Развертывание масштабирования
Распределенное кэширование на пути к масштабированию
Икбаль Хан (Iqbal Khan)
В этой статье обсуждаются:
|
В данной статье использованы следующие технологии: ASP.NET, веб-служб, приложений HPC |
Содержание
Распределенные кэширования
Возможности должны потребовать распределенных кэша
Истечений срока
Вытеснений
Кэширование реляционных данных
Синхронизация кэша с других сред
Синхронизация базы данных
Read-Through
Записи по, запись за
Запрос кэша
Передача событий
Кэш производительность и масштабируемость
Обеспечение доступности
Производительность
Получение популярности
Если вы разработкой, веб-службы или приложением для высокопроизводительных вычислений (HPC), вы вероятность столкнуться масштабируемости основные проблемы, попробуйте масштабирования и поместить несколько нагрузки на приложение. С помощью XML (веб-службы) приложения, узкие места возникают в хранилища данных. Первый — данные приложения, находящиеся в базе данных, а другой — XML (веб-службы) данные состояния сеанса, которые обычно хранятся в одном из трех режимов (InProc, StateServer или SqlServer), предоставленный корпорацией Майкрософт. Все три возникают проблемы основных масштабируемости.
Веб-службы обычно не используется состояние сеанса но они имеют масштабируемости узких мест, когда доходит до данных приложения. Подобно XML (веб-службы) приложений, веб-служб размещенных в IIS и развернуты в веб-ферме для обеспечения масштабируемости.
HPC приложения, предназначенные для обработки больших параллельных также имеют проблемы масштабируемости, поскольку хранилище данных не поддерживает масштабирования таким же образом. (Также называемые вычисления сетки) HPC традиционно использовать Java, но как доли рынка прибыли .NET все более широкое HPC приложений также. Развертывать приложения HPC сотен, и иногда тысячи компьютеров для параллельной обработки, и они часто необходимо работать с большими объемами данных и совместное использование промежуточные результаты с другими компьютерами. Приложения HPC используйте базы данных или общей файловой системы в качестве хранилища данных и оба эти не выполнять масштабирование очень хорошо.
Распределенные кэширования
Кэширование — это известный концепция миров оборудования и программного обеспечения. Традиционно кэширование был изолированный механизм, но это не рабочий больше в большинстве сред, поскольку теперь приложения выполняются на нескольких серверах и в нескольких процессах в пределах каждого сервера.
Распределенных кэширования в памяти является формой кэширования, позволяющий кэш, чтобы охватывать несколько серверов, может увеличиваться в размер и транзакций производственной мощности. Распределенные кэширования стала теперь подходящего по ряду причин. Сначала памяти стал очень дешевое и средства компьютеров с много гигабайт по throwaway ценам. Во-вторых сетевые платы стали очень быстро стандарт теперь 1Gbit везде и gaining traction 10Gbit. Наконец в отличие от базы данных сервера, обычно требующий современного компьютера, распределенные кэширование работает хорошо на нижнем компьютерах затрат (например, тех, которые используются для веб-серверов), который позволяет легко добавить несколько компьютеров.
Распределенные кэширование является масштабируемой, так как архитектуры, он использует. Распространяет свою работу между несколькими серверами, но по-прежнему предоставляет логическое представление одной кэша. Для данных приложения распределенных кэша сохраняет копию подмножества данных в базе данных. Предназначен для временное хранилище, которое может означать часов, дней или недель. В лоте ситуаций постоянно храниться данные, используемые в приложении не нужно. В XML (веб-службы), например, данные сеанса является временные и необходимости возможно несколько минут до нескольких часов максимум.
Аналогично в HPC, большие фрагменты обработки требует хранения промежуточных данных в хранилище данных и также это временный характер. Окончательный результат HPC может храниться в базе данных, однако. Рисунок 1 показывает типичную конфигурацию распределенных кэша на предприятии.
