Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Модели машинного обучения можно реализовывать в качестве определяемой пользователем функции (UDF) в заданиях Azure Stream Analytics для оценки и прогнозирования входных данных потоковой передачи в реальном времени. Машинное обучение Azure позволяет использовать любое популярное средство с открытым кодом, например Tensorflow, scikit-learn или PyTorch, для подготовки, обучения и развертывания моделей.
Предварительные условия
Перед добавлением модели машинного обучения в качестве функции в задание Stream Analytics выполните следующие действия.
Разверните модель как веб-службу с помощью Машинного обучения Azure.
Конечная точка машинного обучения должна иметь связанный с ней файл swagger, который помогает Stream Analytics выяснить схему входных и выходных данных. Вы можете использовать этот пример определения Swagger в качестве контрольного варианта для правильной настройки.
Убедитесь, что веб-служба принимает и возвращает сериализованные данные JSON.
Разверните свою модель в службе Azure Kubernetes для крупномасштабных развертываний в рабочей среде. Если веб-служба не может обрабатывать количество запросов, поступающих из вашего задания, производительность задания Stream Analytics будет снижена, что приведет к увеличению задержки. Модели, развернутые в Экземплярах контейнеров Azure, поддерживаются только при использовании портала Azure.
Добавление модели машинного обучения к заданию
Вы можете добавить функции Машинного обучения Azure в задание Stream Analytics непосредственно на портале Azure или в Visual Studio Code.
Портал Azure
Перейдите к заданию Stream Analytics в портале Azure и выберите Функции в разделе Топология задания. Затем щелкните Служба Машинного обучения Azure в раскрывающемся меню + Добавить.
Заполните форму Функция службы машинного обучение Azure следующими значениями свойств:
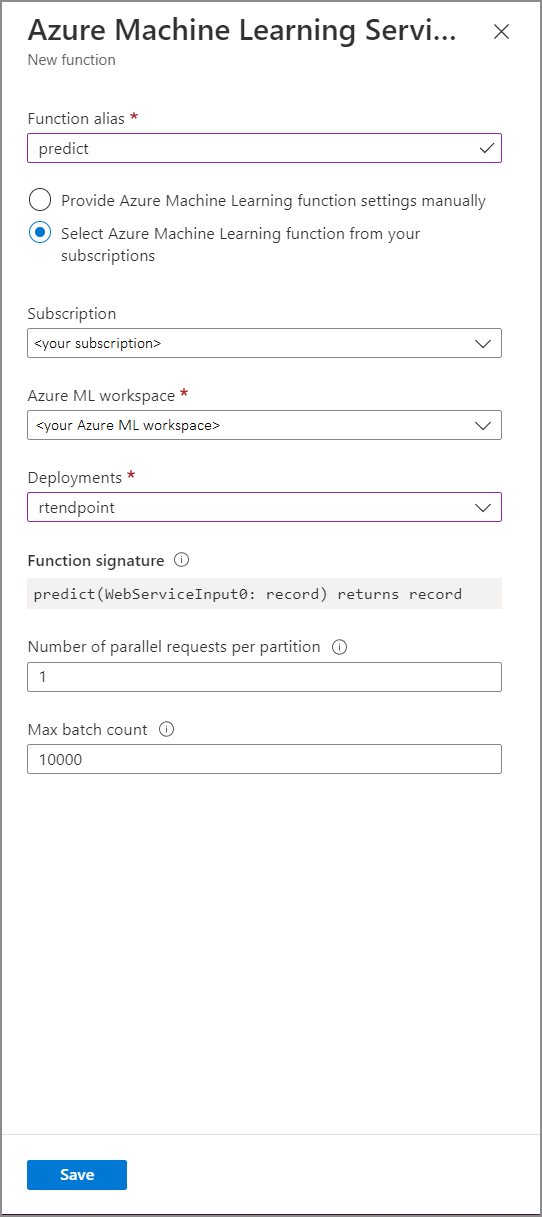
В следующей таблице описаны все свойства функций службы Машинного обучения Azure в Stream Analytics.
