Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Потоки данных доступны как в конвейерах Фабрики данных Azure, так и в конвейерах Azure Synapse Analytics. Эта статья относится к сопоставлению потоков данных. Если вы не знакомы с преобразованиями, ознакомьтесь с вводной статьей "Преобразование данных с помощью сопоставления потоков данных".
Используйте Unpivot в потоке данных для сопоставления как способ преобразования ненормализованного набора данных в более нормализованную версию. Это позволяет развернуть значения из нескольких столбцов одной записи в несколько записей с одинаковыми значениями в одном столбце.

Разгруппировать по
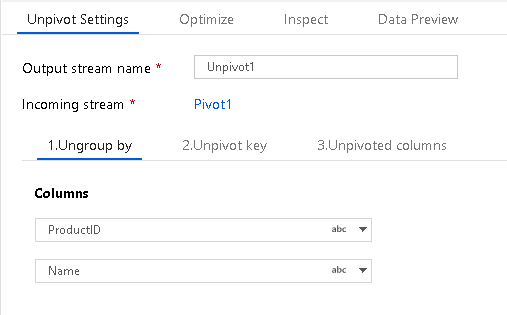
Сначала задайте столбцы, по которым будет производиться разгруппирование для развертывания агрегированного значения. Укажите один или несколько столбцов для разгруппировки со знаком "+" рядом со списком столбцов.
Ключ денормализации
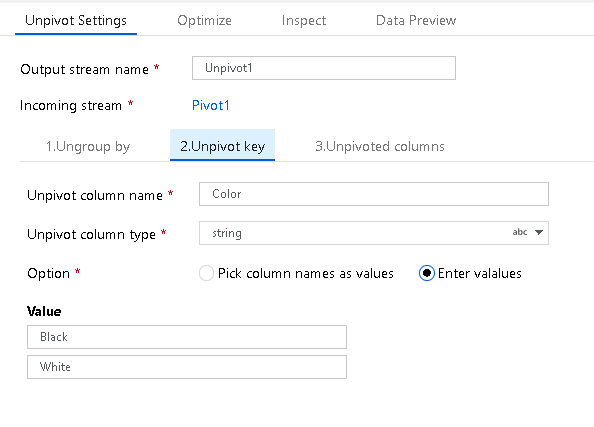
Ключом преобразования называется столбец, по которому служба будет преобразовывать данные из столбца в строку. По умолчанию каждое уникальное значение в наборе данных для этого поля будет сводиться в строку. При желании можно указать значения из набора данных, которые нужно преобразовать в значения строк.
Несвернутые столбцы
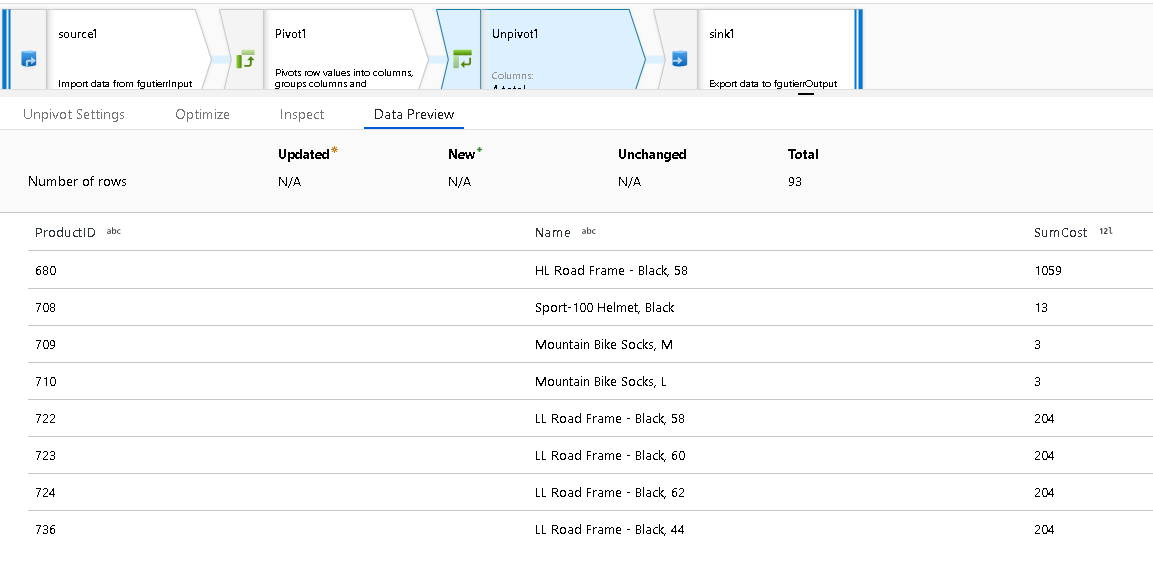
Наконец, выберите имя столбца для хранения значений несвернутых столбцов, преобразованных в строки.
(Дополнительно) Строки со значениями NULL можно удалить.
Например, SumCost — это имя столбца, выбранного в приведенном выше примере.

Если для параметра “Расположение столбцов” выбрано значение “Обычное”, все новые несвернутые столбцы с одинаковыми значениями будут сгруппированы вместе. Если для параметра “Расположение столбцов” выбрано значение “Боковое”, будут сгруппированы вместе новые несвернутые столбцы, сформированные на основе существующего столбца.
В окончательном наборе результатов для несвернутых данных отображаются итоговые значения столбца, которые теперь не объединены в значения отдельных строк.
Связанный контент
Используйте преобразование таблицы, чтобы преобразовать строки в столбцы.