Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Область применения: Azure Stack HCI, версии 22H2 и 21H2; Windows Server 2022, Windows Server 2019
В этой статье содержатся рекомендации по планированию томов кластера в соответствии с потребностями рабочих нагрузок в производительности и емкости, включая выбор файловой системы, типа устойчивости и размера.
Note
Storage Spaces Direct не поддерживает файловый сервер для общего использования. Если вам нужно запустить файловый сервер или другие универсальные службы в Storage Space Direct, настройте его на виртуальных машинах.
Обзор: Что такое объемы
Тома — это место, где вы размещаете файлы, необходимые для рабочих нагрузок, такие как VHD или VHDX-файлы для Hyper-V виртуальных машин. Тома объединяют диски в пуле носителей, чтобы обеспечить отказоустойчивость, масштабируемость и производительность Storage Spaces Direct — технологии программно-определяемого хранилища, лежащей в основе Azure Stack HCI и Windows Server.
Note
Термин «том» используется для обозначения тома и виртуального диска под ним, включая функции, предоставляемые другими встроенными функциями Windows, такими как Cluster Shared Volumes (CSV) и ReFS. Понимание этих различий на уровне реализации не является необходимым для успешного планирования и развертывания локальных дисковых пространств.
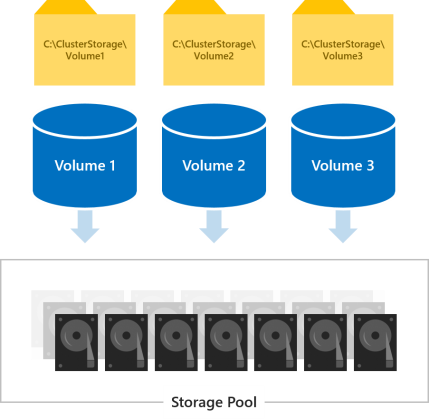
Все тома доступны всем серверам кластера одновременно. Once created, they show up at C:\ClusterStorage\ on all servers.

Выбор количества создаваемых объемов
Мы рекомендуем сделать количество томов кратным количеству серверов в кластере. Например, если у вас 4 сервера, вы получите более стабильную производительность при 4 томах, чем при 3 или 5. Это позволяет кластеру равномерно распределять «владение» томами (один сервер обрабатывает оркестрацию метаданных для каждого тома) между серверами.
Мы рекомендуем ограничить общее количество томов до 64 томов на кластер.
Выбор файловой системы
Мы рекомендуем использовать новую отказоустойчивую файловую систему (ReFS) для локальных дисковых пространств. ReFS — это передовая файловая система, специально разработанная для виртуализации и предлагающая множество преимуществ, включая значительное повышение производительности и встроенную защиту от повреждения данных. Он поддерживает почти все ключевые функции NTFS, включая дедупликацию данных в Windows Server версии 1709 и более поздних. Дополнительные сведения см. в таблице сравнения функций ReFS.
Если для рабочей нагрузки требуется функция, которую ReFS еще не поддерживает, можно использовать NTFS.
Tip
Тома с разными файловыми системами могут сосуществовать в одном кластере.
Выбор типа устойчивости
Тома в локальных дисковых пространствах обеспечивают устойчивость для защиты от проблем с оборудованием, таких как сбои дисков или серверов, а также для обеспечения непрерывной доступности во время обслуживания сервера, например при обновлении программного обеспечения.
Note
Выбор типов устойчивости не зависит от типов дисков.
С двумя серверами
При наличии двух серверов в кластере можно использовать двустороннее зеркальное отображение или вложенную устойчивость.
При двустороннем зеркалировании сохраняются две копии всех данных, по одной копии на дисках каждого сервера. Эффективность хранения составляет 50 процентов; Чтобы записать 1 ТБ данных, необходимо иметь не менее 2 ТБ физической емкости хранилища в пуле носителей. Двустороннее зеркалирование может безопасно допускать один сбой оборудования за раз (один сервер или диск).
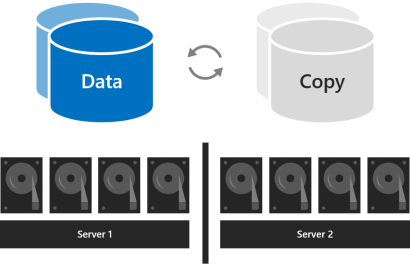
Вложенная устойчивость обеспечивает устойчивость данных между серверами с помощью двустороннего зеркалирования, а затем добавляет устойчивость внутри сервера с помощью двустороннего зеркалирования или четности с зеркальным ускорением. Вложение обеспечивает устойчивость данных даже при перезапуске или недоступности одного сервера. Его эффективность хранения составляет 25 процентов при вложенном двустороннем зеркалировании и около 35–40 процентов при вложенном зеркальном ускорении четности. Вложенная устойчивость может безопасно допускать два сбоя оборудования одновременно (два диска или сервер и диск на оставшемся сервере). Из-за такой дополнительной устойчивости данных рекомендуется использовать вложенную устойчивость в производственных развертываниях кластеров с двумя серверами. For more info, see Nested resiliency.