| Свойство | Описание |
|---|---|
| Псевдоним функции | Введите имя для вызова функции в запросе. |
| Подписка | Ваша подписка Azure. |
| Рабочая область службы "Машинное обучение Azure" | Рабочая область машинного обучения Azure, используемая для развертывания модели как веб-службы. |
| Конечная точка | Веб-служба, в которой размещается ваша модель. |
| Сигнатура функции | Сигнатура веб-службы выводится из спецификации схемы API. Если не удается загрузить сигнатуру, убедитесь, что вы предоставили пример входных и выходных данных в сценарии оценки для автоматического создания схемы. |
| Число параллельных запросов на секцию | Это расширенная конфигурация для оптимизации пропускной способности при высоких нагрузках. Это число представляет параллельные запросы, отправляемые из каждой секции задания в веб-службу. Задания с шестью единицами потоковой передачи (SU) или меньше имеют один раздел. Задания с 12 SU имеют два раздела, 18 SU — три раздела и так далее. Например, если в вашем задании два раздела и вы установите этот параметр на 4, то будет отправлено восемь одновременных запросов из вашего задания к веб-службе. |
| Максимальное количество пакетов | Это параметр расширенной конфигурации для оптимизации пропускной способности на большом уровне. Это число представляет максимальное число событий, сгруппированных в одном запросе, отправленном в веб-службу. |
Вызов конечной точки машинного обучения из запроса
Когда запрос Stream Analytics вызывает пользовательскую функцию Azure Machine Learning UDF, задание создает сериализованный JSON-запрос к веб-службе. Запрос основан на модели, специфичной для схемы, которую Stream Analytics выводит из Swagger-документации конечной точки.
Предупреждение
Конечные точки машинного обучения не вызываются при тестировании с помощью редактора запросов в портале Azure, поскольку задание не выполняется. Чтобы проверить вызов конечной точки на портале, задание Stream Analytics должно выполняться.
Следующий запрос Stream Analytics является примером вызова UDF в Azure Machine Learning:
SELECT udf.score(<model-specific-data-structure>)
INTO output
FROM input
WHERE <model-specific-data-structure> is not null
Если отправленные в ML UDF входные данные не согласуются с ожидаемой схемой, конечная точка возвратит ответ с кодом ошибки 400, что приведет к переходу задания Stream Analytics в состояние сбоя. Рекомендуется включить журналы ресурсов для задания, что позволит легко отлаживать и устранять такие проблемы. Поэтому настоятельно рекомендуется:
- Убедитесь, что входные данные в UDF машинного обучения не являются null
- Проверяйте тип для каждого поля, которое передается во входных данных ML UDF, чтобы он соответствовал ожиданиям конечной точки.
Примечание.
Функции UDF вычисляются для каждой строки этапа запроса, даже при вызове с помощью условного выражения (т. е. CASE WHEN [A] IS NOT NULL THEN udf.score(A) ELSE '' END). При необходимости используйте предложение WITH для создания разветвляющихся путей, вызывая UDF ML только при необходимости, перед использованием UNION с целью повторного объединения путей.
Передача нескольких входных параметров в UDF (определяемую пользователем функцию)
Наиболее распространенными примерами входных данных для моделей машинного обучения являются DataFrame и массивы NumPy. Вы можете создать массив, используя определяемую пользователем функцию JavaScript (UDF), а сериализованный в формате JSON DataFrame — с помощью предложения WITH.
