Создание и обучение пользовательской модели извлечения
Это содержимое относится к: версии 4.0 (предварительная версия) | Предыдущие версии: ![]()
![]() v3.1 (GA) версии 3.0 (GA)
v3.1 (GA) версии 3.0 (GA)![]()
![]() версии 2.1
версии 2.1
Внимание
Пользовательское поведение обучения модели создания отличается от пользовательского шаблона и обучения нейронной модели. В следующем документе рассматривается обучение только для пользовательских шаблонов и нейронных моделей. Рекомендации по пользовательскому генерируемой модели см. в разделе "Пользовательская модель создания"
Для начала работы с пользовательскими моделями аналитики документов требуется несколько обучающих документов. Если у вас есть как минимум пять документов, вы можете приступать к обучению пользовательской модели. Вы можете обучить пользовательскую модель шаблона (настраиваемую форму) или пользовательскую нейронную модель (пользовательский документ) или пользовательскую модель шаблона (настраиваемую форму). В этом документе описан процесс обучения пользовательских моделей.
Требования к входным данным настраиваемой модели
Сначала убедитесь, что набор обучающих данных соответствует требованиям к входным данным для аналитики документов.
Поддерживаемые форматы файлов:
Модель PDF Изображение: JPEG/JPG, ,BMPPNGTIFFHEIFMicrosoft Office:
Word (), Excel (XLSXDOCX), PowerPoint (PPTX), HTMLЧитать ✔ ✔ ✔ Макет ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Документ общего назначения ✔ ✔ Готовое ✔ ✔ Настраиваемая функция извлечения ✔ ✔ Настраиваемая классификация ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) Для получения наилучших результатов предоставьте одну четкую фотографию или скан-копию документа высокого качества.
Для PDF и TIFF можно обрабатывать до 2000 страниц (с подпиской на бесплатный уровень только первые две страницы обрабатываются).
Размер файла для анализа документов составляет 500 МБ для платного уровня (S0) и
4МБ для бесплатного уровня (F0).Размеры изображения должны составлять от 50 пикселей до 50 пикселей и 10 000 пикселей x 10 000 пикселей.
Если PDF-файлы заблокированы паролем, перед отправкой необходимо снять блокировку.
Минимальная высота извлекаемого текста составляет 12 пикселей для изображения размером 1024 x 768 пикселей. Это измерение соответствует тексту
8точки в 150 точек на дюйм (DPI).Для обучения пользовательской модели максимальный объем обучающих данных составляет 500 страниц для пользовательской модели шаблона и 50 000 страниц для пользовательской нейронной модели.
Для обучения пользовательской модели извлечения общий размер обучающих данных составляет 50 МБ для модели шаблона и
1ГБ для нейронной модели.Для обучения пользовательской модели классификации общий размер обучающих данных составляет
1ГБ не более 10 000 страниц. Для 2024-07-31-preview и более поздних версий общий размер обучающих данных составляет2ГБ с максимальным количеством 10 000 страниц.
Советы касательно данных для обучения
Ниже приведены советы по дополнительной оптимизации набора данных для обучения:
- Используйте текстовые pdf-документы вместо документов на основе изображений. Отсканированные PDF-файлы обрабатываются как изображения.
- Используйте примеры, которые имеют все поля, завершенные для форм с полями ввода.
- Используйте формы с разными значениями в каждом поле.
- Используйте более крупный набор данных (10–15 изображений), если образы форм имеют более низкое качество.
Отправка данных для обучения
После сбора набора форм или документов для обучения необходимо отправить его в контейнер хранилища BLOB-объектов Azure. Если вы не знаете, как создать учетную запись хранения Azure с контейнером, обратитесь к краткому руководству по работе со службой хранилища Azure на портале Azure. Используйте бесплатную ценовую категорию (F0), чтобы опробовать службу, а затем выполните обновление до платного уровня для рабочей среды.
Видео: обучение пользовательской модели
- После сбора и отправки обучаемого набора данных вы можете обучить настраиваемую модель. В следующем видео мы создадим проект и рассмотрим некоторые основы успешной маркировки и обучения модели.