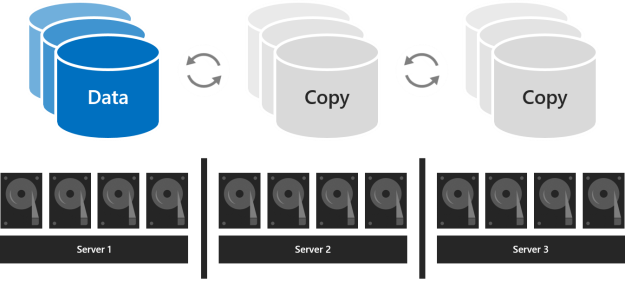
С тремя серверами
При работе с тремя серверами следует использовать трехстороннее зеркалирование для повышения отказоустойчивости и производительности. Трехстороннее зеркалирование сохраняет три копии всех данных, по одной копии на дисках каждого сервера. Его эффективность хранения составляет 33,3 процента — для записи 1 ТБ данных требуется не менее 3 ТБ физической емкости хранилища в пуле хранения. Трехстороннее зеркалирование может безопасно допускать как минимум две проблемы с оборудованием (диском или сервером) одновременно. Если 2 узла становятся недоступными, пул носителей теряет кворум, так как 2/3 дисков недоступны, а виртуальные диски недоступны. Однако один из узлов может выйти из строя, и один или несколько дисков на другом узле могут выйти из строя, а виртуальные диски останутся в сети. Например, если вы перезагрузите один сервер при внезапном сбое другого диска или сервера, все данные остаются безопасными и постоянно доступными.
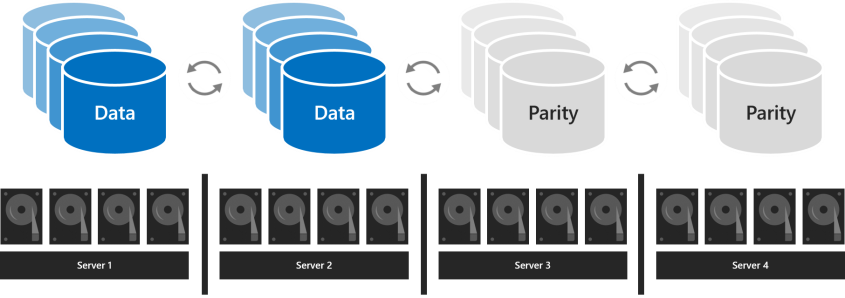
С четырьмя и более серверами
При использовании четырех или более серверов для каждого тома можно выбрать, следует ли использовать трехстороннее зеркалирование, двойную четность (часто называемую «стирающим кодированием») или смешивать их с помощью четности с зеркальным ускорением.
Двойная четность обеспечивает такую же отказоустойчивость, как и трехстороннее зеркалирование, но с более высокой эффективностью хранения. При наличии четырех серверов эффективность хранения данных составляет 50,0 процента; Для хранения 2 ТБ данных требуется 4 ТБ физической емкости хранилища в пуле носителей. Это увеличивает эффективность хранения данных до 66,7% при использовании семи серверов и сохраняет эффективность хранения данных до 80,0%. Компромисс заключается в том, что кодирование четности требует больших вычислительных ресурсов, что может ограничить его производительность.
Выбор типа устойчивости зависит от требований к производительности и емкости для вашей среды. Ниже приведена таблица, в которой приведены сводные данные о производительности и эффективности хранения данных для каждого типа устойчивости.
| Resiliency type | Capacity efficiency | Speed |
|---|---|---|
| Mirror |

Трехстороннее зеркало: 33% Two-way-mirror: 50% |

Highest performance |
| Mirror-accelerated parity |

Зависит от пропорции зеркала и четности |

Намного медленнее, чем зеркало, но до двух раз быстрее, чем двойная четность Лучше всего подходит для больших последовательных операций записи и чтения |
| Dual-parity |

