Что такое анализ изображений?
Служба анализа изображений Зрение ИИ Azure может извлекать из ваших изображений самые разные визуальные характеристики. Например, служба может определить, есть ли на изображении содержимое для взрослых, конкретные торговые марки или объекты, или найти человеческие лица.
Последняя версия анализа изображений 4.0, которая в настоящее время является общедоступной, имеет новые функции, такие как синхронное обнаружение OCR и людей. Рекомендуется использовать эту версию.
Вы можете использовать Анализ изображений с помощью пакета SDK для клиентской библиотеки или посредством прямого вызова REST API. Чтобы приступить к работе, ознакомьтесь с этим руководством.
Вы также можете быстро и легко опробовать возможности Анализа изображений в браузере с помощью Vision Studio.
Эта документация включает статьи следующих видов:
- Краткие руководства — пошаговые инструкции, которые помогут вам вызвать службу и быстро получить результат.
- Практические руководства — содержат инструкции для более специфического или специализированного использования службы.
- Тематические статьи — подробно описывают функциональность и возможности службы.
- Учебники — расширенные руководства, которые описывают использование службы в качестве компонента бизнес-решений.
Для более структурированного подхода следуйте модулю обучения для анализа изображений.
Версии анализа изображений
Внимание
Выберите версию API анализа изображений, которая лучше всего соответствует вашим требованиям.
| Версия | Доступные возможности | Рекомендация |
|---|---|---|
| версия 4.0 | Чтение текста, субтитров, плотных подписей, тегов, обнаружения объектов, классификации пользовательских изображений/ обнаружения объектов, людей, интеллектуальной обрезки | Лучшие модели; используйте версию 4.0, если она поддерживает вариант использования. |
| версия 3.2 | Теги, объекты, описания, бренды, лица, тип изображения, цветовая схема, ориентиры, знаменитости, содержимое для взрослых, смарт-обрезка | Более широкий спектр функций; используйте версию 3.2, если вариант использования еще не поддерживается в версии 4.0 |
Рекомендуется использовать API анализа изображений 4.0, если он поддерживает вариант использования. Используйте версию 3.2, если вариант использования еще не поддерживается 4.0.
Кроме того, вам потребуется использовать версию 3.2, если вы хотите сделать подпись изображений, а ресурс Визуального зрения находится за пределами поддерживаемых регионов Azure. Функция подписи изображений в Анализе изображений 4.0 поддерживается только в определенных регионах Azure. Заголовок изображения в версии 3.2 доступен во всех регионах Azure AI Vision. См . сведения о доступности региона.
Анализ изображения
Вы можете проанализировать изображения, чтобы получить сведения о визуальных компонентах и характеристиках. Все функции в этом списке предоставляются API анализа изображений. Чтобы приступить к работе, ознакомьтесь с этим руководством.
| Имя | Описание | Страница концепции |
|---|---|---|
| Настройка модели (только предварительная версия версии 4.0) | Вы можете создавать и обучать пользовательские модели для классификации изображений или обнаружения объектов. Приведите собственные изображения, пометьте их настраиваемыми тегами, а анализ изображений обучает модель, настраиваемую для вашего варианта использования. | Настройка модели |
| Чтение текста из изображений (только версия 4.0) | Предварительная версия 4.0 анализа изображений позволяет извлекать доступный для чтения текст из изображений. По сравнению с асинхронным Компьютерное зрение API чтения 3.2 новая версия предлагает знакомый механизм чтения OCR в унифицированном API с улучшенным производительностью, что упрощает получение OCR вместе с другими аналитическими сведениями в одном вызове API. | OCR для изображений |
| Обнаружение людей в изображениях (только версия 4.0) | Версия 4.0 анализа изображений позволяет обнаруживать людей, отображаемых на изображениях. Координаты ограничивающего прямоугольника каждого обнаруженного человека возвращаются вместе с оценкой достоверности. | Обнаружение людей |
| Создание подписей изображений | Создайте подпись изображения на удобочитаемом языке, используя полные предложения. алгоритмы Компьютерное зрение создают подписи на основе объектов, определенных на изображении. Модель заголовка изображений версии 4.0 является более расширенной реализацией и работает с более широким диапазоном входных изображений. Он доступен только в определенных географических регионах. См . сведения о доступности региона. Версия 4.0 также позволяет использовать плотную подпись, которая создает подробные субтитры для отдельных объектов, найденных на изображении. API возвращает координаты ограничивающего поля (в пикселях) каждого объекта, найденного на изображении, а также подпись. Эту функцию можно использовать для создания описания отдельных частей изображения. 
