Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Автоматизация роботизированных процессов (RPA) позволяет организациям автоматизировать повторяющиеся задачи путем оркестрации рабочих процессов в разных системах. В сочетании с Azure Content Understanding RPA может обрабатывать сложные сценарии приема содержимого в документах, изображениях, аудио и видео.
Многие решения RPA предназначены для прямой обработки (STP): автоматизируйте сквозные рабочие процессы с минимальным вмешательством человека. Оценки достоверности и обоснования помогают поддерживать STP, улучшая качество принятия решений и аудита.
Что такое RPA?
RPA автоматизирует повторяющиеся задачи, которые обычно требуют ручной работы, таких как запись данных, обработка документов и интеграция системы.
Пример: Автоматизация обработки счетов— извлечение полей из счетов, проверка итогов и обновление систем ERP (планирование ресурсов предприятия) без вмешательства вручную.
Компоненты решения RPA
Эффективный конвейер RPA для обработки содержимого обычно включает:
Расщепление
Разорвать большие файлы (например, PDF-файлы с несколькими счетами) в отдельные документы.Классификация
Определите типы документов (счет, контракт, квитанция) для маршрутизации в соответствующие анализаторы.Извлечение полей с уверенностью и заземлением
Извлеките структурированные данные, такие как номер счета, дата и общая сумма.
К ключевым выходным данным относятся:-
Извлеченные поля (например,
InvoiceNumber, ,DateTotalAmount) - Оценка достоверности для каждого поля, включение автоматизированного принятия решений
-
Извлеченные поля (например,
- Сведения о заземлении— где поле было определено в источнике (номер страницы, ограничивающее поле или фрагмент текста или ссылка). Это крайне важно для аудита и человеческой проверки.
После обработки и проверки
Применение бизнес-правил (например, итоги должны соответствовать элементам строки, даты должны быть допустимыми).Рецензия и валидация человеком
Активируйте проверку, когда оценки достоверности падают ниже порогового значения или правила дают сбой.Другие шаги
- Маршрутизация: направлять документы в последующие анализаторы или системы.
- Интеграция: отправка проверенных данных в ERP, CRM или другие бизнес-системы.
Архитектурный процесс
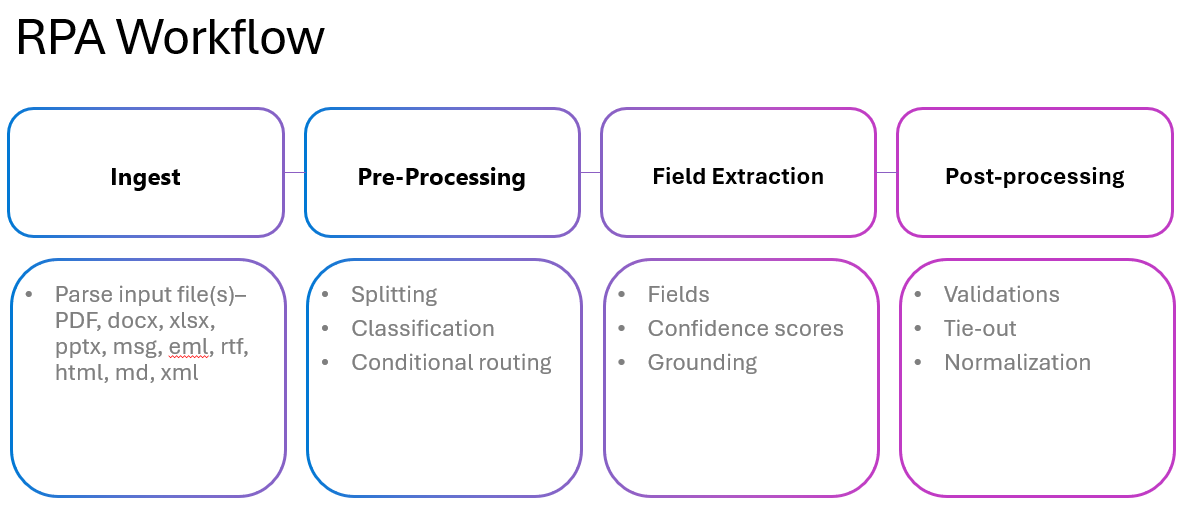
Создание RPA-решения с использованием "Понимания контента".
