Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Когда пользовательский запрос сопоставляется с базой знаний, API службы QnA Maker возвращает соответствующие ответы вместе с оценкой достоверности. Эта оценка означает степень достоверности того, что ответ соответствует этому запросу пользователя.
Оценка достоверности находится в пределах от 0 до 100. Оценка 100, скорее всего, указывает на точное соответствие, а оценка 0 означает, что соответствия не обнаружено. Чем выше оценка — тем больше уверенность в ответе. Для данного запроса может возвращаться несколько ответов. В этом случае ответы возвращаются в порядке уменьшения оценки достоверности.
В приведенном ниже примере представлена одна сущность QnA с 2 вопросами.

В приведенном выше примере для разных типов пользовательских запросов можно ожидать такие оценки, как в диапазоне оценок ниже:
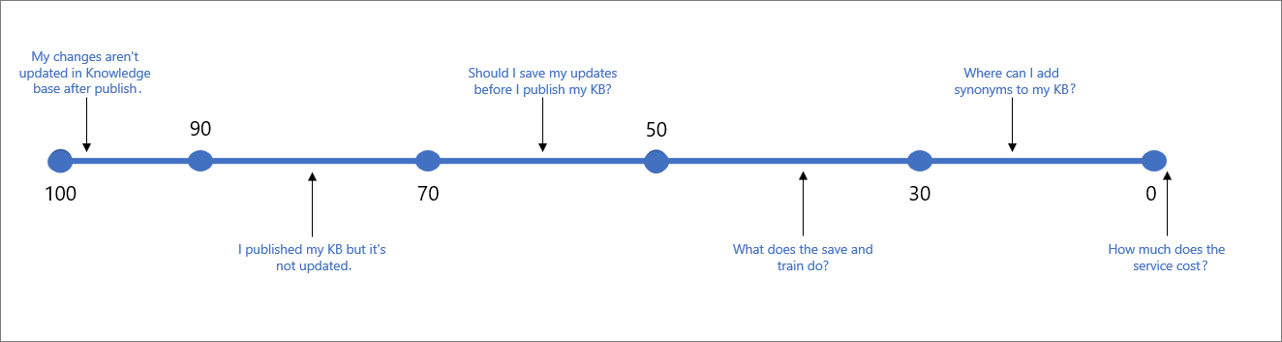
В следующей таблице указана типичная уверенность, ассоциированная с данным баллом.
| Значение оценки | Значение оценки | Пример запроса |
|---|---|---|
| 90–100 | Практически точное совпадение с запросом пользователя и вопросом из базы знаний | "После публикации мои изменения в базе знаний не обновляются" |
| > 70 | Высокий уровень достоверности. Обычно это правильный ответ, который полностью отвечает на запрос пользователя | "Я опубликовал свою базу знаний, но она не обновлена" |
| 50–70 | Средний уровень достоверности. Обычно довольно хороший ответ, соответствующий основному намерению в запросе пользователя. | Требуется ли сохранять изменения перед публикацией базы знаний? |
| 30–50 | Ответ с низким уровнем уверенности — обычно это связанный ответ, который частично соответствует намерению пользователя. | Что делают функции сохранения и обучения? |
| < 30 | Очень низкая достоверность. Обычно ответ на запрос пользователя не предоставляется, но выводятся некоторые совпадения слов или фраз. | "Где можно добавить синонимы в мою базу знаний" |
| 0 | Нет соответствия, поэтому ответ не возвращается. | "Сколько стоит использование службы" |
Указание порогового значения оценки
В приведенной выше таблице показаны оценки, ожидаемые в большинстве баз знаний. На самом деле, поскольку все базы знаний отличаются и содержат различные типы слов, намерений и целей, рекомендуем протестировать различные пороговые значения и выбрать то, которое лучше всего вам подходит. По умолчанию пороговое значение равно 0, чтобы возвращались все возможные ответы. Рекомендуемое пороговое значение, которое работает для большинства баз знаний, — 50.
При выборе порогового значения не забывайте про баланс между точностью и охватом и настраивайте порог в соответствии со своими требованиями.
