Получение дополненного поколения с помощью аналитики документов ИИ Azure
Это содержимое относится к: ![]() версии 4.0 (предварительная версия)
версии 4.0 (предварительная версия)
Введение
Получение дополненного поколения (RAG) — это шаблон проектирования, который объединяет предварительно обученную модель большого языка (LLM), например ChatGPT с системой извлечения внешних данных, чтобы создать расширенный ответ, включающий новые данные за пределами исходных обучающих данных. Добавление системы получения информации в приложения позволяет общаться с документами, создавать увлекательные материалы и получать доступ к моделям Azure OpenAI для данных. Кроме того, вы имеете больше контроля над данными, используемыми LLM, как он сформулирует ответ.
Модель макета аналитики документов — это расширенный API анализа документов на основе машинного обучения. Модель макета предлагает комплексное решение для расширенного извлечения содержимого и возможностей анализа структуры документов. С помощью модели макета можно легко извлечь текст и структурные элементы, чтобы разделить большие тела текста на небольшие, значимые фрагменты на основе семантического содержимого, а не произвольных разбиений. Извлеченные сведения можно удобно выводить в формат Markdown, что позволяет определить стратегию семантического фрагментирования на основе предоставленных стандартных блоков.
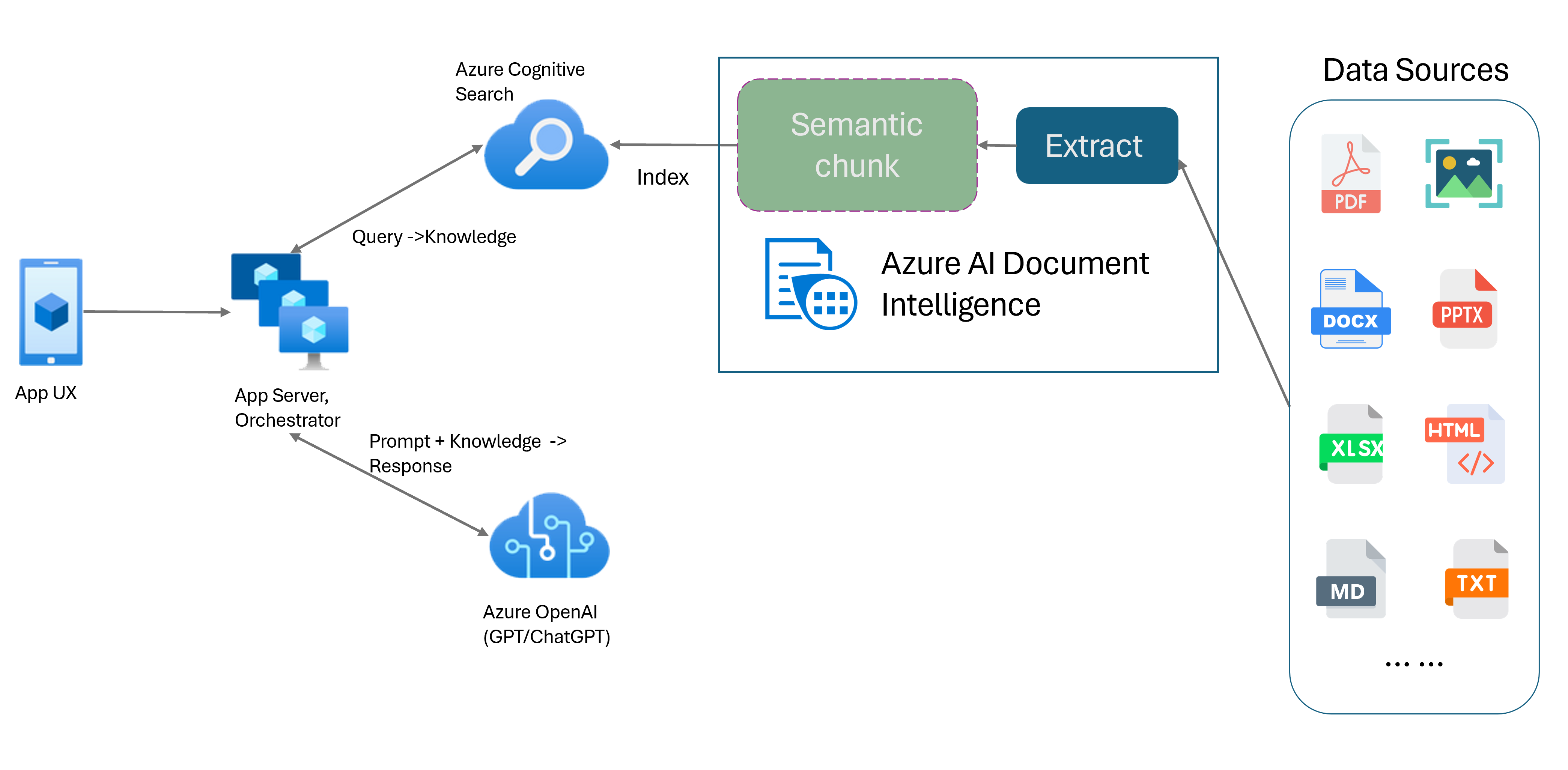
Семантическое фрагментирование
Длинные предложения являются сложными для приложений обработки естественного языка (NLP). Особенно если они состоят из нескольких предложений, сложных фраз существительных или глаголов, относительных предложений и круглых скобок. Точно так же, как и заполнитель, система NLP также должна успешно отслеживать все представленные зависимости. Цель семантического фрагментирования заключается в поиске семантической последовательности фрагментов представления предложения. Затем эти фрагменты можно обрабатывать независимо и перекомбинировать как семантические представления без потери информации, интерпретации или семантической релевантности. Неотъемлемое значение текста используется в качестве руководства для процесса блокирования.
Стратегии блокирования текстовых данных играют ключевую роль в оптимизации ответа RAG и производительности. Фиксированный размер и семантика являются двумя различными методами блокирования:
