Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Предварительно созданная модель распознавания текста в AI Builder извлекает печатный и рукописный текст из изображений и документов. Используя эту модель в Power Automate, вы можете создавать рабочие процессы, которые автоматически обрабатывают текст из отсканированных документов, фотографий и PDF-файлов, обеспечивая эффективную обработку данных и интеграцию с другими приложениями.
В этом документе содержится руководство по использованию предварительно созданной модели распознавания текста в Power Automate.
Инициализация облачного потока Power Automate
Инициализация облачного потока Power Automate — это первый шаг в настройке автоматизированного процесса. Этот шаг позволяет определить триггер и начальные входные параметры для облачного потока. При инициализации можно убедиться в том, что облачный поток запускается правильно и имеет необходимую информацию для эффективной обработки задач распознавания текста.
Чтобы инициализировать облачный поток, выполните следующие действия:
Выполните вход в Power Automate.
В левом меню навигации выберите Мои потоки, затем выберите Создать поток>Мгновенный облачный поток.
Присвойте своему облачному потоку имя, в разделе Выбор способа запуска для этого потока щелкните Активировать поток вручную и нажмите кнопку Создать.
Разверните Активация потока вручную и выберите +Добавить входные данные>Файл в качестве типа входных данных.
Выберите +Создать шаг>AI Builder, затем выберите Распознавание текста на изображении или в документе PDF в списке действий.
Выберите ввод Изображение, а затем выберите Содержимое файла из списка Динамический контент:
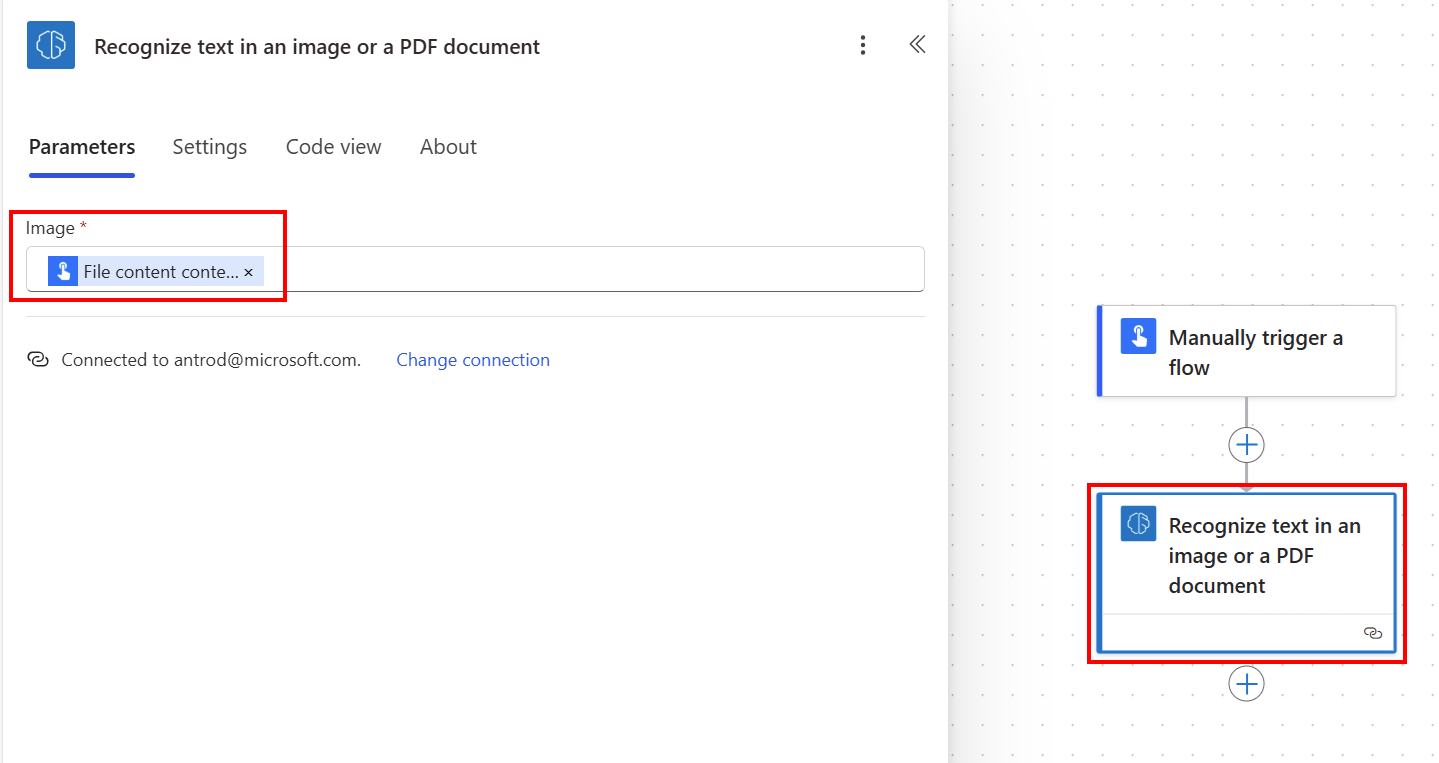
Для обработки результатов можно использовать либо полный текст документа, либо текст страницы, либо текст документа строка за строкой.