Создание проекта в Студии аналитики документов
Document Intelligence Studio предоставляет и оркестрирует все вызовы API, необходимые для завершения набора данных и обучения модели.
Начните с перехода к Студии аналитики документов. При первом использовании Студии необходимо инициализировать подписку, группу ресурсов и ресурс. Затем следуйте предварительным требованиям для пользовательских проектов , чтобы настроить Студию для доступа к набору данных для обучения.
В Студии выберите плитку "Пользовательская модель извлечения" и нажмите кнопку "Создать проект ".
create projectВ диалоговом окне укажите имя проекта, необязательно описание и нажмите кнопку "Продолжить".На следующем шаге рабочего процесса выберите или создайте ресурс аналитики документов перед продолжением.
Внимание
Пользовательские нейронные модели доступны только в нескольких регионах. Если вы планируете обучить нейронную модель, выберите или создайте ресурс в одном из поддерживаемых регионов.
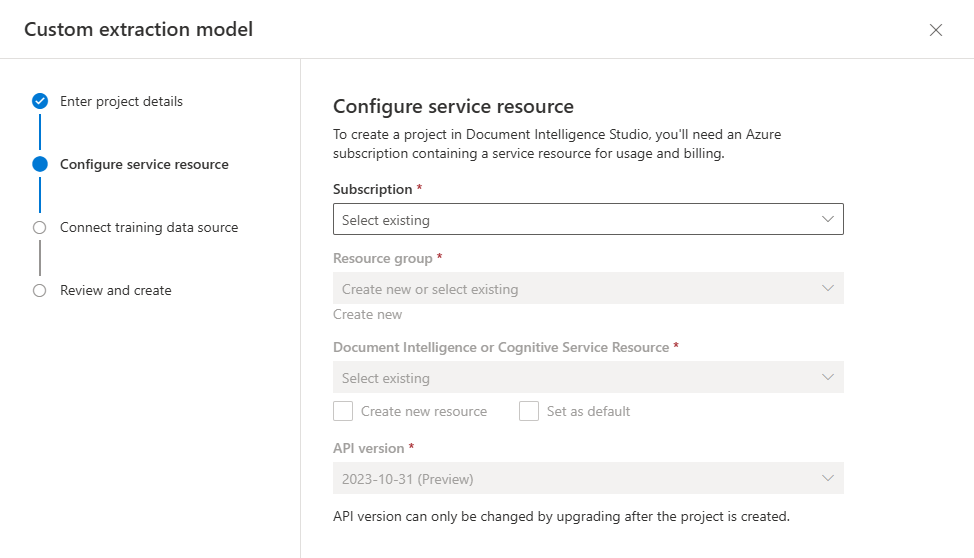
Затем выберите учетную запись хранения, используемую для отправки набора данных обучения пользовательской модели. Если документы для обучения находятся в корне контейнера, поле Путь к папке необходимо оставить пустым. Если документы находятся во вложенной папке, введите в поле Путь к папке относительный путь из корня контейнера. После настройки учетной записи хранения нажмите кнопку "Продолжить".