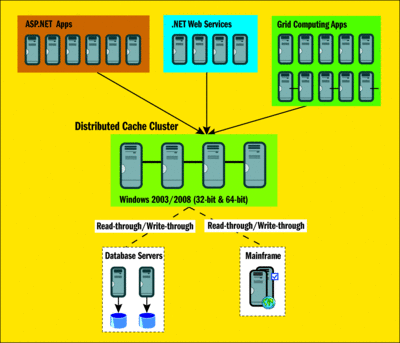
На рис. 1 Shared кэша распределенных по различных приложений в корпоративный (щелкните изображение для его увеличения)
Возможности должны потребовать распределенных кэша
Традиционно разработчики считается кэширование только статические данные, смысл данных, которые никогда не изменяется в течение жизненного цикла приложения. Данных обычно является подмножеством очень маленький — возможно 10 % — данные, которые приложение обрабатывает. Хотя статические данные можно хранить в кэше, реальные значения выведен кэширования динамического или транзакций данных — данные, которые сохраняет изменения каждые несколько минут. Вы по-прежнему его кэширование так как в этот промежуток времени могут выборки десятки раз и сохранить, количество обращений в базе данных. Если умножить тысяч пользователей, которые пытаются одновременно выполнять операции, можно представить себе сколько меньше операций чтения, иметь в базе данных.
Но если кэшировать динамических данных в кэш для некоторых возможностей во избежание проблем целостности данных. Обычно кэша должны иметь возможности для истечения срока действия и исключения элементов, а также другие возможности. Я рассмотрю эти функции в следующих разделах.
Истечений срока
Истечений срока находятся в верхней части списка. Они позволяют указать, сколько данных должны оставаться в кэше перед кэш автоматически удаляет ее. Можно задать два срока действия: абсолютное время истечения срока истечения срока действия и скользящий время (или время простоя).
Если данные в свой кэш также существует в главный источник, известно, эти данные можно изменить в базе данных пользователями или приложениями, которые не могут иметь доступ в кэш. В этом случае данные в кэше становится устаревшей. Если вы возможность оценить, сколько эти данные могут безопасно храниться в кэше, можно задать абсолютное время истечения срока действия — примерно такие как «СрокДействия этот элемент через 10 минут»или «СрокДействия этот элемент в полночь tonight.»
Один интересный вариантов абсолютный срок действия, является ли свой кэш можно загрузить обновленную копию кэшированный элемент непосредственно из источника данных. Это возможно, только если кэш обеспечивает read-through возможности (см. в дальнейших разделах) и позволяет зарегистрировать обработчик read-through, перезагружает кэшированных элементов при возникновении абсолютный срок действия. За исключением несколько коммерческих кэши большинство кэши не поддерживают эту функцию.
Срок действия (скользящий времени) время простоя можно использовать срок действия элемента, если он не используется для заданного периода времени. Можно указать примерно так «Истекает этот элемент.», если никто не читает и обновлениях для 10 минут Этот подход полезен, когда приложению данные временно, но после завершения приложения его использованием необходимо автоматически срок действия кэша. XML (веб-службы) состояние сеанса является хорошим кандидатом простоя время истечения срока действия.
Абсолютное время истечения срока действия поможет избежать ситуаций, имеет в кэш, устаревшую копию данных или копию старее, чем основной копией в базе данных. Простое время истечения срока действия предназначен для очистки кэша после приложения больше не требуются определенные данные. Вместо следить за необходимости очистки приложения позволяют заниматься его кэша.
Вытеснений
Наиболее распределенных кэши являются в памяти и не сохраняются кэша на диске. Это означает, что в большинстве случаев память ограничена, и размер кэша не может выйти за пределы определенных ограничение, которое может быть общей памяти или гораздо меньше, если имеется другим приложениям, работающим на том же компьютере.
В любом случае распределенных кэша должен позволяют указать размер максимального кэша (в идеале в терминах размер памяти). При достижении этого размера кэша, удаление кэшированных элементов, чтобы освободить место для новых, процесс обычно называется вытеснений следует запустить.
Вытеснений выполняются на различных алгоритмов. Наиболее популярные является как минимум недавно использовавшихся (LRU), где эти кэшированные объекты не имеют были затронуты длинной время удаляются. Другой алгоритм является как минимум часто используемый (LFU). Здесь, эти элементы, которые были затронуты наименьшее число раз удаляются. Существует несколько вариантов, но эти две наиболее популярных.
Кэширование реляционных данных
Большинство данные извлекаются из реляционной базы данных, но даже если это не является реляционной характер, это означает, что различные части данных связаны друг с другом — например, объект клиента и объект заказа.
При наличии этих отношений, необходимо обработать их в кэше. Это означает кэша должен знать связь между клиентом и заказа. Если обновление или удалить заказчика из кэша, может потребоваться кэш, чтобы автоматически обновить или удалить связанный заказ объектов из кэша. Это помогает поддерживать целостность данных во многих ситуациях.