Понимание содержимого обеспечивает гибкость для определения всего рабочего процесса в одном анализаторе. Вы можете настроить разделение документов, классификацию, извлечение полей и шаги проверки в одном вызове. Этот рабочий процесс можно структурировать как один уровень или с несколькими уровнями в зависимости от требований к автоматизации.
Классификация и извлечение одного уровня
Страховое требование является хорошим примером классификации одного уровня, где каждый пакет утверждений может состоять из формы утверждения и одной или нескольких оценок.
Классификация на нескольких уровнях
Для обработки налогов требуется более сложная классификация, где можно начать на верхнем уровне, классифицируя документ как налоговую форму или запись о расходах. Следующий уровень классификации будет дополнительно классифицировать налоговые документы в конкретный тип, чтобы повысить точность классификации.
Определение анализатора
В этом сценарии вы собираетесь обработать файл, содержащий страховую претензию. Вы ожидаете четыре типа контента:
- Форма заявки: Маршрут к пользовательскому
claimFormанализатору. - Оценки (ремонт автомобиля или повреждение имущества): направляйте каждую оценку анализатору
prebuilt-invoice. - Медицинские отчеты: путь к пользовательскому
medicalReportанализатору. - Полицейский отчет: игнорировать.
Так как этот сценарий специфичен для документа, начните с того, чтобы производить анализ на основе анализатора prebuilt-document.
{
"analyzerId": "insuranceClaim",
"baseAnalyzerId": "prebuilt-document",
"models": {
"completion": "gpt-4.1",
"embedding": "text-embedding-ada-002"
},
"config": {
"enableSegment": true,
"contentCategories": {
"claimForm": {
"description": "The claim form for Zava Insurance.",
"analyzerId": "claimForm"
},
"estimate": {
"description": "The body shop estimate or contractor estimate to fix the property damage.",
"analyzerId": "prebuilt-invoice"
},
"medicalReport": {
"description": "A doctor's assessment or medical report related to injury suffered.",
"analyzerId": "medicalReport"
},
"policeReport": {
"description": "A police or law enforcement report detailing the events that led to the loss."
/* Don't perform analysis for this category. */
}
},
"omitContent": true
}
}
Замечание
В insuranceClaim конфигурации анализатора показано, как направлять различные сегменты документов в предварительно созданные или пользовательские анализаторы. В этом примере анализаторы claimForm и medicalReport необходимо определить отдельно перед использованием. Вы можете ссылаться на анализаторы по их analyzerId или определять их встроенно с помощью свойства analyzer для более точного управления. Кроме того, можно игнорировать определенные типы документов (например policeReport , в этом примере), чтобы оптимизировать затраты на обработку. Этот гибкий подход позволяет адаптировать рабочие процессы классификации, сегментации и извлечения в соответствии с вашими бизнес-требованиями.
После обработки, проверки и нормализации
Анализаторы поддерживают постобработку, например, извлечение только числовой части значения, нормализацию даты до определенного формата или проверку того, что строки складываются в общую сумму. Эти действия можно указать с помощью простых инструкций в описаниях полей.
Оценки достоверности и обоснование
Достоверность и заземление (источник) задаются на уровне поля. Для каждого поля, для которого требуется уверенность и заземление, установите значение estimateSourceAndConfidencetrue.
Инициирование человеческой проверки на основе уровней доверия
После извлечения полей, связанных с ними показателей достоверности и основной информации, вы можете автоматизировать человеческую проверку, задав порог показателей достоверности. Для проверки вручную помечаются только поля с оценкой достоверности ниже этого порога. Этот подход обеспечивает проверку только неопределенных данных, повышая точность и полноту данных, при этом максимизируя сквозную обработку (STP).
Этот процесс выборочной проверки помогает поддерживать высокие показатели автоматизации и гарантирует, что только критические исключения требуют вмешательства вручную.