобразование производного столбца, а Remove создает преобразование Select.
Примечание.
Если изменить Data Flow, перед добавлением быстрого преобразования необходимо повторно получить предварительный просмотр данных.
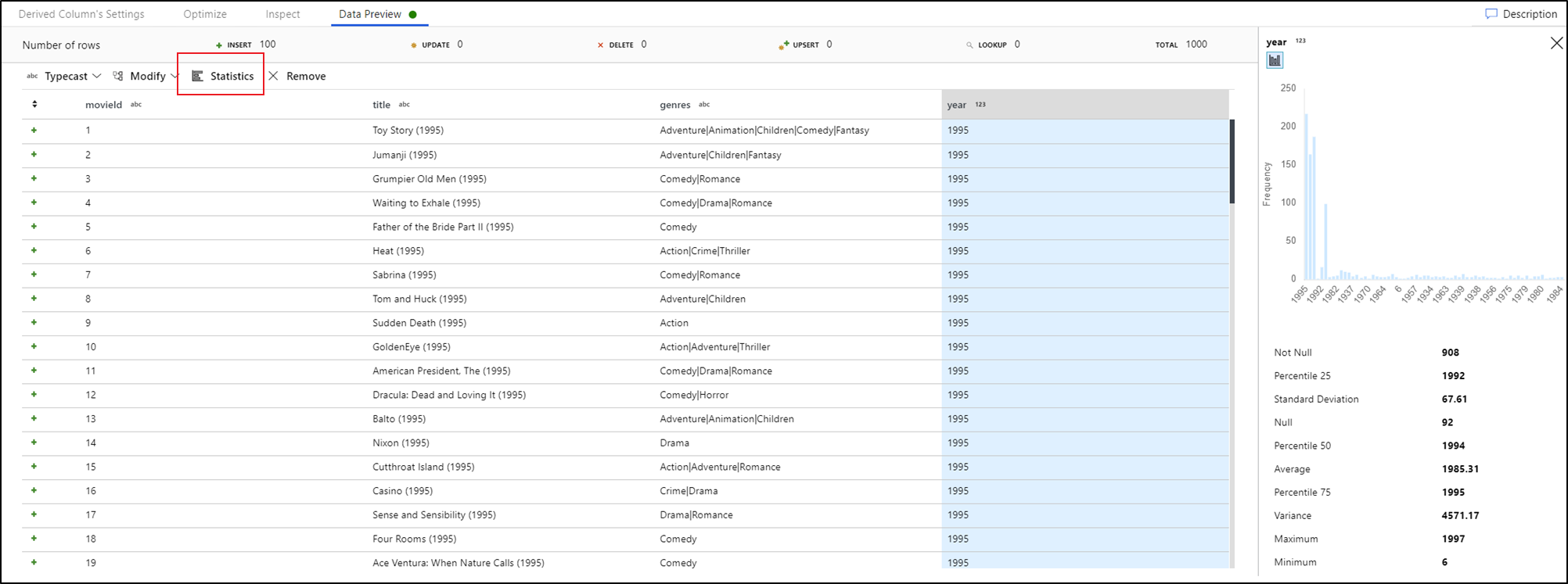
Профилирование данных
Выбор столбца на вкладке предварительного просмотра данных и нажатие кнопки "Статистика " на панели инструментов предварительного просмотра данных появится диаграмма справа от сетки данных с подробными статистическими данными о каждом поле. Служба принимает решение на основе выборки данных о том, какой тип диаграммы отображать. Поля высокой кратности по умолчанию имеют диаграммы NULL/NOT NULL, а категориальные и числовые данные с низкой кратностью отображают линейчатые диаграммы с частотой значения данных. Кроме того, отображается максимальная длина строковых полей, минимальное или максимальное значение в числовых полях, стандартное dev, процентиль, счетчики и среднее значение.
Связанный контент
- После завершения сборки и отладки потока данных выполните его из конвейера.
- При тестировании конвейера с потоком данных используйте опцию выполнения отладки конвейера.