Проектирование для выживания при сбоях (создание Real-World облачных приложений с помощью Azure)
Рик Андерсон(Rick Anderson),Том Дайкстра (Tom Dykstra)
Скачать проект fix it или скачать электронную книгу
Электронная книга Building Real World Cloud Apps with Azure (Создание реальных облачных приложений с помощью Azure ) основана на презентации, разработанной Скоттом Гатри. В ней описано 13 шаблонов и методик, которые помогут вам успешно разрабатывать веб-приложения для облака. Сведения об электронной книге см. в первой главе.
Одна из вещей, о которых вы должны думать при создании любого типа приложения, особенно в облаке, где его будет использовать множество людей, — это проектирование приложения, чтобы оно могло корректно обрабатывать сбои и продолжать предоставлять как можно больше ценности. Учитывая достаточно времени, все пойдет не так в любой среде или любой программной системе. То, как приложение обрабатывает эти ситуации, определяет, насколько расстроены ваши клиенты и сколько времени вам придется потратить на анализ и устранение проблем.
Типы сбоев
Существует две основные категории сбоев, которые необходимо обрабатывать по-разному.
- Временные сбои самовосстановления, такие как периодические проблемы с сетевым подключением.
- Устойчивые сбои, требующие вмешательства.
Для временных сбоев можно реализовать политику повторных попыток, чтобы гарантировать, что в большинстве случаев приложение восстанавливается быстро и автоматически. Ваши клиенты могут заметить немного больше времени отклика, но в противном случае они не будут затронуты. Мы рассмотрим некоторые способы обработки этих ошибок в разделе Обработка временных сбоев.
Для устойчивых сбоев можно реализовать функции мониторинга и ведения журнала, которые быстро уведомляют вас о возникающих проблемах и упрощают анализ первопричин. В разделе Мониторинг и телеметрия мы расскажем о некоторых способах, которые помогут вам оставаться в курсе таких ошибок.
Область сбоя
Кроме того, необходимо подумать о область сбоя : затрагивается ли один компьютер, вся служба, например База данных SQL или хранилище, или весь регион.

Сбои компьютера
В Azure неисправный сервер автоматически заменяется новым, а хорошо спроектированное облачное приложение автоматически и быстро восстанавливается после такого сбоя. Ранее мы подчеркнули преимущества масштабируемости веб-уровня без отслеживания состояния и простоту восстановления с неработоспособности сервера. Простота восстановления также является одним из преимуществ функций PaaS (платформа как услуга), таких как База данных SQL и Служба приложений Azure веб-приложения. Сбои оборудования встречаются редко, но при возникновении эти службы обрабатывают их автоматически; Вам даже не нужно писать код для обработки сбоев компьютера при использовании одной из этих служб.
Сбои службы
Облачные приложения обычно используют несколько служб. Например, приложение Fix It использует службу База данных SQL, службу хранилища, а веб-приложение развертывается в Служба приложений Azure. Что будет делать приложение в случае сбоя одной из служб, от которые вы зависите? При некоторых сбоях службы лучше всего может оказаться понятное сообщение "Извините, повторите попытку позже". Но во многих сценариях вы можете сделать лучше. Например, если внутреннее хранилище данных не работает, вы можете принять введенные пользователем данные, отобразить сообщение "ваш запрос получен" и временно сохранить входные данные в другом месте; затем, когда необходимая служба снова будет работать, можно получить входные данные и обработать их.
В главе Шаблон работы, ориентированной на очередь , показан один из способов обработки этого сценария. Приложение Fix It хранит задачи в База данных SQL, но при отключении База данных SQL не нужно прекращать работу. В этой главе мы посмотрим, как сохранить входные данные пользователя для задачи в очереди и использовать рабочий процесс для чтения очереди и обновления задачи. Если SQL не работает, возможность создания задач Исправления не затрагивается; рабочий процесс может ждать и обрабатывать новые задачи, когда База данных SQL будет доступен.