Получение полного текста документа или полного текста страницы
Если вам нужно выполнить действие над полным текстом документа или над конкретным текстом страницы, эта опция полезна. Примером использования текста страницы является ситуация, когда требуется найти подстроку или передать его последующему действию.
Весь извлеченный текст можно опубликовать в канале Teams, используя пункт Весь текст документа из списка динамического содержимого.
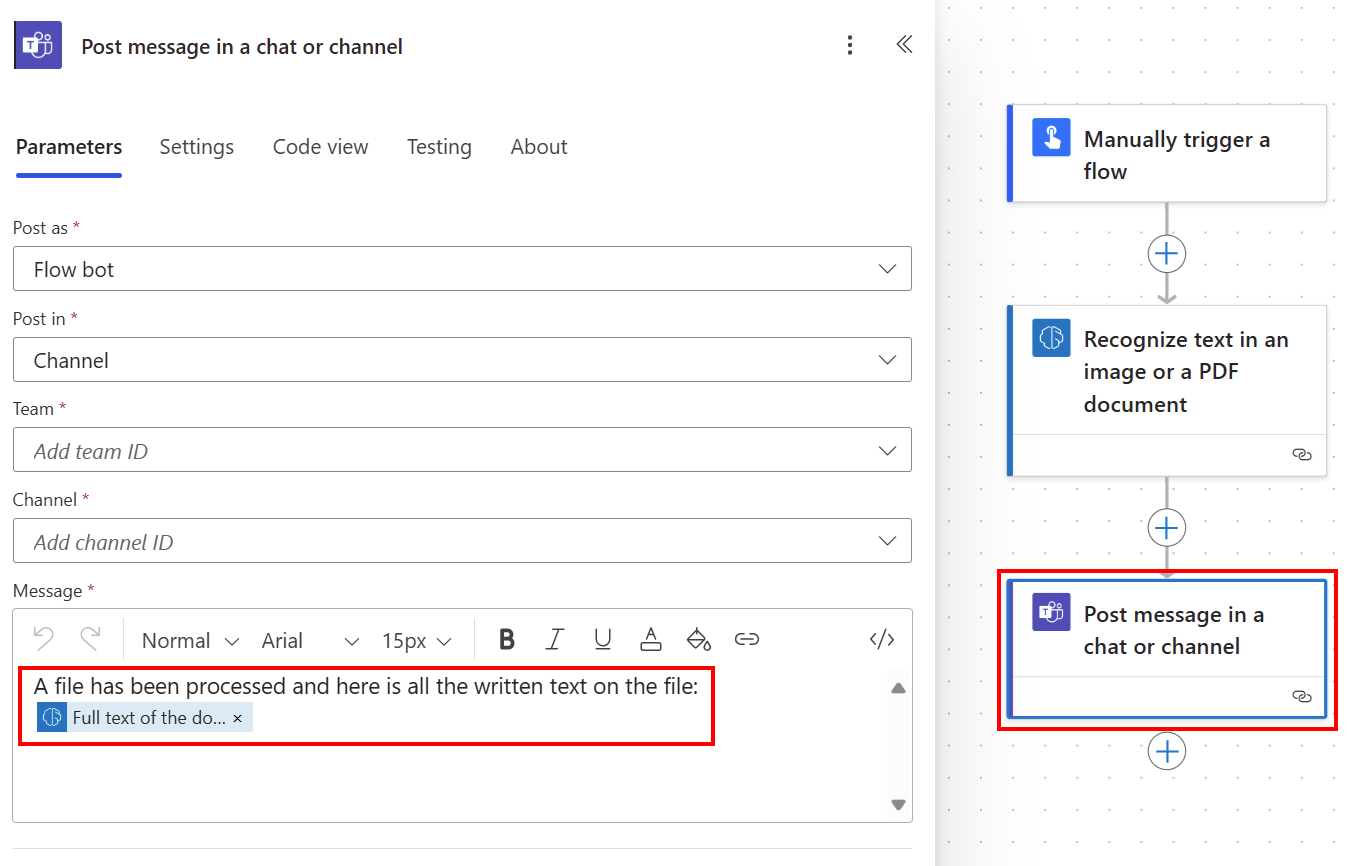
Получение текста документа построчно
Получение текста документа построчно может быть полезно, если вам нужно изолировать определенную строку текста или переформатировать текст по вашему усмотрению.
Чтобы создать строковую переменную, выберите + Создать шаг>Элемент управления, затем выберите Инициализировать переменную.
Назовите ее, например, Извлеченный текст.
Выберите + Создать шаг>Элемент управления, затем выберите Добавить к строковой переменной.
В поле значение выберите Текст в списке динамического содержимого.
Он автоматически генерирует два действия Применить к каждому при чтении списка строк текста в списке страниц. Затем вы можете поместить весь извлеченный текст в канал Teams.
