Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это важно
- Выпуски общедоступной предварительной версии языка искусственного интеллекта Azure предоставляют ранний доступ к функциям, которые находятся в активной разработке.
- Функции, подходы и процессы могут изменяться до общедоступной доступности на основе отзывов пользователей.
Язык ИИ Azure — это облачная служба, которая применяет функции обработки естественного языка (NLP) к текстовым данным. Суммаризация документов использует обработку естественного языка для создания экстрактивных (извлечение значимых предложений) или абстрактивных (извлечение контекстных слов) резюме. Оба API, AbstractiveSummarization и ExtractiveSummarization, поддерживают нативную обработку документов. Родной документ относится к файловому формату, который используется для создания оригинального документа, такого как Microsoft Word (docx) или портативный файл документа (pdf). Поддержка собственных документов устраняет необходимость предварительной обработки текста перед использованием возможностей ресурсов языка искусственного интеллекта Azure. Возможность встроенной поддержки документов позволяет асинхронно отправлять API-запросы, используя тело HTTP POST запроса для отправки данных и строку запроса HTTP GET для извлечения статуса результатов. Обработанные документы находятся в контейнере назначения вашей службы Azure Blob Storage.
Поддерживаемые форматы документов
Приложения используют собственные форматы файлов для создания, сохранения или открытия собственных документов. В настоящее время возможности PII и суммаризации документов поддерживают следующие собственные форматы документов:
| Тип файла | Расширение файла | Описание |
|---|---|---|
| Текст | .txt |
Неотформатированный текстовый документ. |
| Adobe PDF | .pdf |
Документ в формате переносимого файла. |
| Microsoft Word | .docx |
Файл документа Microsoft Word. |
Рекомендации по входным данным
Поддерживаемые форматы файлов
| Тип | поддержка и ограничения |
|---|---|
| PDF-файлы | Полностью сканированные PDF-файлы не поддерживаются. |
| Текст в изображениях | Цифровые изображения с внедренным текстом не поддерживаются. |
| Цифровые таблицы | Таблицы в сканированных документах не поддерживаются. |
Размер документа
| Свойство | Ограничение входных данных |
|---|---|
| Общее количество документов на запрос | ≤ 20 |
| Общий размер контента на запрос | ≤ 10 МБ |
Включение местных документов в HTTP-запрос
Давайте приступим к работе:
Для этого проекта мы используем средство командной строки cURL для вызова REST API.
Замечание
Пакет cURL предварительно установлен в большинстве дистрибутивов Windows 10 и Windows 11, а также в большинстве дистрибутивов macOS и Linux. Вы можете проверить версию пакета со следующими командами: Windows:
curl.exe -VmacOScurl -VLinux:curl --versionЕсли cURL не установлен, вот ссылки на установку для вашей платформы:
Активная учетная запись Azure. Если ее нет, можно создать бесплатную учетную запись.
Учетная запись хранения объектов BLOB в Azure. Кроме того, необходимо создать контейнеры в учетной записи Хранилище BLOB-объектов Azure для исходных и целевых файлов:
- Контейнер исходных файлов. Этот контейнер предназначен для отправки собственных файлов для анализа (обязательно).
- Целевой контейнер. В этом контейнере хранятся проанализированные файлы (обязательные).
Ресурс языка для одного сервиса (а не ресурс Azure AI Foundry с несколькими службами):
Заполните поля с деталями проекта языкового ресурса и его экземпляра следующим образом:
Подписка. Выберите одну из доступных подписок Azure.
Группа ресурсов. Вы можете создать новую группу ресурсов или добавить ресурс в ранее созданную группу ресурсов, которая использует одинаковый жизненный цикл, разрешения и политики.
Область ресурсов. Выберите Глобальный, если для вашего бизнеса или приложения не требуется конкретный регион. Если вы планируете использовать управляемое удостоверение, назначаемое системой, для проверки подлинности, выберите географический регион, например западная часть США.
Имя. Введите имя, выбранное для ресурса. Выбранное вами имя должно быть уникальным в Azure.
Ценовая категория. Вы можете использовать бесплатный тарифный план (
Free F0), чтобы попробовать службу, а затем перейти на платный план для работы в продакшене.Выберите Review + Create.
Проверьте условия обслуживания и щелкните Создать, чтобы развернуть ресурс.
После успешного развертывания ресурса выберите "Перейти к ресурсу".
Получите ваш ключ и конечную точку языковой службы
Для запросов к службе языка требуется ключ только для чтения и настраиваемая конечная точка для проверки подлинности доступа.