Создание входного массива
Вы можете создать пользовательскую функцию JavaScript, которая принимает N входных данных и создает массив, который можно использовать в качестве входных данных для пользовательской функции Azure Machine Learning.
function createArray(vendorid, weekday, pickuphour, passenger, distance) {
'use strict';
var array = [vendorid, weekday, pickuphour, passenger, distance]
return array;
}
После того как вы добавили JavaScript UDF в задание, вы можете вызвать UDF машинного обучения Azure с помощью следующего запроса:
WITH
ModelInput AS (
#use JavaScript UDF to construct array that will be used as input to ML UDF
SELECT udf.createArray(vendorid, weekday, pickuphour, passenger, distance) as inputArray
FROM input
)
SELECT udf.score(inputArray)
INTO output
FROM ModelInput
#validate inputArray is not null before passing it to ML UDF to prevent job from failing
WHERE inputArray is not null
Следующий JSON является примером запроса:
{
"Inputs": {
"WebServiceInput0": [
["1","Mon","12","1","5.8"],
["2","Wed","10","2","10"]
]
}
}
Создайте DataFrame Pandas или PySpark
Можно использовать предложение WITH для создания сериализованного в формате JSON DataFrame, который можно передать в качестве входных данных для пользовательской функции Azure Machine Learning, как показано ниже.
Следующий запрос создает DataFrame, выбирая необходимые поля и использует DataFrame в качестве ввода для UDF в Azure Machine Learning.
WITH
Dataframe AS (
SELECT vendorid, weekday, pickuphour, passenger, distance
FROM input
)
SELECT udf.score(Dataframe)
INTO output
FROM Dataframe
WHERE Dataframe is not null
Следующий JSON является примером запроса из состава предыдущего запроса:
{
"Inputs": {
"WebServiceInput0": [
{
"vendorid": "1",
"weekday": "Mon",
"pickuphour": "12",
"passenger": "1",
"distance": "5.8"
},
{
"vendorid": "2",
"weekday": "Tue",
"pickuphour": "10",
"passenger": "2",
"distance": "10"
}]
}
}
Оптимизация производительности определяемых пользователем функций в Машинном обучении Azure
При развертывании модели в службе Kubernetes Azure можно профилировать модель, чтобы определить использование ресурсов. Кроме того, вы можете включить Application Insights для развертываний, чтобы узнать их частоту запросов, время отклика и частоту сбоев.
При наличии сценария с высоким потоком событий для достижения оптимальной производительности с низкими сквозными задержками может потребоваться изменить следующие параметры в Stream Analytics.
- Максимальное количество пакетов
- Число параллельных запросов на раздел.
Определение правильного размера пакета
После развертывания веб-службы вы отправляете пример запроса с различными размерами пакетов, начиная с 50 и увеличивая их на сотни. Например, 200, 500, 1000, 2000 и т. д. Вы заметите, что после определенного размера пакета задержка ответа увеличится. Точка, после которой увеличивается задержка отклика, должна быть максимальным числом пакетов обработки для вашего задания.
Определите количество параллельных запросов на раздел.
При оптимальном масштабе задание Stream Analytics должно иметь возможность отправить несколько параллельных запросов в веб-службу и получить ответ в течение нескольких миллисекунд. Задержка ответа веб-службы может напрямую влиять на задержку и производительность задания Stream Analytics. Если вызов из задания в веб-службу занимает много времени, вы, скорее всего, увидите увеличение задержки водяного знака, а также увеличение числа отложенных входных событий.
Чтобы снизить задержку, обеспечьте достаточное количество узлов и реплик при подготовке кластера Службы Azure Kubernetes (AKS). Очень важно, чтобы веб-служба была высокодоступна и возвращала успешные ответы. Если задание получает сообщение об ошибке, которое может быть повторено, например, сообщение о недоступности службы (503), оно автоматически повторится с экспоненциальной задержкой. Если задание получает в ответе от конечной точки одну из перечисленных ниже ошибок, оно переходит в состояние сбоя.
- Недопустимый запрос (400)
- Конфликт (409)
- Не найдено (404)
- Не авторизовано (401)
Ограничения
Если вы используете управляемую конечную точку Azure ML, Stream Analytics в настоящее время может получить доступ только к конечным точкам с включенным общедоступным сетевым доступом. Дополнительные сведения см. на странице о частных конечных точках Машинного обучения Azure.