Учебник. Использование Функций Azure и Python для обработки сохраненных документов
Аналитика документов может использоваться в составе автоматизированного конвейера обработки данных, созданного с помощью Функции Azure. В этом учебнике показано, как использовать Функции Azure для обработки документов, отправленных в контейнер хранилища BLOB-объектов Azure. Этот рабочий процесс извлекает данные таблицы из сохраненных документов с помощью модели макета аналитики документов и сохраняет данные таблицы в файле .csv в Azure. Затем данные можно отобразить с помощью Microsoft Power BI (не рассматривается здесь).
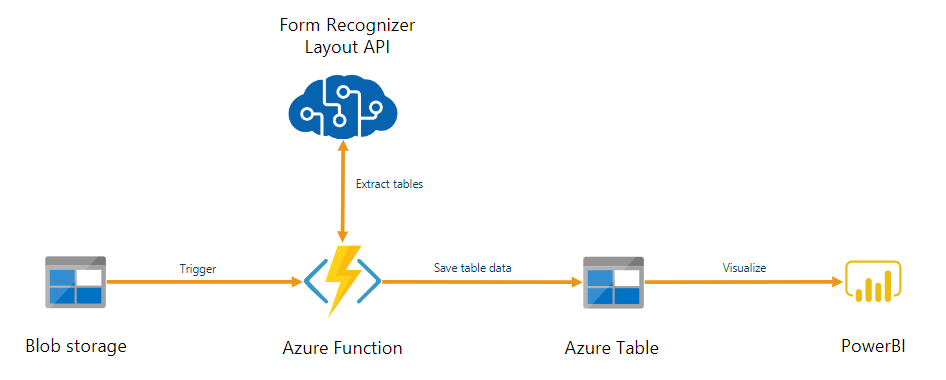
В этом руководстве описано следующее:
- Создайте учетную запись Службы хранилища Azure.
- Создайте проект Функций Azure.
- Извлечение данных макета из отправленных форм.
- Отправка извлеченных данных макета в службу хранилища Azure.
Необходимые компоненты
Подписка Azure - Создайте подписку бесплатно
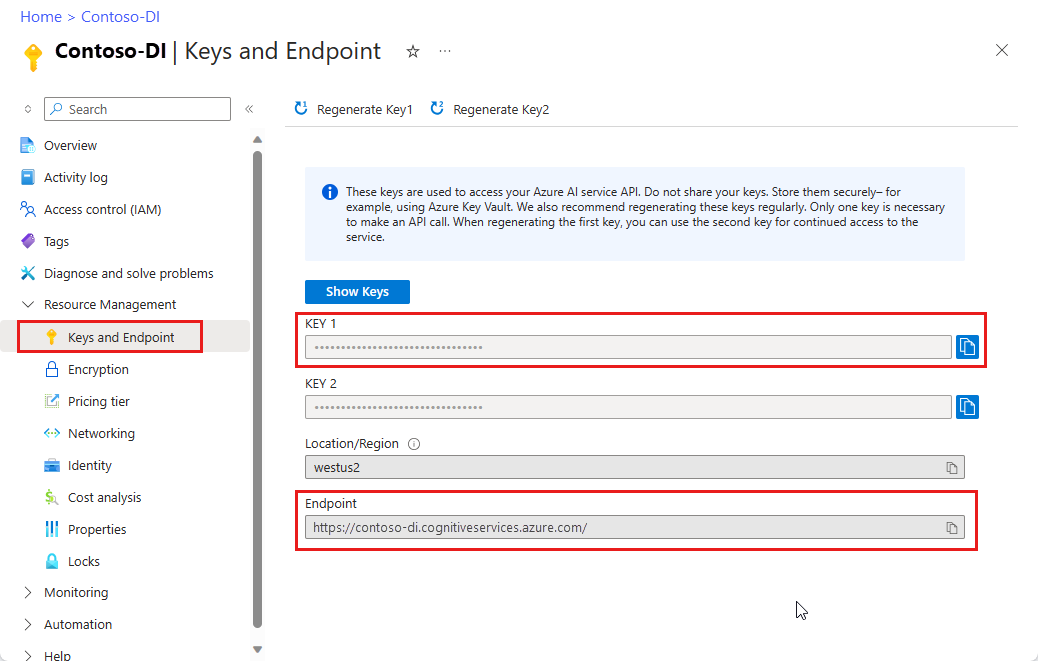
Ресурс аналитики документов. После получения подписки Azure создайте ресурс аналитики документов в портал Azure, чтобы получить ключ и конечную точку. Используйте бесплатную ценовую категорию (
F0), чтобы опробовать службу, а затем выполните обновление до платного уровня для рабочей среды.После развертывания ресурса выберите Перейти к ресурсу. Вам потребуется ключ и конечная точка из ресурса, создаваемого для подключения приложения к API аналитики документов. Ключ и конечная точка позднее будут вставлены в приведенное ниже поле кода.