Если вы создали новый ресурс, после его развертывания нажмите кнопку "Перейти к ресурсу". Если у вас есть существующий ресурс службы языка, перейдите непосредственно на страницу ресурсов.
На левой границе в разделе Управление ресурсами выберите Ключи и конечная точка.
Вы можете скопировать и вставить
keylanguage service instance endpointв примеры кода, чтобы пройти проверку подлинности запроса в языковой службе. Для вызова API необходим только один ключ.
Создайте контейнеры Azure Blob Storage
Создайте контейнеры в вашей учетной записи Azure Blob Storage для исходных и целевых файлов.
- Контейнер исходных файлов. Этот контейнер предназначен для отправки собственных файлов для анализа (обязательно).
- Целевой контейнер. В этом контейнере хранятся проанализированные файлы (обязательные).
Аутентификация
Ваш языковой ресурс должен получить доступ к вашей учетной записи хранения, прежде чем он сможет создавать, читать или удалять объекты. Существует два основных метода, которые можно использовать для предоставления доступа к данным хранилища:
Токены подписей общего доступа (SAS). Маркеры SAS делегирования пользователей защищены учетными данными Microsoft Entra. Маркеры SAS обеспечивают безопасный делегированный доступ к ресурсам в учетной записи хранения Microsoft Azure.
Управление доступом на основе ролей управляемого удостоверения (RBAC). Управляемые удостоверения для ресурсов Azure — это основные параметры службы, которые создают идентификатор Microsoft Entra и устанавливают определенные разрешения для управляемых ресурсов Azure.
Для этого проекта мы аутентифицируем доступ к source location и target location URL-адресам с помощью SAS-маркеров, добавленных в строку запроса. Каждому токену назначается определенный файл.

- Исходный контейнер или блоб должны предоставлять доступ для чтения и к списку.
- Ваш целевой контейнер или блоб должен предоставлять доступ к записи и чтению списка.
API резюмирования с выдержками использует методы обработки естественного языка для поиска ключевых предложений в неструктурированном текстовом документе. Эти предложения в сочетании содержат основную идею документа.
Функция резюмирования с выдержками возвращает в системном ответе оценку ранжирования (ранг), а также извлеченные предложения и их положение в исходных документах. Ранг — это мера того, насколько релевантно предложение относительно основной идеи документа. В модели предусмотрен балл от 0 и 1 (включительно) для каждого предложения, и она возвращает по запросу предложения с максимальной оценкой. Например, если вы запрашиваете сводку с тремя предложениями, служба возвращает три предложения с наибольшим рейтингом.
Существует еще одна функция в языке ИИ Azure, извлечении ключевых фраз, которые могут извлекать ключевые сведения. Чтобы выбрать между извлечением ключевых фраз и извлечением сводных данных, ниже приведены полезные рекомендации.
- Извлечение ключевых фраз возвращает фразы, а извлечение суммирования возвращает предложения.
- Извлечение суммирования возвращает предложения вместе с оценкой ранжирования, а предложения верхнего ранга возвращаются на запрос.
- Извлечение сводных данных также возвращает следующие позиционные сведения:
- Смещение: начальная позиция каждого извлеченного предложения.
- Длина: длина каждого извлеченного предложения.
Определение способа обработки данных (необязательно)
Отправка данных
Документы отправляются в API в виде строк текста. Анализ выполняется при получении запроса. Так как API является асинхронным, может возникнуть задержка между отправкой запроса API и получением результатов.
При использовании этой функции результаты API доступны в течение 24 часов с момента приема запроса и указываются в ответе. По истечении этого периода результаты очищаются и больше не будут доступны для извлечения.
Получение результатов формирования сводных данных по тексту
При получении результатов от функции распознавания языка можно передать результаты в приложение или сохранить выходные данные в файл в локальной системе.
Ниже приведен пример содержимого, который можно отправить для суммирования, который извлекается с помощью статьи блога Майкрософт О целостном представлении для интеграции искусственного интеллекта. Эта статья является только примером. API может принимать более длинный входной текст. Дополнительные сведения см. в разделеоб ограничениях данных и служб.