4 сервера: 50% 16 серверов: до 80% |

Высочайшая задержка ввода-вывода и загрузка ЦП при записи Лучше всего подходит для больших последовательных операций записи и чтения |
Когда производительность важнее всего
Рабочие нагрузки со строгими требованиями к задержке или с большим количеством смешанных случайных операций ввода-вывода в секунду, такие как базы данных SQL Server или Hyper-V виртуальные машины, чувствительные к производительности, должны выполняться на томах, использующих зеркальное отображение для максимальной производительности.
Tip
Зеркальное отображение быстрее, чем любой другой тип отказоустойчивости. Мы используем зеркальное отображение почти для всех примеров производительности.
Когда производительность имеет наибольшее значение
Рабочие нагрузки с нечастой записью, такие как хранилища данных или «холодное» хранилище, должны выполняться на томах, использующих двойную четность для максимальной эффективности хранения. Некоторые другие рабочие нагрузки, такие как Scale-Out файловый сервер (SoFS), инфраструктура виртуальных рабочих столов (VDI) или другие, которые не создают большого количества быстро дрейфующего случайного трафика ввода-вывода и (или) не требуют наилучшей производительности, также могут использовать двойную четность по вашему усмотрению. Четность неизбежно увеличивает загрузку ЦП и задержку ввода-вывода, особенно при записи, по сравнению с зеркальным отображением.
Когда данные записываются массово
Рабочие нагрузки, которые записывают большие последовательные проходы, такие как целевые объекты архивации или резервного копирования, имеют еще один вариант: один том может сочетать зеркальное отображение и двойную четность. Запись сначала осуществляется в зеркальном разделе, а затем постепенно перемещается в раздел четности. Это ускоряет прием и снижает эффективность использования ресурсов при поступлении больших объемов записи, позволяя кодированию четности, требующей больших вычислительных ресурсов, выполняться в течение более длительного времени. При определении размера порций учитывайте, что количество операций записи, которые происходят одновременно (например, одно ежедневное резервное копирование), должно удобно помещаться в зеркальной части. Например, если вы принимаете 100 ГБ один раз в день, рассмотрите возможность использования зеркального отображения для 150 ГБ до 200 ГБ и двойной четности для остальных.
Итоговая эффективность хранения зависит от выбранных вами пропорций.
Tip
Если вы наблюдаете резкое снижение производительности записи в середине приема данных, это может указывать на то, что зеркальная часть недостаточно велика или что четность с зеркальным ускорением не подходит для вашего варианта использования. Например, если производительность записи снижается с 400 МБ/с до 40 МБ/с, рассмотрите возможность расширения зеркальной части или переключения на трехстороннее зеркало.
Сведения о развертываниях с NVMe, SSD и HDD
При развертывании с двумя типами дисков более быстрые диски обеспечивают кэширование, а более медленные — емкость. Это происходит автоматически — дополнительные сведения см. в разделе Общие сведения о кэше в локальных дисковых пространствах. В таких развертываниях все тома в конечном итоге находятся на дисках одного типа — дисках емкости.
При развертывании со всеми тремя типами дисков кэширование обеспечивают только самые быстрые диски (NVMe), а емкость обеспечивают два типа дисков (SSD и HDD). Для каждого тома можно выбрать, находится ли он полностью на уровне SSD, полностью на уровне HDD или охватывает оба тома.
Important
Мы рекомендуем использовать уровень SSD для размещения наиболее чувствительных к производительности рабочих нагрузок во всех флэш-памяти.
Выбор размера объемов
Мы рекомендуем ограничить размер каждого тома до 64 ТБ в Azure Stack HCI.
Tip
Если вы используете решение для резервного копирования, основанное на службе теневого копирования томов (VSS) и поставщике программного обеспечения Volsnap, как это часто бывает с рабочими нагрузками файловых серверов, ограничение размера тома до 10 ТБ повысит производительность и надежность. Решения для резервного копирования, использующие более новый API Hyper-V RCT и (или) клонирование блоков ReFS и (или) собственные API резервного копирования SQL, имеют емкость до 32 ТБ и более.
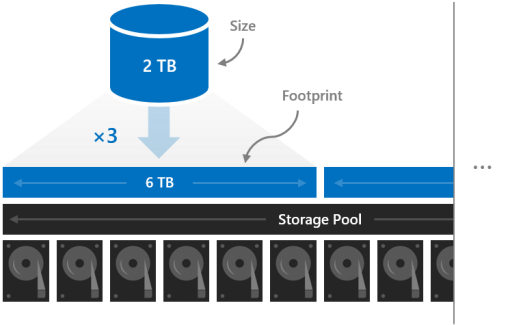
Footprint
Размер тома относится к его полезной емкости, то есть к объему данных, которые он может хранить. This is provided by the -Size parameter of the New-Volume cmdlet and then appears in the Size property when you run the Get-Volume cmdlet.
Size is distinct from volume's footprint, the total physical storage capacity it occupies on the storage pool. Занимаемая площадь зависит от типа устойчивости. Например, тома, использующие трехстороннее зеркальное отображение, имеют занимаемую площадь в три раза больше себя.
Занимаемые места томов должны помещаться в пуле ресурсов хранения.
Reserve capacity
Если оставить некоторую емкость в пуле ресурсов хранения нераспределенной, то можно освободить место для восстановления томов «на месте» после сбоя дисков, что повышает безопасность данных и производительность. При наличии достаточной емкости немедленное параллельное восстановление на месте может восстановить полную отказоустойчивость томов еще до того, как будут заменены неисправные диски. Этот процесс выполняется автоматически.
Мы рекомендуем зарезервировать эквивалент одного диска емкости на сервер, до 4 дисков. Вы можете зарезервировать больше по своему усмотрению, но эта минимальная рекомендация гарантирует, что немедленный параллельный ремонт на месте может быть успешным после выхода из строя любого диска.