Если точность важнее для вашего сценария, увеличьте пороговое значение. Таким образом, каждый возвращаемый ответ будет иметь гораздо более высокую степень достоверности и намного вероятнее будет соответствовать запросу пользователя. В этом случае многие другие вопросы могут остаться без ответа. Например, если пороговое значение — 70, можно пропустить некоторые неоднозначные примеры, такие как "Что такое сохранение и обучение?".
Если охват (или полнота) важнее и вы хотите ответить на как можно большее количество вопросов, даже если имеется только частичное отношение к вопросу пользователя, то следует снизить пороговое значение. Это означает, что может быть больше случаев, когда ответ не соответствует фактическому запросу пользователя, а предоставляет лишь некоторые связанные сведения. Например, если вы установите пороговое значение 30, вы сможете давать ответы на такие запросы, как "Где я могу изменить свою базу знаний?"
Примечание.
В новых версиях QnA Maker улучшена логика оценки, что может повлиять на пороговые значения. Каждый раз при обновлении службы проверяйте и, при необходимости, изменяйте пороговые значения. Узнать текущую версию службы QnA вы можете здесь. Сведения о том, как получить последние обновления см. здесь.
Установка порога
Установите пороговую оценку в качестве свойства JSON-тела API GenerateAnswer. Это означает, что вы устанавливаете его для каждого вызова GenerateAnswer.
В Bot Framework установите оценку как часть объекта options с помощью C# или Node.js.
Улучшение оценок достоверности
Чтобы улучшить оценку достоверности конкретного ответа на запрос пользователя, можно добавить запрос пользователя в базу знаний в качестве альтернативного вопроса для этого ответа. Вы также можете использовать изменения слов без учета регистра, чтобы добавить синонимы к ключевым словам в вашей КБ.
Аналогичные оценки достоверности
Если несколько ответов имеют аналогичные оценки достоверности, вполне вероятно, что запрос был слишком общим и, следовательно, соответствовал с равной вероятностью с несколькими ответами. Попытайтесь структурировать QnAs лучше, чтобы каждый объект QnA имел четкое намерение.
Различия оценки достоверности между тестовой и рабочей средами
Оценка достоверности ответа может незначительно измениться между тестируемой и опубликованной версией базы знаний, даже если содержимое одинаковое. Это связано с тем, что содержимое теста и опубликованного база знаний находятся в разных индексах поиска ИИ Azure.
Тестовый индекс содержит все пары "вопрос/ответ" вашей базы знаний. При запросе к индексу для тестирования запрос применяется ко всему индексу, а результаты ограничены секцией для этой конкретной базы знаний. Если результаты тестового запроса отрицательно влияют на возможность проверки базы знаний, можно выполнить следующее.
- Организуйте свою базу знаний с помощью одного из следующих:
- 1 ресурс ограничен одной базой знаний: ограничьте ваш единственный ресурс QnA (и результирующий тестовый индекс поиска Azure ИИ) одной базой знаний.
- 2 ресурса: 1 для тестирования, 1 для рабочей среды: настройте два ресурса QnA Maker, один из которых используется для тестирования (со своими тестовыми и рабочими индексами), а другой — для рабочей среды (также имеющий свои собственные тестовые и рабочие индексы)
- и всегда используйте одинаковые параметры, такие как top, при запросе к тестовой и рабочей базе знаний.
При публикации базы знаний ее содержимое раздела вопросов и ответов переносится из тестового индекса в рабочий индекс в службе "Поиск Azure". Посмотрите, как работает операция публикации.
Если у вас есть база знаний в разных регионах, каждый регион использует собственный индекс поиска ИИ Azure. Так как используются разные индексы, оценки не обязательно будут совпадать.
Совпадения не найдены
Если алгоритм ранжирования не нашел подходящего совпадения, возвращается значение оценки достоверности 0.0 или "Нет", а ответ по умолчанию – "Нет хорошего совпадения в базе знаний". Вы можете переопределить этот ответ по умолчанию в коде бота или приложения, вызывающего конечную точку. В качестве альтернативы вы также можете установить замену ответа в Azure, и это изменяет значение по умолчанию для всех баз знаний, развернутых в конкретной службе QnA Maker.