Но опять же, если кэш не следить за эти связи, необходимо выполнить его и это делает приложение более громоздким и сложные. Это намного проще, если только кэш данных времени добавляется связана с клиентом заказа и кэша затем знает, что если клиента обновлена или удалена, связанные заказы также иметь обновлены или удалены из кэша.
XML (веб-службы) Кэша есть замечательно функция называется CacheDependency, который позволяет следить за связи между различными кэшированных элементов. Некоторые коммерческие кэши также поддерживает этой функции. Figure 2 shows an example of how ASP.NET Cache works.
На рисунке 2 обновление исправления, связи между кэшированных элементов
using System.Web.Caching;
...
public void CreateKeyDependency()
{
Cache["key1"] = "Value 1";
// Make key2 dependent on key1.
String[] dependencyKey = new String[1];
dependencyKey[0] = "key1";
CacheDependency dep1 = new CacheDependency(null, dependencyKey);
Cache.Insert("key2", "Value 2", dep2);
}
Это многослойных зависимостей, значение, чтобы A может зависеть B и B может зависеть от C. Поэтому, если приложение удаляет C, A и B удаляется из кэша также.
Синхронизация кэша с других сред
Истечений срока и функции зависимости кэша предназначены для помогут сохранить в кэше свежей и правильный. Также необходимо синхронизировать свой кэш с источниками данных, и в кэш нет доступа к что изменения в этих источниках данных отражаются в кэш, чтобы сохранить новую.
Например предположим свой кэш записывается с использованием Microsoft .NET Framework, но имеется приложений Java или C++, изменение данных в главный источник. Нужно, чтобы эти приложения для уведомления в кэш при изменении определенных данных в основной источники так, что кэш может сделать недействительным соответствующего кэшированного элемента.
В идеале свой кэш, должны поддерживать эту возможность. Если нет, это бремя попадает на приложение. Кэш ASP.NET предоставляет эту возможность через CacheDependency, как некоторые коммерческих решений кэширования. Он позволяет указать определенные кэшированного элемента зависит от файла и этот файл обновлены или удалены, кэша обнаруживает это и делает недействительным кэшированного элемента. Аннулирования принудительно элемент, приложение для выборки следующего последнюю копию этого объекта времени приложения необходимо его и не находит в кэше.
Если имеется 100 000 элементов в кэше 10 000 из них, возможно, файл зависимости и, могут иметь 10 000 файлов в специальную папку. Каждый файл имеет специальное имя, связанные с, кэшированный элемент. Когда другие приложения — ли написаны в .NET, или не — изменяет данные в источнике данных master, взаимодействующих приложений для кэша через обновление штампа времени файла.
Синхронизация базы данных
Поскольку базы данных используется совместно несколькими приложениями, а не все приложения имеют доступ к свой кэш, возникает потребность в синхронизации базы данных. Если приложение является единственным приложением, обновление базы данных и его можно также легко обновить кэш, скорее всего не требуется возможность синхронизации базы данных. Но в реальной среде, не всегда так. Изменении третьей стороной или любого приложения базы данных, требуется кэш, чтобы отразить это изменение. Кэш отражает изменения, перезагрузки данных или в крайней мере, не используя старых данных в кэше.
Если кэш старой копии и базы данных новую копию, теперь имеется проблема целостности данных поскольку неизвестно, какие копия находится справа. Конечно база данных всегда находится справа, но не всегда к базе данных. Получить данные из кэша, так как приложение доверяет, кэш всегда будет правильно или что кэш будет недостаточно подходит для своих нужд.
Синхронизация с базой данных может означать аннулирования связанного элемента в кэше, чтобы в следующий раз приложению, он будет выборки из базы данных. Один интересный варианта этот процесс является кэша автоматически перезагружает обновленную копию объекта при изменении данных в базе данных. Однако это возможно, только если свой кэш позволяет предоставить обработчик read-through (см. следующий раздел) и использует его для перезагрузки кэшированного элемента из базы данных. Однако только некоторые типографии кэши поддерживают эту функцию и ни один из свободных те сделать.