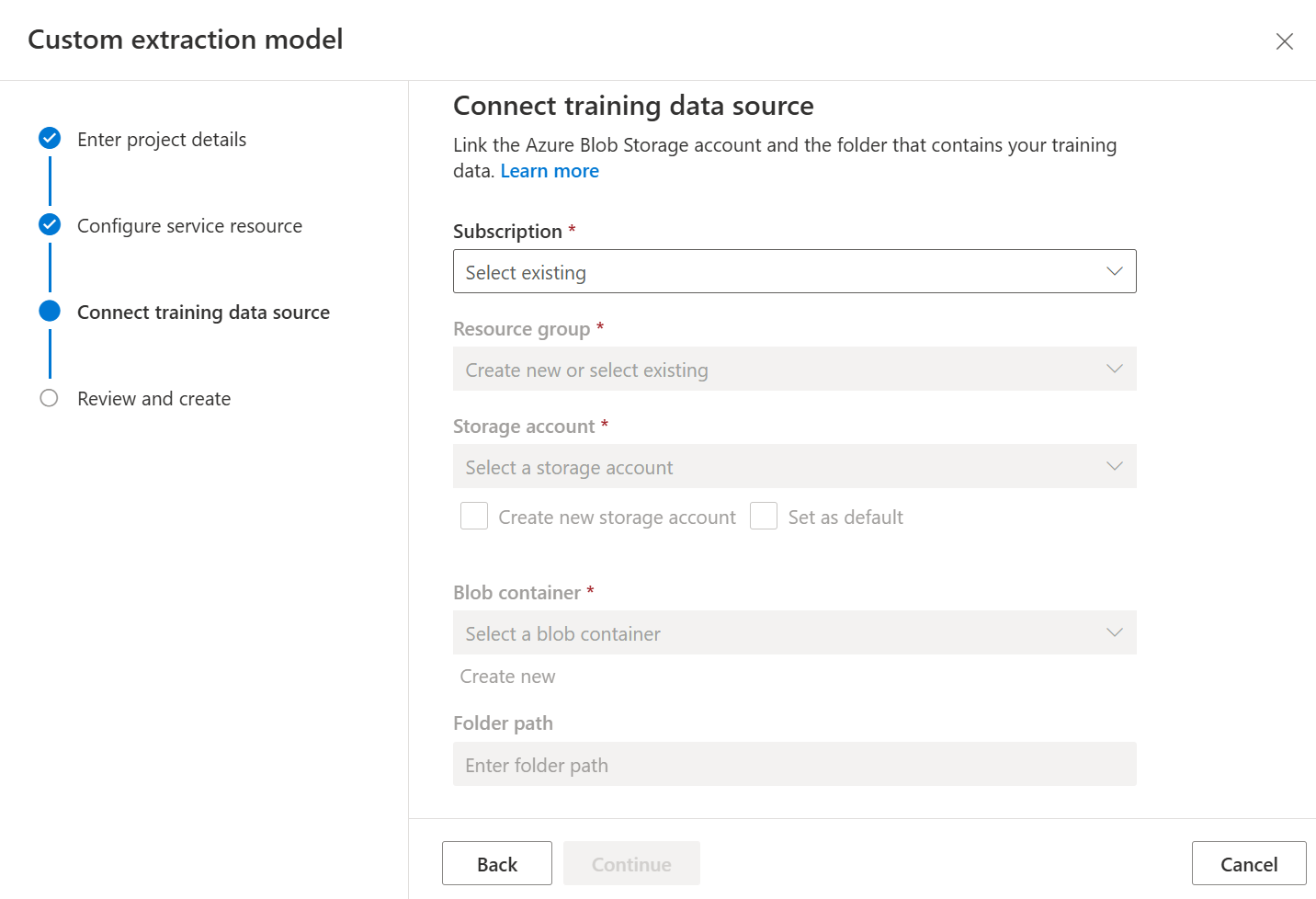
Наконец, проверьте параметры проекта и выберите Создать проект, чтобы создать новый проект. Далее должно открыться окно добавления меток, где можно просмотреть список файлов в наборе данных.
Добавление меток к данным
Первая задача при работе с проектом заключается в том, чтобы добавить метки для полей набора данных, которые требуется извлекать.
Файлы, отправленные в хранилище, перечислены слева от экрана с первым файлом, готовым к маркировке.
Начните метку набора данных и создайте первое поле, нажав кнопку "плюс" (➕) в правом верхнем углу экрана.