Блоки фиксированного размера. Большинство стратегий блокирования, используемых в RAG сегодня, основаны на сегментах текста размера исправления, известных как блоки. Блоки фиксированного размера являются быстрыми, простыми и эффективными с текстом, которые не имеют строгой семантической структуры, таких как журналы и данные. Однако не рекомендуется использовать текст, требующий семантического понимания и точного контекста. Характер окна фиксированного размера может привести к разрыву слов, предложений или абзацев, которые препятствуют пониманию и нарушению потока информации и понимания.
Семантическое фрагментирование. Этот метод делит текст на блоки на основе семантического понимания. Границы деления сосредоточены на субъекте предложения и используют значительные вычислительные алгоритмически сложные ресурсы. Однако она имеет уникальное преимущество поддержания семантической согласованности в каждой блоке. Это полезно для задач сводных данных текста, анализа тональности и классификации документов.
Семантическое фрагментирование с помощью модели макета аналитики документов
Markdown — это структурированный и форматированный язык разметки и популярные входные данные для включения семантического фрагментирования в RAG (получение дополненного поколения). Содержимое Markdown из модели макета можно использовать для разделения документов на основе границ абзаца, создания определенных блоков для таблиц и точной настройки стратегии блокирования для улучшения качества созданных ответов.
Преимущества использования модели макета
Упрощенная обработка. Вы можете проанализировать различные типы документов, такие как цифровые и сканированные PDF-файлы, изображения, файлы office (docx, xlsx, pptx) и HTML с одним вызовом API.
Качество масштабируемости и искусственного интеллекта. Модель макета очень масштабируема в оптическом распознавании символов (OCR), извлечении таблиц и анализе структуры документов. Он поддерживает 309 печатных и 12 рукописных языков, обеспечивая более качественные результаты, вызванные возможностями искусственного интеллекта.
Совместимость больших языковых моделей (LLM). Выходные данные модели макета Markdown удобны для LLM и упрощают простую интеграцию с рабочими процессами. Вы можете превратить любую таблицу в документ в формат Markdown и избежать обширного анализа документов для повышения понимания LLM.