XML (веб-службы) Кэша имеет функцию SqlCacheDependency (см. рис. 3), позволяет синхронизировать в кэш с SQL Server 2005/2008 или Oracle 10 g R2 или более поздней версии базы данных — по сути любой базы данных, имеющего .NET CLR, встроенные в его. Некоторые коммерческие кэши также предоставляют такую возможность.
Использование объекта SqlDependency для синхронизации с реляционной базой данных на рисунке 3
using System.Web.Caching;
using System.Data.SqlClient;
...
public void CreateSqlDependency(Customers cust, SqlConnection conn)
{
// Make cust dependent on a corresponding row in the
// Customers table in Northwind database
string sql = "SELECT CustomerID FROM Customers WHERE ";
sql += "CustomerID = @ID";
SqlCommand cmd = new SqlCommand(sql, conn);
cmd.Parameters.Add("@ID", System.Data.SqlDbType.VarChar);
cmd.Parameters["@ID"].Value = cust.CustomerID;
SqlCacheDependency dep = new SqlCacheDependency(cmd);
string key = "Customers:CustomerID:" + cust.CustomerID;
Cache.Insert(key, cust, dep);
}
Кэш XML (веб-службы) SqlCacheDependency позволяет указать строку SQL для сопоставления одного или нескольких строк в таблице в базе данных. Если эта строка никогда не обновляется, СУБД запускает событие .NET, перехватывает свой кэш. Он затем знает, какие кэшированный элемент связанной с этой строкой в базе данных и недействительной, кэшированный элемент.
Одна возможность кэш ASP.NET не предоставляет, выполните некоторые коммерческих решений является синхронизации баз данных на основе опроса. Эта возможность полезна в двух ситуациях. Во-первых Если у вашей СУБД встроенных .NET CLR, не преимущество от SqlCacheDependency. В этом случае было бы замечательно, если кэш может опроса базы данных на настраиваемые интервалы и обнаружения изменений в определенных строк в таблице. Если эти строки были изменены, свой кэш сделает их соответствующие кэшированных элементов.
Вторая ситуация часто изменяется в базе данных и событий .NET становятся слишком неаккуратные. Это происходит потому, что отдельные события .NET для каждого изменения SqlCacheDependency и при наличии тысяч строк, которые часто обновляются, это может легко crowd свой кэш. В таких случаях эффективным является гораздо более полагаться на опрос, где с одной базы данных запроса можно извлекать сотни или тысячи строк, которые были изменены и недействительными соответствующего кэшированных элементов. Конечно опрос создается небольшая задержка в синхронизации (возможно 15–30 секунд), но это допустимо, во многих случаях.
Read-Through
В двух словах, read-through — функция, позволяющая свой кэш непосредственно прочитать данные из источника данных, любой может быть. Написать обработчик read-through и зарегистрировать его в кэш, а затем в кэше вызывает этот обработчик в соответствующие моменты. Пример показан на рис. 4.
Пример на рис. 4 Read-Through обработчика для SQL Server
using System.Web.Caching;
using System.Data.SqlClient;
using Company.MyDistributedCache;
...
public class SqlReadThruProvider : IReadhThruProvider
{
private SqlConnection _connection;
// Called upon startup to initialize connection
public void Start(IDictionary parameters)
{
_connection = new SqlConnection(parameters["connstring"]);
_connection.Open();
}
// Called at the end to close connection
public void Stop() { _connection.Close(); }
// Responsible for loading object from external data source
public object Load(string key, ref CacheDependency dep)
{
string sql = "SELECT * FROM Customers WHERE ";
sql += "CustomerID = @ID";
SqlCommand cmd = new SqlCommand(sql, _connection);
cmd.Parameters.Add("@ID", System.Data.SqlDbType.VarChar);
// Let's extract actual customerID from "key"
int keyFormatLen = "Customers:CustomerID:".Length;
string custId = key.Substring(keyFormatLen,
key.Length - keyFormatLen);
cmd.Parameters["@ID"].Value = custId;
// fetch the row in the table
SqlDataReader reader = cmd.ExecuteReader();
// copy data from "reader" to "cust" object
Customers cust = new Customers();
FillCustomers(reader, cust);
// specify a SqlCacheDependency for this object
dep = new SqlCacheDependency(cmd);
return cust;
}
}
Поскольку распределенные кэша обычно находится вне приложения, она совместно используется несколько экземпляров приложения или даже нескольких приложений. Один важные возможности обработчика read-through является, данных, можно кэшировать выбирается кэш непосредственно из базы данных. Следовательно приложения не обязательно должны иметь код базы данных. Они могут просто выборки данных из кэша, и если в кэше нет его, кэш переходит и принимает из базы данных.