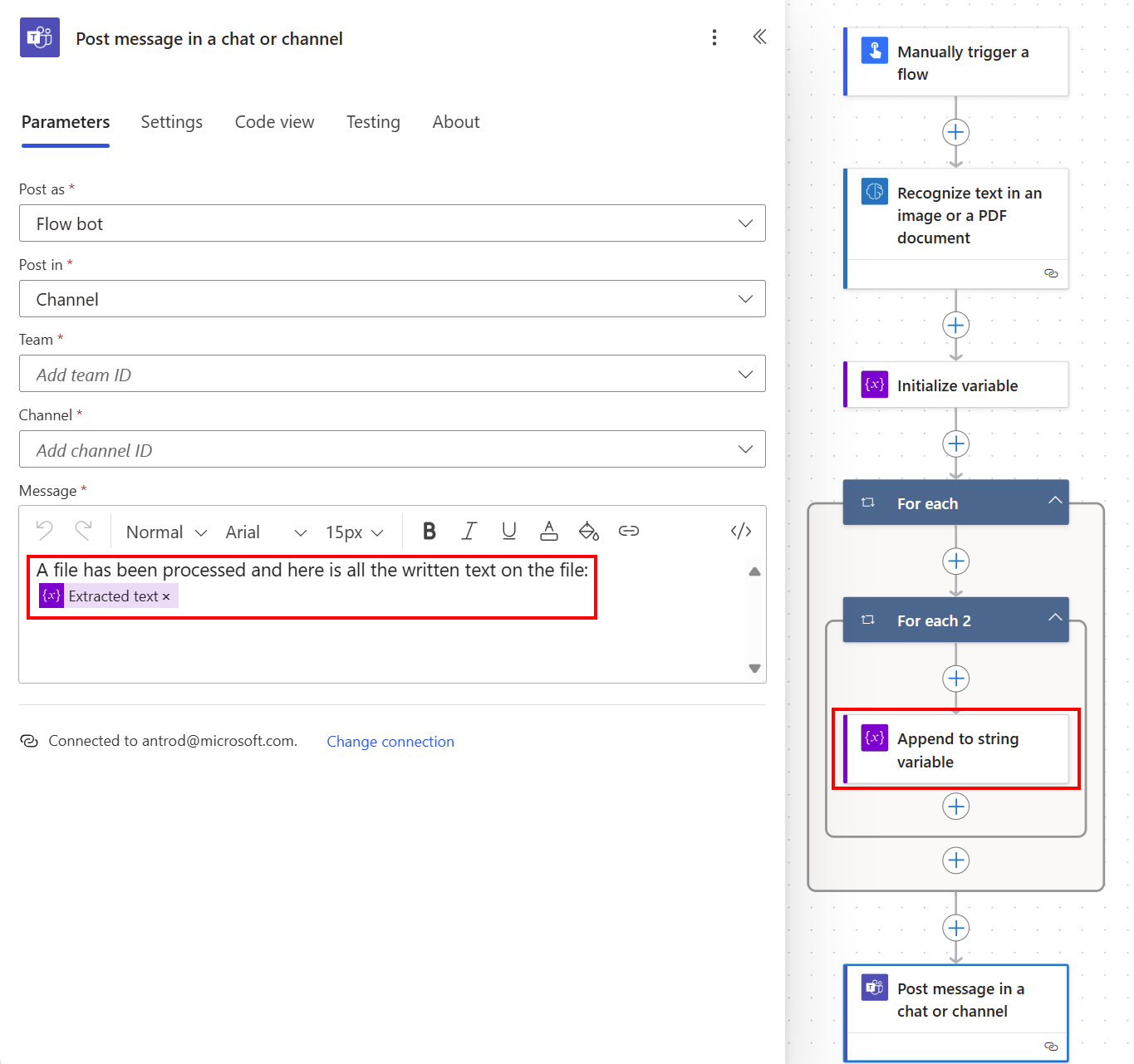
Поздравляем! Вы создали облачный поток, использующий модель распознавания текстов. Вы можете продолжить настройку этого облачного потока, пока он не будет соответствовать вашим требованиям. Щелкните Сохранить в правом верхнем углу, а затем выберите Тест, чтобы проверить облачный поток.
Параметры
Предварительно созданная модель распознавания текста в AI Builder содержит следующие входные и выходные параметры.
Входные данные
| Полное имя | Обязательно | Type | Description |
|---|---|---|---|
| Изображение | Да | файл | Изображение для анализа |
Выходные данные
Обнаруженный текст вставляется во вложенный список строки списка результаты. Сначала вам нужно выбрать столбец строки из действия Применить к каждому для просмотра всех следующих столбцов.
| Полное имя | Тип | Описание |
|---|---|---|
| Текст | строка | Строки, содержащие обнаруженные строки текста |
| Номер страницы | string | Номер страницы для обнаруженного текста |
| Координаты | с плавающей запятой | Координаты для обнаруженного текста |
| Весь текст документа | string | Обнаружен полный текст |
| Весь текст страницы | string | Обнаружен весь текст страницы |