Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Внешняя таблица указывает на данные, расположенные в Hadoop, BLOB-объекте службы хранилища Azure или Azure Data Lake Storage (ADLS).
Внешние таблицы можно использовать для чтения данных из файлов или записи данных в файлы в службе хранилища Azure. С помощью Azure Synapse SQL можно использовать внешние таблицы для чтения внешних данных с помощью выделенного пула SQL или бессерверного пула SQL.
В зависимости от типа внешнего источника данных можно использовать два типа внешних таблиц:
- Внешние таблицы Hadoop , которые можно использовать для чтения и экспорта данных в различных форматах данных, таких как CSV, Parquet и ORC. Внешние таблицы Hadoop доступны в выделенных пулах SQL, но они недоступны в бессерверных пулах SQL.
- Собственные внешние таблицы , которые можно использовать для чтения и экспорта данных в различных форматах данных, таких как CSV и Parquet. Собственные внешние таблицы доступны в бессерверных пулах SQL и в выделенных пулах SQL. Запись и экспорт данных с помощью CETAS и собственных внешних таблиц доступна только в бессерверном пуле SQL, но не в выделенных пулах SQL.
Основные различия между Hadoop и собственными внешними таблицами:
| Тип внешней таблицы | Hadoop | Native |
|---|---|---|
| Выделенный пул SQL | Available | Только Parquet |
| Бессерверный пул SQL | Недоступно | Available |
| Поддерживаемые форматы | Делимитированный/CSV, Parquet, ORC, Hive RC и RC | Бессерверного SQL пула: разделённый текст/CSV, Parquet и Delta Lake Выделенный пул SQL: Parquet |
| Устранение разделов папок | No | Устранение секций доступно только в секционированных таблицах, созданных в форматах Parquet или CSV, которые синхронизируются из пулов Apache Spark. Вы можете создавать внешние таблицы в секционированных папках Parquet, но столбцы секционирования недоступны и игнорируются, а исключение секционирования не будет применено. Не создавайте внешние таблицы в папках Delta Lake , так как они не поддерживаются. Используйте Delta секционированные представления, если необходимо запрашивать секционированные данные Delta Lake. |
| Удаление файла (предикатное выталкивание) | No | Да в бессерверном пуле SQL. Чтобы включить pushdown строки, необходимо использовать Latin1_General_100_BIN2_UTF8 параметры сортировки для VARCHAR столбцов. Дополнительные сведения о параметрах сортировки см. в статье о поддержке сортировки базы данных для Synapse SQL в Azure Synapse Analytics. |
| Настраиваемый формат расположения | No | Да, используя подстановочные знаки, например /year=*/month=*/day=* для форматов Parquet или CSV. Путь к пользовательским папкам недоступен в Delta Lake. В бессерверном пуле SQL можно также использовать рекурсивные подстановочные знаки /logs/** для ссылки на файлы Parquet или CSV в любой вложенной папке под указанной папкой. |
| Рекурсивная проверка папки | Yes | Yes. В бессерверных пулах SQL необходимо указать /** в конце пути расположения. В выделенном пуле папки всегда сканируются рекурсивно. |
| Проверка подлинности хранилища | Ключ доступа к хранилищу (SAK), сквозная передача Microsoft Entra, управляемое удостоверение, пользовательское приложение Microsoft Entra удостоверение | Подпись для совместного доступа (SAS), сквозная аутентификация Microsoft Entra, управляемая удостоверение, пользовательское приложение идентификатор Microsoft Entra. |
| Сопоставление столбцов | Порядковый — столбцы в определении внешней таблицы по позиции сопоставляются со столбцами в базовых файлах Parquet. | Бессерверный пул: поиск по имени. Столбцы в определении внешней таблицы сопоставляются со столбцами в базовых файлах Parquet по совпадению имен столбцов. Выделенный пул: порядковое сопоставление. Столбцы во определении внешней таблицы сопоставляются со столбцами в базовых файлах Parquet по позиции. |
| CETAS (экспорт и преобразование) | Yes | CETAS с собственными таблицами в качестве целевого объекта работает только в бессерверном пуле SQL. Вы не можете использовать выделенные пулы SQL для экспорта данных с помощью собственных таблиц. |
Note
Собственные внешние таблицы — это рекомендуемое решение в пулах, где они являются общедоступными. Если вам нужно получить доступ к внешним данным, всегда используйте собственные таблицы в бессерверных или выделенных пулах. Используйте таблицы Hadoop только в том случае, если вам нужно получить доступ к некоторым типам, которые не поддерживаются в собственных внешних таблицах (например, ORC, RC) или если собственная версия недоступна.