"Корпорация Майкрософт работает над задачей по расширению возможностей применения ИИ за пределы существующих методик за счет реализации более целостного, ориентированного на человека подхода к обучению и распознаванию. Как главный технический директор служб ИИ Azure, я работал с командой удивительных ученых и инженеров, чтобы превратить этот поиск в реальность. Я использую в работе уникальный подход, основанный на рассмотрении взаимосвязей между тремя аспектами когнитивной деятельности человека: одноязычный текст (X), звуковые или визуальные сигналы (Y) и многоязычное восприятие (Z). На пересечении этих трех элементов возникает магия — так называемый XYZ-код, как показано на рис. 1, представляющий собой совместную платформу для создания более мощного ИИ, который может говорить, слышать, видеть и лучше понимать людей. Мы считаем, что XYZ-code позволяет нам реализовать наше долгосрочное видение: перекрестное обучение, охватывающие модальности и языки. Наша цель состоит в том, чтобы предварительно обученные модели могли совместно изучать представления для поддержки широкого спектра нижестоящих задач ИИ, как сегодня это делают люди. За последние пять лет мы смогли достичь показателей человека по результатам эталонных тестов по распознаванию разговорной речи, машинному переводу, ответам на вопросы в форме диалога, пониманию машинного чтения и созданию субтитров для изображений. Достижения по этим пяти направлениям дали нам твердую уверенность в возможности реализации более амбициозных задач, которые помогли бы нам совершить настоящий прорыв в области ИИ за счет мультисенсорного многоязычного обучения, которое по своей сути ближе к тому, как учатся и воспринимают информацию люди. Я полагаю, что этот совместный код XYZ может стать фундаментом для такого рывка при наличии соответствующих внешних источников знаний в нижестоящих задачах ИИ".
Запрос API суммирования текста обрабатывается при получении запроса путем создания задания для серверной части API. Если задание выполнено успешно, возвращается результат API. Выходные данные доступны для получения в течение 24 часов. По прошествии этого времени выходные данные очищаются. Из-за поддержки многоязычных и эмодзи ответ может содержать смещения текста. Более подробную информацию см. в разделе обработки смещения.
При использовании предыдущего примера API может возвращать следующие сводные предложения:
Извлечение сводных данных:
- "Корпорация Майкрософт работает над задачей по расширению возможностей применения ИИ за пределы существующих методик за счет реализации более целостного, ориентированного на человека подхода к обучению и распознаванию".
- "Мы считаем, что XYZ-code позволяет нам реализовать наше долгосрочное видение: перекрестное обучение, охватывающие модальности и языки".
- "Цель состоит в том, чтобы иметь предварительно обученные модели, которые могут совместно изучать представления для поддержки широкого спектра подчиненных задач ИИ, много в том, как люди делают сегодня".
Абстрактная сводка:
- "Корпорация Майкрософт принимает более целостный, ориентированный на человека подход к обучению и пониманию. Мы считаем, что XYZ-code позволяет нам реализовать наше долгосрочное видение: перекрестное обучение, охватывающие модальности и языки. За последние пять лет мы достигли человеческой производительности на тестах в".
Попробуйте извлечь из текста сводные данные
Вы можете использовать извлечение текста для получения сводок статей, документов или документов. Пример см. в статье краткого руководства.
Этот параметр можно использовать sentenceCount для указания количества возвращаемых предложений, при 3 этом используется значение по умолчанию. Допустимый диапазон: от 1 до 20.
Вы также можете использовать sortby параметр, чтобы указать, в каком порядке возвращаются извлеченные предложения — Offset или Rank, если Offset используется значение по умолчанию.
| Значение параметра | Описание |
|---|---|
| Ранг | Предложения упорядочиваются в соответствии с их релевантностью содержимого входного документа, степень которой определяется службой. |
| Смещение | Сохраняется исходный порядок, в котором предложения появляются во входном документе. |
Попробуйте абстрактное обобщение текста
В следующем примере вы начинаете работу с абстрактной сводкой текста:
- Скопируйте приведенную ниже команду в текстовый редактор. В примере BASH используется
\символ продолжения строки. Если в консоли или терминале используется другой символ продолжения строки, используйте этот символ.
curl -i -X POST https://<your-language-resource-endpoint>/language/analyze-text/jobs?api-version=2023-04-01 \
-H "Content-Type: application/json" \
-H "Ocp-Apim-Subscription-Key: <your-language-resource-key>" \
-d \
'
{
"displayName": "Text Abstractive Summarization Task Example",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "en",
"text": "At Microsoft, we have been on a quest to advance AI beyond existing techniques, by taking a more holistic, human-centric approach to learning and understanding. As Chief Technology Officer of Azure AI services, I have been working with a team of amazing scientists and engineers to turn this quest into a reality. In my role, I enjoy a unique perspective in viewing the relationship among three attributes of human cognition: monolingual text (X), audio or visual sensory signals, (Y) and multilingual (Z). At the intersection of all three, there's magic—what we call XYZ-code as illustrated in Figure 1—a joint representation to create more powerful AI that can speak, hear, see, and understand humans better. We believe XYZ-code enables us to fulfill our long-term vision: cross-domain transfer learning, spanning modalities and languages. The goal is to have pretrained models that can jointly learn representations to support a broad range of downstream AI tasks, much in the way humans do today. Over the past five years, we have achieved human performance on benchmarks in conversational speech recognition, machine translation, conversational question answering, machine reading comprehension, and image captioning. These five breakthroughs provided us with strong signals toward our more ambitious aspiration to produce a leap in AI capabilities, achieving multi-sensory and multilingual learning that is closer in line with how humans learn and understand. I believe the joint XYZ-code is a foundational component of this aspiration, if grounded with external knowledge sources in the downstream AI tasks."