Получить еще более важные преимущества Если read-through возможности объединения с срока действия. При истечении элемента в кэше в кэш автоматически перезагружает его путем вызова обработчика read-through. Сэкономить массу трафик к базе данных с помощью этого механизма. Кэш использует только один поток одного обработки базы данных для перезагрузки данных, из базы данных, тогда как возможно тысяч пользователей, попытка доступа к этой же данные. Если нет возможности read-through эти пользователи бы будет непосредственно в базе данных, inundating базы данных с тысячи параллельных запросов.
Read-Through позволяет установить сетки данных уровня предприятия, то есть хранилище данных, не только масштабируемых, но можно также обновить сам из источников данных master. Это обеспечивает приложений с альтернативный источник из которого читаются данные и избавляет массу давление на вашей базы данных.
Как упоминалось ранее, баз данных всегда являются узким местом в средах транзакции высокого и они становятся узких мест из-за основном избыточные операции чтения, также замедлить операций записи. Наличие кэша, который служит сетки данных корпоративного уровня выше базы данных дает приложения основные повышение производительности и масштабируемости.
Тем не менее, следует помнить, что read-through не заменять для выполнения некоторых сложных объединенных запросов в базе данных. Обычно кэша не позволяют делать этих типов запросов. Read-through возможности работает хорошо отдельного объекта, операции чтения, но не в операции, включающие сложных объединенных запросов, всегда необходимо выполнить в базе данных.
Записи по, запись за
Записи через похоже read-through: предоставить обработчик, а в кэше вызывает обработчика, который записывает данные в базе данных при обновлении кэша. Одно из основных преимуществ том, что приложение не нужно записи непосредственно в базу данных так как кэш не для вас. Это упрощает код приложения, поскольку в кэше, а не приложения, кода доступа к данным.
Обычно приложение выдает обновления кэша (например, установка, добавить или удалить). Кэш обновляется сначала и затем выдает вызова обновления в базу данных через обработчик записи через. Приложение ожидает кэша и базы данных обновляются.
Что делать, если требуется ожидания кэша обновляться, но вы не желаете дождаться базы данных, обновить, поскольку, замедляет производительность приложения? Это происхождения программной записи, которое использует одинаковые записи через обработчик но синхронное обновление кэша и база данных асинхронно. Это означает, что приложение ожидает обновления кэша, но не ожидать базы данных, обновляться.
Вы знаете, обновления базы данных находится в очереди и довольно быстро обновить базу данных, кэш. Это еще один способ повысить производительность приложения. Нужно продолжить запись в базу данных, но зачем ждать? Если в кэше данных, даже не имеют недостаточную последствия другие экземпляры приложения не поиск данных в базы данных, поскольку обновленная кэша, и другие экземпляры приложения будет найти данные в кэше и не нужно перейти к базе данных.
Запрос кэша
Обычно приложение находит объекты в кэше, на основе ключа как хеш-таблица, как вы видели в выше примерах кода источника. Имеется ключ и значение объекта. Но иногда необходимо искать объекты, основанные на атрибуты, кроме ключа. Таким образом свой кэш необходимо предоставить возможность, поиска или запроса в кэше.
Существуют два способа это можно сделать. Один — поиск атрибуты объекта. Другой включает ситуациях в назначенные произвольный теги для кэшированных объектов и требуется найти зависимости в теги. Поиск на основе атрибутов является в настоящее время доступно только в некоторых коммерческих решений через объект языки запросов, но основе тегов поиск доступен в профессиональной кэши и скорость Microsoft.
Предположим, что сохраненный объект клиента. Можно сказать, "Предоставить мне всех клиентов где Город Сан-Франциско"При необходимости только объектов клиента, хотя и имеет свой кэш сотрудников, клиентов, заказы, порядок элементов и многое другое. При выпуске запрос SQL-подобные, такой как показано на рис. 5 находит объекты, удовлетворяющие условиям.