Внешние таблицы в выделенном пуле SQL и бессерверном пуле SQL
Внешние таблицы можно использовать для:
- Запрос данных в хранилищах Azure Blob и ADLS Gen2 с использованием Transact-SQL.
- Храните результаты запроса к файлам в хранилище BLOB-объектов Azure или Azure Data Lake Storage с помощью CETAS с Synapse SQL.
- Импортируйте данные из хранилища BLOB-объектов Azure и Azure Data Lake Storage и сохраните их в выделенном пуле SQL (только таблицы Hadoop в выделенном пуле).
Note
При использовании с инструкцией CREATE TABLE AS SELECT выбор из внешней таблицы импортирует данные в таблицу в выделенном пуле SQL.
Если производительность внешних таблиц Hadoop в выделенных пулах не удовлетворяет вашим целям производительности, рассмотрите возможность загрузки внешних данных в таблицы хранилища данных с помощью инструкции COPY.
Руководство по загрузке см. в разделе "Использование PolyBase" для загрузки данных из хранилища BLOB-объектов Azure.
Внешние таблицы можно создать в пулах SQL Synapse, выполнив следующие действия.
- CREATE EXTERNAL DATA SOURCE для ссылки на внешнее хранилище Azure и укажите учетные данные, которые следует использовать для доступа к хранилищу.
- CREATE EXTERNAL FILE FORMAT для описания формата файлов CSV и Parquet.
- CREATE EXTERNAL TABLE поверх файлов, размещенных в источнике данных с тем же форматом файла.
Удаление разделов папок
Собственные внешние таблицы в пулах Synapse могут игнорировать файлы, помещенные в папки, которые не относятся к запросам. Если файлы хранятся в иерархии папок (например, — /year=2020/month=03/day=16) и значения для year, monthа day также предоставляются в виде столбцов, запросы, содержащие фильтры, например year=2020 , считывают файлы только из вложенных папок, размещенных в папке year=2020 . Файлы и папки, помещенные в другие папки (year=2021 или year=2022) будут игнорироваться в этом запросе. Эта ликвидация называется устранением партиций.
Устранение секций папок доступно в штатных внешних таблицах, которые синхронизируются из пулов Synapse Spark. Если у вас есть секционированные наборы данных, и вы хотите использовать исключение секционирования с создаваемыми внешними таблицами, используйте секционированные представления вместо внешних таблиц.
Устранение файлов
Некоторые форматы данных, такие как Parquet и Delta, содержат статистику файлов для каждого столбца (например, минимальное или максимальное значение для каждого столбца). Запросы, которые фильтруют данные, не считывают файлы, в которых отсутствуют обязательные значения столбцов. Запрос сначала изучит значения min/max для столбцов, используемых в предикате запроса, чтобы найти файлы, которые не содержат необходимые данные. Эти файлы игнорируются и удаляются из плана запроса.
Этот метод также называется принудительной отправкой предиката фильтра и может повысить производительность запросов. Фильтрация pushdown доступна в бессерверных пулах SQL в форматах Parquet и Delta. Чтобы применить pushdown фильтра для строковых типов, используйте тип VARCHAR с параметрами Latin1_General_100_BIN2_UTF8 сортировки. Дополнительные сведения о параметрах сортировки см. в статье о поддержке сортировки базы данных для Synapse SQL в Azure Synapse Analytics.
Security
Пользователь должен иметь SELECT разрешение на внешнюю таблицу для чтения данных.
Внешние таблицы используют учетные данные, определенные в источнике данных, для доступа к базовому хранилищу Azure согласно следующим правилам.
- Источник данных без учетных данных позволяет внешним таблицам получать доступ к общедоступным файлам в хранилище Azure.
- Источник данных может иметь учетные данные, позволяющие внешним таблицам получать доступ только к файлам в хранилище Azure с помощью маркера SAS или управляемого удостоверения рабочей области. Например, см. статью "Разработка управления доступом к файлам хранилища".
Замечания
Чтобы обеспечить надежное выполнение запроса, исходные файлы и папки, на которые ссылаются внешние таблицы, должны оставаться неизменными в течение всей операции.