Текстовое изображение, обработанное с помощью Document Intelligence Studio и выходных данных в MarkDown с помощью модели макета

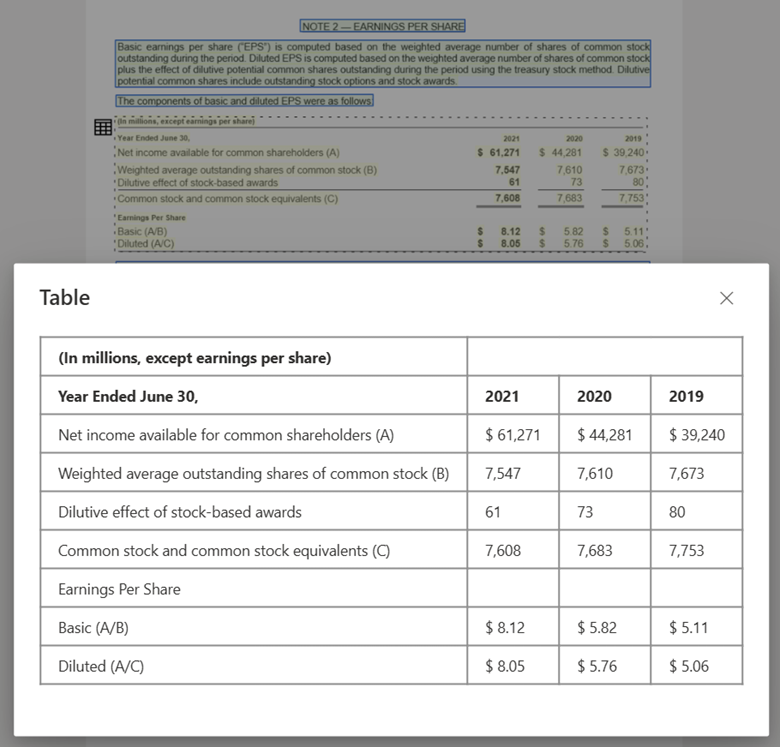
Изображение таблицы, обработанное с помощью Document Intelligence Studio с помощью модели макета
Начать
Модель макета аналитики документов 2024-02-29-preview и 2023-10-31-preview поддерживает следующие варианты разработки:
Готовы начать?
Document Intelligence Studio
Чтобы приступить к работе, ознакомьтесь с кратким руководством по Document Intelligence Studio. Затем можно интегрировать функции аналитики документов с собственным приложением с помощью предоставленного примера кода.
Начните с модели макета. Для использования RAG в студии необходимо выбрать следующие параметры анализа:
**Required**- Запуск диапазона анализа → текущем документе.
- Диапазон страниц → все страницы.
- Стиль формата вывода → Markdown.
**Optional**- Также можно выбрать соответствующие необязательные параметры обнаружения.
Выберите Сохранить.
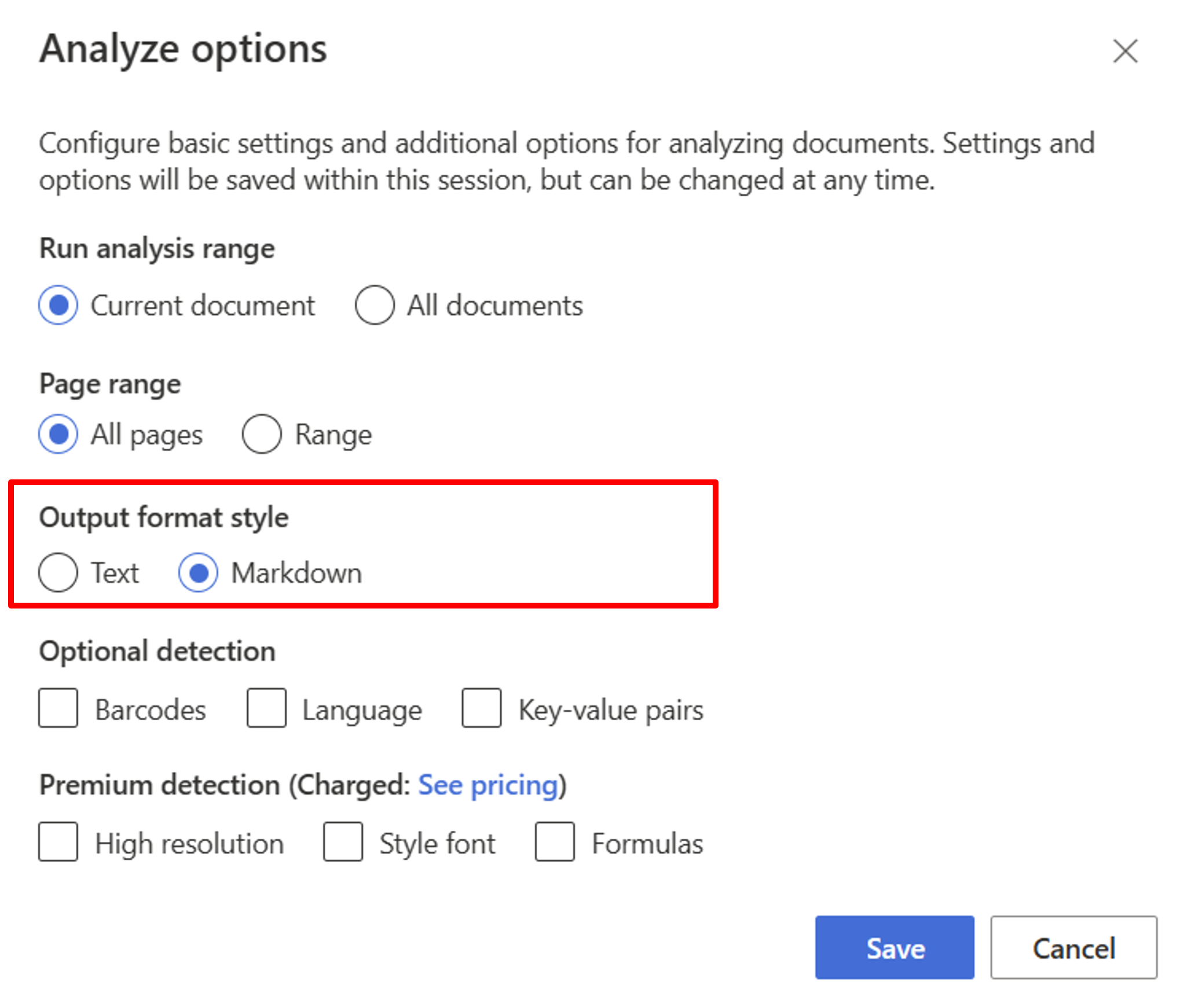
Нажмите кнопку "Выполнить анализ", чтобы просмотреть выходные данные.

ПАКЕТ SDK или REST API
Вы можете следовать краткому руководству по анализу документов для предпочитаемого пакета SDK для языка программирования или REST API. Используйте модель макета для извлечения содержимого и структуры из документов.
Вы также можете ознакомиться с репозиториями GitHub для примеров кода и советов по анализу документа в формате вывода markdown.
Создание чата документов с семантическим фрагментированием
Azure OpenAI для данных позволяет запускать поддерживаемый чат в документах. Azure OpenAI для данных применяет модель макета аналитики документов для извлечения и анализа данных документа путем фрагментирования длинного текста на основе таблиц и абзацев. Вы также можете настроить стратегию блокирования с помощью примеров скриптов Azure OpenAI, расположенных в репозитории GitHub.