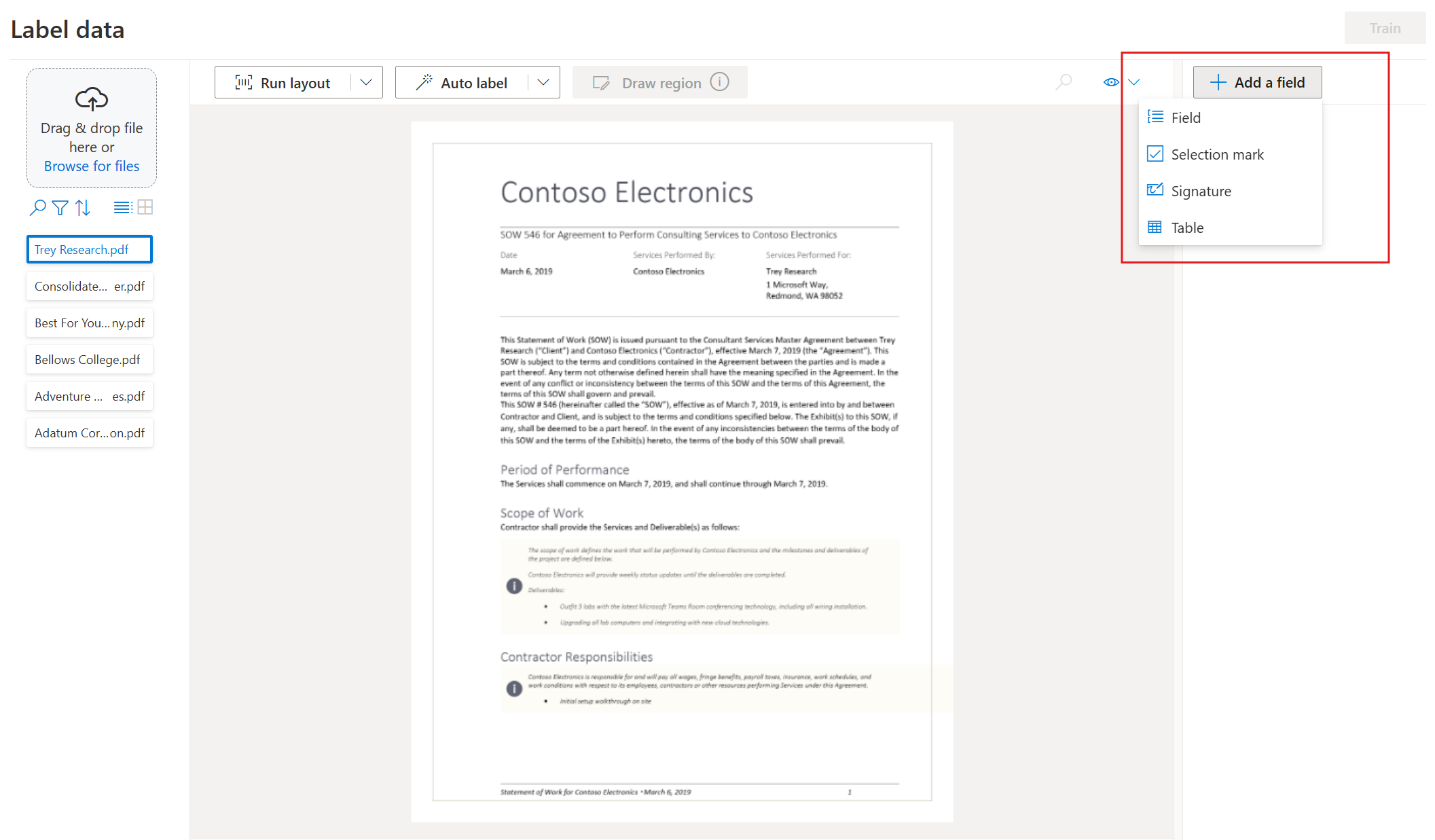
Введите имя поля.
Назначьте значение полю, выбрав слово или слова в документе. Выберите поле в раскрывающемся списке или списке полей на правой панели навигации. Помеченное значение находится под именем поля в списке полей.
Повторите эту процедуру для всех полей набора данных, для которых нужно добавить метки.
Добавьте метки в остальные документы в наборе данных. Для этого выберите каждый документ и укажите текст для, которого нужно добавить метки.
Теперь для всех документов в наборе данных добавлены метки. Файлы .labels.json и .ocr.json соответствуют каждому документу в наборе данных обучения и новому файлу fields.json. Этот набор данных обучения отправляется для обучения модели.
Обучение модели
После добавления меток для набора данных можно приступать к обучению модели. Нажмите кнопку "Обучить" в правом верхнем углу экрана.
В диалоговом окне обучения модели укажите уникальный идентификатор модели и при необходимости введите описание. Идентификатор модели имеет строковый тип данных.