Сбои региона
Сбой может завершиться целыми регионами. Стихийное бедствие может разрушить центр обработки данных, его может сплющить метеор, магистральная линия в центре обработки данных может быть перерезана фермером, хороняющим корову с задней шлюхой, и т. д. Если приложение размещено в пострадавшем центре обработки данных, что вы делаете? Вы можете настроить приложение в Azure для одновременного запуска в нескольких регионах, чтобы в случае аварии в одном из них вы продолжите работу в другом регионе. Такие сбои являются крайне редкими случаями, и большинство приложений не проходят через обручи, необходимые для обеспечения непрерывного обслуживания из-за сбоев такого рода. Сведения о том, как обеспечить доступность приложения даже в случае сбоя региона, см. в разделе Ресурсы в конце главы.
Цель Azure — значительно упростить обработку всех таких сбоев, и вы увидите некоторые примеры того, как мы делаем это в следующих главах.
Соглашения об уровне обслуживания
Люди часто слышат о соглашениях об уровне обслуживания (SLA) в облачной среде. В основном это обещания, которые компании делают о том, насколько надежны их услуги. Соглашение об уровне обслуживания 99,9 % означает, что служба будет правильно работать в 99,9 % случаев. Это довольно типичное значение для SLA, и оно звучит как очень большое число, но вы не можете понять, сколько времени простоя на самом деле составляет 0,1 %. Ниже приведена таблица, в которую показано, сколько простоев в разных процентах соглашение об уровне обслуживания составляет более года, месяца и недели.
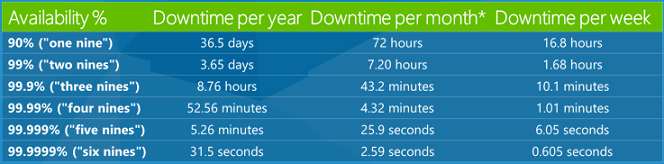
Таким образом, соглашение об уровне обслуживания 99,9 % означает, что ваша служба может быть отключена 8,76 часа в год или 43,2 минуты в месяц. Это больше времени простоя, чем большинство людей понимают. Таким образом, вы, как разработчик, хотите знать, что определенное время простоя возможно, и обрабатывать его корректно. В какой-то момент кто-то будет использовать ваше приложение, и служба будет отключена, и вы хотите свести к минимуму негативное влияние этого на клиента.
Одна вещь, которую вы должны знать о SLA, это то, на какой временной интервал он ссылается: сбрасываются ли часы каждую неделю, каждый месяц или каждый год? В Azure мы сбрасываем часы каждый месяц, что лучше для вас, чем ежегодное соглашение об уровне обслуживания, так как ежегодное соглашение об уровне обслуживания может скрыть плохие месяцы, компенсируя их рядом хороших месяцев.
Конечно, мы всегда стремимся сделать лучше, чем соглашение об уровне обслуживания; обычно вы будете вниз гораздо меньше, чем это. Обещание заключается в том, что если мы когда-либо вниз на больше, чем максимальное время простоя вы можете попросить деньги обратно. Сумма денег, которую вы получите обратно, вероятно, не в полной мере компенсирует вам влияние на бизнес избыточного времени простоя, но этот аспект SLA выступает в качестве политики принудительного применения и позволяет вам знать, что мы относимся к нему очень серьезно.
Составные соглашения об уровне обслуживания
При просмотре соглашений об уровне обслуживания важно учитывать влияние использования нескольких служб в приложении, при этом каждая служба имеет отдельное соглашение об уровне обслуживания. Например, приложение Fix It использует Служба приложений Azure веб-приложения, службу хранилища Azure и База данных SQL. Вот их номера SLA на дату написания этой электронной книги в декабре 2013 года:
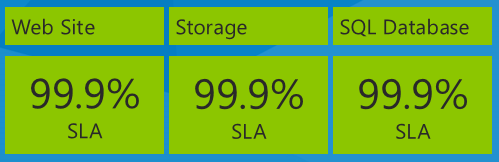
Какое максимальное время простоя вы ожидаете для приложения на основе этих соглашений об уровне обслуживания? Вы можете подумать, что время простоя будет равно худшему проценту SLA, или 99,9% в этом случае. Это было бы верно, если бы все три службы всегда завершали сбой одновременно, но это не обязательно то, что происходит на самом деле. Каждая служба может работать независимо друг от друга в разное время, поэтому необходимо вычислить составное соглашение об уровне обслуживания путем умножения отдельных чисел соглашения об уровне обслуживания.
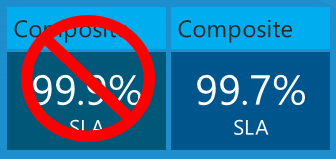
Таким образом, ваше приложение может работать не только на 43,2 минуты в месяц, но и в 3 раза больше, 108 минут в месяц и по-прежнему находиться в пределах SLA Azure.
Эта проблема не является уникальной для Azure. На самом деле мы предоставляем лучшие соглашения об уровне обслуживания для облака из любой доступной облачной службы, и у вас будут аналогичные проблемы, с которыми вы будете сталкиваться при использовании облачных служб любого поставщика. Здесь важно подумать о том, как можно корректно спроектировать приложение для обработки неизбежных сбоев службы, так как они могут происходить достаточно часто, чтобы повлиять на клиентов или пользователей.
Соглашения об уровне обслуживания в облаке по сравнению с корпоративным временем простоя
Люди иногда говорят: "В моем корпоративном приложении у меня никогда не возникает таких проблем". Если вы спросите, сколько простоя в месяц у них на самом деле, они обычно говорят: "Ну, это случается иногда". И если вы спросите, как часто, они признают, что "Иногда нам нужно создать резервную копию или установить новый сервер или обновить программное обеспечение". Конечно, это отсчитывается как время простоя. Большинство корпоративных приложений, если только они не являются критически важными, на самом деле не работают на большее количество времени, отправляемого нашими соглашениями об уровне обслуживания. Но когда это ваш сервер и ваша инфраструктура, и вы отвечаете за него и управляете им, вы, как правило, чувствуете меньше тоской по поводу времени простоя. В облачной среде вы зависите от кого-то другого и не знаете, что происходит, поэтому вы можете больше беспокоиться об этом.
Когда предприятие достигает больше времени доступности, чем вы получаете от облачного SLA, они делают это, тратя гораздо больше денег на оборудование. Облачная служба может сделать это, но придется платить гораздо больше за свои службы. Вместо этого вы используете экономичное обслуживание и проектируете программное обеспечение таким образом, чтобы неизбежные сбои приводили к минимальным сбоям для клиентов. Ваша работа в качестве разработчика облачных приложений заключается не столько в том, чтобы избежать сбоев, сколько во избежание катастрофы, и вы делаете это, сосредоточившись на программном обеспечении, а не на оборудовании. В то время как корпоративные приложения стремятся максимально увеличить среднее время между сбоями, облачные приложения стремятся свести к минимуму среднее время восстановления.
Не все облачные службы имеют соглашения об уровне обслуживания
Имейте в виду также, что не каждая облачная служба даже имеет соглашение об уровне обслуживания. Если ваше приложение зависит от службы без гарантии времени работы, вы можете находиться в отключении гораздо дольше, чем вы могли себе представить. Например, если вы включите вход на сайт с помощью поставщика социальных сетей, такого как Facebook или Twitter, проверка с поставщиком услуг, чтобы узнать, есть ли соглашение об уровне обслуживания, и вы можете обнаружить, что его нет. Но если служба проверки подлинности выходит из строя или не может поддерживать объем запросов, которые вы отправляете на нее, ваши клиенты будут заблокированы в вашем приложении. Вы можете быть вниз в течение нескольких дней или дольше. Создатели одного нового приложения ожидали сотни миллионов загрузок и взяли зависимость от проверки подлинности Facebook, но не поговорили с Facebook, прежде чем начать жить и обнаружили слишком поздно, что не было SLA для этой службы.