|
Создание подписей изображений (версия 3.2) (версия 4.0) |
| Обнаружение объектов | Обнаружение объекта похоже на добавление тегов, но API возвращает координаты ограничивающего прямоугольника для каждого примененного тега. Например, если изображение содержит собаку, кота и человека, операция обнаружения перечисляет эти объекты вместе с их координатами на изображении. Эту функциональность можно использовать, чтобы обрабатывать дальнейшие отношения между объектами изображения. Это также позволяет определить множество экземпляров одного тега на изображении. 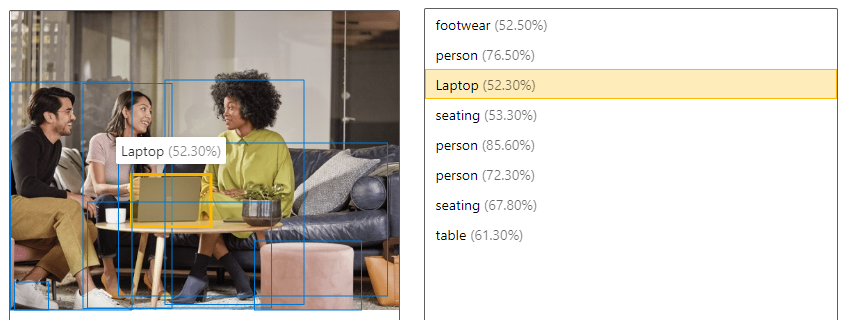
|
Обнаружение объектов (версия 3.2) (версия 4.0) |
| Добавление тегов к визуальным компонентам | Определяйте визуальные компоненты на изображении и добавляйте к ним теги из набора тысяч распознаваемых объектов, живых существ, пейзажей и действий. В случаях, когда теги могут быть неоднозначными или не общеизвестными, в ответ API входят подсказки, уточняющие содержимое тега. Добавление тегов не ограничивается основным предметом, например человеком на переднем плане, но также включает параметр (внутри помещения или снаружи), мебель, инструменты, растения, животных, аксессуары, гаджеты и т. д.
|
Визуальные функции тегов (версия 3.2) (версия 4.0) |
| Получение области интереса / интеллектуальной обрезки | Проанализируйте содержимое изображения, чтобы вернуть координаты интересующей области , которая соответствует указанному пропорции. Компьютерное зрение возвращает координаты ограничивающего поля региона, поэтому вызывающее приложение может изменить исходное изображение по мере необходимости. Модель интеллектуальной обрезки версии 4.0 является более расширенной реализацией и работает с более широким диапазоном входных изображений. Он доступен только в определенных географических регионах. См . сведения о доступности региона. |
Создание эскиза (версия 3.2) (предварительная версия версии 4.0) |
| Обнаружение брендов (только для версии 3.2) | Определяет торговые марки в изображениях или видео из базы данных тысяч глобальных логотипов. Вы можете использовать эту функцию, например, чтобы узнать, какие торговые марки наиболее популярны в социальных сетях или наиболее распространены при размещении медиа-продуктов. | Обнаружение торговых марок |
| Классификация изображения (только для версии 3.2) | Определение и классификация всего изображения с помощью классификации категорий с родительскими или дочерними наследственными иерархиями. Категории могут использоваться отдельно или с новыми моделями добавления тегов. В настоящее время единственным поддерживаемым языком для добавления тегов и классификации изображений является английский. |
Классификация изображения |
| Обнаружение лиц (только для версии 3.2) | Обнаружение лиц на изображении, а также предоставление сведений о каждом обнаруженном лице. Azure AI Vision возвращает координаты, прямоугольник, пол и возраст для каждого обнаруженного лица. Для этих целей также можно использовать отдельный API Распознавания лиц . Его можно использовать для более глубокого анализа, например для идентификации по лицу и определении позы. |
Распознавание лиц |
| Обнаружение типов изображений (только версия 3.2) | Выявление характеристик изображения, например, является ли изображение графическим или же это иллюстрация. | Обнаружение типов изображения |
| Обнаружение содержимого для конкретного домена (только версия 3.2) | Использование модели предметной области для обнаружения и идентификации отдельного предметного содержимого в изображении, например знаменитостей и достопримечательностей. Например, если изображение содержит людей, Azure AI Vision может использовать модель домена для знаменитостей, чтобы определить, обнаружены ли люди на изображении известны знаменитостей. | Обнаружение содержимого, связанного с определенными сферами |
| Обнаружение цветовой схемы (только версия 3.2) | Анализ использования цвета в изображении. Визуальное распознавание искусственного интеллекта Azure может определить, является ли изображение черным и белым или цветным, а для цветовых изображений и определять доминирующие и акцентные цвета. | Обнаружение цветовой схемы |
| Умеренное содержимое в изображениях (только версия 3.2) | Azure AI Vision позволяет обнаруживать содержимое взрослых в изображении и возвращать оценки достоверности для различных классификаций. Порог для обозначения содержимого можно настроить в соответствии с предпочтением пользователя по степени принятия материалов данного характера. | Обнаружение содержимого для взрослых |
Совет
Функции обнаружения текста и объектов чтения можно использовать с помощью службы Azure OpenAI . GPT-4 Turbo с моделью визуального распознавания позволяет общаться с помощником по искусственному интеллекту, который может анализировать общие изображения, а параметр "Улучшение зрения" использует анализ изображений для получения дополнительных сведений об использовании ИИ (доступных для чтения текста и объектов) о изображении. Дополнительные сведения см. в кратком руководстве по GPT-4 Turbo с vision.
