Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
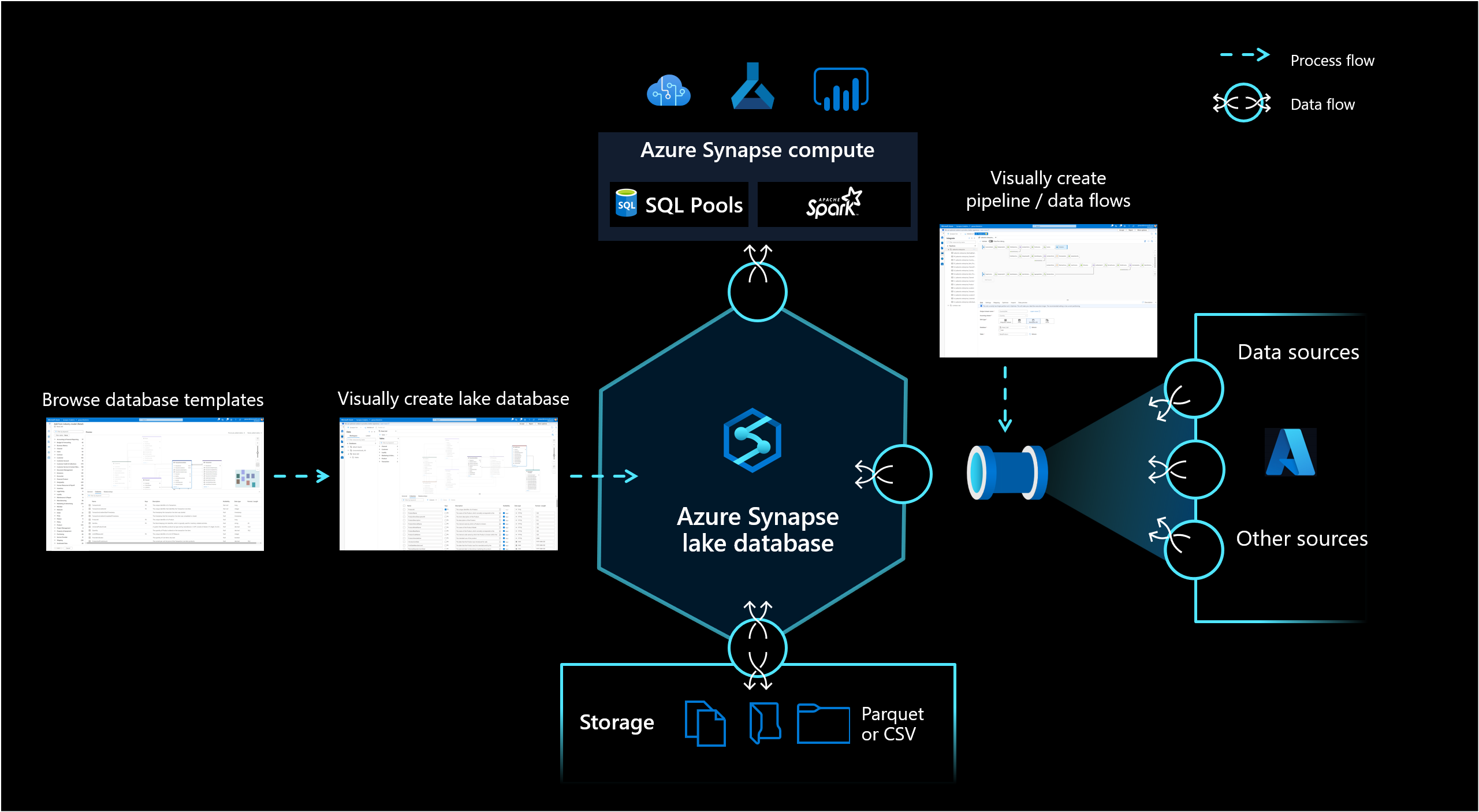
База данных озера в Azure Synapse Analytics позволяет клиентам объединять структуру баз данных, метаданные о хранящихся данных и возможность описания того, как и где эти данные должны храниться. База данных Lake решает проблему современных озер данных, где трудно понять, как структурированы данные.
Конструктор баз данных
Новый конструктор баз данных в Synapse Studio предоставляет возможность создать модель данных для базы данных озера и добавить в нее дополнительные сведения. Каждую сущность и атрибут можно описать, чтобы предоставить дополнительные сведения о модели, которая содержит не только сущности, но и связи. В частности, неспособность смоделировать связи создавала сложности для взаимодействия в озере данных. Теперь эти сложности устранены благодаря интегрированному конструктору, поддерживающему возможности, которые ранее были доступны в базах данных, но не в озере. Кроме того, возможность добавлять в модель описания и возможные демонстрационные значения позволяет людям, которые будут взаимодействовать с ней в будущем, получить нужную информацию там, где это необходимо, чтобы лучше понять данные.
Примечание.
Максимальный размер метаданных в базе данных озера составляет 10 ГБ. Попытка опубликовать или обновить модель, превышающую размер 10 ГБ, завершится ошибкой. Чтобы устранить эту проблему, уменьшите размер модели, удалив таблицы и столбцы. Рассмотрите возможность разделения больших моделей на несколько баз данных озера, чтобы избежать этого ограничения.
Хранилище данных
База данных озера использует озеро данных в учетной записи службы хранилища Azure для хранения своего содержимого. Данные можно хранить в формате Parquet, Delta или CSV, а для оптимизации хранилища можно использовать различные параметры. Каждая база данных озера использует связанную службу, которая позволяет определить расположение корневой папки данных. Для каждой сущности в этой папке базы данных в озере данных по умолчанию создаются отдельные папки. По умолчанию все таблицы в базе данных озера используют один формат, но форматы и расположение данных при необходимости можно изменить для каждой отдельной сущности.
Примечание.
При публикации базы данных озера не создаются никакие базовые структуры или схемы, необходимые для запроса данных в Spark или SQL. После публикации загрузите данные в озерную базу данных с помощью конвейеров, чтобы начать выполнять запросы.
В Synapse Studio в настоящее время не поддерживается Delta-формат для озер данных.
Синхронизация объектов базы данных озера между хранилищем и Synapse является однонаправленной. Не забудьте выполнить любое создание или изменение схемы объектов базы данных lake с помощью конструктора баз данных в Synapse Studio. Если вместо этого вы вносите такие изменения из Spark или непосредственно в хранилище, определения баз данных озера будут не синхронизированы. В этом случае в конструкторе баз данных могут отображаться старые определения базы данных озера. Чтобы привести озёрные базы данных в синхронизацию, необходимо реплицировать и опубликовать такие изменения в конструкторе баз данных.
Вычислительные ресурсы базы данных
База данных озера доступна в бессерверном пуле SQL Synapse SQL и в Apache Spark, предоставляя пользователям возможность отделить хранилище от вычислений. Метаданные, связанные с базой данных озера, упрощают работу различных вычислительных двигателей, которые могут не только предоставлять интегрированный опыт, но и использовать дополнительные сведения (например, связи), которые изначально не поддерживались на озере данных.
Связанный контент
Продолжайте изучение возможностей конструктора баз данных, используя приведенные ниже ссылки.