Аналитика документов Azure теперь интегрирована с LangChain в качестве одного из загрузчиков документов. Его можно использовать для легкой загрузки данных и выходных данных в формат Markdown. Дополнительные сведения см . в нашем примере кода , который показывает простую демонстрацию шаблона RAG с помощью аналитики документов Azure AI в качестве загрузчика документов и поиска Azure в качестве извлекателя в LangChain.
В чате с примером кода акселератора решений данных демонстрируется комплексный пример шаблона RAG. Он использует поиск ИИ Azure в качестве извлекателя и аналитики документов Azure для загрузки документов и семантического фрагментирования.
Вариант использования
Если вы ищете определенный раздел в документе, вы можете использовать семантические блоки, чтобы разделить документ на небольшие блоки на основе заголовков разделов, помогающих найти раздел, который вы ищете быстро и легко:
# Using SDK targeting 2024-02-29-preview or 2023-10-31-preview, make sure your resource is in one of these regions: East US, West US2, West Europe
# pip install azure-ai-documentintelligence==1.0.0b1
# pip install langchain langchain-community azure-ai-documentintelligence
from azure.ai.documentintelligence import DocumentIntelligenceClient
endpoint = "https://<my-custom-subdomain>.cognitiveservices.azure.com/"
key = "<api_key>"
from langchain_community.document_loaders import AzureAIDocumentIntelligenceLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
# Initiate Azure AI Document Intelligence to load the document. You can either specify file_path or url_path to load the document.
loader = AzureAIDocumentIntelligenceLoader(file_path="<path to your file>", api_key = key, api_endpoint = endpoint, api_model="prebuilt-layout")
docs = loader.load()
# Split the document into chunks base on markdown headers.
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
docs_string = docs[0].page_content
splits = text_splitter.split_text(docs_string)
splits
Следующие шаги
Дополнительные сведения об аналитике документов ВИ Azure.
Узнайте, как обрабатывать собственные формы и документы с помощью Document Intelligence Studio.
Выполните краткое руководство по анализу документов и начните создавать приложение для обработки документов на выбранном языке разработки.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по