В качестве режима построения укажите тип модели, которую необходимо обучить. Дополнительные сведения о типах моделей и их возможностях.
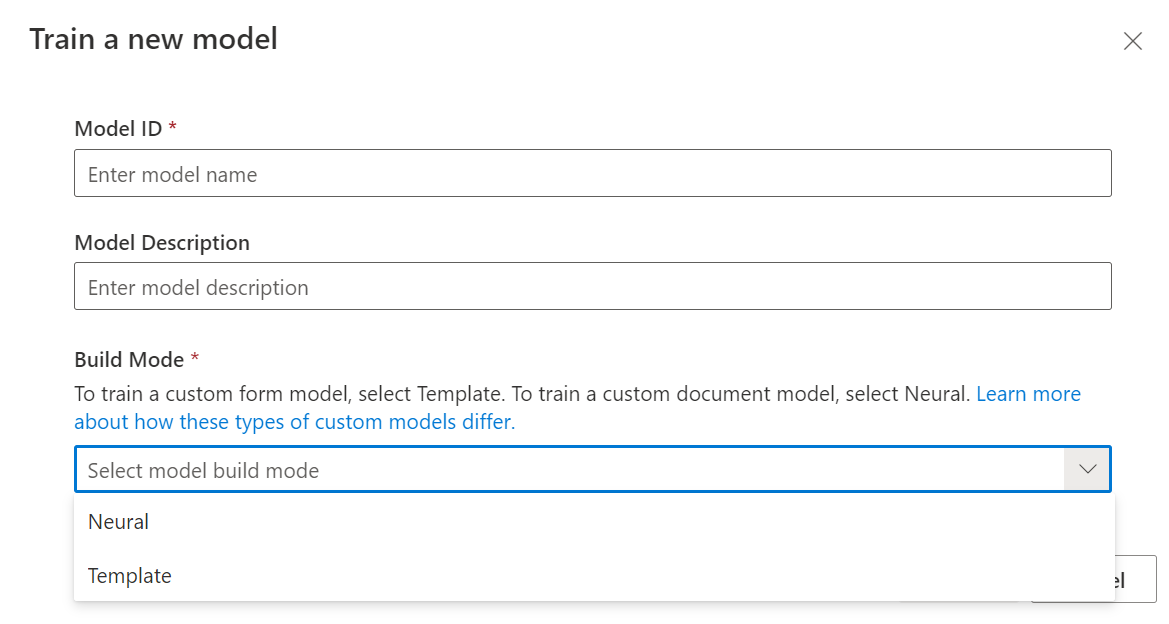
Выберите Обучить, чтобы запустить процесс обучения.
Обучение моделей шаблонов длится несколько минут. Обучение нейронных моделей может занимать до 30 минут.
Состояние процесса обучения можно просмотреть в меню Модели.
Тестирование модели
После завершения обучения можно протестировать модель, выбрав ее на странице со списком моделей.
Выберите модель и нажмите кнопку Тест.
Нажмите кнопку
+ Add, чтобы выбрать файл для проверки модели.После выбора файла нажмите кнопку Анализ, чтобы проверить модель.
Результаты модели отображаются в главном окне, а извлеченные поля выводятся на панели навигации справа.
Проверьте модель, оценивая результаты для каждого поля.
В панели навигации справа также представлен пример кода для вызова модели и результатов JSON из API.
Поздравляем вас, как обучить пользовательскую модель в Студии аналитики документов! Ваша модель готова к использованию для анализа документов с REST API или пакетом SDK.
Применимо к: ![]() версии 2.1. Другие версии: версия 3.0
версии 2.1. Другие версии: версия 3.0
При использовании настраиваемой модели аналитики документов вы предоставляете собственные данные обучения для операции обучения пользовательской модели , чтобы модель могли обучаться в отраслевых формах. Следуйте инструкциям в этом руководстве, чтобы узнать, как получить и подготовить данные для эффективного обучения модели.
Вам потребуется по крайней мере пять завершенных форм одного типа.
Если вы хотите использовать данные обучения, помеченные вручную, необходимо начать с по крайней мере пять завершенных форм одного типа. Вы по-прежнему можете использовать непомеченные формы в дополнение к требуемому набору данных.