Распознавание продуктов (только предварительная версия версии 4.0)
API распознавания продуктов позволяют анализировать фотографии полков в розничном магазине. Вы можете обнаружить наличие или отсутствие продуктов и получить их ограничивающие координаты коробки. Используйте его в сочетании с настройкой модели для обучения модели для идентификации конкретных продуктов. Вы также можете сравнить результаты распознавания продуктов с документом планограммы магазина.
Многомодальные внедрения (только версия 4.0)
Api-интерфейсы многомодальных внедрения обеспечивают векторизацию изображений и текстовых запросов. Они преобразуют изображения в координаты в многомерном векторном пространстве. Затем входящие текстовые запросы также можно преобразовать в векторы, а изображения можно сопоставить с текстом на основе семантической близости. Это позволяет пользователю выполнять поиск по набору изображений с помощью текста без необходимости использовать теги изображений или другие метаданные. Семантическая близость часто дает лучшие результаты в поиске.
2024-02-01 API включает многоязычную модель, которая поддерживает поиск текста на 102 языках. Исходная модель только на английском языке по-прежнему доступна, но ее нельзя объединить с новой моделью в том же индексе поиска. Если векторизованный текст и изображения с помощью модели только на английском языке, эти векторы не будут совместимы с многоязычным текстом и векторами изображений.
Эти API доступны только в определенных географических регионах. См . сведения о доступности региона.
Удаление фона (только предварительная версия версии 4.0)
Анализ изображений 4.0 (предварительная версия) позволяет удалить фон изображения. Эта функция может выводить изображение обнаруженного объекта переднего плана с прозрачным фоном или изображением альфа-матового цвета серого цвета, показывающее непрозрачность обнаруженного объекта переднего плана.
| Исходное изображение | Удаление фона | Альфа-матовый |
|---|---|---|

|

|

|
Лимиты служб
Требования к входным данным
Анализ изображений работает на изображениях, которые отвечают следующим требованиям:
- Изображение должно быть в формате JPEG, PNG, GIF, BMP, WEBP, ICO, TIFF или MPO
- Размер файла изображения должен быть меньше 20 МБ
- Размеры изображения должны быть более 50 x 50 пикселей и менее 16 000 x 16 000 пикселей
Совет
Требования к входным данным для многомодальных внедрения отличаются и перечислены в многомодальных внедрениях.
Поддержка языков
Различные функции анализа изображений доступны на разных языках. См. страницу поддержки языка.
Доступность по регионам
Чтобы использовать API анализа изображений, необходимо создать ресурс Azure AI Vision в поддерживаемом регионе. Функции анализа изображений доступны в следующих регионах:
| Область/регион | Анализ изображения (минус 4.0 субтитры) |
Анализ изображения (включая 4.0 субтитры) |
Распознавание продуктов | Многомодальные внедрения | Удаление фона |
|---|---|---|---|---|---|
| Восточная часть США | ✅ | ✅ | ✅ | ✅ | ✅ |
| Западная часть США | ✅ | ✅ | ✅ | ✅ | |
| Западная часть США 2 | ✅ | ✅ | ✅ | ||
| Центральная Франция | ✅ | ✅ | ✅ | ✅ | |
| Северная Европа | ✅ | ✅ | ✅ | ✅ | |
| Западная Европа | ✅ | ✅ | ✅ | ✅ | |
| Центральная Швеция | ✅ | ✅ | |||
| Северная Швейцария | ✅ | ✅ | |||
| Восточная Австралия | ✅ | ✅ | |||
| Юго-Восточная Азия | ✅ | ✅ | ✅ | ✅ | |
| Восточная Азия | ✅ | ✅ | |||
| Республика Корея, центральный регион | ✅ | ✅ | ✅ | ✅ | |
| Восточная Япония | ✅ | ✅ |
Конфиденциальность и безопасность данных
Как и во всех службах ИИ Azure, разработчики, использующие службу "Визуальное распознавание ИИ Azure", должны учитывать политики Майкрософт по данным клиентов. Дополнительные сведения см. на странице служб ИИ Azure в Центре управления безопасностью Майкрософт.
Следующие шаги
Начните работу с Анализом изображений, изучив краткое руководство по предпочтительному языку разработки:
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по