Python 3.6.x, 3.7.x, 3.8.x или 3.9.x (Python 3.10.x не поддерживается для этого проекта).
Последняя версия Visual Studio Code (VS Code) со следующими расширениями:
Расширение "Функции Azure". После установки вы увидите логотип Azure в области навигации слева.
Azure Functions Core Tools версии 3.x (версия 4.x не поддерживается для этого проекта).
Расширение Python для Visual Studio Code. Дополнительные сведения см. в статье "Начало работы с Python" в VS Code
Локальный PDF-документ для анализа. Для этого проекта можно использовать пример документа PDF.
Создание учетной записи хранения Azure
Создайте учетную запись хранения общего назначения Azure версии 2 на портале Azure. Если вы не знаете, как создать учетную запись хранения Azure с контейнером хранилища, следуйте этим кратким руководствам:
- Создание учетной записи хранения. При создании учетной записи хранения выберите уровень производительности Стандартныйв поле Сведения об экземпляре>Производительность.
- Создание контейнера. При создании контейнера в окне Создание контейнера установите для поля Уровень общего доступа значение Контейнер (анонимный доступ на чтение для контейнеров и файлов).
На панели слева выберите вкладку Общий доступ к ресурсам (CORS) и удалите имеющуюся политику CORS при наличии.
После развертывания учетной записи хранения создайте два пустых контейнера хранилища BLOB-объектов с именем input и output.
Создание проекта Функций Azure
Создайте папку с именем functions-app для хранения проекта и нажмите кнопку Выбрать.
В Visual Studio Code откройте палитру команд. Найдите и выберите Python:Select Interpreter → выберите установленный интерпретатор Python версии 3.6.x, 3.7.x, 3.8.x или 3.9.x. Этот выбор добавит выбранный путь интерпретатора Python в проект.
Выберите логотип Azure на панели навигации слева.
В представлении "Ресурсы" вы увидите существующие ресурсы Azure.
Выберите подписку Azure, которую вы используете для этого проекта, и ниже вы увидите приложение-функцию Azure.
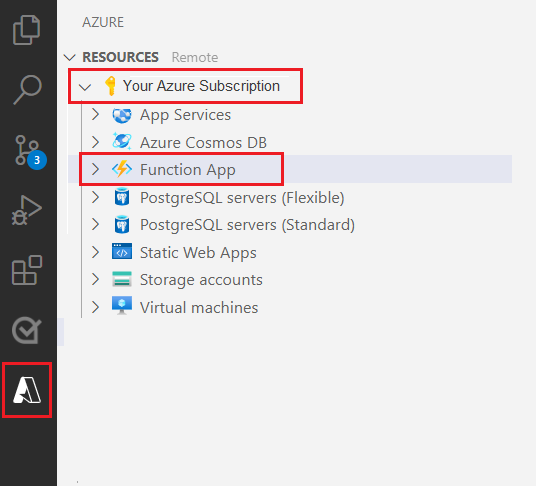
Выберите раздел "Рабочая область (локальная)", расположенный под перечисленными ресурсами. Выберите значок "плюс" и нажмите кнопку Создать функцию.

При появлении запроса выберите Создать проект и перейдите в каталог приложения-функции. Выберите Выбрать.