Требования к входным данным настраиваемой модели
Сначала убедитесь, что набор обучающих данных соответствует требованиям к входным данным для аналитики документов.
Поддерживаемые форматы файлов:
Модель PDF Изображение: JPEG/JPG, ,BMPPNGTIFFHEIFMicrosoft Office:
Word (), Excel (XLSXDOCX), PowerPoint (PPTX), HTMLЧитать ✔ ✔ ✔ Макет ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Документ общего назначения ✔ ✔ Готовое ✔ ✔ Настраиваемая функция извлечения ✔ ✔ Настраиваемая классификация ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) Для получения наилучших результатов предоставьте одну четкую фотографию или скан-копию документа высокого качества.
Для PDF и TIFF можно обрабатывать до 2000 страниц (с подпиской на бесплатный уровень только первые две страницы обрабатываются).
Размер файла для анализа документов составляет 500 МБ для платного уровня (S0) и
4МБ для бесплатного уровня (F0).Размеры изображения должны составлять от 50 пикселей до 50 пикселей и 10 000 пикселей x 10 000 пикселей.
Если PDF-файлы заблокированы паролем, перед отправкой необходимо снять блокировку.
Минимальная высота извлекаемого текста составляет 12 пикселей для изображения размером 1024 x 768 пикселей. Это измерение соответствует тексту
8точки в 150 точек на дюйм (DPI).Для обучения пользовательской модели максимальный объем обучающих данных составляет 500 страниц для пользовательской модели шаблона и 50 000 страниц для пользовательской нейронной модели.
Для обучения пользовательской модели извлечения общий размер обучающих данных составляет 50 МБ для модели шаблона и
1ГБ для нейронной модели.Для обучения пользовательской модели классификации общий размер обучающих данных составляет
1ГБ не более 10 000 страниц. Для 2024-07-31-preview и более поздних версий общий размер обучающих данных составляет2ГБ с максимальным количеством 10 000 страниц.
Советы касательно данных для обучения
Следуйте этим советам, чтобы оптимизировать набор данных для обучения.
- Используйте текстовые pdf-документы вместо документов на основе изображений. Отсканированные PDF-файлы обрабатываются как изображения.
- Используйте примеры, в которых заполнены все поля для завершенных форм.
- Используйте формы с разными значениями в каждом поле.
- Используйте более крупный набор данных (10-15 изображений) для завершенных форм.
Отправка данных для обучения
После сбора набора документов для обучения необходимо отправить его в контейнер хранилища BLOB-объектов Azure. Если вы не знаете, как создать учетную запись хранения Azure с контейнером, обратитесь к краткому руководству по работе со службой хранилища Azure на портале Azure. Используйте уровень производительности "Стандартный".
Если вы хотите использовать данные, помеченные вручную, отправьте .labels.json и .ocr.json файлы, соответствующие учебным документам. Чтобы создать эти файлы, можно использовать средство маркировки данных (или собственный инструмент пользовательского интерфейса).
Упорядочение данных во вложенных папках (необязательно)
По умолчанию API обучения пользовательской модели использует только документы, расположенные в корне контейнера хранилища. Однако для обучения можно использовать данные во вложенных папках, если указать их в вызове API. Как правило, тело вызова функции обучения настраиваемой модели имеет следующий формат, где <SAS URL> — это подписанный URL-адрес контейнера:
{
"source":"<SAS URL>"
}
Если добавить следующее содержимое в текст запроса, API обучается с документами, расположенными в вложенных папках. Поле "prefix" является необязательным и ограничивает набор данных обучения файлам, пути которых начинаются с заданной строки. Таким образом, значение "Test", например, приводит к тому, что API будет просматривать только файлы или папки, начинающиеся с слова Test.
{
"source": "<SAS URL>",
"sourceFilter": {
"prefix": "<prefix string>",
"includeSubFolders": true
},
"useLabelFile": false
}
Следующие шаги
Теперь, когда вы узнали, как создать обучающий набор данных, следуйте краткому руководству, чтобы обучить пользовательскую модель аналитики документов и начать использовать ее в формах.