Например, если у вас есть 2 сервера и вы используете диски емкостью 1 ТБ, выделите 2 x 1 = 2 ТБ пула в качестве резерва. Если у вас есть 3 сервера и диски емкостью 1 ТБ, выделите 3 x 1 = 3 ТБ в качестве резерва. Если у вас есть 4 или более серверов и дисков емкостью 1 ТБ, выделите 4 x 1 = 4 ТБ в качестве резерва.
Note
В кластерах с дисками всех трех типов (NVMe + SSD + HDD) мы рекомендуем резервировать эквивалент одного SSD плюс одного HDD на сервер, до 4 дисков каждого.
Пример: планирование емкости
Рассмотрим один кластер из четырех серверов. Каждый сервер имеет несколько дисков кэша и шестнадцать дисков емкостью 2 ТБ.
4 servers x 16 drives each x 2 TB each = 128 TB
Из этих 128 ТБ в пуле ресурсов хранения мы выделяем четыре диска, или 8 ТБ, чтобы ремонт на месте мог выполняться без спешки с заменой дисков после их сбоя. Таким образом, в пуле остается 120 ТБ физической емкости хранилища, с помощью которой мы можем создавать тома.
128 TB – (4 x 2 TB) = 120 TB
Предположим, что нам нужно развернуть несколько высокоактивных Hyper-V виртуальных машин, но у нас также есть много холодного хранилища — старых файлов и резервных копий, которые нам нужно сохранить. Поскольку у нас четыре сервера, давайте создадим четыре тома.
Let's put the virtual machines on the first two volumes, Volume1 and Volume2. В качестве файловой системы мы выбираем ReFS (для более быстрого создания и контрольных точек) и трехстороннее зеркалирование для обеспечения отказоустойчивости и максимальной производительности. Let's put the cold storage on the other two volumes, Volume 3 and Volume 4. Мы выбираем NTFS в качестве файловой системы (для дедупликации данных) и двойную четность для обеспечения устойчивости и максимизации емкости.
Мы не обязаны делать все тома одинакового размера, но для простоты давайте — например, мы можем сделать их все по 12 ТБ.
Volume1 and Volume2 each occupy 12 TB x 33.3 percent efficiency = 36 TB of physical storage capacity.
Volume3 and Volume4 each occupy 12 TB x 50.0 percent efficiency = 24 TB of physical storage capacity.
36 TB + 36 TB + 24 TB + 24 TB = 120 TB
Четыре тома точно соответствуют физической емкости хранилища, доступной в нашем пуле. Perfect!

Tip
Вам не нужно сразу создавать все объемы. Вы всегда можете продлить тома или создать новые тома позже.
Для простоты в этом примере используются десятичные единицы измерения (с основанием 10), то есть 1 ТБ = 1 000 000 000 000 байт. Однако объемы хранения в Windows отображаются в двоичных единицах (по основанию 2). Например, каждый диск емкостью 2 ТБ будет отображаться как 1,82 ТиБ в Windows. Аналогичным образом, пул ресурсов хранения емкостью 128 ТБ будет отображаться как 116,41 ТиБ. Это ожидается.
Usage
See Creating volumes.
Next steps
Дополнительные сведения см. также в следующих разделах: