Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
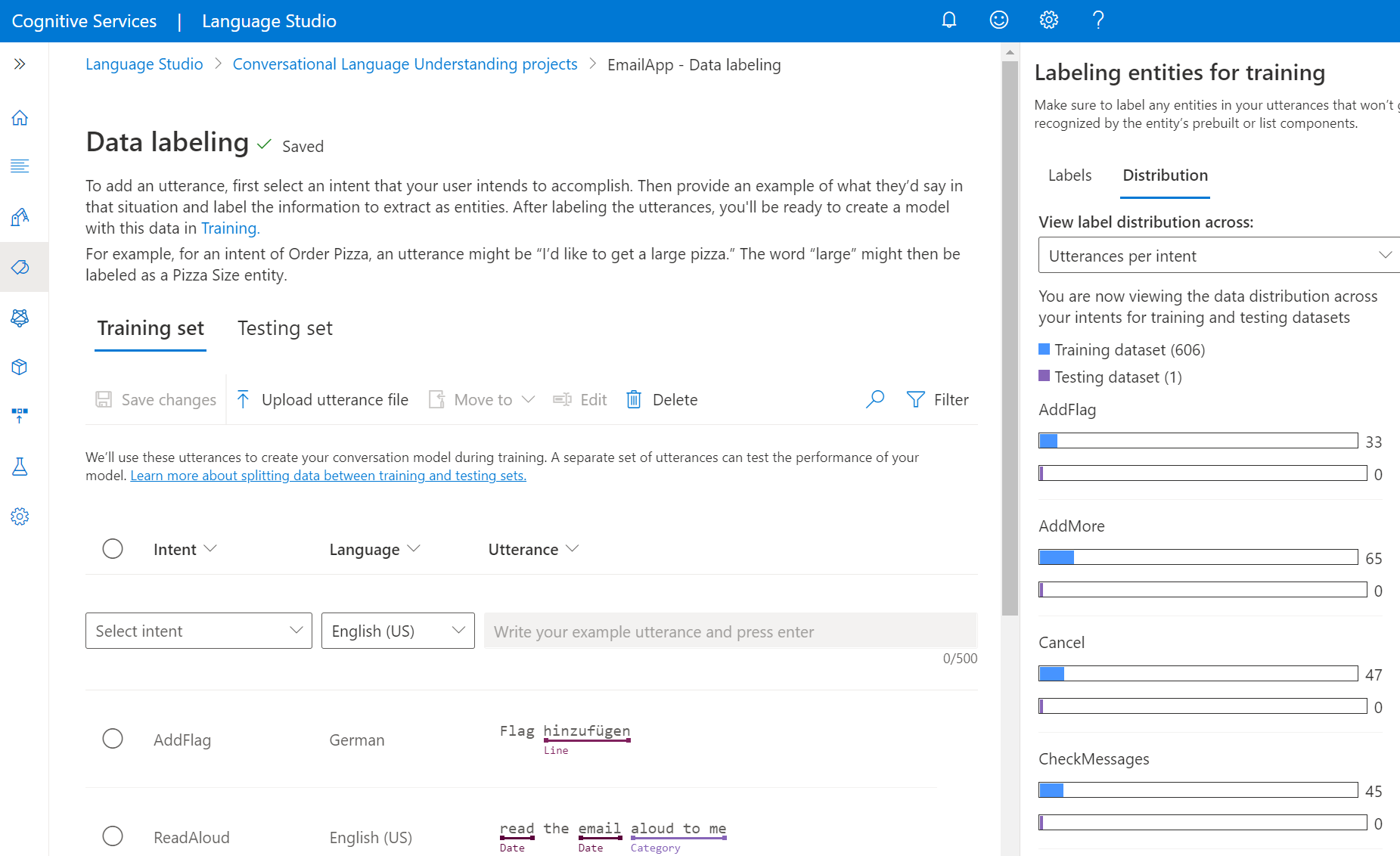
После создания схемы для задачи по тонкой настройке вы добавите обучающие высказывания в проект. Речевые фрагменты должны быть похожи на то, что пользователи используют при взаимодействии с проектом. При добавлении речевого фрагмента необходимо назначить намерение, которому он принадлежит. После добавления речевого фрагмента пометьте в нем слова, которые вы хотите извлечь как сущности.
Метка данных — это важный шаг в обученном жизненном цикле разработки для распознавания речи (CLU). Эти данные используются на следующем шаге при обучении модели, чтобы модель училась на основе помеченных данных. Если вы уже пометили высказывания, их можно импортировать непосредственно в проект, если данные соответствуют принятому формату данных. Дополнительные сведения об импорте помеченных данных см. в статье "Создание задачи тонкой настройки CLU". Помеченные данные сообщают модели о том, как интерпретировать текст и используется для обучения и оценки.
Совет
Используйте параметр быстрого развертывания для реализации пользовательской маршрутизации намерений CLU, которая используется при развертывании собственной крупной языковой модели без добавления или маркировки данных обучения.
Необходимые компоненты
- У вас должен быть успешно созданный проект.
Дополнительные сведения см. в жизненном цикле разработки CLU.
Рекомендации по маркировке данных
После сборки схемы и создания проекта необходимо пометить данные. Маркировка данных важна, чтобы модель знала, какие предложения и слова связаны с намерениями и сущностями в проекте. Провести время, обозначая речевые фрагменты, чтобы ввести и уточнить данные, используемые в обучении моделей.
Добавляя речевые фрагменты и размечая их, помните о следующем:
Модели машинного обучения обобщают на основе указанных вами примеров. Чем больше примеров вы предоставляете, тем больше точек данных есть у модели, чтобы делать более точные обобщения.
Точность, согласованность и полнота помеченных данных являются ключевыми факторами для определения производительности модели:
- Точно определите: Всегда определяйте намерения и сущности правильно по типу. Включайте только то, что вы хотите классифицировать и извлечь. Избегайте ненужных данных в метках.
- Последовательное использование меток: Одна и та же сущность должна иметь одну и ту же метку во всех высказываниях.
- Метка полностью: Предоставьте разнообразные речевые фрагменты для каждого намерения. Пометьте все экземпляры сущности во всех речевых фрагментах.
Четко помеченные речевые фрагменты
Убедитесь, что основные понятия, к которым относятся сущности, являются четко определенными и разделимыми. Проверьте, можно ли легко определить различия надежно. Если вы не можете, это отсутствие различия может указывать на трудности для усвоенного компонента.
Убедитесь, что некоторые аспекты данных могут обеспечить сигнал для различий при наличии сходства между сущностями.
Например, если вы создали модель для бронирования рейсов, пользователь может использовать высказывание, например "Я хочу рейс из Бостона в Сиэтл". Город-источник и город назначения для таких речевых фрагментов, как ожидается, будет похожим. Сигналом для отличия города происхождения может быть то, что слово из часто предшествует ему.
Убедитесь, что все экземпляры каждой сущности помечены как в обучающих, так и в тестовых данных. Одним из способов является использование функции поиска для поиска всех экземпляров слова или фразы в данных, чтобы проверить правильность их метки.
Убедитесь, что вы обозначили тестовые данные на сущностях без изученных компонентов, а также на сущностях с ними. Эта практика помогает убедиться, что метрики оценки являются точными.
Для многоязычных проектов добавление речевых фрагментов на других языках повышает производительность модели на этих языках. Избегайте дублирования данных на всех языках, которые требуется поддерживать. Например, чтобы улучшить взаимодействие бота-календаря с пользователями, разработчик может добавить примеры, в основном на английском языке, а также несколько примеров на испанском и французском языках. Он может добавить такие речевые фрагменты, как:
- "Установите встречу с Мэттом и Кевиномзавтра в 12 вечера". (английский)
- "Ответ в качестве предварительного ответа на еженедельное обновление собрания". (английский)
- "Cancelar mi próxima reunión". (испанский)
Пометьте свои высказывания
Чтобы добавить метки к речевым фрагментам, выполните указанные ниже действия.
Перейдите на страницу проекта в Azure AI Foundry.
На левой панели выберите "Управление данными". На этой странице можно добавить речевые фрагменты и пометить их. Вы также можете загрузить свои речевые фрагменты непосредственно, выбрав Загрузить файл речевых фрагментов в верхнем меню. Обязательно следуйте принятому формату.
С помощью верхних вкладок можно изменить представление на набор обучения или набор тестирования. Узнайте больше о наборах для обучения и тестирования, а также о том, как они используются для обучения и оценки моделей.

Совет
Если вы планируете использовать автоматическое разделение тестового набора от обучающих данных, добавьте все высказывания в набор обучения.
В раскрывающемся меню Выбор намерения выберите одно из намерений, язык речевого фрагмента (для мультиязычных проектов) и сам речевой фрагмент. Нажмите клавишу ВВОД в текстовом поле и добавьте высказывание.
Разметить сущности в речевом фрагменте можно двумя способами:
Вариант Описание Нанесите метку с помощью кисти Выберите значок кисти рядом с сущностью в панели справа, а затем выделите текст в высказывании, который вы хотите пометить. Создайте метку с помощью встроенного меню Выделите слово, которое нужно наметить как сущность, и появится меню. Выберите сущность, которой вы хотите пометить эти слова. В области справа на вкладке "Метки" можно найти все типы сущностей в проекте и количество помеченных экземпляров на каждый из них.
На вкладке "Распределение" можно просмотреть распределение по наборам обучения и тестирования. У вас есть следующие параметры для просмотра:
- Общее количество экземпляров для каждой помеченной сущности: Можно просмотреть количество всех помеченных экземпляров определенной сущности.
- Уникальные речевые фрагменты для каждой помеченной сущности: Каждое высказывание учитывается, если он содержит по крайней мере один помеченный экземпляр этой сущности.
- Высказывания на каждое намерение: Вы можете просмотреть количество высказываний по каждому намерению.


Примечание.
Список, regex и предварительно созданные компоненты не отображаются на странице маркировки данных. Все метки здесь применяются только к обученной компоненте.
Чтобы удалить метку, выполните приведенные действия.
- В вашем речевом высказывании выберите сущность, с которой вы хотите снять метку.
- прокрутите появившееся меню и выберите пункт Удалить метку.
Удаление сущности:
- Щелкните по значку корзины рядом с сущностью, которую вы хотите изменить в панели справа.
- Выберите Удалить, чтобы подтвердить.
Предложение речевых фрагментов с помощью Azure OpenAI
В CLU используйте Azure OpenAI, чтобы предложить речевые фрагменты для добавления в проект с помощью формируемых языковых моделей. Рекомендуется использовать ресурс Azure AI Foundry во время использования CLU, чтобы не нужно подключать несколько ресурсов.
Чтобы использовать ресурс Azure AI Foundry, необходимо предоставить вашему ресурсу Azure AI Foundry повышенные привилегии. Для этого перейдите на портал Azure. В ресурсе Azure AI предоставьте ему самому доступ в качестве пользователя Cognitive Services. Этот шаг гарантирует правильное взаимодействие всех частей ресурса.
Подключитесь с помощью отдельных ресурсов Языка и Azure OpenAI
Сначала необходимо получить доступ и создать ресурс в Azure OpenAI. Затем создайте подключение к ресурсу Azure OpenAI в том же проекте Azure AI Foundry в центре управления слева на странице Azure AI Foundry. Затем необходимо создать развертывание для моделей Azure OpenAI в подключенном ресурсе Azure OpenAI. Чтобы создать новый ресурс, выполните действия, описанные в статье "Создание и развертывание Azure OpenAI" в ресурсе Azure AI Foundry Models.
Перед началом работы функция предлагаемых высказываний доступна только в том случае, если ваш языковой ресурс находится в следующих регионах:
- Восточная часть США
- Центрально-южная часть США
- Западная Европа
На странице разметка данных :
Выберите "Предложить речевые фрагменты". Откроется область справа, и появится приглашение выбрать ресурс и развертывание Azure OpenAI.
Выбрав ресурс Azure OpenAI, выберите "Подключить" , чтобы ресурс языка получил прямой доступ к ресурсу Azure OpenAI. Вашему языковому ресурсу назначается роль пользователя Cognitive Services для ресурса Azure OpenAI. Теперь ваш текущий языковой ресурс имеет доступ к Azure OpenAI. Если подключение завершается ошибкой, выполните следующие действия , чтобы вручную добавить правильную роль в ресурс Azure OpenAI.
После подключения ресурса выберите развертывание. Мы рекомендуем модель для развертывания Azure OpenAI
gpt-35-turbo-instruct.Выберите намерение, для которого требуется получить предложения. Убедитесь, что выбранное намерение содержит по крайней мере пять сохраненных речевых фрагментов, чтобы иметь возможность предлагать речевые фрагменты. Предложения, предоставляемые Azure OpenAI, основаны на последних речевых фрагментах, которые вы добавили для этого намерения.
Выберите " Создать речевые фрагменты".
Предлагаемые речевые фрагменты отображаются с пунктирной линией вокруг них и заметкой , созданной ИИ. Эти предложения должны быть приняты или отклонены. Принятие предложения добавляет его в проект, как если бы вы добавили его самостоятельно. Отклонение предложения приводит к его полному удалению. Только принятые речевые фрагменты являются частью проекта и используются для обучения или тестирования.
Чтобы принять или отклонить, выберите зеленый флажок или красные кнопки отмены рядом с каждым высказыванием. Вы также можете использовать "Принять все " и "Отклонить все " на панели инструментов.


Использование этой функции влечет за собой плату со вашего ресурса Azure OpenAI за аналогичное количество токенов для созданных предложений. Сведения о ценах на Azure OpenAI см. в разделе о ценах на Службу Azure OpenAI.
Добавление необходимых конфигураций в ресурс Azure OpenAI
Включите управление удостоверениями для языкового ресурса с помощью следующих вариантов.
Ваш языковой ресурс должен иметь управление идентификацией. Чтобы включить его с помощью портала Azure, выполните следующие действия.
- Откройте ваш языковой ресурс.
- На левой панели в разделе "Управление ресурсами " выберите "Удостоверение".
- На вкладке Назначено системой установите Состояние как Вкл..
После включения управляемого удостоверения назначьте роль пользователя Cognitive Services вашему ресурсу Azure OpenAI, используя управляемое удостоверение вашего ресурса Language.
Войдите на портал Azure и перейдите к ресурсу Azure OpenAI.
Перейдите на вкладку управления доступом (IAM).
Выберите Добавить>Добавить назначение ролей.
Выберите роли функции задания и нажмите кнопку "Далее".
Выберите "Пользователь Cognitive Services" в списке ролей и нажмите кнопку "Далее".
Выберите Назначить доступ: Управляемая идентичность и выберите Выбрать участников.
В разделе «Управляемое удостоверение» выберите «Язык».
Найдите ресурс и выберите его. Затем нажмите кнопку "Далее " и завершите процесс.
Просмотрите сведения и выберите "Проверить и назначить".


Через несколько минут обновите Azure AI Foundry и успешно подключитесь к Azure OpenAI.