На рисунке 5 с помощью запроса LINQ для поиска элементов в кэше
using Company.MyDistributedCache;
...
public List<Customers> FindCustomersByCity(Cache cache, string city)
{
// Search cache with a LINQ query
List<Customers> custs = from cust in cache.Customers
where cust.City == city
select cust;
return custs;
}
Маркировка позволяет присоединить несколько произвольных тегов определенного объекта и одинаковый тег может быть связано с несколькими объектами. Теги являются обычно основе строку и маркировка также позволяет упорядочивания объектов в группы и затем найти объекты позже с помощью этих тегов или групп.
Передача событий
Может не всегда нужно события распространения в кэше, но является важной возможностью, необходимо знать о. Это хорошая возможность Если распределенных приложений, приложения HPC или несколько приложений, совместного использования данных через кэш. Выполняет какие события распространения является попросите кэша для порождения событий, когда происходят определенные действия в кэше. Приложения могут записывать эти события и предпринять соответствующие действия в ответ.
Предположим, приложение извлечь некоторые объекта из кэша и отображается для пользователя. Может быть заинтересован знать, если всем обновляет или удаляет этот объект из кэша при его отображении. В этом случае будут уведомлены приложения и обновления пользовательского интерфейса.
Это, конечно, очень простой пример. В других случаях может иметь распределенного приложения, где несколько экземпляров приложения создавая данных и другие экземпляры необходимо использовать его. Поставщиков можно информировать потребителей данных при готовности по обработке событий через кэш, получают потребителей. Существует много примерами являются этот тип совместной работы или совместного использования через кэша данных можно сделать через события распространения.
Кэш производительность и масштабируемость
При рассмотрении функций кэширования, описанные в предыдущих разделах, должны не забыт, основной причины, вы thinking использования распределенных кэша, которые для повышения производительности и, более важно повысить масштабируемость приложения. Кроме того поскольку свой кэш выполняется в производственной среде, как сервер, он должен также предоставить высокой доступности.
Масштабируемость — это фундаментальные проблемы распределенных кэша адресов. — Это масштабируемая кэша, который может поддерживать производительности, даже при увеличении нагрузки транзакции на его. Таким образом, при наличии XML (веб-службы) приложения в веб-фермы и роста вашего веб-ферме из пяти веб-серверов на 15 или даже 50 веб-серверах, должны иметь возможность пропорционально увеличить число серверов кэширования и хранить то же время ответа. Это невозможно сделать с базой данных.
Распределенные кэша позволяет избежать проблемы масштабируемости, базы данных обычно сталкивается, поскольку это гораздо проще, характер и СУБД, а также поскольку он использует механизмы различные хранилища (также известный как кэширования топологии) чем СУБД. Сюда входят реплицируются, секционирована и топологии кэша клиента.
В случаях наиболее распределенных кэша имеется два или более серверов кэша, размещение кэша. Я буду использовать термин «cluster кэш»для указания двух или нескольких серверов кэша соединяется вместе один логический кэш формы. Реплицированные кэша копирует всего кэша на каждом сервере кэша в кластер кэша. Это означает, реплицируемых кэша обеспечивает высокую доступность. Все данные в кэше не потеряны любого один кэш сервера отключается, так как другая копия немедленно доступен для приложения. Он также очень эффективную топологию и предоставляет большую масштабируемость, если приложению требуется большое количество операций чтения интенсивно. Добавлении несколько серверов кэша нужно добавить емкость, гораздо более операции чтения кэша кластера. Но реплицированной кэша не идеальный топологии для операций записи интенсивно. Если обновление кэша часто считываются, не используйте топологии репликации.
Секционированные кэша прерывается до кэша разделы и затем сохраняет один раздел на каждом сервере кэша в кластере. Эта топология является масштабируемой для кэширования данные транзакций (при записи в кэше как часто, как чтение). При добавлении нескольких серверов кэша в кластер можно повысить не только емкость транзакции, но также объема кэша, поскольку эти разделы вместе образуют всего кэша.
Многие распределенных кэши предоставляют разновидность секционированные кэша для высокой доступности, где каждая секция также реплицируется таким образом, сервер один кэш содержит секции и копии или резервной копии раздела другого сервера. Таким образом, вы не все данные потеряны если отключается один сервер. Некоторые кэширования решения позволяют создавать более одной копии каждого раздела добавлены надежности.