Вам будет предложено настроить несколько параметров:
Выберите язык → выберите Python.
Выберите интерпретатор Python, чтобы создать виртуальную среду → выберите интерпретатор, заданный по умолчанию.
Выберите шаблон → выберите триггер Хранилища BLOB-объектов Azure и присвойте триггеру имя или примите имя по умолчанию. нажимайте клавишу ВВОД, чтобы подтвердить.
Выберите параметр → в раскрывающемся меню выберите ➕Создать новый параметр локального приложения.
Выберите подписку → выберите подписку Azure с созданной учетной записью хранения → выберите свою учетную запись хранения → выберите имя контейнера ввода хранилища (в данном случае
input/{name}). нажимайте клавишу ВВОД, чтобы подтвердить.Выберите способ открытия проекта → выберите "Открыть проект" в текущем окне в раскрывающемся меню.
После выполнения этих действий в VSCode будет добавлен новый проект Функций Azure с помощью скрипта Python __init__.py. Этот скрипт активируется при отправке файла в контейнер хранилища input:
import logging
import azure.functions as func
def main(myblob: func.InputStream):
logging.info(f"Python blob trigger function processed blob \n"
f"Name: {myblob.name}\n"
f"Blob Size: {myblob.length} bytes")
Проверка функции
Нажмите клавишу F5, чтобы запустить базовую функцию. VS Code предложит выбрать учетную запись хранения для взаимодействия.
Выберите созданную учетную запись хранения и продолжайте работу.
Откройте Обозреватель службы хранилища Azure и отправьте образец PDF-документа в контейнер input. Затем проверьте терминал VSCode. Скрипт должен зарегистрировать, что он был активирован при отправке PDF-файла.
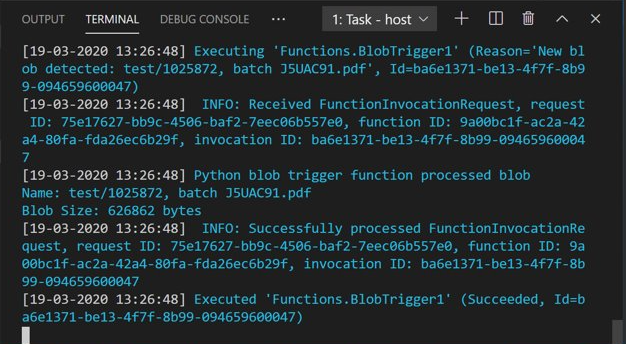
Прежде чем продолжить, завершите выполнение скрипта.
Добавление кода обработки документов
Затем вы добавите собственный код в скрипт Python, чтобы вызвать службу аналитики документов и проанализировать отправленные документы с помощью модели макета аналитики документов.
В VS Code перейдите к файлу функции requirements.txt. В этом файле указаны зависимости для скрипта. Добавьте следующие пакеты Python в файл:
cryptography azure-functions azure-storage-blob azure-identity requests pandas numpyЗатем откройте скрипт __init__.py. Добавьте следующие операторы
import:import logging from azure.storage.blob import BlobServiceClient import azure.functions as func import json import time from requests import get, post import os import requests from collections import OrderedDict import numpy as np import pandas as pdСозданную функцию
mainможно оставить без изменений. Вы добавите пользовательский код в эту функцию.# This part is automatically generated def main(myblob: func.InputStream): logging.info(f"Python blob trigger function processed blob \n" f"Name: {myblob.name}\n" f"Blob Size: {myblob.length} bytes")Следующий блок кода вызывает API анализа макета анализа документов в отправленном документе. Заполните значения конечной точки и ключа.
# This is the call to the Document Intelligence endpoint endpoint = r"Your Document Intelligence Endpoint" apim_key = "Your Document Intelligence Key" post_url = endpoint + "/formrecognizer/v2.1/layout/analyze" source = myblob.read() headers = { # Request headers 'Content-Type': 'application/pdf', 'Ocp-Apim-Subscription-Key': apim_key, } text1=os.path.basename(myblob.name)Внимание
Обязательно удалите ключ из кода, когда завершите работу, и ни в коем случае не публикуйте его в открытом доступе. Для рабочей среды используйте безопасный способ хранения и доступа к учетным данным, например Azure Key Vault. Дополнительные сведения см. в статье "Безопасность служб искусственного интеллекта Azure".