- Изменение, удаление или замена всех ссылочных файлов или папок во время выполнения запроса может привести к сбоям или привести к несогласованным результатам.
- Прежде чем запрашивать внешние таблицы в выделенном пуле SQL, убедитесь, что все исходные данные стабильны и не будут изменены во время выполнения.
Пример для CREATE EXTERNAL DATA SOURCE
В следующем примере создается внешний источник данных Hadoop в выделенном пуле SQL для ADLS 2-го поколения, указывающий на общедоступный набор данных Нью-йорка:
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=2022-11-02&ss=b&srt=co&sp=rl&se=2042-11-26T17:40:55Z&st=2024-11-24T09:40:55Z&spr=https&sig=DKZDuSeZhuCWP9IytWLQwu9shcI5pTJ%2Fw5Crw6fD%2BC8%3D'
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH
-- Please note the abfss endpoint when your account has secure transfer enabled
( LOCATION = 'abfss://data@newyorktaxidataset.dfs.core.windows.net' ,
CREDENTIAL = ADLS_credential ,
TYPE = HADOOP
) ;
В следующем примере создается внешний источник данных для ADLS 2-го поколения, указывающий на общедоступный набор данных Нью-йорка:
CREATE EXTERNAL DATA SOURCE YellowTaxi
WITH ( LOCATION = 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/',
TYPE = HADOOP)
Пример СОЗДАНИЯ ВНЕШНЕГО ФОРМАТА ФАЙЛА
В следующем примере создается внешний формат файла для файлов переписи данных:
CREATE EXTERNAL FILE FORMAT census_file_format
WITH
(
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
Пример CREATE EXTERNAL TABLE
В следующем примере создается внешняя таблица. Она возвращает первую строку:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
)
GO
SELECT TOP 1 * FROM census_external_table
Создание и запрос внешних таблиц из файла в Azure Data Lake
С помощью возможностей изучения Data Lake в Synapse Studio теперь можно создать и запросить внешнюю таблицу с помощью пула SQL Synapse, щелкнув файл правой кнопкой мыши. Жест одного щелчка для создания внешних таблиц из учетной записи хранения ADLS 2-го поколения поддерживается только для файлов Parquet.
Prerequisites
У вас должен быть доступ к рабочей области с по крайней мере
Storage Blob Data Contributorролью доступа к учетной записи ADLS 2-го поколения или спискам управления доступом, которые позволяют запрашивать файлы.Для создания внешней таблицы и запроса внешних таблиц в пуле Synapse SQL (выделенных или бессерверных) необходимо иметь по крайней мере разрешения.
На панели данных выберите файл, из который вы хотите создать внешнюю таблицу:
Откроется диалоговое окно. Выберите выделенный пул SQL или бессерверный пул SQL, присвойте таблице имя и выберите открытый скрипт:
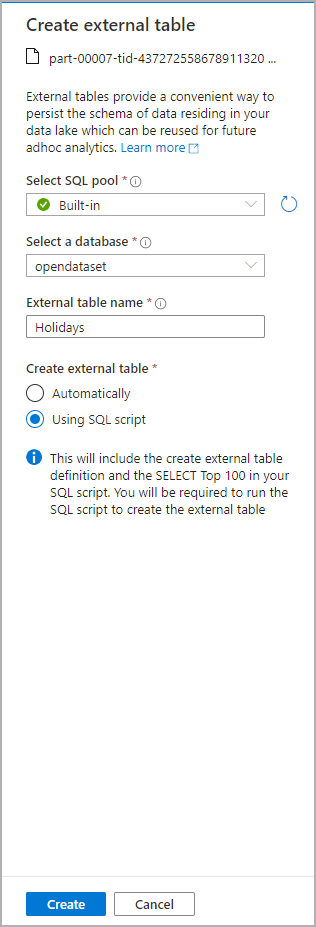
Скрипт SQL автоматически выводит схему из файла:

Запустите скрипт. Скрипт автоматически запустит следующую SELECT TOP 100 *команду:

Внешняя таблица теперь создана. Теперь вы можете запросить внешнюю таблицу непосредственно из области данных.
Связанный контент
Сведения о сохранении результатов запросов во внешней таблице в службе хранилища Azure см. в статье CETAS . Или вы можете начать выполнять запросы с использованием Apache Spark для внешних таблиц Azure Synapse.