}
]
},
"tasks": [
{
"kind": "AbstractiveSummarization",
"taskName": "Text Abstractive Summarization Task 1",
}
]
}
'
При необходимости внесите следующие изменения в команду.
- Замените значение
your-language-resource-keyсобственным ключом. - Замените первую часть URL-адреса запроса
your-language-resource-endpointURL-адресом своей конечной точки.
- Замените значение
Откройте окно командной строки (например, BASH).
Вставьте команду из текстового редактора в окно командной строки, а затем выполните команду.
Получите
operation-locationиз заголовка ответа. Значение выглядит примерно так, как показано по следующему URL-адресу:
https://<your-language-resource-endpoint>/language/analyze-text/jobs/12345678-1234-1234-1234-12345678?api-version=2022-10-01-preview
- Чтобы получить результаты запроса, используйте следующую команду cURL. Обязательно замените
<my-job-id>числовым значением идентификатора, полученным из предыдущего заголовка ответаoperation-location:
curl -X GET https://<your-language-resource-endpoint>/language/analyze-text/jobs/<my-job-id>?api-version=2022-10-01-preview \
-H "Content-Type: application/json" \
-H "Ocp-Apim-Subscription-Key: <your-language-resource-key>"
Пример ответа JSON на абстрактное текстовое сводные данные
{
"jobId": "cd6418fe-db86-4350-aec1-f0d7c91442a6",
"lastUpdateDateTime": "2022-09-08T16:45:14Z",
"createdDateTime": "2022-09-08T16:44:53Z",
"expirationDateTime": "2022-09-09T16:44:53Z",
"status": "succeeded",
"errors": [],
"displayName": "Text Abstractive Summarization Task Example",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "AbstractiveSummarizationLROResults",
"taskName": "Text Abstractive Summarization Task 1",
"lastUpdateDateTime": "2022-09-08T16:45:14.0717206Z",
"status": "succeeded",
"results": {
"documents": [
{
"summaries": [
{
"text": "Microsoft is taking a more holistic, human-centric approach to AI. We've developed a joint representation to create more powerful AI that can speak, hear, see, and understand humans better. We've achieved human performance on benchmarks in conversational speech recognition, machine translation, ...... and image captions.",
"contexts": [
{
"offset": 0,
"length": 247
}
]
}
],
"id": "1"
}
],
"errors": [],
"modelVersion": "latest"
}
}
]
}
}
| параметр | Описание |
|---|---|
-X POST <endpoint> |
Указывает конечную точку ресурса языка для доступа к API. |
--header Content-Type: application/json |
Тип содержимого для отправки данных JSON. |
--header "Ocp-Apim-Subscription-Key:<key> |
Указывает ключ ресурса языка для доступа к API. |
-data |
JSON-файл, содержащий данные, которые необходимо передать с запросом. |
Приведенные ниже команды cURL выполняются из оболочки BASH. Измените эти команды, указав имя ресурса, ключ ресурса и значения JSON. Попробуйте проанализировать исходные документы, выбрав Personally Identifiable Information (PII) проект с примером кода или Document Summarization:
Пример документа для резюмирования
Для этого проекта требуется исходный документ, отправленный в исходный контейнер. Вы можете скачать образец документа Microsoft Word или Adobe PDF для этого быстрого старта. Исходный язык — английский.
Создание запроса POST
С помощью предпочтительного редактора или интегрированной среды разработки создайте новый каталог для вашего приложения с именем
native-document.Создайте файл JSON с именем document-summarization.json в собственном каталоге документов.