Далее добавьте код для запроса к службе и получения возвращаемых данных.
resp = requests.post(url=post_url, data=source, headers=headers) if resp.status_code != 202: print("POST analyze failed:\n%s" % resp.text) quit() print("POST analyze succeeded:\n%s" % resp.headers) get_url = resp.headers["operation-location"] wait_sec = 25 time.sleep(wait_sec) # The layout API is async therefore the wait statement resp = requests.get(url=get_url, headers={"Ocp-Apim-Subscription-Key": apim_key}) resp_json = json.loads(resp.text) status = resp_json["status"] if status == "succeeded": print("POST Layout Analysis succeeded:\n%s") results = resp_json else: print("GET Layout results failed:\n%s") quit() results = resp_jsonДобавьте следующий код для подключения к контейнеру output службы хранилища Azure. Введите собственные значения для имени и ключа учетной записи хранения. Ключ можно получить на вкладке Ключи доступа ресурса хранилища на портале Azure.
# This is the connection to the blob storage, with the Azure Python SDK blob_service_client = BlobServiceClient.from_connection_string("DefaultEndpointsProtocol=https;AccountName="Storage Account Name";AccountKey="storage account key";EndpointSuffix=core.windows.net") container_client=blob_service_client.get_container_client("output")Следующий код анализирует возвращенный ответ аналитики документов, создает файл .csv и отправляет его в выходной контейнер.
Внимание
Скорее всего, вам потребуется изменить этот код, чтобы он соответствовал структуре собственных документов.
# The code below extracts the json format into tabular data. # Please note that you need to adjust the code below to your form structure. # It probably won't work out-of-the-box for your specific form. pages = results["analyzeResult"]["pageResults"] def make_page(p): res=[] res_table=[] y=0 page = pages[p] for tab in page["tables"]: for cell in tab["cells"]: res.append(cell) res_table.append(y) y=y+1 res_table=pd.DataFrame(res_table) res=pd.DataFrame(res) res["table_num"]=res_table[0] h=res.drop(columns=["boundingBox","elements"]) h.loc[:,"rownum"]=range(0,len(h)) num_table=max(h["table_num"]) return h, num_table, p h, num_table, p= make_page(0) for k in range(num_table+1): new_table=h[h.table_num==k] new_table.loc[:,"rownum"]=range(0,len(new_table)) row_table=pages[p]["tables"][k]["rows"] col_table=pages[p]["tables"][k]["columns"] b=np.zeros((row_table,col_table)) b=pd.DataFrame(b) s=0 for i,j in zip(new_table["rowIndex"],new_table["columnIndex"]): b.loc[i,j]=new_table.loc[new_table.loc[s,"rownum"],"text"] s=s+1Наконец, последний блок кода отправляет извлеченную таблицу и текстовые данные в элемент хранилища BLOB-объектов.
# Here is the upload to the blob storage tab1_csv=b.to_csv(header=False,index=False,mode='w') name1=(os.path.splitext(text1)[0]) +'.csv' container_client.upload_blob(name=name1,data=tab1_csv)
Выполнение функции
Нажмите клавишу F5, чтобы запустить функцию повторно.
Используйте Обозреватель службы хранилища Azure для отправки образца формы PDF в контейнер хранилища input. Это действие должно активировать скрипт, и в контейнере output должен отобразиться полученный CSV-файл (в виде таблицы).
Этот контейнер можно подключить к Power BI для создания полнофункциональных визуализаций содержащихся в нем данных.
Следующие шаги
Из этого учебника вы узнали, как использовать Функцию Azure, написанную на языке Python, для автоматической обработки отправленных PDF-документов и вывода их содержимого в более понятном формате. Далее вы узнаете, как использовать Power BI для отображения данных.
- Что такое аналитика документов?
- Узнайте больше об модели макета.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по