Другой очень мощный кэширования топология — кэша клиента (также рядом с именем кэш), который очень полезен, если кэш находится в удаленной выделенный уровня кэширования. Идея за кэш клиента в том, каждый клиент хранит рабочий набор кэша закрыть (даже в процессе приложения) на клиентском компьютере. Однако как распределенные кэша имеет синхронизирована с базой данных средствами другой (как см ранее), кэш клиента должна быть синхронизирована с распределенной кэша. Некоторые коммерческие кэширования решения предоставляют этот механизм синхронизации, но наиболее предоставляют только кэш автономного клиента без всякой синхронизации.
Таким же образом распределенных кэша уменьшает трафик к базе данных кэш клиента уменьшает трафик распределенных кэша. Он не только быстрее, чем кэша распределенных поскольку ближе к приложению (и также могут быть InProc), также улучшает масштабируемость распределенных кэша Уменьшение обращений к распределенной кэша. Конечно кэш клиента подход хорошо только для выполнения многих более считывает записывает. Если равно число операций чтения и записи, не следует использовать кэш клиента. Записывает станет медленнее, поскольку теперь нужно обновить кэш клиента и распределенных кэша.
Обеспечение доступности
Поскольку распределенные кэша выполняется как сервера в производственной среде и во многих случаях служит в качестве хранилища данных только для приложения (например, XML (веб-службы) состояния сеанса), кэша должен обеспечения высокой доступности. Это означает, что свой кэш должен быть очень стабильной, так, чтобы никогда не завершает работу и предоставляет возможность изменения конфигурации без остановки в кэш.
Большинство пользователей распределенных кэша требуется кэш для запуска без любые перерывы месяцев одновременно. Когда они имеют остановить кэша, это обычно во время запланированной работы. Именно поэтому высокой доступности так важно для распределенных кэша. Здесь приведены несколько вопросов следует помнить при оценке ли кэширование решение обеспечивает высокую доступность.
- Можно вставленные один из серверов кэша без остановки всего кэша?
- Можно добавить новый сервер кэша без остановки кэша?
- Можно добавить новые клиенты без остановки кэша?
В большинство кэши используется размер указанного максимального кэша так, что кэш не превышает объем данных. Размер кэша основано сколько памяти имеется в системе. Можно изменить, мощности? Предположим, что изначально задан размер кэша должен быть 1 ГБ, но теперь требуется сделать 2 ГБ. Можно сделать, не останавливая кэша?
Которые являются типами нужно рассмотреть вопросы. Сколько из этих изменений конфигурации действительно требуется кэш следует перезапустить? Меньше, тем лучше. Кроме функций кэширования первый критерий за кэша, который может работать в производственной среде — объем кэша собирается позволяют бесперебойной работы.
Производительность
Просто put, если доступ в кэше не быстрее, чем доступ к базе данных, нет необходимости его. Наличие сказал, должны ожидаемых в терминах производительности из хороших распределенных кэша?
В первую очередь следует помнить, является распределенной кэша обычно OutProc или удаленное, поэтому время доступа никогда не будет так же быстро, что автономного кэша InProc (например, кэш ASP.NET). В автономный кэш InProc вероятно можно считывать элементы 150 000 200 000 в секунду (1 КБ размер объекта). OutProc или удаленного кэша этот номер удаляет существенно. В терминах производительности следует ожидать считывает около 20 000 на 30 000 в секунду (1 КБ размер объекта) как пропускная способность сервера отдельных кэша (из всех клиентов, обращения на нем). Часть этого производительность InProc добиться с помощью кэш клиента (в режиме InProc), но это только для операций чтения и не для операций записи. Чтобы получить масштабируемости сохраняйте некоторые производительности, но понижение производительности является по-прежнему гораздо быстрее, чем доступ к базе данных.
Получение популярности
Распределенные кэша, как концепции и как лучший способ подключении быстрый принять решение более популярность. Только несколько лет назад, очень мало кто в пространстве .NET, знал об этом, хотя сообщества Java была заранее из .NET в этой области. Explosive рост транзакций приложения подчеркнул баз данных за пределами их ограничения и распределенных кэширования теперь признается важной частью любой архитектуры масштабируемых приложений.
Khan Iqbal – президент и пропагандист технологии в Alachisoft. Alachisoft предоставляет NCache, ведущими .NET распределенных кэша для увеличение производительности и масштабируемости в корпоративных приложений. В области компьютерных наук из университета Indiana, Bloomington Iqbal имеет ФЛАЖОК. Чтобы достичь ему на iqbal@alachisoft.com .