Не все простои учитываются в соглашениях об уровне обслуживания
Некоторые облачные службы могут намеренно запретить службу, если приложение чрезмерно их использует. Это называется регулированием. Если служба имеет соглашение об уровне обслуживания, оно должно указать условия, при которых вы можете быть отрегулировать, а в структуре приложения следует избегать этих условий и соответствующим образом реагировать на регулирование, если это произойдет. Например, если запросы к службе начинают завершаться сбоем при превышении определенного числа в секунду, необходимо убедиться, что автоматические повторные попытки не выполняются так быстро, чтобы они привели к продолжению регулирования. Мы подробнее поговорим о регулировании в разделе Обработка временных сбоев.
Итоги
Эта глава поможет вам понять, почему реальное облачное приложение должно быть разработано для корректного выживания при сбоях. Начиная со следующей главы, оставшиеся в этой серии шаблоны подробно описывают некоторые стратегии, которые можно использовать для этого:
- Хороший мониторинг и телеметрия, чтобы вы быстро узнали о сбоях, требующих вмешательства, и у вас есть достаточные сведения для их устранения.
- Обрабатывайте временные сбои путем реализации интеллектуальной логики повторных попыток, чтобы приложение автоматически восстанавливалось, когда это возможно, и возвращалось к логике автоматического выключения , когда это не удается.
- Используйте распределенное кэширование , чтобы свести к минимуму пропускную способность, задержку и проблемы с подключением к базе данных.
- Реализуйте слабую связь с помощью шаблона работы, ориентированного на очереди, чтобы внешний интерфейс приложения продолжал работать при отключении серверной части.
Ресурсы
Дополнительные сведения см. в последующих разделах этой электронной книги и в следующих ресурсах.
Документация.
- Отказоустойчивость. Руководство по устойчивым облачным архитектурам. Технический документ Марка Меркури, Ульриха Хомана и Эндрю Таунхилла. Версия веб-страницы серии видео FailSafe.
- Рекомендации по проектированию служб Large-Scale в Azure Облачные службы. Технический документ Марка Симмса и Майкла Томасси.
- Техническое руководство по обеспечению непрерывности бизнес-процессов Azure. Технический документ ПатрикА Уиклайна и Джейсона Рота.
- Аварийное восстановление и высокий уровень доступности для приложений Azure. Технический документ Майкла Маккеоуна, Хану Коммалапати и Джейсона Рота.
- Шаблоны и методики Майкрософт — руководство по Azure. См. руководство по развертыванию нескольких центров обработки данных, шаблон автоматического выключения.
- Поддержка Azure — соглашения об уровне обслуживания.
- Непрерывность бизнес-процессов в базе данных Azure SQL. Документация по База данных SQL функциям высокого уровня доступности и аварийного восстановления.
- Высокий уровень доступности и аварийное восстановление для SQL Server в Azure Виртуальные машины.
Видеоролики:
- FailSafe: создание масштабируемых, устойчивых Облачные службы. Серия из девяти частей Ульрих Хоманн, Марк Меркури и Марк Симмс. Представляет высокоуровневые концепции и принципы архитектуры очень доступным и интересным способом, на основе историй, взятых из опыта группы технической поддержки Майкрософт (CAT) с реальными клиентами. В эпизодах 1 и 8 подробно приводятся причины разработки облачных приложений, чтобы выдержать сбои. См. также последующее обсуждение регулирования в эпизоде 2, начиная с 49:57, обсуждение точек сбоя и режимов сбоя в эпизоде 2, начиная с 56:05, и обсуждение выключателей цепи в эпизоде 3, начиная с 40:55.
- Большое здание: уроки, извлеченные от клиентов Azure— часть II. Марк Симмс рассказывает о проектировании на основе сбоев и инструментировании всего. Похожа на серию Failsafe, но в ней подробно описаны инструкции.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по