Скопируйте и вставьте пример запроса сводки в свой
document-summarization.jsonфайл. Замените{your-source-container-SAS-URL}и{your-target-container-SAS-URL}на значения из экземпляра контейнеров учетной записи хранения на портале Azure:
Пример запроса
{
"tasks": [
{
"kind": "ExtractiveSummarization",
"parameters": {
"sentenceCount": 6
}
}
],
"analysisInput": {
"documents": [
{
"source": {
"location": "{your-source-blob-SAS-URL}"
},
"targets": {
"location": "{your-target-container-SAS-URL}"
}
}
]
}
}
Запуск запроса POST
Перед выполнением запроса POST, замените {your-language-resource-endpoint} и {your-key} значением конечной точки из вашего экземпляра ресурса в портале Azure.
Это важно
Обязательно удалите ключ из кода, когда завершите работу, и ни в коем случае не публикуйте его в открытом доступе. Для рабочей среды используйте безопасный способ хранения и доступа к учетным данным, например Azure Key Vault. Дополнительные сведения см. в статье "Безопасность служб искусственного интеллекта Azure".
PowerShell
cmd /c curl "{your-language-resource-endpoint}/language/analyze-documents/jobs?api-version=2024-11-15-preview" -i -X POST --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}" --data "@document-summarization.json"
командная строка или терминал
curl -v -X POST "{your-language-resource-endpoint}/language/analyze-documents/jobs?api-version=2024-11-15-preview" --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}" --data "@document-summarization.json"
Пример ответа:
HTTP/1.1 202 Accepted
Content-Length: 0
operation-location: https://{your-language-resource-endpoint}/language/analyze-documents/jobs/f1cc29ff-9738-42ea-afa5-98d2d3cabf94?api-version=2024-11-15-preview
apim-request-id: e7d6fa0c-0efd-416a-8b1e-1cd9287f5f81
x-ms-region: West US 2
Date: Thu, 25 Jan 2024 15:12:32 GMT
Ответ POST (jobId)
Вы получите ответ 202 (Успех), содержащий заголовок Operation-Location только для чтения. Значение этого заголовка содержит идентификатор задания, который можно запросить, чтобы получить состояние асинхронной операции и получить результаты с помощью запроса GET:
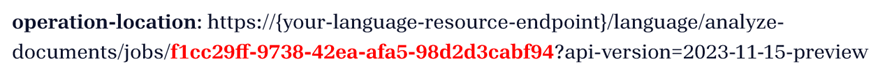
Получение результатов анализа (запрос GET)
После успешного запроса POST опрашивайте заголовок местоположения операции, возвращённый в запросе POST, чтобы просмотреть обработанные данные.
Ниже приведена структура запроса GET :
GET {cognitive-service-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2024-11-15-previewПеред выполнением команды внесите следующие изменения:
Замените {jobId} заголовком Operation-Location из ответа POST.
Замените {your-language-resource-endpoint} и {your-key} значениями из экземпляра языковой службы в портале Azure.
GET-запрос
cmd /c curl "{your-language-resource-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2024-11-15-preview" -i -X GET --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}"
curl -v -X GET "{your-language-resource-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2024-11-15-preview" --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}"
Изучите ответ.
Вы получаете ответ 200 (успех) с данными в формате JSON. Поле состояния указывает результат операции. Если операция не завершена, значение состояния является "выполняется" или "неНачато", и необходимо снова вызвать API вручную или через скрипт. Мы рекомендуем установить между вызовами интервал в одну секунду или более.
Пример ответа
{
"jobId": "f1cc29ff-9738-42ea-afa5-98d2d3cabf94",
"lastUpdatedDateTime": "2024-01-24T13:17:58Z",
"createdDateTime": "2024-01-24T13:17:47Z",
"expirationDateTime": "2024-01-25T13:17:47Z",
"status": "succeeded",
"errors": [],
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "ExtractiveSummarizationLROResults",
"lastUpdateDateTime": "2024-01-24T13:17:58.33934Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "doc_0",
"source": {
"kind": "AzureBlob",
"location": "https://myaccount.blob.core.windows.net/sample-input/input.pdf"
},
"targets": [
{
"kind": "AzureBlob",
"location": "https://myaccount.blob.core.windows.net/sample-output/df6611a3-fe74-44f8-b8d4-58ac7491cb13/ExtractiveSummarization-0001/input.result.json"
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2023-02-01-preview"
}
}
]
}
}
После успешного завершения:
- Проанализированные документы можно найти в целевом контейнере.
- Успешный метод POST возвращает код ответа, указывающий
202 Accepted, что служба создала пакетный запрос. - Запрос POST также вернул заголовки ответа, включая
Operation-Locationзначение, используемое в последующих запросах GET.
Очистите ресурсы
Если вы хотите очистить и удалить подписку на службы искусственного интеллекта Azure, можно удалить ресурс или группу ресурсов. Удаление группы ресурсов также удаляет все другие ресурсы, связанные с ней.